探索MATLAB矩阵奇异值分解:解锁数据降维新境界,深入理解矩阵本质
发布时间: 2024-06-10 05:07:09 阅读量: 86 订阅数: 47 
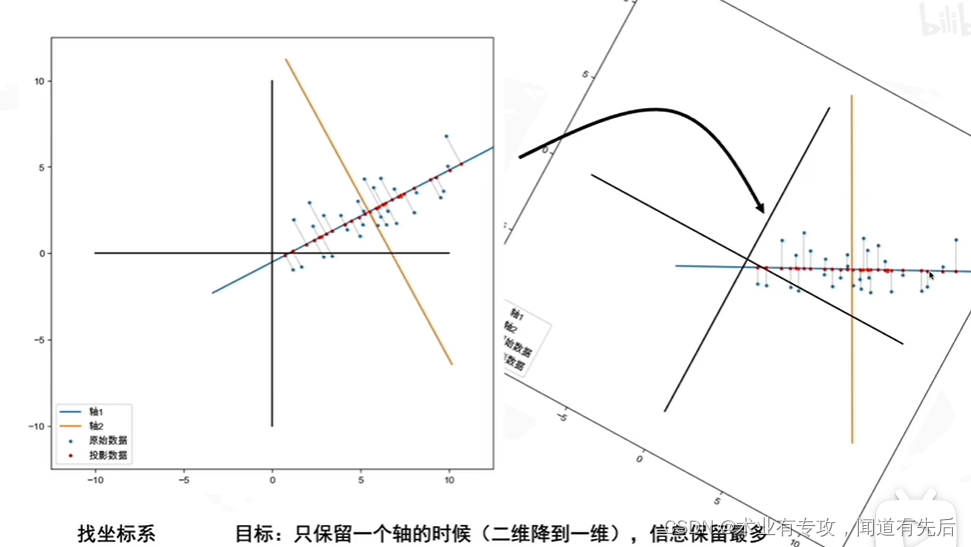
# 1. 矩阵奇异值分解(SVD)基础**
矩阵奇异值分解(SVD)是一种强大的数学工具,用于对矩阵进行分解,揭示其内部结构和性质。它广泛应用于数据分析、图像处理和机器学习等领域。
SVD将一个矩阵分解为三个矩阵的乘积:一个正交矩阵U,一个对角矩阵Σ和另一个正交矩阵V。对角矩阵Σ包含了矩阵的奇异值,它们是矩阵的重要特征值。奇异值的大小反映了矩阵中各个特征向量的相对重要性。
# 2. SVD的理论基础
### 2.1 线性代数基础
**矩阵秩**
矩阵的秩表示其线性无关行或列的数量。秩为 r 的矩阵可以表示为 r 个线性无关向量的和。
**正交分解**
正交分解将矩阵分解为两个正交矩阵的乘积:
```
A = QR
```
其中:
* A 是原始矩阵
* Q 是正交矩阵,其列向量是单位正交向量
* R 是上三角矩阵
### 2.2 矩阵秩和正交分解
矩阵秩与正交分解密切相关。矩阵 A 的秩等于正交分解中上三角矩阵 R 的秩。
### 2.3 奇异值分解的定义和性质
**奇异值分解 (SVD)**
奇异值分解将矩阵分解为三个矩阵的乘积:
```
A = UΣV^T
```
其中:
* A 是原始矩阵
* U 和 V 是正交矩阵,其列向量是单位正交向量
* Σ 是对角矩阵,其对角元素称为奇异值
**性质**
SVD 具有以下性质:
* 奇异值是矩阵 A 的非负特征值。
* U 和 V 的列向量是 A 的左奇异向量和右奇异向量。
* 奇异值分解是矩阵 A 的唯一分解。
# 3. SVD的计算方法
### 3.1 数值方法(如QR分解)
**QR分解**是一种将矩阵分解为正交矩阵和上三角矩阵的方法。对于一个m×n矩阵A,其QR分解可以表示为:
```python
A = QR
```
其中,Q是一个m×m的正交矩阵(即Q^T Q = I),R是一个m×n的上三角矩阵。
**使用QR分解计算SVD**
QR分解可以用于计算SVD。具体步骤如下:
1. 对矩阵A进行QR分解,得到Q和R。
2. 计算R的奇异值分解,得到U和Σ。
3. 计算V = Q^T U。
则A的SVD为:
```python
A = U Σ V^T
```
**代码示例**
```python
import numpy as np
# 矩阵A
A = np.array([[1, 2], [3, 4]])
# QR分解
Q, R = np.linalg.qr(A)
# R的奇异值分解
U, Σ, Vh = np.linalg.svd(R)
# 计算V
V = Q.T @ U
# 输出SVD
print("U:")
print(U)
print("Σ:")
print(Σ)
print("V:")
print(V)
```
**逻辑分析**
* `np.linalg.qr(A)`:对矩阵A进行QR分解,得到正交矩阵Q和上三角矩阵R。
* `np.linalg.svd(R)`:对R进行奇异值分解,得到奇异值矩阵U、奇异值向量Σ和右奇异向量Vh。
* `Q.T @ U`:计算左奇异向量V。
* 输出U、Σ和V,即矩阵A的SVD。
### 3.2 迭代方法(如兰czos方法)
**兰czos方法**是一种迭代方法,用于计算大型稀疏矩阵的奇异值分解。该方法通过构造一个三对角矩阵来近似矩阵A的SVD。
**兰czos方法的步骤**
1. 初始化一个单位向量v_0。
2. 迭代进行以下步骤:
* 计算v_i = A v_{i-1}。
* 计算α_i = v_i^T v_i。
* 计算β_i = v_i^T v_{i+1}。
* 构造三对角矩阵T_i:
```
T_i =
[α_1 β_1 0 ... 0]
[β_1 α_2 β_2 ... 0]
[0 β_2 α_3 ... 0]
...
[0 0 0 ... α_i]
```
3. 计算T_i的特征值和特征向量。
4. 将T_i的特征值开方得到奇异值。
5. 将T_i的特征向量正交化得到奇异向量。
**代码示例**
```python
import numpy as np
from scipy.sparse.linalg import eigsh
# 矩阵A
A = np.array([[1, 2], [3, 4]])
# 初始化v_0
v0 = np.array([1, 0])
# 迭代次数
n_iter = 10
# 迭代兰czos方法
T = np.zeros((n_iter, n_iter))
for i in range(n_iter):
v = A @ v0
α = np.dot(v, v)
β = np.dot(v, v0)
T[i, i] = α
T[i,
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 MATLAB 矩阵为主题,深入浅出地介绍了矩阵的基础知识、运算技巧、索引切片、转置逆矩阵、分解、求解线性方程组、奇异值分解、可视化等方面的内容,帮助读者全面掌握矩阵操作。此外,专栏还扩展到 MySQL 数据库性能优化、索引设计、事务并发控制、备份恢复、高可用架构、监控报警、查询优化、数据类型存储引擎、锁机制、权限管理等方面,为读者提供一站式的数据处理和数据库管理知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GSP TBC高级技巧:效率飞跃的五大策略
# 摘要
本文旨在提升GSP TBC的效率,并从理论到实践对其进行全面概述。首先,介绍了GSP TBC的基本概念、原理及关键因素,奠定了理论基础。随后,阐述了策略设计的原则、步骤和案例分析,提供了实施GSP TBC的策略框架。在实践应用方面,本文详细讨论了实战策略的选择、应用和效果评估,以及优化技巧的原理、方法和案例。进阶技巧部分着重于数据分析和自动化的理论、方法和实践应用。最后,对未来GSP TBC的发展趋势和应用前景进行了探讨,提供了对行业发展的深度见解。整体而言,本文为GSP TBC的理论研究和实际应用提供了详实的指导和展望。
# 关键字
GSP TBC;效率提升;理论基础;实践应用;
【算法设计与数据结构】:李洪伟教授的课程复习与学习心得

# 摘要
本文对算法与数据结构进行了全面的概述和分析。首先介绍了基础数据结构,包括线性结构、树形结构和图结构,并探讨了它们的基本概念、操作原理及应用场景。随后,深入探讨了核心算法原理,包括排序与搜索、动态规划、贪心算法以及字符串处理算法,并对它们的效率和适用性进行了比较。文章还涉及了算法设计中的技巧与优化方法,重点在于算法复杂度分析、优化实践以及数学工具的应用。最后,通过案例分析和项目实践,展
【实用型】:新手入门到老手精通:一步到位的TI-LMP91000模块编程教程
# 摘要
本文系统介绍了TI-LMP91000模块的基础知识、硬件操作、编程基础以及高级应用。首先,文章对TI-LMP91000模块进行了基础介绍,并详细阐述了其硬件操作,包括硬件连接初始化、模拟信号输入输出处理以及数字接口的应用。接着,本文聚
【SUSE Linux系统优化】:新手必学的15个最佳实践和安全设置
# 摘要
本文详细探讨了SUSE Linux系统的优化方法,涵盖了从基础系统配置到高级性能调优的各个方面。首先,概述了系统优化的重要性,随后详细介绍了基础系统优化实践,包括软件包管理、系统升级、服务管理以及性能监控工具的应用。接着,深入到存储与文件系统的优化,讲解了磁盘分区、挂载点管理、文件系统调整以及LVM逻辑卷的创建与管理。文章还强调了网络性能和安全优化,探讨了网络配置、防火墙设置、
企业微信服务商营销技巧:提高用户粘性

# 摘要
随着移动互联网和社交平台的蓬勃发展,企业微信营销已成为企业数字化转型的重要途径。本文首先概述了企业微信营销的基本概念,继而深入分析了提升用户粘性的理论基础,包括用户粘性的定义、重要性、用户行为分析以及关键影响因素。第三章探讨了企业微信营销的实战技巧,重点介绍了内容营销、互动营销和数据分析在提升营销效果中的应用。第四章通过分析成功案例和常见问题,提供营销实践中的策略和解决方案。最后,第五章展望了技术创新和市场适应性对微信营销未来趋势的
UG Block开发进阶:掌握性能分析与资源优化的秘技

# 摘要
UG Block作为一种在UG软件中使用的功能模块,它的开发和应用是提高设计效率和质量的关键。本文从UG Block的基本概念出发,详述了其基础知识、创建、编辑及高级功能,并通过理论与实践相结合的方式,深入分析了UG Block在性能分析和资源优化方面的重要技巧
TIMESAT案例解析:如何快速定位并解决性能难题

# 摘要
本文从理论基础出发,详细探讨了性能问题定位的策略和实践。首先介绍了性能监控工具的使用技巧,包括传统与现代工具对比、性能指标识别、数据收集与分析方法。随后深入剖析 TIMESAT 工具,阐述其架构、工作原理及在性能监控中的应用。文章进一步讨论了性能优化的原则、实践经验和持续过程,最后通过综合案例实践,展示了如何应用 TIMESAT 进行性能问题分析、定位、优
低位交叉存储器深度探究:工作机制与逻辑细节

# 摘要
本文系统地介绍了低位交叉存储器的基本概念、工作原理、结构分析以及设计实践。首先阐述了低位交叉存储器的核心概念和工作原理,然后深入探讨了其物理结构、逻辑结构和性能参数。接着,文中详细说明了设计低位交叉存储器的考虑因素、步骤、流程、工具和方法。文章还通过多个应用案例,展示了低位交叉存储器在计算机系统、嵌入式系统以及服务器与存储设备中的实际应用。最后,
系统分析师必学:如何在30天内掌握单头线号检测

# 摘要
单头线号检测作为工业自动化领域的重要技术,对于确保产品质量、提高生产效率具有显著作用。本文首先概述了单头线号检测的概念、作用与应用场景,随后详细介绍了其关键技术和行业标准。通过对线号成像技术、识别算法以及线号数据库管理的深入分析,文章旨在为业界提供一套系统的实践操作指南。同时,本文还探讨了在实施单头线号检测过程中可能遇到的问题和相应的解决方案,并展望了大数据与机器学习在该领域的应用前景。文章最终通过行业成功案例
Flink1.12.2-CDH6.3.2容错机制精讲:细节与原理,确保系统稳定运行
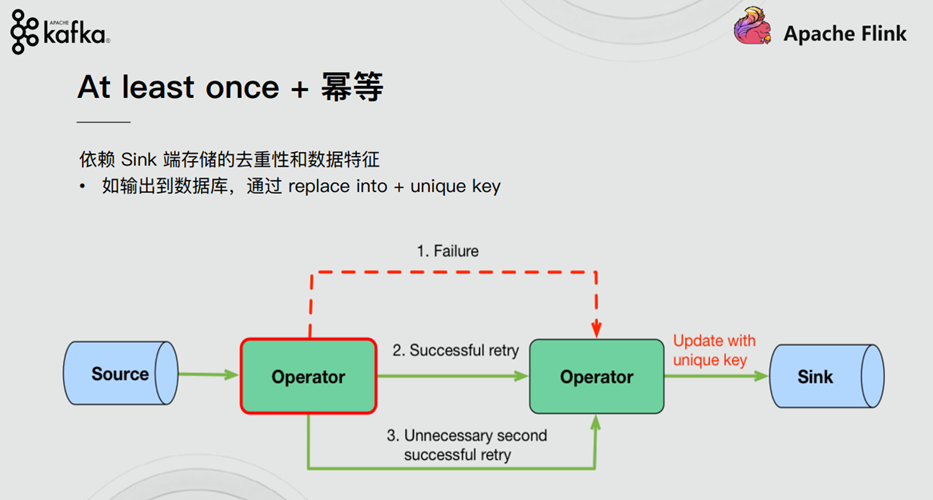
# 摘要
Flink容错机制是确保大规模分布式数据流处理系统稳定运行的关键技术。本文首先概述了Flink的容错机制,接着深入探讨了状态管理和检查点机制,包括状态的定义、分类、后端选择与配置以及检查点的原理和持久化策略。随后,文章分析了故障类型和恢复策略,提出了针对不同类型故障的自动与手动恢复流程,以及优化技术。在实践应用部分,本文展示了如何配置和优化检查点以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )