Kafka消息队列在大数据处理中的作用
发布时间: 2024-02-29 06:20:49 阅读量: 51 订阅数: 42 
# 1. Kafka消息队列的基础概念
## 1.1 什么是Kafka消息队列
Kafka是一种分布式流处理平台,最初由LinkedIn开发,后捐赠给Apache软件基金会。它是一种高吞吐量的分布式发布订阅消息系统,具备持久化的消息特性。Kafka主要基于发布订阅模式,将消息以一种高效、高可靠的方式进行存储和传输。
Kafka消息队列由若干台服务器组成,每台服务器称为一个Broker。消息通过Producer发送到Kafka集群,然后由Consumer来消费处理。在Kafka中,每条消息都有一个时间戳,消息是以topic进行分类,生产者将消息发布到topic,同时消费者根据topic订阅并消费消息。
## 1.2 Kafka消息队列的优势和特点
Kafka消息队列具有以下优势和特点:
- **高吞吐量**:Kafka能够处理非常高的数据吞吐量,适合大数据处理和实时分析。
- **水平扩展**:Kafka集群可以方便地进行水平扩展,以适应不断增长的数据量和访问需求。
- **持久性**:Kafka中的消息是持久化存储的,即使消费者处理消息失败,消息仍然不会丢失。
- **低延迟**:Kafka能够以很低的延迟传输消息,满足实时处理的需求。
- **容错性**:Kafka集群具备高度容错性,即使某个节点故障,仍能保证消息的可靠处理。
## 1.3 Kafka在大数据处理中的应用场景
Kafka在大数据处理中拥有广泛的应用场景,主要包括:
- **日志收集与传输**:Kafka能够快速稳定地传输大量日志数据,适合日志收集和分析场景。
- **实时数据处理**:Kafka可以作为实时数据流处理的基础组件,与Apache Storm、Apache Flink等实时处理框架集成,用于构建实时数据处理系统。
- **事件驱动架构**:Kafka支持事件驱动架构,能够构建微服务、大规模数据同步等场景。
- **行为跟踪**:Kafka能够用于跟踪用户行为,例如用户点击、浏览等行为的记录和分析。
在接下来的章节中,我们将深入探讨Kafka消息队列的架构和工作原理,帮助读者更加全面地了解Kafka在大数据处理中的重要性和作用。
# 2. Kafka消息队列的架构和工作原理
Kafka作为一个分布式流处理平台,具有高可靠性、可伸缩性和持久性,它的架构和工作原理对于理解Kafka在大数据处理中的作用至关重要。
### 2.1 Kafka的架构介绍
Kafka的架构可以分为以下几个核心组件:
- Broker:Kafka集群中的每个服务器节点称为Broker,负责消息的存储和转发。
- Topic:消息的类别,每个消息都属于一个特定的Topic。
- Partition:每个Topic可以分为多个Partition,Partition在物理上对应于一个目录,包含若干个日志段文件。
- Producer:生产者,向Kafka Broker发布消息的客户端应用。
- Consumer:消费者,从Kafka Broker订阅消息的客户端应用。
### 2.2 Kafka消息队列如何保证高可靠性和高扩展性
Kafka如何保证高可靠性和高扩展性主要有以下几个优点:
- Replication:Kafka通过副本机制实现数据的高可靠性,每个Partition都有多个副本,并且分布在不同的Broker上,当Broker失效时,可以从其他副本中恢复数据。
- 分布式架构:Kafka集群是一个分布式系统,可以方便地进行水平扩展,通过增加Broker节点来提高消息吞吐量和存储容量。
- 无状态:Kafka Broker本身是无状态的,所有的消息都持久化到磁盘中,因此可以方便地进行横向扩展。
### 2.3 Kafka消息队列的工作原理和消息传递流程
Kafka消息队列的工作原理主要包括生产者发送消息、消息存储和消费者订阅消息三个过程:
1. 生产者发送消息:生产者将消息发布到特定的Topic中,Kafka根据消息的key进行Partition,然后将消息发送到对应的Partition中。
2. 消息存储:消息以日志形式持久化到磁盘上,每个Partition对应一个日志文件,消息在日志文件中的偏移量(offset)作为唯一标识。
3. 消费者订阅消息:消费者通过订阅Topic来获取消息,Kafka会将消息推送给消费者,并且保证消息的顺序性和至少一次传递。
以上是Kafka消息队列的架构和工作原理介绍,了解这些核心概念对于后续深入学习和实际应用Kafka非常重要。
# 3. Kafka在大数据处理中的角色和重要性
Apache Kafka作为一款分布式流处理平台,在大数据处理中扮演着重要的角色。本章将深入探讨Kafka在大数据处理中的作用和地位,以及它如何与大数据技术(如Hadoop、Spark等)集成,并对几个具体的应用案例进行分析。
#### 3.1 Kafka在大数据处理中的作用和地位
Kafka作为一个分布式、可水平扩展、高吞吐量的消息队列系统,具有以下几个重要作用和地位:
- **数据收集和汇总**:在大数据处理中,各种数据源产生的海量数据需要被收集和汇总,Kafka作为一个高吞吐量的消息队列,可以快速接收、存储和分发数据。
- **数据缓冲**:对于实时流处理或批处理系统,Kafka可以作为数据的缓冲区,允许数据生产者和数据消费者在系统不同部分之间进行解耦和协调。
- **数据同步和削峰填谷**:Kafka可以将数据从一个数据中心传输到另一个数据中心,或者在多个数据中心之间同步数据,同时能够有效地应对高峰时段的数据压力。
- **消息传递和通信桥梁**:Kafka作为通信桥梁,可在不同的数据处理系统之间进行消息传递,并保障消息的可靠性和顺序性。
#### 3.2 Kafka如何与大数据技术(如Hadoop、Spark等)集成
Kafka与大数据生态系统中的Hadoop、Spark等技术集成紧密,这些集成为大数据处理提供了更灵活和高效的解决方案:
- **与Hadoop集成**:Kafka可以作为Hadoop生态系统中数据收集和交换的中间层。通过Kafka Connect,可以轻松地将Kafka与Hadoop生态系统集成,实现数据的实时传输和同步。
- **与Spark集成**:Kafka和Spark Streaming天生就是一对完美的组合。Spark可以直接从Kafka的topic中读取数据,并进行实时流处理和分析,快速响应数据的变化。
#### 3.3 大数据处理中Kafka的应用案例分析
下面通过一个实际的场景来展示Kafka在大数据处理中的应用案例:
##### 场景描述
假设我们需要构建一个大数据分析系统,用于分析用户行为数据,并实时生成用户画像。用户行为数据以日志的形式不断产生,需要被采集、存储、处理并进行实时分析。
##### 代码示例
```java
// 生产者将用户行为数据发送至Kafka的topic
KafkaProducer<String, String> producer = createProducer();
producer.send(new ProducerRecord<>("user_behavior_topic", "user01", "click_event"));
// Spark Streaming从Kafka的topic中读取数据,进行实时分析
JavaPairInputDStream<String, String> kafkaStream = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topicsSet
);
kafkaStream.foreachRDD(rdd -> {
// 实时生成用户画像并存储到数据库
rdd.foreach(record -> generateUserProfile(record._1(), record._2()));
});
```
##### 代码说明
通过Kafka Producer将用户行为数据发送至Kafka的topic,然后通过Spark Streaming从该topic中读取数据进行实时分析,最终将用户画像数据存储到数据库中。
##### 结果说明
通过Kafka在大数据处理中的应用,我们实现了用户行为数据的实时分析和用户画像的生成,大大提高了数据处理的实时性和可靠性。
#### 结论
综上所述,Kafka在大数据处理中扮演着至关重要的角色,能够高效地处理数据流,保证数据的可靠传输和实时处理,同时与大数据生态系统良好集成,为大数据处理提供了便利和高效率。
通过以上案例的介绍和分析,我们更深刻地理解了Kafka在大数据处理中的重要性和实际应用,对于读者来说也能更直观地理解Kafka在大数据处理中的实际应用场景和效果。
# 4. Kafka消息队列的性能优化和调优
Kafka消息队列的性能优化和调优对于大数据处理系统至关重要。在这一章节中,我们将深入探讨如何设计高性能的Kafka消息队列系统,分析Kafka消息队列的性能瓶颈和问题,并介绍在大数据处理中如何进行实时性和可靠性优化的方法。
#### 4.1 如何设计高性能的Kafka消息队列系统
在设计高性能的Kafka消息队列系统时,需要考虑以下几个关键要素:
##### 4.1.1 分区和副本的合理设计
- 合理设计分区数量和副本数量,以提高系统的并发性和容错性。
- 根据业务特点和数据量大小,动态调整分区和副本的数量。
```java
// 示例代码:创建topic时指定分区和副本数
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 8 --topic my_topic
```
总结:合理设计分区和副本数可以提升Kafka消息队列系统的吞吐量和容错能力。
##### 4.1.2 生产者和消费者的优化
- 使用批量发送和拉取方式,减少网络开销,提高吞吐量。
- 合理配置生产者和消费者的缓冲区大小。
```java
// 示例代码:配置Kafka生产者的批量发送和缓冲区大小
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
```
总结:优化生产者和消费者的配置可以有效提升Kafka消息队列的性能和效率。
#### 4.2 Kafka消息队列的性能瓶颈和问题分析
在实际应用中,Kafka消息队列可能会遇到以下性能瓶颈和问题:
- 网络延迟:网络通信的延迟对Kafka消息的传输速度有直接影响。
- 硬件资源:磁盘IO、CPU和内存资源的瓶颈会影响Kafka的性能表现。
- 配置参数:未合理配置Kafka的参数也会导致性能下降。
#### 4.3 Kafka消息队列在大数据处理中的实时性和可靠性优化
为了提高Kafka在大数据处理中的实时性和可靠性,我们可以采取以下优化措施:
##### 4.3.1 数据分区和预热
- 合理划分数据分区,进行数据预热,提高数据访问的速度。
- 使用数据分片技术,提高实时数据处理的效率。
##### 4.3.2 数据压缩和索引
- 对Kafka中的数据进行压缩和索引,减小数据体积,提高数据传输效率。
##### 4.3.3 数据复制和备份
- 合理配置数据的复制和备份策略,确保数据的可靠性和容灾能力。
以上优化措施可以有效提升Kafka消息队列在大数据处理中的实时性和可靠性,从而更好地满足大数据处理系统的需求。
# 5. Kafka消息队列的监控和运维
Kafka消息队列作为大数据处理中的重要组件,在实际生产环境中需要进行监控和运维。本章将深入探讨Kafka消息队列的监控和运维的相关内容,包括监控方法、常见问题处理以及运维经验分享。
#### 5.1 如何进行Kafka消息队列的监控和性能调优
在实际应用中,我们需要对Kafka消息队列进行监控,以确保其稳定运行并发现潜在问题。在监控Kafka时,我们可以利用以下方法:
##### 5.1.1 使用JMX进行监控
Java Management Extensions (JMX) 是 Java 平台上的一套管理和监控规范。Kafka提供了丰富的JMX指标,可以通过JConsole、JVisualVM等工具进行监控,包括各个Broker节点的消息处理速度、存储情况、连接数等信息。
```java
// Java代码示例:使用JMX监控Kafka
import javax.management.MBeanServerConnection;
import javax.management.ObjectName;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
public class KafkaJMXMonitor {
public static void main(String[] args) {
try {
JMXServiceURL url = new JMXServiceURL("service:jmx:rmi:///jndi/rmi://<broker-host>:<jmx-port>/jmxrmi");
JMXConnector jmxc = JMXConnectorFactory.connect(url, null);
MBeanServerConnection mbsc = jmxc.getMBeanServerConnection();
ObjectName objectName = new ObjectName("kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec");
Object messagesPerSec = mbsc.getAttribute(objectName, "OneMinuteRate");
System.out.println("Messages In Per Second: " + messagesPerSec);
jmxc.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
##### 5.1.2 使用Kafka自带工具进行监控
Kafka自带了一些用于监控的工具,比如Kafka Manager、Kafka Tool等,可以通过这些工具进行topic、partition的监控和管理,以及查看消费者组、偏移量等状态。
```bash
# 使用Kafka Manager进行监控
./kafka-manager #启动Kafka Manager服务
```
#### 5.2 Kafka消息队列的常见问题和故障处理
在实际运维过程中,Kafka可能会遇到各种问题和故障,比如磁盘空间不足、消息堆积、ZooKeeper连接问题等。针对这些常见问题,我们需要及时诊断并解决。
##### 5.2.1 磁盘空间不足
当Kafka Broker节点的磁盘空间不足时,会影响消息的写入和读取,甚至导致服务不可用。解决方法包括扩展磁盘容量、删除过期数据、调整日志保留策略等。
```bash
# 清理过期日志
./kafka-topics.sh --zookeeper <zookeeper-host>:<zookeeper-port> --alter --topic <topic-name> --config retention.ms=3600000
```
##### 5.2.2 消息堆积
消息堆积可能是由于消费者处理能力不足、网络故障等原因引起的。我们可以通过监控工具查看消费者组的消费速度和偏移量,及时调整消费者数量以及处理能力。
```bash
# 查看消费者组偏移量
./kafka-consumer-groups.sh --bootstrap-server <broker-host>:<broker-port> --describe --group <group-id>
```
#### 5.3 Kafka消息队列的运维和管理经验分享
在运维Kafka过程中,积累了一些经验和技巧,包括定期备份、故障切换、紧急修复等方面的经验,以下是一些建议:
- 定期备份Kafka配置文件、日志和相关数据
- 设置监控报警机制,对关键指标进行实时监控
- 实施合理的故障切换和紧急修复方案
通过以上经验分享,可以更好地保障Kafka消息队列的稳定运行和高可靠性。
以上是Kafka消息队列的监控和运维相关内容,通过对监控方法、常见问题处理以及运维经验的探讨,读者可以更好地理解如何进行Kafka消息队列的监控和运维工作。
# 6. 未来Kafka消息队列在大数据处理中的发展
大数据处理领域一直在不断发展和演进,Kafka作为一个高性能的分布式消息队列系统,在大数据处理中扮演着越来越重要的角色。未来,Kafka消息队列将会面临更多的挑战和机遇,在以下几个方面有着更多的发展空间:
#### 6.1 Kafka消息队列的未来发展趋势和方向
随着大数据处理的不断深入,对消息队列系统的需求也日益增加,未来Kafka消息队列将朝着以下方向发展:
- 更加智能化的管理和调度:Kafka消息队列将会加强自身的智能化管理能力,提供更加智能的调度和资源管理,以应对日益复杂的大数据处理场景。
- 更强的实时性和可靠性:随着实时数据处理的需求不断增加,Kafka将持续优化自身的消息传递性能,并进一步提升可靠性,确保数据能够被高效地实时处理。
- 更紧密的云原生集成:随着云原生技术的兴起,Kafka将更加紧密地与云原生架构集成,提供更加灵活和高效的部署方式,进一步降低使用门槛。
#### 6.2 Kafka与新兴技术(如人工智能、物联网等)的结合
随着人工智能、物联网等新兴技术的快速发展,Kafka消息队列将会与这些新兴技术更加紧密地结合,为其提供高效的数据传输和处理能力。
- 在人工智能领域,Kafka消息队列可以作为实时数据传输和处理的重要基础设施,为机器学习模型的训练和推理提供高效的数据支持。
- 在物联网领域,Kafka消息队列可以扮演着物联网设备数据传输和处理的关键角色,为大规模物联网数据的管理和分析提供可靠的消息中间件支持。
#### 6.3 大数据处理中Kafka的创新应用和前景展望
除了传统的大数据处理场景,Kafka消息队列在一些新兴的领域也有着广阔的应用前景和创新空间。
- 在边缘计算领域,随着边缘计算的快速发展,Kafka消息队列可以成为边缘设备数据传输和处理的重要基础设施,支持边缘端和云端的高效数据通信。
- 在区块链技术中,Kafka消息队列可以为区块链网络提供高效的数据传输和共识机制,为区块链系统的可扩展性和性能提供支持。
总的来说,Kafka消息队列所面临的挑战和机遇都是前所未有的,随着大数据处理领域的不断发展,Kafka将会不断演进和完善,为大数据处理提供更加稳定可靠的消息传递和处理能力,助力各行业更好地应对未来的数据处理挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32固件升级注意事项:如何避免版本不兼容导致的问题
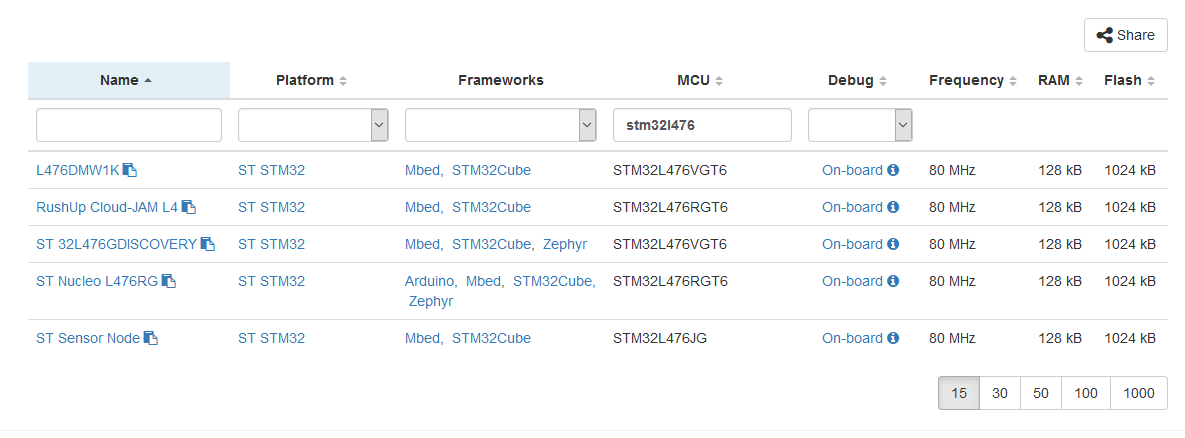
# 摘要
本文全面探讨了STM32固件升级的过程及其相关问题。首先概述了固件升级的重要性和准备工作,包括风险评估和所需工具与资源的准备。随后深入分析了固件升级的理论基础,包括通信协议的选择和存储管理策略。文章进一步提供了实用技巧,以避免升级中的版本不兼容问题,并详述了升级流程的实施细节。针对升级过程中可能出现的问题
锂电池保护板DIY攻略:轻松制作与调试手册
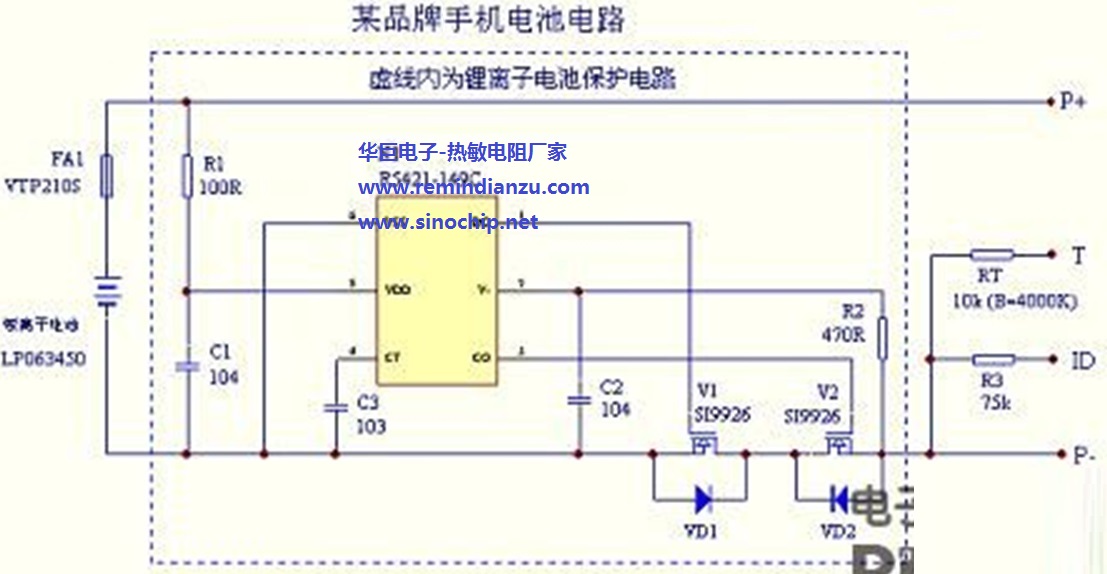
# 摘要
本论文系统性地介绍了锂电池保护板的基本知识、硬件设计、软件编程、组装与测试以及进阶应用。第一章对保护板的基础知识进行了概述,第二章详细讨论了保护板的硬件设计,包括元件选择、电路设计原则、电路图解析以及PCB布局与走线技巧。第三章则聚焦于保护板软件编程的环境搭建、编程实践和调试优化。组装与测试的环节在第四章中被详尽解释,包括组装步骤、初步测试和安全性测试。最后一章探讨了锂电池保护板在智能保护功能拓展、定制化开发以及案例研究
复变函数的视觉奇迹:Matlab三维图形绘制秘籍
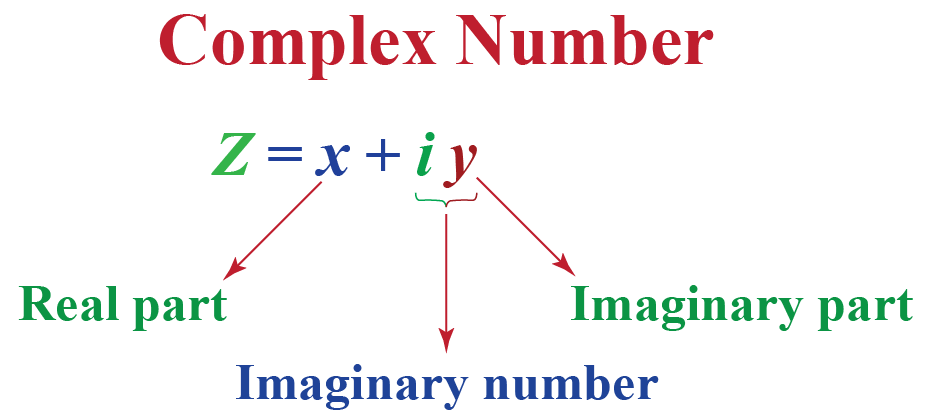
# 摘要
本文探讨了复变函数理论与Matlab软件在三维图形绘制领域的应用。首先介绍复变函数与Matlab的基础知识,然后重点介绍Matlab中三维图形的绘制技术,包括三维图形对象的创建、旋转和平移,以及复杂图形的生成和光照着色。文中还通过可视化案例分析,详细讲解了复变函数的三维映射和特定领域的可视化表现,以及在实际工程问题中的应用
【OSA案例研究】:TOAS耦合测试在多场景下的应用与分析

# 摘要
TOAS耦合测试是一种新兴的软件测试方法,旨在解决复杂系统中组件或服务间交互所产生的问题。本文首先介绍了TOAS耦合测试的理论框架,包括其基本概念、测试模型及其方法论。随后,文章深入探讨了
CSS预处理器终极对决:Sass vs LESS vs Stylus,谁主沉浮?

# 摘要
CSS预处理器作为提高前端开发效率和样式表可维护性的工具,已被广泛应用于现代网页设计中。本文首先解析了CSS预处理器的基本概念,随后详细探讨了Sass、LESS和Stylus三种主流预处理器的语法特性、核心功能及实际应用。通过深入分析各自的
CMW500信令测试深度应用:信号强度与质量优化的黄金法则

# 摘要
本文详细介绍了CMW500信令测试仪在无线通信领域的应用,涵盖了信号强度、信号质量和高级应用等方面。首先,本文阐述了信号强度的基本理论和测试方法,强调了信号衰落和干扰的识别及优化策略的重要性。接着,深入探讨了信号质量的关键指标和管理技术,以及如何通过优化网络覆盖和维护提升信号质量。此外,还介绍了CMW500在信令分析、故障排除和信号传输性能测试
高速FPGA信号完整性解决方案:彻底解决信号问题
# 摘要
本文综述了FPGA(现场可编程门阵列)信号完整性问题的理论基础、实践策略以及分析工具。首先概述了信号完整性的重要性,并探讨了影响信号完整性的关键因素,包括电气特性和高速设计中的硬件与固件措施。接着,文章介绍了常用的信号完整性分析工具和仿真方法,强调了工具选择和结果分析的重要性。案例研究部分深入分析了高速FPGA设计中遇到的信号完整性问题及解决
协同创新:“鱼香肉丝”包与其他ROS工具的整合应用
# 摘要
本文全面介绍了协同创新的基础与ROS(Robot Operating System)的深入应用。首先概述了ROS的核心概念、结构以及开发环境搭建过程。随后,详细解析了“鱼香肉丝”包的功能及其在ROS环境下的集成和实践,重点讨论了
CPCI标准2.0中文版嵌入式系统应用详解

# 摘要
CPCI(CompactPCI)标准2.0作为一种高性能、模块化的计算机总线标准,广泛应用于工业自动化、军事通信以及医疗设备等嵌入式系统中。本文全面概述了CPCI标准2.0的硬件架构和软件开发,包括硬件的基本组成、信号协议、热插拔机制,以及嵌入式Linux和RTOS的部署和应用。通过案例分析,探讨了CPCI在不同领域的应用情况和挑战。最后,展望了CPCI技术的发展趋势,包括高速总线技术、模块化设计、以及与物联网、AI技术的融合前景,强调了CPCI在国际化和标准化进程中的重要性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )