RDD概念与Spark数据处理
发布时间: 2024-02-29 06:15:48 阅读量: 49 订阅数: 43 

大数据spark学习之rdd概述
# 1. RDD简介
## 1.1 RDD的定义和背景
在Spark中,RDD(Resilient Distributed Datasets)是一个容错的、并行的数据结构,它能够用于跨集群节点进行数据处理。RDD是Spark中最基本的数据抽象,是一种可变的分布式集合,提供了一种高度优化的数据处理方式。
RDD的背景可以追溯至MapReduce,但相比之下,RDD提供了更加灵活和高效的数据处理模型。它可以跨多个操作进行流式计算,同时还能将数据缓存在内存中,以加快数据访问速度。RDD的引入极大地提升了数据处理的效率和性能。
## 1.2 RDD的特点和优势
RDD具有以下特点和优势:
- **容错性:** RDD能够通过记录其构建过程来实现容错,因此在节点出现故障时能够快速恢复。
- **数据可分性:** RDD能够将数据分割成多个分区,以便在集群中并行处理。
- **数据处理优化:** RDD支持数据处理操作的惰性求值和优化,能够在执行计算时进行优化。
- **内存计算:** RDD能够将数据持久化在内存中,从而实现更快的数据访问速度。
## 1.3 RDD的基本操作和数据流转模型
RDD支持两种类型的操作:**转换操作**和**行动操作**。转换操作指的是应用于RDD以产生新的RDD的操作,例如`map`、`filter`等;行动操作指的是将计算结果返回到驱动程序中,例如`collect`、`count`等。
数据流转模型指的是RDD通过转换操作进行数据处理,并最终触发行动操作以获取结果的整个执行过程。在这个过程中,Spark会构建RDD的有向无环图(DAG)来表示计算过程,从而实现数据流转和优化。
接下来我们将深入探讨RDD的创建方式及示例。
# 2. RDD的创建与转换
RDD的创建与转换是Spark中非常重要的操作,本章将介绍RDD的创建方式及示例、RDD的转换操作及其实际应用,以及RDD操作的惰性求值和转换优化。
### 2.1 RDD的创建方式及示例
在Spark中,有多种方式可以创建RDD,包括从内存中的集合中创建、从外部数据源加载等。下面是一些常用的创建RDD的方式示例:
#### 从内存中的集合创建RDD
```python
# 创建SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("create_rdd").getOrCreate()
# 从内存中的集合创建RDD
data = [1, 2, 3, 4, 5]
rdd = spark.sparkContext.parallelize(data)
rdd.collect()
```
#### 从外部数据源加载创建RDD
```python
# 从文本文件加载创建RDD
rdd = spark.sparkContext.textFile("file:///path/to/file.txt")
rdd.collect()
```
### 2.2 RDD的转换操作及其实际应用
RDD的转换操作是指对RDD进行各种操作,如map、filter、reduce等,以产生新的RDD。这些操作可以完成数据处理、筛选、统计等功能。下面是一些常见的RDD转换操作示例:
#### map操作示例--对RDD中每个元素都乘以2
```python
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])
result_rdd = rdd.map(lambda x: x * 2)
result_rdd.collect()
```
#### filter操作示例--筛选出RDD中大于3的元素
```python
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])
result_rdd = rdd.filter(lambda x: x > 3)
result_rdd.collect()
```
### 2.3 RDD操作的惰性求值和转换优化
在Spark中,RDD操作采用惰性求值的机制,即在遇到action操作前,转换操作并不会立即执行,而是等到需要计算结果时才会触发。这种机制可以优化计算过程,避免不必要的计算开销。同时,Spark也会对一些转换操作进行优化,提高计算性能。
在实际使用中,建议合理使用RDD操作的惰性求值特性和转换优化机制,以提高数据处理效率和性能。
以上是关于RDD的创建与转换的内容,希望对您有所帮助。接下来,我们将详细介绍RDD的持久化与分区。
# 3. RDD的持久化与分区
在这一章节中,我们将深入探讨RDD的持久化策略和机制,以及RDD分区的概念和分区策略,同时分析RDD分区与数据处理性能之间的关系。
#### 3.1 RDD的持久化策略和机制
在Spark中,RDD的持久化是指将RDD的计算结果缓存到内存或磁盘中,以便在需要重用RDD时能够更快地获取。Spark提供了多种持久化级别,包括MEMORY_ONLY、MEMORY_ONLY_SER、MEMORY_AND_DISK、MEMORY_AND_DISK_SER、DISK_ONLY等。开发者可以根据具体场景选择合适的持久化级别,来平衡内存和磁盘之间的存储开销和速度。
以下是一个简单的示例代码来展示RDD的持久化操作:
```python
from pyspark import SparkContext
# 创建SparkContext
sc = SparkContext("local", "persistence_example")
# 创建一个RDD
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 对RDD进行持久化到内存
rdd.persist()
# 对RDD进行一个action操作,触发持久化
result = rdd.reduce(lambda x, y: x + y)
# 手动解除持久化
rdd.unpersist()
# 关闭SparkContext
sc.stop()
```
在上面的示例中,我们使用`persist()`方法将RDD持久化到内存中,然后通过`reduce()`操作触发计算。最后使用`unpersist()`方法来手动解除持久化。
#### 3.2 RDD分区的概念和分区策略
RDD的分区是Spark中用于并行处理的基本单位,RDD中的数据会被划分为多个分区,每个分区可以在集群的不同节点上进行计算,实现并行处理。通常情况下,Spark会根据数据源的类型和默认分区规则来确定RDD的分区数,但开发者也可以手动指定分区数来优化计算性能。
以下是一个简单的示例代码来展示RDD分区的操作:
```python
from pyspark import SparkContext
# 创建SparkContext
sc = SparkContext("local", "partition_example")
# 创建一个RDD并指定2个分区
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data, numSlices=2)
# 获取RDD的分区数
num_partitions = rdd.getNumPartitions()
print("RDD的分区数为:", num_partitions)
# 关闭SparkContext
sc.stop()
```
在上面的示例中,我们使用`parallelize()`方法创建RDD时指定了2个分区,然后通过`getNumPartitions()`方法获取RDD的分区数。
#### 3.3 RDD分区与数据处理性能之间的关系
RDD的分区数对数据处理性能有着重要的影响,合理设置分区数可以提高作业的并行度,从而加快数据处理的速度。如果分区数过少,可能会导致任务在某些节点上处理的数据量过大,造成计算资源的浪费;如果分区数过多,可能会增加任务调度和数据传输的开销,降低计算性能。
因此,在实际应用中,开发者需要根据数据量大小、集群资源等因素来合理设置RDD的分区数,以达到最佳的性能表现。
# 4. Spark数据处理基础
在这一章节中,我们将深入了解Spark的数据处理基础知识,包括Spark的数据处理架构和组件、数据处理流程与原理,以及Spark数据处理在大数据场景中的优势和应用。让我们一起来探究Spark在数据处理领域的核心概念和技术。
#### 4.1 Spark的数据处理架构和组件
Spark是一个基于内存计算的快速、通用的集群计算系统,其数据处理架构包括以下主要组件:
1. **Spark Core**:Spark的核心组件,提供了RDD抽象和分布式任务调度功能。
2. **Spark SQL**:用于结构化数据处理的模块,支持SQL查询和DataFrame API。
3. **Spark Streaming**:用于实时数据流处理的组件,支持微批处理和事件驱动的处理方式。
4. **MLlib**:Spark的机器学习库,提供了各种常见机器学习算法的并行实现。
5. **GraphX**:用于图计算的库,支持图数据结构和图算法的高效计算。
6. **SparkR**:提供了在R语言中使用Spark的接口和功能。
#### 4.2 Spark的数据处理流程与原理
Spark的数据处理流程主要包括以下步骤:
1. **数据加载**:从数据源读取数据,可以是文件系统、数据库、Kafka等。
2. **数据转换**:对数据进行转换操作,可以使用map、filter、reduce等操作。
3. **数据计算**:执行数据处理的逻辑,如聚合、排序、过滤等。
4. **结果输出**:将结果数据写入外部存储或输出到终端。
在Spark中,数据处理的原理基于RDD的惰性求值和转换优化,通过创建RDD数据集进行数据处理,实现快速而高效的计算。
#### 4.3 Spark数据处理在大数据场景的优势和应用
Spark作为一个高性能的分布式计算框架,在大数据场景中具有以下优势:
- **快速计算**:通过内存计算和并行处理,实现快速的批处理和实时计算。
- **易扩展性**:支持横向扩展,能够处理PB级别的数据规模。
- **容错性**:通过RDD的弹性特性,能够在节点故障时进行数据恢复和重试。
- **多模块支持**:提供了丰富的模块和库支持,包括机器学习、图处理等。
Spark的数据处理应用广泛,涵盖了数据清洗、特征提取、模型训练等各个环节,被广泛应用于金融、电商、物联网等领域,为解决大数据处理问题提供了强大的工具和支持。
# 5. Spark数据处理高级操作
5.1 Spark的数据集和数据框架
Spark的数据集(Dataset)是一种新的抽象概念,它是强类型的API,允许用户以编程方式创建和操作分布式数据集。数据集提供了比RDD更丰富的功能,包括更丰富的数据结构和函数,以及更好的性能优化。同时,Spark的数据框架(DataFrame)也是一种基于数据集的高层抽象,它提供了类似于SQL的操作接口,可以方便地进行数据处理和分析。
5.2 Spark SQL与数据处理的集成
Spark SQL是Spark中用于结构化数据处理的模块,它提供了一种基于SQL的接口和内置的函数,可以方便地进行数据查询、分析和处理。通过Spark SQL,用户可以将结构化数据直接导入到Spark中进行处理,也可以将处理结果直接导出到外部系统中。同时,Spark SQL还支持常见的关系型数据库连接,可以与外部数据源进行交互。
5.3 Spark Streaming与实时数据处理
Spark Streaming是Spark中用于实时数据处理的组件,它可以以微批处理的方式处理实时数据流,从Kafka、Flume等数据源中实时获取数据,并进行实时的数据处理和分析。Spark Streaming提供了丰富的数据转换和窗口操作,可以方便地处理实时数据,并且与Spark核心API无缝集成,可以使用相同的代码逻辑进行批处理和实时处理。
以上是关于Spark数据处理高级操作的概述,后续将会详细介绍各个方面的实际操作和应用场景。
# 6. 实例应用与最佳实践
在本章中,我们将深入探讨基于RDD和Spark的数据处理流程的实际案例分析,解决数据处理中常见的问题,并总结数据处理中的最佳实践和经验。
#### 6.1 实际案例分析:基于RDD和Spark的数据处理流程
在这一部分,我们将介绍一个实际的数据处理案例,展示如何使用RDD和Spark来处理数据并提取有用信息。
```python
# 导入SparkContext
from pyspark import SparkContext
# 创建SparkContext
sc = SparkContext("local", "DataProcessingApp")
# 读取数据文件
data_rdd = sc.textFile("data.txt")
# 对数据进行处理
result_rdd = data_rdd.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
.sortBy(lambda x: x[1], ascending=False)
# 输出处理结果
for word, count in result_rdd.collect():
print(f"单词 '{word}' 出现的次数为: {count}")
# 停止SparkContext
sc.stop()
```
**代码总结:**
1. 通过SparkContext读取数据文件并创建RDD。
2. 使用flatMap和map操作对数据进行处理,将单词拆分为键值对并统计数量。
3. 使用reduceByKey合并相同单词的数量,并按数量降序排序。
4. 最后打印每个单词的出现次数。
**结果说明:**
处理后的数据将按照单词出现的次数进行降序排列,并输出每个单词的出现次数。
#### 6.2 数据处理中常见的问题和解决方案
在实际数据处理中,常常会遇到数据丢失、处理速度慢等问题,针对这些问题我们可以采取一些解决方案:
1. 数据丢失:可以采用数据备份、数据恢复等方案来防止数据丢失。
2. 处理速度慢:可以对RDD进行合理的持久化、调整分区数等优化操作来提高数据处理速度。
#### 6.3 数据处理中的最佳实践与经验总结
在数据处理中的最佳实践包括:
1. 合理选择合适的数据结构,如RDD、DataFrame等。
2. 尽量使用内置的优化方法,如使用“map”代替“foreach”等。
3. 针对具体场景进行优化,避免不必要的计算。
在经验总结方面,经常进行数据处理实践是最好的积累经验的方式,不断总结和改进处理方案,才能更好地应对各种数据处理问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单高级应用

# 摘要
扇形菜单作为一种创新的用户界面设计方式,近年来在多个应用领域中显示出其独特优势。本文概述了扇形菜单设计的基本概念和理论基础,深入探讨了其用户交互设计原则和布局算法,并介绍了其在移动端、Web应用和数据可视化中的应用案例
C++ Builder高级特性揭秘:探索模板、STL与泛型编程

# 摘要
本文系统性地介绍了C++ Builder的开发环境设置、模板编程、标准模板库(STL)以及泛型编程的实践与技巧。首先,文章提供了C++ Builder的简介和开发环境的配置指导。接着,深入探讨了C++模板编程的基础知识和高级特性,包括模板的特化、非类型模板参数以及模板
【深入PID调节器】:掌握自动控制原理,实现系统性能最大化

# 摘要
PID调节器是一种广泛应用于工业控制系统中的反馈控制器,它通过比例(P)、积分(I)和微分(D)三种控制作用的组合来调节系统的输出,以实现对被控对象的精确控制。本文详细阐述了PID调节器的概念、组成以及工作原理,并深入探讨了PID参数调整的多种方法和技巧。通过应用实例分析,本文展示了PID调节器在工业过程控制中的实际应用,并讨
【Delphi进阶高手】:动态更新百分比进度条的5个最佳实践

# 摘要
本文针对动态更新进度条在软件开发中的应用进行了深入研究。首先,概述了进度条的基础知识,然后详细分析了在Delphi环境下进度条组件的实现原理、动态更新机制以及多线程同步技术。进一步,文章探讨了数据处理、用户界面响应性优化和状态视觉呈现的实践技巧,并提出了进度
【TongWeb7架构深度剖析】:架构原理与组件功能全面详解
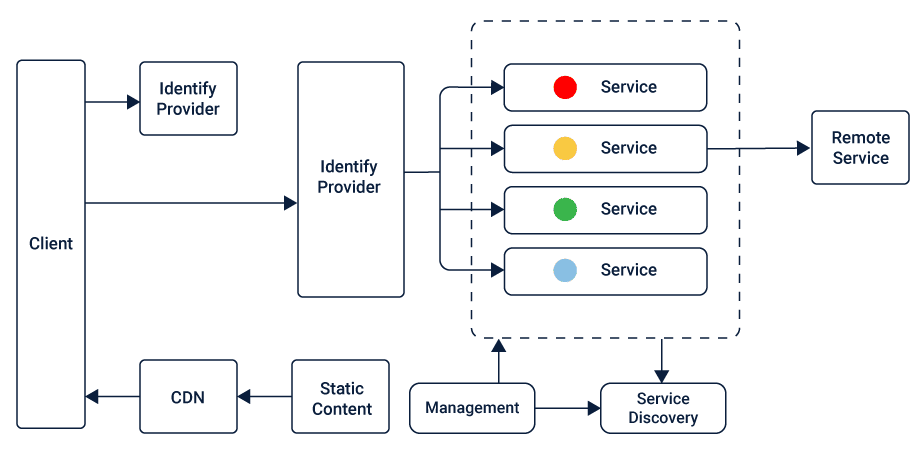
# 摘要
TongWeb7作为一个复杂的网络应用服务器,其架构设计、核心组件解析、性能优化、安全性机制以及扩展性讨论是本文的主要内容。本文首先对TongWeb7的架构进行了概述,然后详细分析了其核心中间件组件的功能与特点,接着探讨了如何优化性能监控与分析、负载均衡、缓存策略等方面,以及安全性机制中的认证授权、数据加密和安全策略实施。最后,本文展望
【S参数秘籍解锁】:掌握驻波比与S参数的终极关系
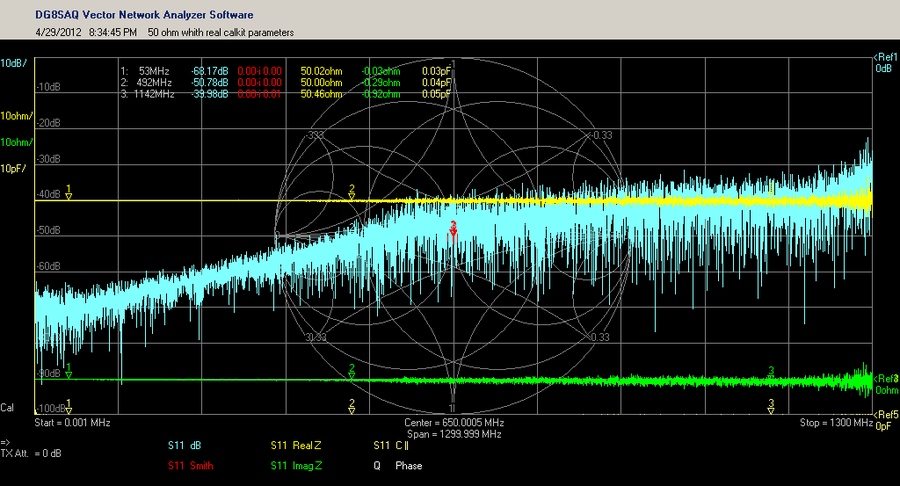
# 摘要
本论文详细阐述了驻波比与S参数的基础理论及其在微波网络中的应用,深入解析了S参数的物理意义、特性、计算方法以及在电路设计中的实践应用。通过分析S参数矩阵的构建原理、测量技术及仿真验证,探讨了S参数在放大器、滤波器设计及阻抗匹配中的重要性。同时,本文还介绍了驻波比的测量、优化策略及其与S参数的互动关系。最后,论文探讨了S参数分析工具的使用、高级分析技巧,并展望
【嵌入式系统功耗优化】:JESD209-5B的终极应用技巧
# 摘要
本文首先概述了嵌入式系统功耗优化的基本情况,随后深入解析了JESD209-5B标准,重点探讨了该标准的框架、核心规范、低功耗技术及实现细节。接着,本文奠定了功耗优化的理论基础,包括功耗的来源、分类、测量技术以及系统级功耗优化理论。进一步,本文通过实践案例深入分析了针对JESD209-5B标准的硬件和软件优化实践,以及不同应用场景下的功耗优化分析。最后,展望了未来嵌入式系统功耗优化的趋势,包括新兴技术的应用、JESD209-5B标准的发展以及绿色计算与可持续发展的结合,探讨了这些因素如何对未来的功耗优化技术产生影响。
# 关键字
嵌入式系统;功耗优化;JESD209-5B标准;低功耗
ODU flex接口的全面解析:如何在现代网络中最大化其潜力
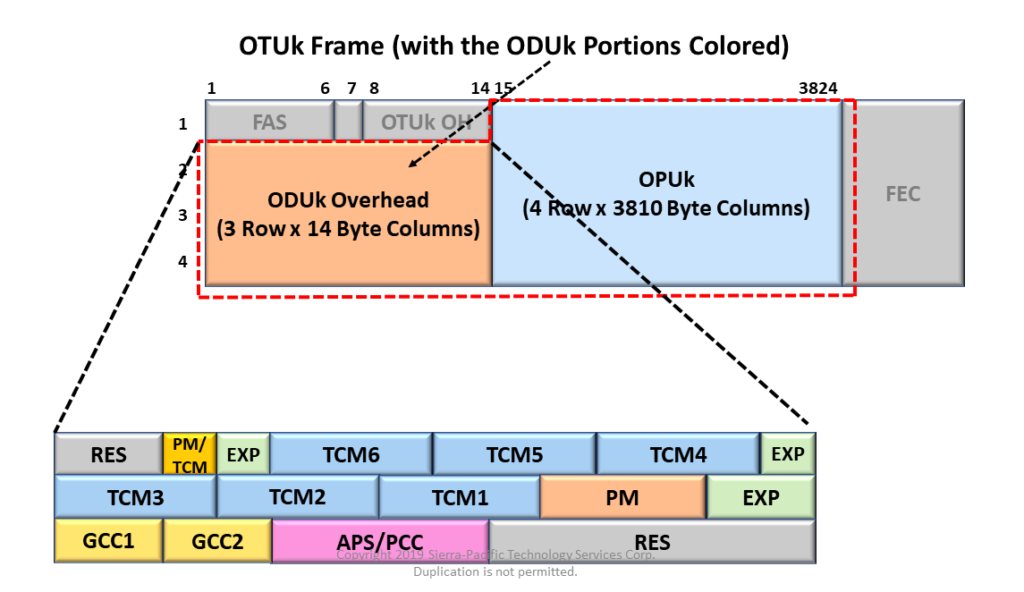
# 摘要
ODU flex接口作为一种高度灵活且可扩展的光传输技术,已经成为现代网络架构优化和电信网络升级的重要组成部分。本文首先概述了ODU flex接口的基本概念和物理层特征,紧接着深入分析了其协议栈和同步机制,揭示了其在数据中心、电信网络、广域网及光纤网络中的应用优势和性能特点。文章进一步
如何最大化先锋SC-LX59的潜力
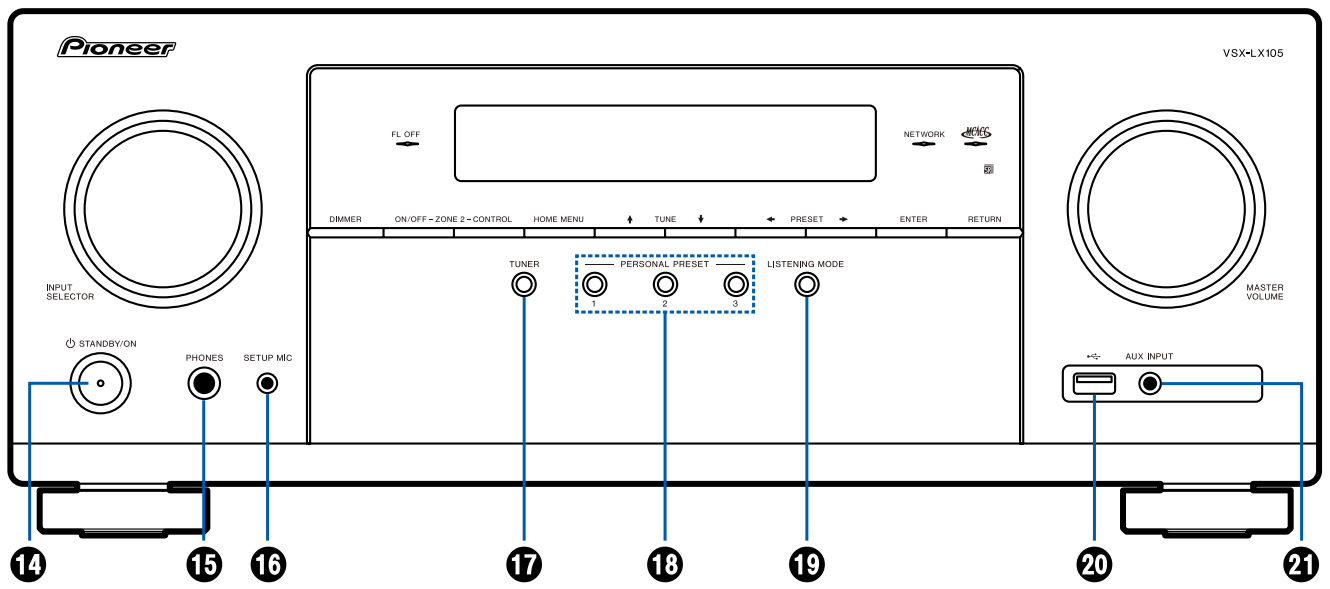
# 摘要
先锋SC-LX59作为一款高端家庭影院接收器,其在音视频性能、用户体验、网络功能和扩展性方面均展现出巨大的潜力。本文首先概述了SC-LX59的基本特点和市场潜力,随后深入探讨了其设置与配置的最佳实践,包括用户界面的个性化和音画效果的调整,连接选项与设备兼容性,以及系统性能的调校。第三章着重于先锋SC-LX59在家庭影院中的应用,特别强调了音视频极致体验、智能家居集成和流媒体服务的充分利用。在高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )