高级排序算法之归并排序
发布时间: 2024-01-09 09:07:10 阅读量: 47 订阅数: 36 

归并排序(Merge sort)(台灣譯作:合併排序)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
# 1. 排序算法概述
## 1.1 排序算法的定义和用途
排序算法是一种将一组数据按照特定顺序进行排列的算法。排序算法在计算机领域有着广泛的应用,例如在数据库索引构建、数据压缩、图形处理等各个领域均有着重要的作用。
## 1.2 常见的排序算法分类
排序算法可以分为多种不同的分类,常见的包括:
- 比较类排序:通过比较来决定元素间的相对次序,如冒泡排序、快速排序等。
- 非比较类排序:不通过元素间的比较来决定元素的相对次序,如计数排序、桶排序等。
- 稳定排序:如果待排序的序列中存在值相等的元素,经过排序之后它们的相对位置保持不变,如插入排序、归并排序。
- 非稳定排序:如果序列中存在值相等的元素,经过排序之后它们的相对位置可能发生变化,如快速排序、希尔排序等。
## 1.3 高级排序算法介绍
高级排序算法包括归并排序、快速排序、堆排序等,它们通常具有较高的时间复杂度表现和较好的稳定性特点,能够适应不同规模数据的排序需求。接下来我们将重点介绍归并排序算法。
# 2. 归并排序原理
#### 2.1 归并排序的基本思想
归并排序是一种基于分治策略的排序算法。其基本思想是将待排序的序列分成两个子序列,分别对子序列进行排序,然后将两个已排序的子序列合并成一个有序的序列。
#### 2.2 归并排序的递归与迭代实现
归并排序可以通过递归或迭代的方式来实现。
##### 2.2.1 递归实现
递归实现归并排序时,将待排序的序列不断分割成更小的子序列,直到每个子序列只剩下一个元素。然后,将这些单个元素逐对合并,直到最后得到一个有序的序列。
下面是Python代码示例:
```python
def merge_sort_recursive(nums):
if len(nums) <= 1:
return nums
mid = len(nums) // 2
left = merge_sort_recursive(nums[:mid])
right = merge_sort_recursive(nums[mid:])
return merge(left, right)
def merge(left, right):
res = []
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
res.extend(left[i:])
res.extend(right[j:])
return res
```
##### 2.2.2 迭代实现
迭代实现归并排序时,使用循环来不断合并已排序的子序列,直到得到一个完整的有序序列。
下面是Python代码示例:
```python
def merge_sort_iterative(nums):
size = 1
while size < len(nums):
left = 0
while left < len(nums) - size:
mid = left + size - 1
right = min(left + 2 * size - 1, len(nums) - 1)
merge(nums, left, mid, right)
left += 2 * size
size *= 2
def merge(nums, left, mid, right):
temp = []
i, j = left, mid + 1
while i <= mid and j <= right:
if nums[i] <= nums[j]:
temp.append(nums[i])
i += 1
else:
temp.append(nums[j])
j += 1
while i <= mid:
temp.append(nums[i])
i += 1
while j <= right:
temp.append(nums[j])
j += 1
for k in range(len(temp)):
nums[left + k] = temp[k]
```
#### 2.3 归并排序的时间复杂度分析
归并排序的时间复杂度为O(nlogn),其中n为待排序序列的长度。归并排序的时间复杂度在各种排序算法中相对较低,并且稳定性好,适用于各种场景。
# 3. 归并排序算法流程
在本章中,我们将详细介绍归并排序算法的流程。归并排序是一种高效稳定的排序算法,它采用分治的策略,将待排序的序列分割成若干个子序列,然后逐步合并这些子序列,最终得到有序的序列。下面我们将分别介绍归并排序的分治策略、递归实现步骤和迭代实现步骤。
## 3.1 归并排序的分治策略
归并排序的基本思想是将待排序的序列递归地分割成两个子序列,直到每个子序列只有一个元素或为空。然后将这些子序列两两合并,同时按照顺序进行排序,最终得到有序的序列。归并排序的分治策略可以用以下步骤表示:
1. 将待排序序列分割成两个子序列,直到每个子序列只有一个元素或为空。
2. 对每对子序列进行合并排序。
3. 递归地合并排序后的子序列,直到整个序列排序完成。
## 3.2 归并排序的递归实现步骤
归并排序的递归实现步骤如下:
1. 将待排序序列分割成两个子序列,直到每个子序列只有一个元素或为空。
2. 对每对子序列进行合并排序:
- 比较两个子序列的第一个元素,将较小的元素放入合并后的序列中。
- 继续比较两个子序列的下一个元素,并将较小的元素放入合并后的序列中,直到其中一个子序列为空。
- 将另一个非空子序列中剩余的元素全部放入合并后的序列中。
3. 递归地合并排序后的子序列,直到整个序列排序完成。
下面是归并排序的递归实现的Python代码示例:
```python
def merge_sort_recursive(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort_recursive(arr[:mid])
right = merge_sort_recursive(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
```
## 3.3 归并排序的迭代实现步骤
除了递归实现外,归并排序还可以使用迭代的方式进行实现。迭代实现步骤如下:
1. 将待排序序列中的每个元素视为一个单独的有序序列。
2. 重复进行两两合并排序,直到得到完全有序的序列。
下面是归并排序的迭代实现的Python代码示例:
```python
def merge_sort_iterative(arr):
n = len(arr)
gap = 1
while gap < n:
for i in range(0, n - gap, 2 * gap):
left = i
mid = i + gap
right = min(i + 2 * gap, n)
merge(arr, left, mid, right)
gap *= 2
return arr
def merge(arr, left, mid, right):
temp = []
i = left
j = mid
while i < mid and j < right:
if arr[i] <= arr[j]:
temp.append(arr[i])
i += 1
else:
temp.append(arr[j])
j += 1
while i < mid:
temp.append(arr[i])
i += 1
while j < right:
temp.append(arr[j])
j += 1
arr[left:right] = temp
```
以上是归并排序算法的流程介绍和递归、迭代实现的代码示例,通过这些步骤可以清楚地理解归并排序的实现原理。在下一章节中,我们将介绍归并排序的优化方法。
# 4. 归并排序的优化
在实际应用中,归并排序虽然具有稳定的时间复杂度,但在某些情况下会出现一些不足。因此,我们需要对归并排序进行一些优化,以提高其性能和适用性。
#### 4.1 归并排序的空间优化
一般的归并排序算法需要额外的 O(n) 空间来存储临时数组。这会导致在处理大规模数据时,空间复杂度较高,不利于内存资源的合理利用。为了优化空间复杂度,我们可以使用原地排序的思想来实现归并排序。
下面以Python语言为例,展示如何在归并排序中进行空间优化:
```python
def merge_sort_in_place(arr):
if len(arr) > 1:
mid = len(arr) // 2
L = arr[:mid]
R = arr[mid:]
merge_sort_in_place(L)
merge_sort_in_place(R)
i = j = k = 0
while i < len(L) and j < len(R):
if L[i] < R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
while i < len(L):
arr[k] = L[i]
i += 1
k += 1
while j < len(R):
arr[k] = R[j]
j += 1
k += 1
return arr
```
通过这种方式,我们可以在归并排序时实现空间复杂度的优化,不需要额外的 O(n) 空间。
#### 4.2 归并排序的时间优化
归并排序的基本时间复杂度为 O(nlogn),但在一些特定情况下,可以通过一些优化策略来提升排序的效率。例如,当数组长度较小时,可以选择插入排序来代替归并排序的递归调用。
下面是一个示例代码,展示了如何在归并排序中结合插入排序来进行时间优化:
```python
def insertion_sort(arr, low, high):
for i in range(low + 1, high + 1):
key = arr[i]
j = i - 1
while j >= low and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
def merge_sort_with_insertion(arr, low, high):
if high - low < 10: # 设置阈值,当数组长度小于10时,使用插入排序
insertion_sort(arr, low, high)
else:
mid = (low + high) // 2
merge_sort_with_insertion(arr, low, mid)
merge_sort_with_insertion(arr, mid + 1, high)
merge(arr, low, mid, high)
merge_sort_with_insertion(arr, 0, len(arr) - 1)
```
在实现中,当数组长度小于10时,我们切换到插入排序,从而减少递归调用的开销,从而提升归并排序的效率。
#### 4.3 归并排序在实际应用中的优化策略
在实际应用中,归并排序往往需要根据具体场景做进一步的优化。例如,可以结合多线程并行计算,利用CPU多核的优势来加速排序过程。另外,在处理外部存储大数据时,可以利用归并排序的特性,在磁盘I/O方面进行优化,减少数据的读写次数,提高排序效率。
综上所述,归并排序虽然拥有稳定的时间复杂度,但是在实际应用中仍然需要针对具体情况进行优化,以提升其性能和适用性。
# 5. 归并排序与其他排序算法的对比
在这一章中,我们将对归并排序与其他常见的排序算法进行对比,包括快速排序和堆排序,以及分析归并排序的优势和劣势。
### 5.1 归并排序与快速排序的比较
#### 性能对比
- 归并排序的时间复杂度为O(nlogn),最坏情况下也能保证O(nlogn)的时间复杂度;而快速排序的平均时间复杂度也是O(nlogn),但最坏情况下可能达到O(n^2)。
- 归并排序的空间复杂度为O(n),因为每次合并操作需要额外的辅助数组;快速排序的空间复杂度为O(logn),因为递归调用时需要额外的栈空间。
#### 稳定性对比
- 归并排序是稳定的排序算法,相同元素的相对位置不会发生改变;而快速排序是不稳定的,因为交换操作可能破坏相同元素的先后顺序。
#### 适用场景
- 当数据量较大,对稳定性排序有要求时,优先考虑使用归并排序;而对于一般情况下,数据量较小且对排序性能有较高要求时,可以选择快速排序。
### 5.2 归并排序与堆排序的比较
#### 性能对比
- 归并排序的时间复杂度为O(nlogn),稳定且适用于大规模数据排序;堆排序的时间复杂度也为O(nlogn),且对数据原地排序,但是不稳定。
#### 空间复杂度对比
- 归并排序需要额外的O(n)辅助空间,因此空间复杂度较高;而堆排序的空间复杂度为O(1),在空间上优于归并排序。
#### 对比总结
- 归并排序适用于大规模数据排序,并且能保证稳定性;堆排序适用于需要原地排序的情况,并且对空间复杂度有要求。
### 5.3 归并排序的优势与劣势分析
#### 优势
- 稳定性:保证相同元素的相对顺序不变。
- 适用性:适用于大规模数据、外部排序等场景。
- 可读性:算法结构清晰,易于理解和实现。
#### 劣势
- 空间复杂度高:需要额外的O(n)空间。
- 性能:在一些特定情况下,性能略逊于快速排序等原地排序算法。
综合来看,归并排序在稳定性和适用性上有较大优势,但在空间复杂度和部分性能指标上略逊色于其他排序算法。因此,在具体应用中需要根据实际情况进行选择。
# 6. 归并排序在实际应用中的案例分析
归并排序是一种高效、稳定的排序算法,在实际应用中有着广泛的应用。本章将通过三个不同的案例,分别探讨归并排序在大数据处理、外部排序和并行计算中的应用。
#### 6.1 归并排序在大数据处理中的应用
在处理大规模数据时,归并排序具有较好的性能优势。通过将大数据拆分成多个小数据块,在内存中分别对小数据块进行排序,然后利用归并排序的合并操作,将各个有序的小数据块合并成一个有序的大数据,从而达到对大规模数据进行排序的目的。
以下是一个使用归并排序处理百万级数据的示例代码(Python):
```python
def merge_sort(arr):
if len(arr) <= 1:
return arr
# 将数组拆分为两个子数组
mid = len(arr) // 2
left = arr[:mid]
right = arr[mid:]
# 递归调用归并排序对子数组进行排序
left = merge_sort(left)
right = merge_sort(right)
# 合并两个有序子数组
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
# 将剩余的元素添加到结果数组中
result.extend(left[i:])
result.extend(right[j:])
return result
# 测试数据
data = [4, 2, 9, 6, 3, 7, 1, 5, 8, 10]
sorted_data = merge_sort(data)
print(sorted_data)
```
通过以上代码,我们可以将一个包含10个元素的数组进行排序。在实际应用中,我们可以根据需要进行扩展,从而处理更大规模的数据集合。
#### 6.2 归并排序在外部排序中的应用
外部排序是一种在数据量大于内存容量的情况下,对数据进行排序的方法。归并排序是外部排序中最常使用的算法之一。
在外部排序中,我们需要将大文件分割成多个能够放入内存的小文件块,然后对这些小文件块分别使用归并排序进行排序。最后,再将排好序的小文件块进行归并,得到最终排序后的大文件。
下面是一个使用归并排序进行外部排序的示例代码(Java):
```java
import java.io.*;
import java.util.*;
public class ExternalSort {
public static void sort(String inputFilePath, String outputFilePath, int chunkSize) throws IOException {
List<String> chunkFilePaths = new ArrayList<>();
// 切分大文件为小文件块
try (BufferedReader reader = new BufferedReader(new FileReader(inputFilePath))) {
String line;
List<String> chunk = new ArrayList<>();
while ((line = reader.readLine()) != null) {
chunk.add(line);
if (chunk.size() == chunkSize) {
chunk.sort(null);
String chunkFilePath = writeChunkToFile(chunk);
chunkFilePaths.add(chunkFilePath);
chunk.clear();
}
}
if (!chunk.isEmpty()) {
chunk.sort(null);
String chunkFilePath = writeChunkToFile(chunk);
chunkFilePaths.add(chunkFilePath);
}
}
// 归并排序
mergeSort(chunkFilePaths, outputFilePath);
// 删除临时文件
for (String chunkFilePath : chunkFilePaths) {
File chunkFile = new File(chunkFilePath);
chunkFile.delete();
}
}
private static String writeChunkToFile(List<String> chunk) throws IOException {
String chunkFilePath = UUID.randomUUID().toString() + ".txt";
try (BufferedWriter writer = new BufferedWriter(new FileWriter(chunkFilePath))) {
for (String line : chunk) {
writer.write(line);
writer.newLine();
}
}
return chunkFilePath;
}
private static void mergeSort(List<String> inputFilePaths, String outputFilePath) throws IOException {
PriorityQueue<LineReader> pq = new PriorityQueue<>(Comparator.comparing(LineReader::getCurrentLine));
for (String inputFilePath : inputFilePaths) {
LineReader lineReader = new LineReader(inputFilePath);
if (lineReader.hasNextLine()) {
pq.offer(lineReader);
}
}
try (BufferedWriter writer = new BufferedWriter(new FileWriter(outputFilePath))) {
while (!pq.isEmpty()) {
LineReader lineReader = pq.poll();
String line = lineReader.readLine();
writer.write(line);
writer.newLine();
if (lineReader.hasNextLine()) {
pq.offer(lineReader);
}
}
}
}
private static class LineReader {
private final BufferedReader reader;
private String currentLine;
public LineReader(String filePath) throws IOException {
reader = new BufferedReader(new FileReader(filePath));
currentLine = reader.readLine();
}
public String getCurrentLine() {
return currentLine;
}
public boolean hasNextLine() {
return currentLine != null;
}
public String readLine() throws IOException {
String line = currentLine;
currentLine = reader.readLine();
return line;
}
}
// 测试
public static void main(String[] args) throws IOException {
String inputFilePath = "input.txt";
String outputFilePath = "output.txt";
int chunkSize = 100;
sort(inputFilePath, outputFilePath, chunkSize);
// 输出排序后的结果
try (BufferedReader reader = new BufferedReader(new FileReader(outputFilePath))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
}
}
}
```
在以上代码中,我们首先将大文件切分为多个小文件块,每个小文件块中的数据量不超过给定的阈值(chunkSize)。然后,对每个小文件块使用归并排序进行排序。最后,我们使用归并操作将排好序的小文件块合并为一个有序的大文件。
#### 6.3 归并排序在并行计算中的应用
归并排序在并行计算中有着很好的适应性,可以通过并行化的方式提高排序的效率。
在并行计算中,我们可以将数组分成多个子数组,并使用多个线程或进程同时对子数组进行排序。接着,使用归并操作将排好序的子数组合并成一个有序的完整数组。
以下是一个使用归并排序进行并行计算的示例代码(Go):
```go
package main
import (
"fmt"
"sync"
)
func mergeSort(arr []int) []int {
if len(arr) <= 1 {
return arr
}
mid := len(arr) / 2
left := mergeSort(arr[:mid])
right := mergeSort(arr[mid:])
return merge(left, right)
}
func merge(left []int, right []int) []int {
result := make([]int, 0, len(left)+len(right))
i, j := 0, 0
for i < len(left) && j < len(right) {
if left[i] < right[j] {
result = append(result, left[i])
i++
} else {
result = append(result, right[j])
j++
}
}
result = append(result, left[i:]...)
result = append(result, right[j:]...)
return result
}
func parallelMergeSort(arr []int) []int {
if len(arr) <= 1 {
return arr
}
mid := len(arr) / 2
var left, right []int
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
left = parallelMergeSort(arr[:mid])
}()
go func() {
defer wg.Done()
right = parallelMergeSort(arr[mid:])
}()
wg.Wait()
return merge(left, right)
}
func main() {
data := []int{4, 2, 9, 6, 3, 7, 1, 5, 8, 10}
sortedData := parallelMergeSort(data)
fmt.Println(sortedData)
}
```
在上述代码中,我们首先定义了一个辅助函数`merge`,用于合并两个有序的子数组。然后,使用`mergeSort`函数对原始数组进行串行的归并排序。接下来,我们利用并行化的方式实现`parallelMergeSort`函数,将数组进行切分,分别并行地对子数组进行排序,最后再合并子数组得到有序的完整数组。
通过以上的案例分析,我们可以看到归并排序在大数据处理、外部排序和并行计算等实际应用中都具有较好的效果和灵活性。然而,在具体应用场景中还需要根据实际情况进行优化选择,以获得更好的性能和效果。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《java数据结构与算法面试实战课》从基础入手,深入探讨了Java编程的基本语法和面向对象编程的要点。在介绍常用数据结构时,着重介绍了数组和链表的原理和应用。在排序算法方面,详细讲解了冒泡、选择和插入排序,以及高级排序算法中的归并排序和快速排序。此外,还对哈希表的原理和应用场景进行了深入剖析,以及图算法中的最短路径算法和最小生成树算法进行了解析。在字符串匹配算法和动态规划算法方面,也有详细的介绍和实战示例。最后,通过对红黑树、B树和B树的原理和应用,以及动态规划算法中的最长公共子序列问题进行探讨,让读者全面掌握Java数据结构与算法的精髓,为面试和实际工程应用打下坚实基础。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入理解锂电池保护板:电路图原理与应用实践详解
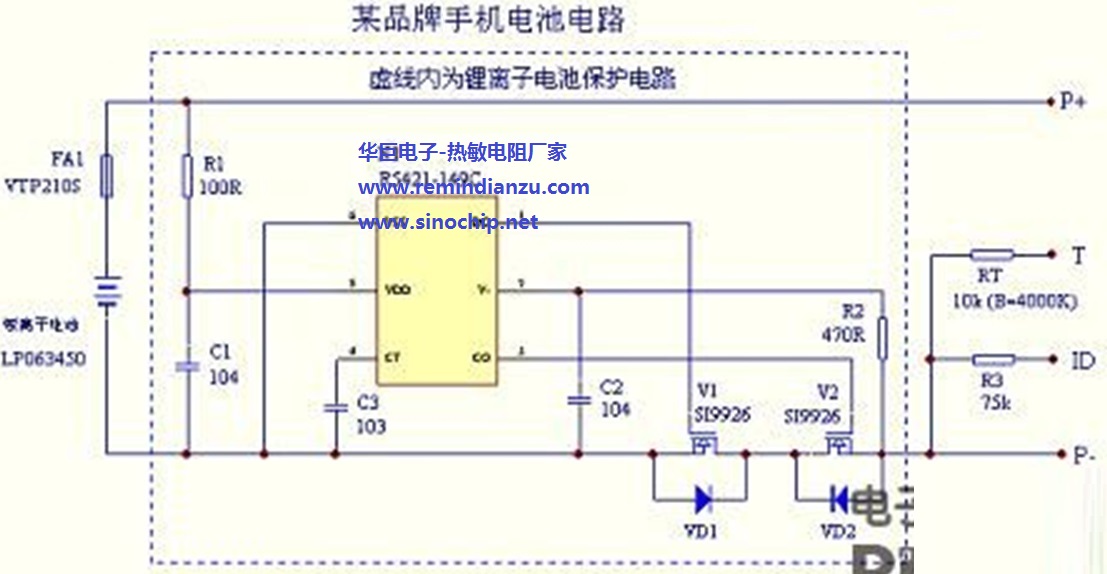
# 摘要
锂电池保护板作为关键的电池管理系统组件,对于确保电池安全、延长使用寿命至关重要。本文对锂电池保护板进行了全面介绍,分析了其电路图原理,并探讨了在不同电池类型中的应用与设计实践。文中详细解读了保护板的主要电路设计原理,包括过充、过放、短路和过流保护机制,以及微控制器集成与通信协议的应用。同时,本文也指出了保护板设计过程中的挑战,并通过案例分析提出了相应的解决方案。最后,本文展望了保护板的未来发展趋势,重点在于新型材料的应用以及智能化和物
【自动化操作录制系统】:易语言构建稳定可靠的实践教程

# 摘要
本文系统地介绍了自动化操作录制系统的设计与实现,包括易语言的特性、开发环境的搭建、基础语法,以及自动化操作录制技术的原理和脚本编写方法。通过对易语言的详细介绍和案例分析,本文阐述了如何构建稳定可靠的自动化操作录制系统,并探讨了进阶应用中的功能扩展、网络分布式处理和安全性管理。文章旨在为开发者提供一套完整的自动化操作录制解决方案,帮助他们在易语言环境下快速开发出高效且安
高级VLAN配置案例分析:企业级应用全面解读
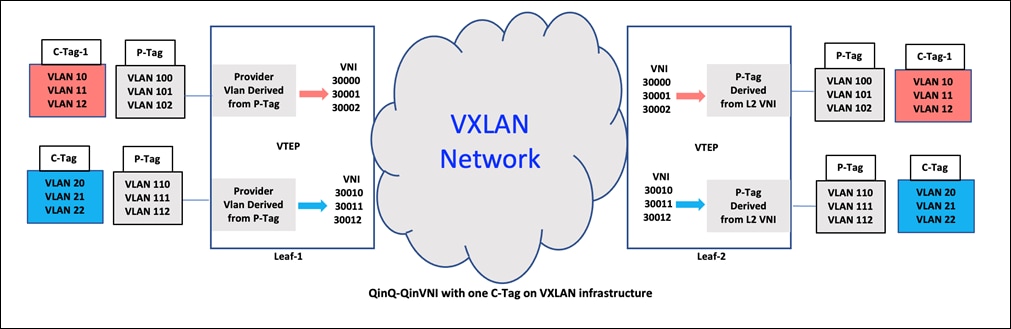
# 摘要
虚拟局域网(VLAN)技术是现代企业网络设计中的关键组成部分,其目的是为了提高网络资源的灵活性、安全性和管理效率。本文首先介绍了VLAN的基本概念和企业需求,接着深入探讨了
ROS新兵起步指南:Ubuntu下“鱼香肉丝”包的安装全教程

# 摘要
本文提供了ROS(Robot Operating System)的概述、安装与设置指南,以及基础概念和进阶操作的详细教程。首先,本文概述了ROS的基本架构和核心组件,并指导读者完成在Ubuntu环境下的ROS安装和配置过程。随后,深入探讨了ROS的基础概念,包括节点、话题、消息、服务和工作空间等。在此基础上,介绍了如
复变函数绘图秘籍:Matlab中三维艺术的创造与优化
# 摘要
本文全面探讨了复变函数绘图的数学基础及其在Matlab中的应用。文章首先回顾了复变函数绘图的数学基础和Matlab的基本
【CPCI标准2.0中文版:全面入门与深入解析】:掌握核心应用与行业实践的终极指南
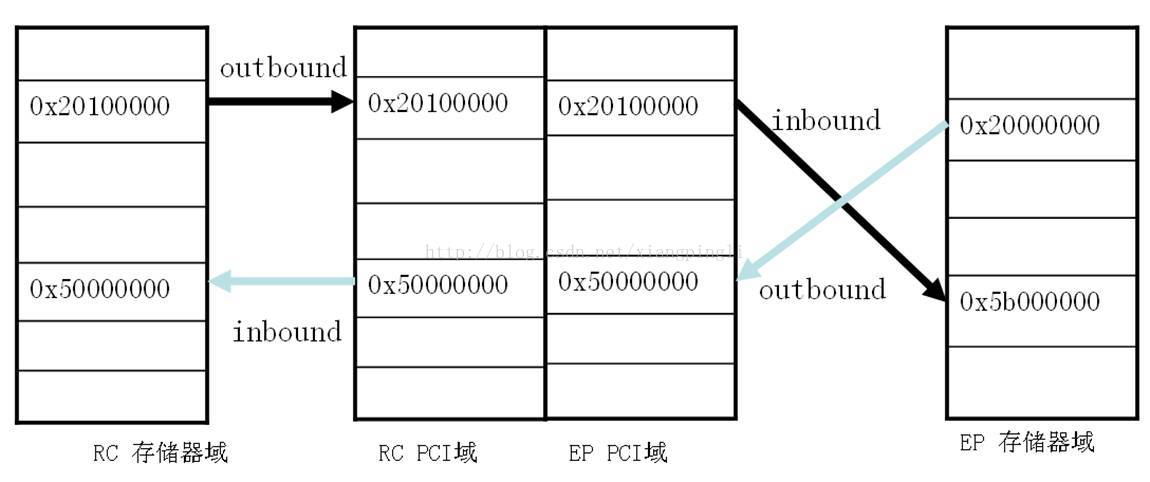
# 摘要
本文旨在全面介绍CPCI标准2.0的核心原理、技术规范及在不同行业中的应用。文章首先回顾了CPCI标准的发展历程,然后深入剖析其框架结构和关键技术,包括与PCI及PCI-X的对比、PCIe技术的演进及其可
计算机视觉目标检测:案例分析与实战技巧
# 摘要
计算机视觉中的目标检测是图像分析的核心问题之一,旨在识别和定位图像中特定物体的位置。本文首先概述了目标检测的发展历程和理论基础,然后深入分析了经典算法如R-CNN、YOLO和SSD的原理及性能。接着,文章探讨了目标检测在实战中的数据处理、模型训练和调优技巧,并通过多个行业案例加以说明。此外,本文还介绍了模型压缩、加速技术以及部署框架和工具,以实现
虚拟串口驱动7.2嵌入式系统集成与测试:专家指导手册
# 摘要
本文系统地阐述了虚拟串口驱动的概念、在嵌入式系统中的集成基础及其测试方法论,并通过实践案例分析来探讨驱动集成后的功能验证和故障诊断。文章首先介绍了虚拟串口驱动的基本概念,然后详细探讨了嵌入式系统的集成,包括驱动程序的作用、集成步骤和关键的技术要求。在实践部分,本文详细说明了集成前的准备工作、集成过程中的关键步骤以及集成后如何进行功能和性能测试。最后,文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )