自然语言处理在爬虫中的作用:理解文本内容
发布时间: 2024-04-24 18:31:12 阅读量: 17 订阅数: 43 
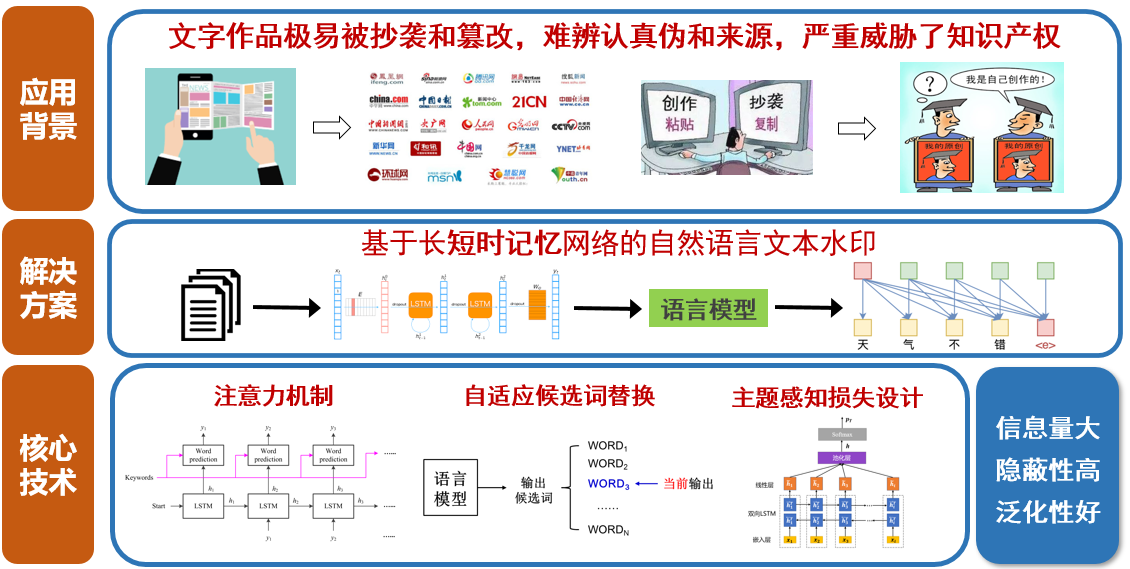
# 1. 自然语言处理简介**
自然语言处理(NLP)是一门计算机科学领域,专注于让计算机理解、解释和生成人类语言。它涉及一系列技术,包括文本解析、信息提取、情感分析和语言生成。NLP 在广泛的应用中发挥着至关重要的作用,包括爬虫、机器翻译和聊天机器人。
# 2. 自然语言处理在爬虫中的应用
自然语言处理(NLP)技术在爬虫领域发挥着至关重要的作用,它可以赋予爬虫理解和处理文本数据的强大能力。通过利用 NLP 技术,爬虫能够从非结构化文本中提取有价值的信息,从而提高爬取效率和数据质量。
### 2.1 文本解析和信息提取
文本解析和信息提取是 NLP 在爬虫中的核心应用之一。通过对文本进行分词、词性标注、命名实体识别、文本分类和聚类等处理,爬虫可以将非结构化的文本数据转换为结构化的信息。
#### 2.1.1 分词和词性标注
分词是将文本拆分为单词或词组的过程,而词性标注是为每个单词或词组分配词性(如名词、动词、形容词等)。这些技术对于理解文本的含义和提取有价值的信息至关重要。
```python
import nltk
# 分词
text = "自然语言处理在爬虫中的应用"
tokens = nltk.word_tokenize(text)
print(tokens)
# 词性标注
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)
```
**代码逻辑分析:**
* `nltk.word_tokenize()` 函数将文本拆分为单词或词组,并返回一个单词列表。
* `nltk.pos_tag()` 函数为每个单词或词组分配词性,并返回一个带词性的单词列表。
#### 2.1.2 命名实体识别
命名实体识别(NER)是一种 NLP 技术,用于识别文本中的命名实体,如人名、地名、组织名等。NER 对于从文本中提取结构化信息非常有用。
```python
import spacy
# 加载 spaCy 模型
nlp = spacy.load("en_core_web_sm")
# 命名实体识别
text = "Barack Obama, the former president of the United States, visited China in 2016."
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
```
**代码逻辑分析:**
* `spacy.load()` 函数加载 spaCy 模型,用于进行 NLP 处理。
* `nlp(text)` 函数将文本解析为 spaCy 文档对象。
* `doc.ents` 属性包含文本中识别的命名实体,每个命名实体都有一个 `text` 属性(表示实体文本)和一个 `label_` 属性(表示实体类型)。
#### 2.1.3 文本分类和聚类
文本分类和聚类是将文本分配到预定义类别或组的过程。这些技术可以帮助爬虫对爬取的文本数据进行组织和分类。
```python
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.cluster import KMeans
# 文本分类
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(["自然语言处理", "爬虫", "机器学习"])
y = [0, 1, 2]
classifier = MultinomialNB()
classifier.fit(X, y)
# 文本聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
```
**代码逻辑分析:**
* `CountVectorizer` 将文本转换为词频矩阵,其中每个单词或词组是一个特征。
* `MultinomialNB` 是一个朴素贝叶斯分类器,用于将文本分类到预定义的类别。
* `KMeans` 是一个聚类算法,用于将文本聚类到不同的组。
# 3.1 基于Python的自然语言处理库
#### 3.1.1 NLTK
NLTK(Natural Language Toolkit)是一个广泛使用的Python自然语言处理库,提供了一系列功能,包括:
- **分词和词性标注:**将文本分割成单词并标记它们的词性(例如,名词、动词、形容词)。
- **命名实体识别:**识别文本中的命名实体,例如人名、地名和组织。
- **文本分类:**将文本分类到预定义的类别中,例如新闻、体育或科技。
- **情感分析:**分析文本的情感极性,例如积极或消极。
#### 代码块:使用NLTK进行分词和词性标注
```python
import nltk
# 加载文本
text = "自然语言处理是一个强大的工具,可以帮助我们理解和处理文本数据。"
# 分词
tokens = nltk.word_tokenize(text)
print(tokens) # 输出:['自然', '语言'
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python网站爬虫技术实战》专栏深入浅出地介绍了Python网站爬虫技术的各个方面,从入门到精通,涵盖了HTTP请求发送、动态加载内容处理、反爬虫措施破解、数据清洗与预处理、多线程与并发、分布式爬虫、爬虫道德与法律、爬虫框架、图像识别、自然语言处理、爬虫性能优化、爬虫监控与维护、爬虫反欺诈、爬虫与大数据分析、爬虫与人工智能、爬虫与云计算等主题。通过一系列循序渐进的实战教程,读者可以掌握网站爬虫的原理、技术和应用,并能够开发出高效、可靠的爬虫程序,从海量网络数据中提取有价值的信息。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB面向对象编程:提升MATLAB代码可重用性和可维护性,打造可持续代码

# 1. 面向对象编程(OOP)简介**
面向对象编程(OOP)是一种编程范式,它将数据和操作封装在称为对象的概念中。对象代表现实世界中的实体,如汽车、银行账户或学生。OOP 的主要好处包括:
- **代码可重用性:** 对象可以根据需要创建和重复使用,从而节省开发时间和精力。
- **代码可维护性:** OOP 代码易于维护,因为对象将数据和操作封
傅里叶变换在MATLAB中的云计算应用:1个大数据处理秘诀

# 1. 傅里叶变换基础**
傅里叶变换是一种数学工具,用于将时域信号分解为其频率分量。它在信号处理、图像处理和数据分析等领域有着广泛的应用。
傅里叶变换的数学表达式为:
```
F(ω) = ∫_{-\infty}^{\infty} f(t) e^(-iωt) dt
```
其中:
* `f(t)` 是时域信号
* `F(ω)` 是频率域信号
* `ω`
直方图反转:图像处理中的特殊效果,创造独特视觉体验
# 1. 直方图反转简介**
直方图反转是一种图像处理技术,它通过反转图像的直方图来创造独特的视觉效果。直方图是表示图像中不同亮度值分布的图表。通过反转直方图,可以将图像中最亮的像素变为最暗的像素,反之亦然。
这种技术可以产生引人注目的效果,例如创建高对比度的图像、增强细节或创造艺术性的表达。直方图反转在图像处理中有着广泛的应用,包括图像增强、图像分割和艺术表达。
# 2. 直
Java网络编程实战:Socket、NIO、Netty,构建高效网络应用
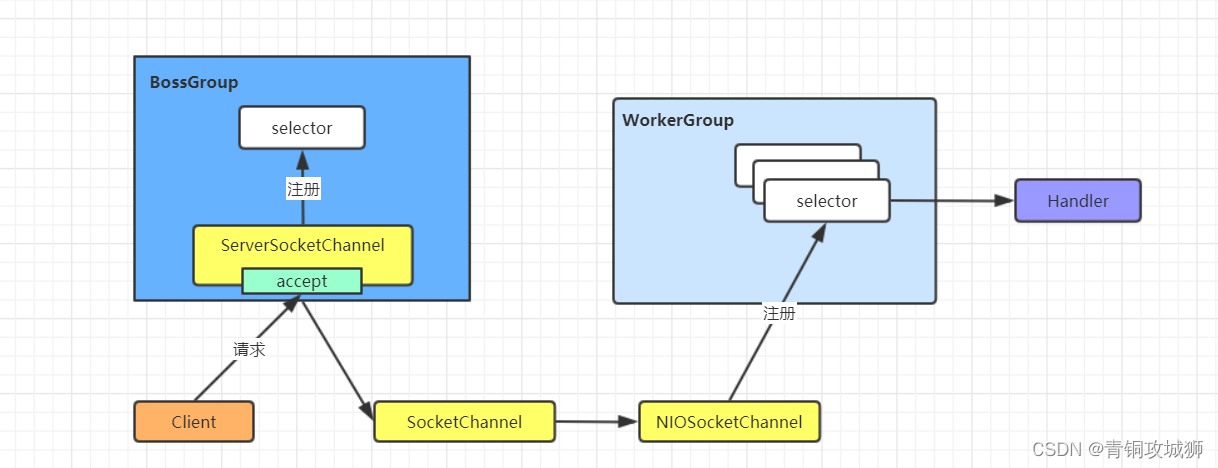
# 1. Java网络编程基础**
Java网络编程是利用Java语言开发网络应用程序的基础。本章将介绍Java网络编程的基础
MATLAB随机数交通规划中的应用:从交通流量模拟到路线优化

# 1.1 交通流量的随机特性
交通流量具有明显的随机性,这主要体现在以下几个方面:
- **车辆到达时间随机性:**车辆到达某个路口或路段的时间不是固定的,而是服从一定的概率分布。
- **车辆速度随机性:**车辆在道路上行驶的速度会受到各种因素的影响,如道路状况、交通状况、天气状况等,因此也是随机的。
- **交通事故随机性:**交通事故的发生具有偶然性,其发生时间
MATLAB神经网络与物联网:赋能智能设备,实现万物互联

# 1. MATLAB神经网络简介**
MATLAB神经网络是一个强大的工具箱,用于开发和部署神经网络模型。它提供了一系列函数和工具,使研究人员和工程师能够轻松创建、训练和评估神经网络。
MATLAB神经网络工具箱包括各种神经网络类型,包括前馈网络、递归网络和卷积网络。它还提供了一系列学习算法,例如反向传播和共轭梯度法。
MATLAB神经网络工具箱在许多领域都有应用,包括
遵循MATLAB最佳实践:编码和开发的指南,提升代码质量
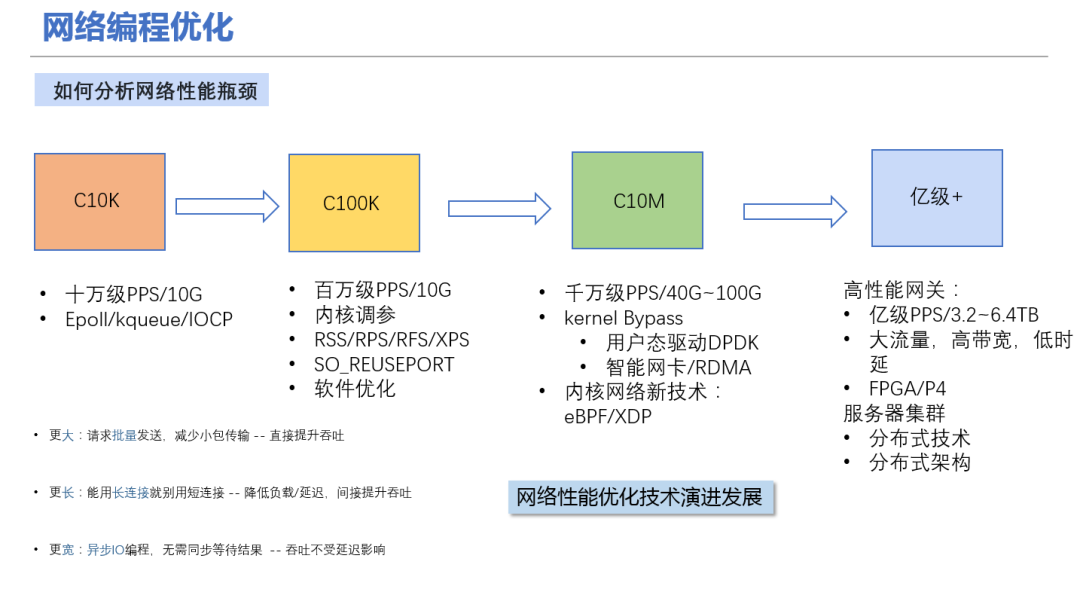
# 1. MATLAB最佳实践概述**
MATLAB是一种广泛用于技术计算和数据分析的高级编程语言。MATLAB最佳实践是一套准则,旨在提高MATLAB代码的质量、可读性和可维护性。遵循这些最佳实践可以帮助开发者编写更可靠、更有效的MATLAB程序。
MATLAB最佳实践涵盖了广泛的主题,包括编码规范、开发实践和高级编码技巧。通过遵循这些最佳实践,开发者可以提高代码的质量,
MATLAB阶乘大数据分析秘籍:应对海量数据中的阶乘计算挑战,挖掘数据价值
# 1. MATLAB阶乘计算基础**
MATLAB阶乘函数(factorial)用于计算给定非负整数的阶乘。阶乘定义为一个正整数的所有正整数因子的乘积。例如,5的阶乘(5!)等于120,因为5! = 5 × 4 × 3 × 2 × 1。
MATLAB阶乘函数的语法如下:
```
y = factorial(x)
```
其中:
* `x`:要计算阶
MATLAB数值计算高级技巧:求解偏微分方程和优化问题

# 1. MATLAB数值计算概述**
MATLAB是一种强大的数值计算环境,它提供了一系列用于解决各种科学和工程问题的函数和工具。MATLAB数值计算的主要优
MATLAB常见问题解答:解决MATLAB使用中的常见问题

# 1. MATLAB常见问题概述**
MATLAB是一款功能强大的技术计算软件,广泛应用于工程、科学和金融等领域。然而,在使用MA
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )