【Python数据处理与可视化的桥梁】:整合pandas与Plotly图表
发布时间: 2024-12-07 01:26:59 阅读量: 14 订阅数: 11 

# 1. 数据处理与可视化的必要性
## 数据的重要性
在当今这个信息爆炸的时代,数据已经成为了各个领域中不可或缺的资源。企业通过数据分析来洞察市场趋势,政府机构利用数据处理结果来进行公共决策,科学家通过数据可视化来呈现复杂的研究成果。数据的准确处理和有效呈现,对任何依赖数据分析的业务或研究都至关重要。
## 数据处理的挑战
数据处理不仅仅是对原始数据进行简单的清洗和整理,它还包括复杂的数据转换、挖掘和分析过程。由于数据来源的多样性和数据格式的不一致性,数据处理往往面临着数据质量不高、数据量庞大、处理效率低下等挑战。
## 可视化的力量
数据可视化是数据处理流程中的重要环节,它能够将复杂的数据转化为直观的图表,帮助人们快速理解信息、发现规律。一个好的数据可视化设计能够揭示数据背后的故事,为决策提供支持,甚至激发新的思考和创意。
在接下来的章节中,我们将逐步深入探索如何使用pandas库来进行高效的数据处理,以及如何结合Plotly图表库实现强大的数据可视化功能。
# 2. pandas库的基本概念和数据结构
### 2.1 pandas的安装与配置
#### 2.1.1 pandas库的环境搭建
为了在Python环境中使用pandas库,首先需要确保已经安装了Python,并且安装了pandas及其依赖。pandas库基于NumPy构建,因此NumPy也需要被安装。安装pandas库可以通过Python的包管理工具pip来完成。
```bash
pip install pandas
```
在安装过程中,可以考虑创建一个虚拟环境来避免依赖冲突。使用虚拟环境的好处在于它允许用户在不影响系统中其他Python项目的情况下安装和管理包。可以使用`venv`模块来创建一个新的虚拟环境。
```bash
# 创建虚拟环境
python -m venv myenv
# 激活虚拟环境
# 在Windows系统中
myenv\Scripts\activate
# 在Unix或MacOS系统中
source myenv/bin/activate
```
一旦虚拟环境被激活,pip安装的包将被限制在该环境中。在虚拟环境中安装pandas后,就可以开始数据处理之旅了。
#### 2.1.2 pandas与Python的关系
pandas与Python之间有紧密的关系。pandas提供了大量数据结构和操作这些结构的函数,而Python则是编写这些函数和操作数据结构的编程语言。pandas的高效实现得益于Python简洁的语法和强大的社区支持。
Python是pandas开发者的首选语言,因为它简单易学,且拥有大量的库和框架,这使得Python成为数据科学和分析的热门工具。pandas库在数据处理和分析中扮演核心角色,其Series和DataFrame数据结构允许存储和操作各种类型的数据,同时提供了丰富的方法进行数据清洗、转换和可视化。
### 2.2 pandas的数据类型和结构
#### 2.2.1 Series与DataFrame的区别和联系
在pandas中,数据被存储在两种主要的数据结构中:Series和DataFrame。
**Series** 是一维数组,能够存储任何数据类型(整数、字符串、浮点数、Python对象等)。每个元素都有一个与之关联的标签,称为索引。索引可以通过`index`属性进行访问。Series可以由列表、数组、字典等创建。
```python
import pandas as pd
# 使用列表创建Series
s = pd.Series([1, 2, 3, 4, 5])
# 使用字典创建Series
s_dict = pd.Series({'a': 100, 'b': 200, 'c': 300})
```
**DataFrame** 是二维的表格型数据结构,可以被看作是Series对象的容器。DataFrame具有索引,且每列数据类型可以不同。DataFrame可以由字典、二维数组、Series等创建。
```python
# 使用字典创建DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': ['one', 'two', 'three'],
'C': [4.5, 5.6, 6.7]
})
# 使用Series创建DataFrame
df_series = pd.DataFrame({
'A': pd.Series(1, index=[0, 1, 2]),
'B': pd.Series(2, index=[0, 1, 2])
})
```
Series和DataFrame之间的联系在于,DataFrame可以看作是多个Series的集合。每个Series都可以成为DataFrame的一列。这样的设计使得pandas在处理表格数据时既灵活又高效。
#### 2.2.2 数据索引与选择技巧
在pandas中,索引是用来检索数据的一种机制,它允许用户快速访问Series或DataFrame中的数据。pandas支持多种类型的索引方式,包括数字索引、标签索引、切片索引等。
例如,可以通过标签索引来访问Series中的数据:
```python
s = pd.Series(['apple', 'banana', 'cherry'], index=[1, 2, 3])
print(s[2]) # 输出 'banana'
```
对于DataFrame,可以使用列标签来选择数据:
```python
df = pd.DataFrame({
'A': ['foo', 'bar', 'baz'],
'B': ['one', 'two', 'three']
})
print(df['A']) # 输出 Series 对象
```
pandas也支持基于布尔的索引方式,这在数据清洗和筛选中特别有用:
```python
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]
})
# 选择列 'A' 大于 1 的行
filtered_df = df[df.A > 1]
```
利用这些索引技巧,pandas用户可以精确地选择和操作数据集中的特定部分,无论是用于进一步的分析还是可视化。
### 2.3 pandas的数据清洗和预处理
#### 2.3.1 缺失值处理方法
数据集中通常会遇到缺失值,它们可能是由于各种原因造成的,例如数据收集不完整、数据录入错误或数据传输过程中丢失。在pandas中处理缺失值是数据分析的一个重要环节,因为它会影响到后续的数据分析和模型构建。
pandas提供了多种方法来检测和处理缺失值。可以通过`isnull()`或`notnull()`函数检测缺失值,这两个函数会返回一个与原数据结构相同的布尔型对象。
```python
import numpy as np
# 创建包含NaN的DataFrame
df = pd.DataFrame(np.random.randn(5, 3), columns=list('ABC'))
df.iloc[2, 1] = np.nan
# 检测缺失值
print(df.isnull())
```
处理缺失值的常见方法包括删除含有缺失值的行或列、填充缺失值为特定值或使用统计方法(例如均值、中位数)填充。
```python
# 删除含有缺失值的行
df_dropped_rows = df.dropna()
# 填充缺失值为0
df_filled_with_zero = df.fillna(0)
# 使用列的均值填充缺失值
df_filled_with_mean = df.fillna(df.mean())
```
选择哪种方法取决于具体的数据集和分析目的。在某些情况下,删除含有缺失值的数据可能不可取,因为这可能导致大量数据丢失。因此,填充缺失值通常是更常用的解决方案。
#### 2.3.2 数据合并、连接和重塑技术
在处理复杂的数据集时,经常需要将数据从不同的来源合并到一个单一的结构中。pandas提供了`merge()`, `join()`和`concat()`等函数来实现数据合并和连接。
`merge()`函数用于根据一个或多个键将不同DataFrame的行连接起来:
```python
df1 = pd.DataFrame({'key': ['foo', 'bar'], 'value': [1, 2]})
df2 = pd.DataFrame({'key': ['foo', 'bar'], 'value': [3, 4]})
# 使用 'key' 列合并两个DataFrame
merged_df = pd.merge(df1, df2, on='key')
```
`join()`函数则默认根据索引合并数据:
```python
df3 = pd.DataFrame({'A': ['foo', 'bar', 'baz'], 'B': [1, 2, 3]})
df4 = pd.DataFrame({'C': ['one', 'two', 'three'], 'D': [4, 5, 6]})
# 使用 join() 根据索引合并
joined_df = df3.join(df4)
```
最后,`concat()`函数可以用来沿着一个轴将多个对象堆叠在一起:
```python
df5 = pd.DataFrame({'A': ['foo', 'bar'], 'B': [1, 2]})
df6 = pd.DataFrame({'A': ['baz', 'qux'], 'B': [3, 4]})
# 使用 concat() 沿着行方向堆叠
concatenated_df = pd.concat([df5, df6], axis=0)
```
这些技术使得合并和连接多个数据集变得非常方便,可以轻松地将数据集整合在一起,为数据分析和处理提供便利。
重塑数据是另一个常见的数据预处理步骤。pandas中的`pivot()`和`melt()`函数可以用来调整DataFrame的形状。`pivot()`函数可以将数据从长格式转换为宽格式,而`melt()`函数则可以将宽格式转换为长格式。
```python
# 使用 pivot() 重塑数据
df7 = pd.DataFrame({
'Date': ['2021-01-01', '2021-01-01', '2021-01-02', '2021-01-02'],
'Variable': ['A', 'B', 'A', 'B'],
'Value': [100, 200, 300, 400]
})
pivot_df = df7.pivot(index='Date', columns='Variable', values='Value')
```
数据重塑使得数据结构更适合于分析需求,是数据分析过程中的一个重要步骤。通过这些方法,pandas为数据清洗和预处理提供了强大的工具集。
# 3. pandas在数据处理中的应用
在第二章中,我们对pandas库的基础概念和数据结构有了一个全面的了解,包括如何安装和配置pandas,以及其数据类型和结构的细节。本章将更进一步,着重介绍pandas在实际数据处理中的应用技巧和方法。
## 3.1 数据筛选和排序
### 3.1.1 筛选数据的技巧
数据筛选是数据分析中非常关键的一个环节,pandas库提供了一系列的方法来帮助用户高效筛选数据。利用pandas的条件筛选功能,可以根据

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是 Python 图表绘制的全面指南,重点介绍了 Plotly 库。从安装和配置到定制、交互式可视化、数据探索和高级功能,本专栏涵盖了 Plotly 的各个方面。它还提供了优化技巧,以提高图表绘制性能。通过本专栏,读者可以掌握 Plotly 的精髓,创建引人注目的数据可视化,揭示数据的隐藏秘密,并提升他们的 Python 绘图技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【构建个性化打印解决方案】:ESC_POS命令实战应用详解

参考资源链接:[ESC/POS打印控制详解:命令一览与功能解析](https://wenku.csdn.net/doc/646c54a6d12cbe7ec3e52369?spm=1055.2635.3001.10343)
# 1. ESC/POS协议基础与打印原理
## 1.1 ESC/POS技术起源与应用
ESC/P
GMW3172手册实践指南:汽车行业工程师的必备工具

参考资源链接:[GMW3172_Handbook_Version_19.pdf](https://wenku.csdn.net/doc/6401acf0cce7214c316edb16?spm=1055.2635.3001.10343)
# 1. GMW3172手册概述与汽车行业的重要性
## 1.1 GMW3172手册概览
GMW3172手
【数据安全与稳定】:屏通Panelmaster数据备份与恢复的最佳实践

参考资源链接:[PanelMaster触控大师软件操作指南](https://wenku.csdn.net/doc/64631b535928463033bd1dca?spm=1055.2635.3001.10343)
# 1. 数据安全与稳定性的基本概念
## 1.1 数据安全的重要性
在当今数字化时代
Gel-PRO ANALYZER实用技巧分享:提升分析效率的五个方法
参考资源链接:[Gel-PRO ANALYZER软件:凝胶定量分析完全指南](https://wenku.csdn.net/doc/15xjsnno5m?spm=1055.2635.3001.10343)
# 1. Gel-P
深入解析UCINET 6:高级社交网络分析技术独家揭秘

参考资源链接:[UCINET 6 for Windows中文手册:详解与资源指南](https://wenku.csdn.net/doc/7enj0faejo?spm=1055.2635.3001.10343)
# 1. UCINET 6概述与安装配置
## 1.1 UCINET 6简介
UCINET(University of California at Ir
企业数字化转型:3-Matic 8.0水印版在数字水印策略中的应用案例

参考资源链接:[3-matic 8.0中文操作手册:从STL到CAD的正向工程解析](https://wenku.csdn.net/doc/4349r8nbr5?spm=1055.2635.3001.10343)
# 1. 企业数字化转型概述
随着信息时代的到来,企业正经历一场深远的变革
【Isserlis' Theorem:权威指南】:如何用它简化复杂数据分析
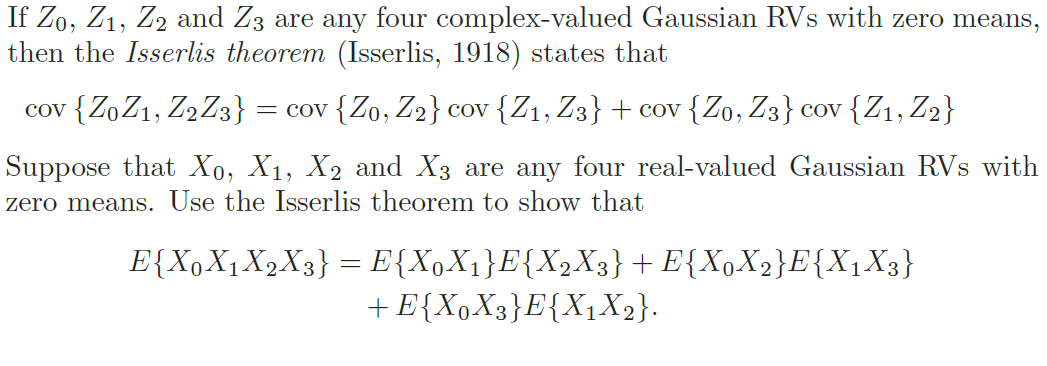
参考资源链接:[Isserlis定理:多元正态分布任意阶混合矩的通用公式证明](https://wenku.csdn.net/doc/6tpi5kvhfa?spm=1055.2635.3001.10343)
# 1. Isserlis' Theorem 理论基础
在探索数据的深层结构时,Isserlis' Theorem 扮演着一个关键角色,它为随机变量的高阶矩提
PLS_UDE_STK的日常维护:全方位监控、备份和恢复策略
参考资源链接:[快速掌握PLS-UDE调试工具:安装与使用指南](https://wenku.csdn.net/doc/2aq26rjykb?spm=1055.2635.3001.10343)
# 1. PLS_UDE_STK系统概述及维护基础
## 系统概述
PLS_UDE_STK系统是一个高度集成的数据处理平台,专为满足大规模数据存储、分析和备份需求而设计。它支
【SoftMove应用全攻略】:新手入门到高级技巧,一文掌握
参考资源链接:[ABB机器人SoftMove中文应用手册](https://wenku.csdn.net/doc/1v1odu86mu?spm=1055.2635.3001.10343)
# 1. SoftMove应用简介
## 1.1 SoftMove概述
SoftMove是一款先进的数据处理和自动化工作流软件,专门设计以适应IT专业人士和业务分析师的需求。它提供了丰富的功能,包括数据导入导出、自动化流程设计、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )