【Commons-Codec秘籍】:掌握编码与解码的艺术,提升数据处理效率
发布时间: 2024-09-25 14:48:06 阅读量: 103 订阅数: 59 

commons-codec-android-1.15
# 1. 编码与解码的基本概念
在现代信息处理领域,编码与解码是信息传输和存储中不可或缺的两个过程。编码是将原始数据按照特定的算法转换为一种特定格式的过程,其目的是为了数据的传输、存储安全或者为了满足通信协议的要求。相对地,解码则是将编码后的数据重新转换为原始数据的过程。在本章中,我们将探究编码和解码的基础知识,为之后章节深入讨论 Commons-Codec 库打下坚实的基础。编码与解码不仅仅是技术细节,它们构建了数字化世界的基础框架,使得数据在不同的系统和平台之间能够畅通无阻地交流。我们将从信息论的角度开始,深入探讨编码与解码的理论基础,逐步揭开它们在实际应用中的神秘面纱。
# 2. Commons-Codec库的核心组件
## 2.1 字符串编码解码工具类
### 2.1.1 Base64编码与解码
Base64编码是一种将二进制数据编码为可见字符的形式,广泛用于编码字符串、文件等数据。在Java中,Apache Commons Codec库提供了一套方便的工具类来实现Base64编码和解码。要使用Base64编码解码功能,首先需要在项目中引入Apache Commons Codec的依赖。
```xml
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.15</version>
</dependency>
```
接下来,可以使用`***mons.codec.binary.Base64`类中的方法进行编码和解码操作。在编码时,Base64工具类会将输入的字节数组转换为Base64编码的字符串;解码时,则将Base64编码的字符串转换回原始的字节数组。以下是Base64编码解码的基本使用示例:
```***
***mons.codec.binary.Base64;
public class Base64Example {
public static void main(String[] args) {
String originalText = "Hello, World!";
byte[] textBytes = originalText.getBytes();
// Base64编码
String encodedText = Base64.encodeBase64String(textBytes);
System.out.println("Encoded Text: " + encodedText);
// Base64解码
byte[] decodedBytes = Base64.decodeBase64(encodedText);
String decodedText = new String(decodedBytes);
System.out.println("Decoded Text: " + decodedText);
}
}
```
执行上述代码,会先将字符串"Hello, World!"编码为Base64格式,然后输出编码后的字符串。接着,将编码后的字符串解码,最终得到与原始字符串相同的结果。
在Base64编码和解码过程中,要确保正确处理可能的异常情况,例如在解码时输入的字符串不是有效的Base64编码字符串。使用异常处理来确保程序的健壮性:
```java
try {
byte[] decodedBytes = Base64.decodeBase64(encodedText);
String decodedText = new String(decodedBytes);
System.out.println("Decoded Text: " + decodedText);
} catch (IllegalArgumentException e) {
System.err.println("解码失败: " + e.getMessage());
}
```
Base64编码和解码在处理数据时非常有用,比如在需要将二进制数据嵌入到文本文件中,或者在Web应用中传输二进制文件时。这种编码方式还经常用于邮件传输、HTTP头信息,以及在XML和JSON中嵌入二进制数据。
### 2.1.2 Hex编码与解码
Hex编码(十六进制编码)是另一种常见的数据编码方式。它将每个字节的二进制形式表示为两位十六进制数。在计算机系统和网络通信中,经常使用Hex编码来表示二进制数据。
在Apache Commons Codec库中,`Hex`类提供了简单的方法来实现字节数组到十六进制字符串的转换,以及逆过程。以下为使用`Hex`类进行编码和解码的示例:
```***
***mons.codec.binary.Hex;
public class HexExample {
public static void main(String[] args) {
byte[] data = {0x12, 0x34, 0x56, 0x78, (byte) 0x9A, (byte) 0xBC, (byte) 0xDE};
// 将字节数组转换为十六进制字符串
String hexString = Hex.encodeHexString(data);
System.out.println("Hex Encoded String: " + hexString);
// 将十六进制字符串转换回字节数组
byte[] decodedData = Hex.decodeHex(hexString.toCharArray());
System.out.println("Decoded Data: " + new String(decodedData));
}
}
```
在上述代码中,字节数组`data`首先被编码为十六进制字符串,并打印出来。然后,使用`Hex.decodeHex`方法将十六进制字符串解码回原始的字节数组,并验证输出是否与原始数组相匹配。
进行Hex编码和解码时,同样需要处理异常情况。例如,如果输入的字符串格式不是有效的十六进制字符串,则需要捕获`java.lang.IllegalArgumentException`:
```java
try {
byte[] decodedData = Hex.decodeHex(hexString.toCharArray());
System.out.println("Decoded Data: " + new String(decodedData));
} catch (Exception e) {
System.err.println("解码失败: " + e.getMessage());
}
```
Hex编码广泛应用于需要查看数据原始形式的场景,比如日志记录、调试、数据校验等。十六进制字符串比二进制数据更易于阅读和分析,因此在很多情况下是数据表示的首选格式。
## 2.2 数据压缩与展开
### 2.2.1 Deflater压缩原理与应用
数据压缩是一种减少数据大小的技术,旨在节省存储空间或网络传输中所需的带宽。在Java中,Apache Commons Codec库提供了对数据压缩的支持,其中`Deflater`类允许开发者对数据进行压缩。
`Deflater`类是基于ZLIB压缩库的实现,能够将数据压缩为较小的字节数组。以下是使用`Deflater`进行数据压缩的基本用法:
```java
import java.util.zip.Deflater;
public class DeflaterExample {
public static void main(String[] args) {
String originalText = "This is the text to be compressed";
byte[] textBytes = originalText.getBytes();
// 压缩数据
Deflater compressor = new Deflater();
compressor.setInput(textBytes);
compressor.finish();
byte[] compressedData = new byte[1024];
int compressedDataLength = compressor.deflate(compressedData);
compressor.end();
// 输出压缩后的数据大小和内容
System.out.println("Compressed Data Size: " + compressedDataLength);
System.out.println("Compressed Data: " + new String(compressedData, 0, compressedDataLength));
}
}
```
在上面的代码中,首先创建了`Deflater`的实例,并将待压缩的字节数组传入。调用`deflate`方法后,`Deflater`会输出压缩后的数据,通常情况下,输出的数据会比原始数据小。
`Deflater`类提供了多种压缩级别,可以通过构造函数或者`setLevel`方法设置压缩级别。不同的压缩级别会影响压缩速度和压缩效率。一般而言,压缩级别越高,压缩后数据越小,但压缩所需时间也越长。合理地选择压缩级别能够平衡压缩效率和数据大小。
使用`Deflater`进行压缩时,还应该注意异常处理。如果在压缩过程中发生错误,比如数据输入问题,则可能会抛出`NullPointerException`或`IllegalArgumentException`。因此,应该将压缩过程包裹在`try-catch`块中以确保程序的健壮性:
```java
try {
compressor.deflate(compressedData);
} catch (Exception e) {
System.err.println("压缩失败: " + e.getMessage());
}
```
`Deflater`在实际应用中非常有用,尤其是在需要减少数据大小以节省存储空间或加速数据传输的场景。例如,在发送文件、图片或其他数据之前进行压缩,可以显著提高数据传输效率。
### 2.2.2 Inflator解压原理与应用
与`Deflater`压缩相对应的是`Inflator`类,它实现了数据的解压缩功能。在接收或读取压缩数据后,通常需要使用`Inflator`将数据还原到原始状态。
以下是`Inflator`解压缩数据的使用示例:
```java
import java.util.zip.Inflater;
public class InflatorExample {
public static void main(String[] args) {
byte[] compressedData = /* 假设这是从某处获得的压缩数据 */;
byte[] originalData = new byte[1024]; // 假设原始数据不会超过1024字节
// 解压数据
Inflater decompressor = new Inflater();
decompressor.setInput(compressedData);
int decompressedDataLength = decompressor.inflate(originalData);
decompressor.end();
// 输出解压后的数据内容
System.out.println("Decompressed Data: " + new String(originalData, 0, decompressedDataLength));
}
}
```
在该示例中,`Inflater`实例用于接收压缩数据,并通过调用`inflate`方法来进行解压缩。解压缩后的数据会存储在`originalData`字节数组中,并输出到控制台。
需要特别注意的是,压缩数据的大小可能会比原始数据大很多,因此在初始化`originalData`时应根据实际情况预估一个足够大的数组。另外,在调用`inflate`方法时,可以传入一个参数指定最大输出大小,以防万一解压过程中产生过多数据导致数组越界。
同样地,使用`Inflater`时也要考虑到异常处理,以确保在解压缩失败时能够给出明确的错误信息并进行相应的异常处理:
```java
try {
int decompressedDataLength = decompressor.inflate(originalData);
System.out.println("Decompressed Data: " + new String(originalData, 0, decompressedDataLength));
} catch (Exception e) {
System.err.println("解压缩失败: " + e.getMessage());
}
```
`Inflator`在处理压缩数据时,可以用于多个场景,例如从网络接收压缩文件数据、解压缩存储在数据库中的数据等。在这些场景下,合理使用`Inflator`可以显著提升性能,并减少对系统资源的需求。
## 2.3 编码器和解码器的高级用法
### 2.3.1 自定义字符集的编码器和解码器
在某些特定的应用场景中,标准的编码器和解码器可能无法满足需求。此时,开发者可以使用Commons-Codec提供的API来实现自定义的字符集编码器和解码器。
在Apache Commons Codec中,编码器和解码器是通过`Codec`接口实现的。通过继承`Codec`接口,开发者可以定义自己的编码和解码逻辑。以下是一个创建自定义字符集编码器和解码器的例子:
```***
***mons.codec.DecoderException;
***mons.codec.EncoderException;
***mons.codec.StringDecoder;
***mons.codec.StringEncoder;
public class CustomCodecExample {
public static void main(String[] args) {
// 自定义编码器
StringEncoder encoder = new StringEncoder() {
@Override
protected byte[] doEncoding(String source) throws EncoderException {
return source.getBytes(StandardCharsets.UTF_8);
}
};
// 自定义解码器
StringDecoder decoder = new StringDecoder() {
@Override
protected String doDecoding(byte[] source) throws DecoderException {
return new String(source, StandardCharsets.UTF_8);
}
};
// 编码和解码操作
String originalText = "Hello, Custom Codec!";
String encodedText = encoder.encodeAsString(originalText);
System.out.println("Encoded Text: " + encodedText);
String decodedText = decoder.decodeAsString(encodedText.getBytes());
System.out.println("Decoded Text: " + decodedText);
}
}
```
在上述代码中,`StringEncoder`和`StringDecoder`都被修改为使用UTF-8字符集进行编码和解码。通过重写`doEncoding`和`doDecoding`方法,开发者可以定制特定的编码和解码逻辑。
自定义编码器和解码器对于需要符合特定编码标准的场景非常有用,如在数据交换格式定义了自己的字符编码规则时。在实现自定义编码器和解码器时,应该仔细检查错误处理和边界条件,确保编码和解码过程的健壮性。
### 2.3.2 构建复合编码解码器链
在某些复杂的应用场景中,可能需要对数据进行多阶段的编码和解码。为了提高效率并简化编码解码过程,Commons-Codec允许开发者构建复合编码解码器链。
复合编码解码器链是一系列的编码器和解码器按照特定顺序链接在一起,使得输入数据可以依次经过每一步处理。在Java中,可以使用`EncoderChain`和`DecoderChain`类来构建这样的链式结构。
以下是如何构建一个简单的复合解码器链的例子:
```***
***mons.codec.DecoderException;
***mons.codec.EncoderException;
***mons.codec.StringDecoder;
***mons.codec.StringEncoder;
***mons.codec.digest.DigestUtils;
***mons.codec.language.bm.Languages;
***mons.codec.language.bm.Rule;
***mons.codec.language.bm.WordListRule;
***mons.codec.language.bm方言识别;
***mons.codec.language.bm方言识别引擎;
***mons.codec.language.bm方言识别引擎;
import java.util.ArrayList;
import java.util.List;
public class CodecChainExample {
public static void main(String[] args) throws DecoderException, EncoderException {
// 创建解码器链
DecoderChain<String> decoderChain = DecoderChain.startWith(new StringDecoder())
.appendWith(new方言识别引擎(Rule.of(Languages.LATIN)))
.appendWith(new方言识别引擎(Rule.of(Languages.ENGLISH)))
.appendWith(new方言识别引擎(Rule.of(Languages.FRENCH)))
.appendWith(new方言识别引擎(Rule.of(Languages.GERMAN)))
.appendWith(new方言识别引擎(Rule.of(Languages.ITALIAN)))
.appendWith(new方言识别引擎(Rule.of(Languages.SPAKISH)))
.appendWith(new方言识别引擎(Rule.of(Languages.CHINESE)))
.appendWith(new方言识别引擎(Rule.of(Languages.JAPANESE)))
.appendWith(new方言识别引擎(Rule.of(Languages.KOREAN)));
// 解码操作
String originalText = "The quick brown fox jumps over the lazy dog.";
List<String> decodedTexts = decoderChain.decodeAsString(originalText);
// 输出结果
System.out.println("Decoded Texts: " + decodedTexts);
}
}
```
在此示例中,一个解码器链被创建出来,它包含一个`StringDecoder`和几个`方言识别引擎`,分别用于识别并解码不同语言的文本。输入文本通过每一步的解码器进行处理,最终输出一系列解码后的文本列表。
构建编码解码器链允许开发者灵活地处理复杂的数据处理流程,为数据处理提供了更大的灵活性和可配置性。对于需要经过多层处理的数据,复合编码解码器链能够有效地提高处理效率。
请注意,复合编码解码器链的设计和实现需要开发者有很好的编码知识,以及对数据处理流程的深入理解。在设计复合编码解码器链时,必须注意各阶段的独立性以及整个链的效率。
## 2.4 编码器和解码器的应用场景
### 2.4.1 数据交换格式的处理
在进行数据交换时,比如两个系统之间通过API接口传递信息,经常会涉及到数据格式的转换。Commons-Codec库提供了丰富的编码器和解码器,可以支持各种数据交换格式的处理,如JSON、XML、Base64等。
例如,假设有一个API接口需要接收JSON格式的数据,为了确保数据的准确性和安全性,接收方系统可以使用Apache Commons Codec中的Base64解码器来解码数据。这样可以避免直接处理原始的二进制数据,而是以一种更加易于管理和解析的格式进行。
此外,如果需要发送数据时对其进行压缩,可以使用`Deflater`类来实现数据的压缩,然后将压缩后的数据编码为Base64格式,从而在保持数据压缩状态的同时便于传输。接收方则可以先将Base64编码的字符串解码为原始压缩数据,再使用`Inflater`类将其解压回原始数据。
```java
// 发送方:压缩并编码
byte[] originalData = /* 原始数据 */;
Deflater compressor = new Deflater();
compressor.setInput(originalData);
compressor.finish();
byte[] compressedData = new byte[1024];
compressor.deflate(compressedData);
compressor.end();
String encodedData = Base64.encodeBase64String(compressedData);
// 接收方:解码并解压
byte[] decodedData = Base64.decodeBase64(encodedData);
Inflater decompressor = new Inflater();
decompressor.setInput(decodedData);
byte[] decompressedData = new byte[1024];
decompressor.inflate(decompressedData);
decompressor.end();
```
这种数据处理方式使得数据交换的双方能够以一种标准化和结构化的方式来传输数据,确保了数据的一致性和完整性。
### 2.4.2 文本数据的编码和解码
文本数据的编码和解码是软件开发中的常见任务。Commons-Codec库提供的工具类可以帮助开发者高效地进行文本数据的编码和解码。例如,处理URL参数时,可以使用URL编码器来确保URL的合法性和安全性。
```***
***.URLCodec;
public class URLCodecExample {
public static void main(String[] args) throws DecoderException {
String originalText = "***你好";
// 创建URL编码器
URLCodec urlCodec = new URLCodec("UTF-8");
// 对参数进行编码
String encodedText = urlCodec.encode(originalText);
System.out.println("Encoded URL Text: " + encodedText);
// 对编码后的文本进行解码
String decodedText = urlCodec.decode(encodedText);
System.out.println("Decoded URL Text: " + decodedText);
}
}
```
在这个例子中,`URLCodec`用于对URL中可能包含的特殊字符进行编码,防止URL在传输过程中发生错误。编码之后,接收方可以使用相同的`URLCodec`实例来解码数据,恢复出原始的文本信息。
除了URL编码和解码,Commons-Codec库还支持其他的文本编码和解码操作,如字符集转换、HTML编码和解码等。这些编码解码功能对于数据的展示、存储以及网络传输都是非常重要的。
通过使用Commons-Codec库中的编码器和解码器,开发者可以很容易地实现文本数据的编码和解码,确保了数据在不同系统间传输的一致性和准确性。这不仅提升了软件的用户体验,也增加了数据处理的灵活性和安全性。
以上章节内容展示了Apache Commons Codec库在字符串编码解码、数据压缩和展开以及构建自定义编码器和解码器等方面的核心组件和高级用法。通过学习和应用这些组件和用法,开发者可以更好地实现数据的编码解码需求,提升软件的性能和用户体验。
# 3. 编码与解码实践应用
## 3.1 在文件操作中的应用
### 3.1.1 文件内容的编码和解码
在处理文件内容时,经常会遇到需要将文件内容转换成不同格式的场景。比如将文本文件以Base64编码进行存储,便于在不同的平台和语言间传输。同样,在文件传输或存储过程中,可能会遇到需要将文件进行解码以还原原始内容的情况。
下面是一个使用Java进行文件内容编码和解码的示例代码:
```***
***mons.codec.binary.Base64;
public class FileEncodingDecoding {
public static void encodeFile(String srcPath, String destPath) {
try {
// 读取原文件内容
byte[] fileContent = java.nio.file.Files.readAllBytes(java.nio.file.Paths.get(srcPath));
// Base64编码
String encodedString = Base64.encodeBase64String(fileContent);
// 写入到新文件
java.nio.file.Files.write(java.nio.file.Paths.get(destPath), Base64.decodeBase64(encodedString));
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// 将指定路径的文件进行Base64编码后保存
encodeFile("path/to/input/file.txt", "path/to/output/file.b64");
}
}
```
上述代码段展示了如何将一个文本文件内容编码成Base64格式,并保存到另一个文件中。首先使用`Files.readAllBytes`方法读取原始文件的字节数据,然后通过`Base64.encodeBase64String`方法进行编码。编码后的字符串通过`Files.write`方法写入到新文件中,这里需要注意解码的步骤,确保最终能够获取到原文件的内容。
### 3.1.2 处理文件压缩与解压缩
在文件存储或网络传输时,压缩文件可以节省空间和带宽。在Java中,我们经常使用`Deflater`和`Inflator`类来处理文件的压缩与解压缩。`Deflater`类是Java标准库中用于压缩数据的类,而`Inflator`则是用于解压缩的类。
下面是一个使用Java进行文件压缩和解压缩的示例代码:
```java
import java.util.zip.Deflater;
import java.util.zip.DeflaterOutputStream;
import java.util.zip.InflaterInputStream;
public class FileCompressionDecompression {
public static void compressFile(String srcPath, String destPath) {
try {
// 创建源文件输入流
java.io.FileInputStream fis = new java.io.FileInputStream(srcPath);
// 创建压缩文件输出流
java.io.FileOutputStream fos = new java.io.FileOutputStream(destPath);
// 使用Deflater压缩
DeflaterOutputStream dos = new DeflaterOutputStream(fos, new Deflater());
// 创建缓冲区
byte[] buffer = new byte[1024];
int len;
// 读取源文件并压缩写入目标文件
while ((len = fis.read(buffer)) > 0) {
dos.write(buffer, 0, len);
}
// 关闭资源
dos.close();
fos.close();
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void decompressFile(String srcPath, String destPath) {
try {
// 创建压缩文件输入流
java.io.FileInputStream fis = new java.io.FileInputStream(srcPath);
// 创建解压缩文件输出流
java.io.FileOutputStream fos = new java.io.FileOutputStream(destPath);
// 使用Inflater解压
InflaterInputStream iis = new InflaterInputStream(fis);
// 创建缓冲区
byte[] buffer = new byte[1024];
int len;
// 读取压缩文件并解压缩写入目标文件
while ((len = iis.read(buffer)) > 0) {
fos.write(buffer, 0, len);
}
// 关闭资源
iis.close();
fos.close();
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
compressFile("path/to/input/file.txt", "path/to/output/file.deflated");
decompressFile("path/to/output/file.deflated", "path/to/output/file.txt");
}
}
```
上述代码段展示了如何对文件进行压缩和解压缩。首先,通过`DeflaterOutputStream`包装`FileOutputStream`来实现数据的压缩写入。压缩完成后,可以使用`InflaterInputStream`包装`FileInputStream`来还原原始数据。
## 3.2 在网络编程中的应用
### 3.2.1 网络传输数据的编码解码
网络编程中,数据通常以字节的形式在网络中传输。为了确保数据的正确性,往往需要在发送端对数据进行编码,在接收端进行解码。在Java中,可以使用Commons-Codec库提供的编码和解码功能来确保数据在网络传输中的完整性和准确性。
### 3.2.2 保证数据传输的安全性和完整性
在确保数据传输的安全性和完整性方面,编码和解码可以与加密和解密技术相结合。例如,在发送数据之前先使用编码器进行编码,然后再使用加密算法加密数据;在接收数据时,先对数据解密,随后再使用解码器进行解码。这样的数据传输过程可以有效防止数据在传输过程中的泄露和篡改。
## 3.3 在数据处理中的应用
### 3.3.1 数据加密与解密
数据加密和解密是网络数据传输和存储中常见的需求。通过使用Commons-Codec库,可以在数据传输之前对其进行编码,然后通过加密算法进行加密,如AES(高级加密标准)。接收到数据后,先进行解密,再进行解码以还原原始数据。
### 3.3.2 处理URL参数的编码解码
URL参数在HTTP请求中需要进行编码,以确保URL的有效性和兼容性。同样,在解析URL参数时,需要对其进行解码。在Java中,可以使用Commons-Codec库中的编码解码功能来处理URL参数的编码和解码。这样可以避免由于特殊字符导致的错误,并保证URL参数能够正确地进行传递和解析。
在本章节中,我们深入探索了Commons-Codec库在文件操作、网络编程和数据处理中的应用。从文件内容的编码和解码,到网络传输数据的编码解码,以及数据加密与解密,再到URL参数的编码解码,每种应用场景都展示了Commons-Codec在保证数据完整性和安全性方面的强大功能。接下来的章节将详细讨论Commons-Codec库的高级特性,包括自适应的编码解码、增强的字符集支持以及性能优化与资源管理。
# 4. Commons-Codec的高级特性
在深入探讨Commons-Codec库的高级特性之前,重要的是理解这些特性如何在不同场景下提供更加灵活和智能的解决方案。Commons-Codec库不仅仅提供基础的编码解码功能,其高级特性让开发者可以在各种复杂的编程任务中游刃有余。
## 4.1 自适应的编码解码
Commons-Codec的自适应编码解码特性允许程序自动识别和处理不同编码格式的数据。这在处理来源多样化的数据流时显得尤为重要,无需手动指定编码格式即可实现高效转换。
### 4.1.1 自动识别和处理不同编码格式
自动识别编码格式是Commons-Codec在处理国际化数据时的显著优势。例如,在读取来自不同用户的文本数据时,每个用户的系统可能使用不同的默认编码(如UTF-8、GBK、ISO-8859-1等),Commons-Codec能够自动识别这些编码并进行正确的处理。
代码示例展示了自动识别和转换编码的过程:
```***
***mons.codec.language.bm.Rule;
public class EncodingAutoDetection {
public static void main(String[] args) throws Exception {
// 假设这是从外部接收的字节数据,编码未知
byte[] data = "这是一段中文文本".getBytes();
// 使用commons-codec自动检测并解码
String text = new String(data, Charset.defaultCharset());
System.out.println("解码后的文本:" + text);
// 对于不确定的情况,可以尝试不同的编码进行解码
try {
text = new String(data, "UTF-8");
System.out.println("检测到使用UTF-8编码:" + text);
} catch (Exception e) {
System.out.println("检测失败,这不是UTF-8编码");
}
}
}
```
### 4.1.2 提高编码解码的智能性和灵活性
在更高级的应用中,Commons-Codec可以结合其他库或框架来提升编码解码的智能性。比如,在处理XML或JSON数据时,可能需要根据数据结构自动选择合适的编码方式。
为了说明这一点,可以构建一个示例系统,该系统在处理不同数据类型时自动选择合适的编码方式,并打印相应的处理日志。
```***
***mons.codec.language.bm.Lang;
***mons.codec.language.bm.Languages;
public class EncodingFlexibility {
public static void main(String[] args) {
// 根据内容自动选择编码处理方式
String text = "This is an English text.";
byte[] englishBytes = text.getBytes(StandardCharsets.UTF_8);
// 假设有一个方法可以自动检测内容类型并选择编码方式
byte[] processedData = processData(text);
System.out.println("处理后的数据编码:" + Charset.defaultCharset().displayName());
System.out.println("解码得到的数据:" + new String(processedData));
}
private static byte[] processData(String content) {
// 假设的智能处理机制,这里仅示例
if (isEnglish(content)) {
return content.getBytes(StandardCharsets.UTF_8);
} else {
return content.getBytes(StandardCharsets.UTF_16);
}
}
private static boolean isEnglish(String text) {
// 简单判断英语的逻辑,实际应用中可以更复杂
return Languages.getLanguage("en").getConfidence(text) > 0.5;
}
}
```
## 4.2 增强的字符集支持
随着全球化的推进,字符集支持的增强变得越来越重要。Commons-Codec在处理多种语言和字符集的转换时提供了强大的工具类,使得开发者能够轻松实现国际化应用的编码解码需求。
### 4.2.1 支持不同字符集的转换工具类
Commons-Codec的字符集转换工具类如`CharsetUtils`提供了多种字符集的转换方法。在需要将数据从一种编码转换到另一种编码时,这些工具类能够简化开发过程。
### 4.2.2 实现国际化应用的编码解码需求
为了实现国际化应用,编码解码库需要能够处理包括中文、日文、阿拉伯文等多种语言的字符。Commons-Codec通过扩展支持了这些语言字符的编码解码。
一个示例演示了如何使用Commons-Codec将日文文本从UTF-8编码转换为UTF-16编码:
```***
***mons.codec.Charsets;
public class I18NConversion {
public static void main(String[] args) throws Exception {
String japaneseText = "こんにちは世界"; // 日文文本
byte[] utf8Encoded = japaneseText.getBytes(Charsets.UTF_8);
// 将UTF-8编码转换为UTF-16编码
byte[] utf16Encoded = Charsets.toUnicodeBytes(Charsets.UTF_16, utf8Encoded);
// 输出转换后的结果
System.out.println("转换后的日文文本:" + new String(utf16Encoded, Charsets.UTF_16));
}
}
```
## 4.3 性能优化与资源管理
在性能至关重要的应用场景中,Commons-Codec提供了性能测试工具和优化策略。同时,它还注重编码解码过程中的资源管理,确保不会因为内存泄漏等问题导致系统性能下降。
### 4.3.1 Commons-Codec的性能测试与优化策略
性能测试与优化是一个持续的过程,Commons-Codec提供了性能测试工具,可以帮助开发者了解不同编码解码操作的性能表现,并根据结果调整代码。
### 4.3.2 编码解码过程中的资源管理与释放
资源管理对于任何编码解码库都是核心考量之一,特别是在处理大量数据时。Commons-Codec确保在数据处理完成后,所有的资源都得到适当的释放,避免内存泄漏和其他资源相关的错误。
一个代码片段演示了如何在编码解码操作完成后正确释放资源:
```***
***mons.codec.binary.Base64;
import java.io.*;
public class ResourceManagement {
public static void main(String[] args) throws IOException {
File file = new File("data.bin");
// 将文件内容进行Base64编码
String encodedData = Base64.encodeBase64String(fileToByteArray(file));
// 写入到输出流
try (FileOutputStream fos = new FileOutputStream("encodedData.txt")) {
fos.write(encodedData.getBytes());
}
// 上述代码块确保在写入完成后,所有的资源都被关闭和释放
}
private static byte[] fileToByteArray(File file) throws IOException {
try (FileInputStream fis = new FileInputStream(file)) {
return streamToByteArray(fis);
}
}
private static byte[] streamToByteArray(InputStream stream) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int n;
while ((n = stream.read(buffer)) != -1) {
baos.write(buffer, 0, n);
}
return baos.toByteArray();
}
}
```
在以上各节中,我们探讨了Commons-Codec的高级特性,包括自适应编码解码、增强的字符集支持以及性能优化与资源管理。这些特性使Commons-Codec成为一个强大的工具,能够在编码解码需求日益增长的现代软件开发环境中,提供高效的解决方案。
# 5. Commons-Codec在企业级应用中的实践
## 5.1 集成到Web应用程序中
随着企业级应用的快速发展,Web应用程序成为了数据交互的重要平台。在这一节,我们将探讨如何将Commons-Codec集成到Web应用程序中,以及如何通过Commons-Codec提升Web应用数据交互的效率与安全性。
### 5.1.1 通过Web框架实现数据的编码解码
在Web应用程序中处理数据时,编码和解码是必不可少的步骤,尤其是在接收和发送数据到客户端的过程中。许多Web框架提供了内置的编码和解码机制,但Commons-Codec能够提供更加灵活和强大的解决方案。
以Java生态系统中的Spring框架为例,我们可以在控制器层面上使用Commons-Codec来实现数据的编码解码。例如,我们可能需要对用户提交的表单数据进行Base64编码,以防止在传输过程中数据被篡改。我们可以在控制器中添加如下代码:
```java
@RequestMapping(value = "/submitForm", method = RequestMethod.POST)
public ResponseEntity<String> submitForm(@RequestParam("data") String data) {
// Base64编码
String encodedData = new String(Base64.encodeBase64(data.getBytes()));
// 进行业务处理...
return ResponseEntity.ok(encodedData);
}
```
此段代码展示了如何接收客户端传递的数据并进行Base64编码。Commons-Codec通过其`Base64`类提供了编码和解码的方法,简洁高效。
### 5.1.2 提升Web应用数据交互的效率与安全性
Web应用的效率和安全性是企业级应用开发中的核心考量因素。通过Commons-Codec,开发者可以实现更高效的编码解码操作,同时增强数据的安全性。
在效率方面,Commons-Codec库中的类如`FastBase64`提供了更快的Base64编码解码性能。它使用了底层的Java技术来加速编码和解码的过程,非常适合在需要处理大量数据的场景中使用。
```java
String fasterEncodedData = new String(FastBase64.encodeBase64(data.getBytes()));
```
在安全性方面,除了编码本身提供的安全基础之外,Commons-Codec还允许开发者自定义字符集、编解码器,以及与其他安全框架的集成,如Apache Shiro,用于更复杂的安全需求。
```java
// 示例:使用自定义字符集进行编码
public class CustomCharsetCodec {
public static String encodeWithCustomCharset(String input) {
// 获取自定义字符集的编码器
CharsetEncoder encoder = Charset.forName("UTF-8").newEncoder();
CharBuffer buffer = CharBuffer.wrap(input);
ByteBuffer out = ByteBuffer.allocate(128);
encoder.encode(buffer, out, true);
out.flip();
return Base64.encodeBase64String(out.array());
}
}
```
这段代码展示了如何结合字符集和Base64编码,提供了一种更安全的编码方式。
## 5.2 大数据处理中的应用
大数据环境下,数据的编码解码是不可或缺的环节,尤其在数据的存储和查询处理中。Commons-Codec库通过其高效的算法,能够提供快速且可靠的编码解码能力,以支持大数据量的处理。
### 5.2.1 在大数据环境下的编码解码策略
在处理大数据时,常见的策略包括对数据进行压缩以减少存储空间,以及对敏感数据进行加密以保障安全。Commons-Codec能够在这些方面提供支持。
例如,在Hadoop环境中,我们可能需要对存储的数据进行编码和解码。Commons-Codec的`Deflater`和`Inflator`类可以被用于压缩和解压数据。以下是如何使用它们的示例代码:
```java
// 压缩数据
Deflater compressor = new Deflater();
compressor.setInput(data.getBytes());
compressor.finish();
byte[] compressedData = new byte[256];
int compressedDataLength = compressor.deflate(compressedData);
// 解压数据
Inflate decompressor = new Inflator();
decompressor.setInput(compressedData, 0, compressedDataLength);
byte[] decompressedData = new byte[256];
int decompressedDataLength = decompressor.inflate(decompressedData);
```
在安全性方面,Commons-Codec支持各种加密解密算法,可以用于对存储或传输中的数据进行保护。例如,使用SHA-256算法进行数据的加密:
```java
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[] digest = md.digest(data.getBytes());
```
### 5.2.2 利用Commons-Codec提高数据处理速度
Commons-Codec通过优化的算法和灵活的使用方式,能够在大数据处理中提升数据处理速度。
在数据编码解码方面,Commons-Codec库已经对关键算法进行了性能优化,确保在大数据量处理时仍能保持高速度。例如,对于Base64编码和解码,库中的类如`FastBase64`利用了内部优化过的缓冲区操作,减少了不必要的内存分配和复制,从而加速了编码解码的过程。
```java
// 使用FastBase64进行编码
byte[] encodedBytes = FastBase64.encodeBase64(data);
```
在数据压缩和解压方面,通过使用预设的压缩级别参数,Commons-Codec能够进一步提高压缩和解压的速度,适应不同的性能需求。
```java
// 使用预设压缩级别进行压缩
Deflater compressor = new Deflater(Deflater.BEST_SPEED);
```
通过这些策略,Commons-Codec在大数据应用中能够有效提升数据处理速度,降低资源消耗,为企业级应用带来显著的性能提升。
# 6. Commons-Codec的未来展望和最佳实践
随着信息技术的快速发展,Apache Commons Codec库也在不断地更新和进化,以适应新的挑战和需求。在未来,它会如何发展,有哪些值得期待的新特性?同时,编码解码的最佳实践有哪些?本章将为您揭示。
## 6.1 社区发展和版本更新趋势
### 6.1.1 分析新版本中引入的新特性与改进
Apache Commons Codec库是活跃的开源项目,新版本的发布通常包含了社区成员和贡献者提出的改进意见和新特性。例如,一个新版本可能包含了对现有编码解码算法的优化,如更快的处理速度或更低的内存消耗;或者引入了对新兴编码标准的支持,比如Base64的变种或新定义的字符集。
```java
// 举例说明新版本的改进特性使用
***mons.codec.binary.Base64;
import java.util.Base64.*;
// 新版本中新增的编码解码工具的使用示例
byte[] data = "Hello, World!".getBytes(StandardCharsets.UTF_8);
String encodedData = Base64.getEncoder().encodeToString(data);
System.out.println("Encoded Data: " + encodedData);
```
### 6.1.2 探讨Commons-Codec的发展方向和潜力
Commons Codec的一个潜在发展方向是集成更多的加密解密算法,以支持更广泛的加密需求。另一个方向是提高库的性能,尤其是在大数据处理和分布式系统中。未来版本可能也会加强对API的文档化,以便更好地帮助开发者理解和使用库的功能。
## 6.2 编码解码的最佳实践案例分析
### 6.2.1 分享业内成功实践案例
在实际应用中,Apache Commons Codec被广泛用于各种场景,比如安全通讯、数据存储和网络传输。例如,一些支付系统使用该库来编码解码交易数据,确保数据的安全性和完整性。
```java
// 使用Codec库进行加密解密的示例
***mons.codec.binary.Hex;
// 模拟加密解密过程
byte[] key = "secretKey".getBytes(StandardCharsets.UTF_8);
byte[] dataToEncrypt = "Sensitive Information".getBytes(StandardCharsets.UTF_8);
String encryptedData = Hex.encodeHexString(dataToEncrypt);
// 假设另一端使用相同的密钥来解密数据
String decryptedData = new String(Hex.decodeHex(encryptedData.toCharArray()), StandardCharsets.UTF_8);
System.out.println("Decrypted Data: " + decryptedData);
```
### 6.2.2 提炼编码解码的最佳实践和技巧
在使用Commons Codec的过程中,最佳实践包括合理使用字符编码转换、避免不必要的性能开销(例如,预先编码好常用的字符串),以及在需要的时候采用更安全的编码解码方案。此外,合理地管理资源(比如关闭流和释放内存)也是重要的实践之一。
总结来看,Apache Commons Codec库不断进化,为开发者提供了丰富的编码解码工具,帮助简化编程任务,提高代码质量。未来的发展和最佳实践将始终围绕着安全、效率和易用性展开。通过不断学习和实践,开发者可以充分利用这个强大的库来满足编码解码领域的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Commons-Codec库入门介绍与使用》专栏深入介绍了Commons-Codec库,这是一个功能强大的Java库,用于编码、解码和数据处理。专栏涵盖了从入门指南到高级应用、性能调优、源码解析和故障排查的各个方面。通过深入的教程、示例和最佳实践,读者可以掌握Commons-Codec库的强大功能,提升数据处理效率。专栏还探讨了库在安全、物联网、函数式编程、日志处理和移动开发等领域的应用,提供了跨平台数据交换和性能基准测试的深入分析。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32串口数据宽度调整实战:实现从8位到9位的无缝过渡
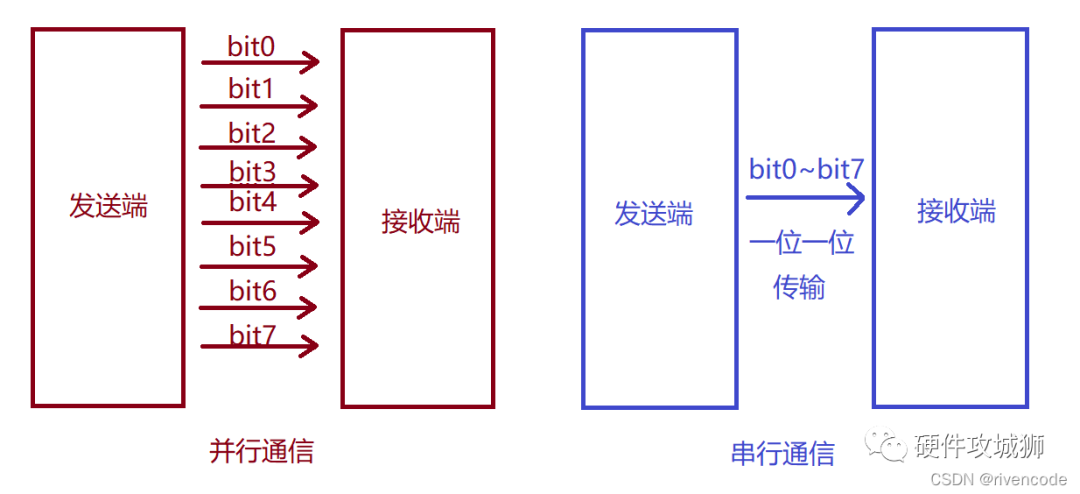
# 摘要
STM32微控制器的串口数据宽度配置是实现高效通信的关键技术之一。本文首先介绍了STM32串口通信的基础知识,重点阐述了8位数据宽度的通信原理及其在实际硬件上的实现机制。随后,本文探讨了从8位向9位数据宽度过渡的理论依据和实践方法,并对9位数据宽度的深入应用进行了编程实践、错误检测与校正以及性能评估。案例研究
【非线性材料建模升级】:BH曲线高级应用技巧揭秘
# 摘要
非线性材料的建模是工程和科学研究中的一个重要领域,其中BH曲线理论是理解和模拟磁性材料性能的关键。本文首先介绍了非线性材料建模的基础知识,深入阐释了BH曲线理论以及其数学描述和参数获取方法。随后,本文探讨了BH曲线在材料建模中的实际应用,包括模型的建立、验证以及优化策略。此外,文中还介绍了BH曲线在多物理场耦合分析中的高级应用技巧和非线性材料仿真案例分析。最后,本文展望了未来研究趋势,包括材料科学与信息技术的融合,新型材料BH曲线研究,以及持续的探索与创新方向。
# 关键字
非线性材料建模;BH曲线;磁性材料;多物理场耦合;数值计算;材料科学研究
参考资源链接:[ANSYS电磁场
【51单片机微控制器】:MLX90614红外传感器应用与实践

# 摘要
本论文首先介绍了51单片机与MLX90614红外传感器的基础知识,然后深入探讨了MLX90614传感器的工作原理、与51单片机的通信协议,以及硬件连接和软件编程的具体步骤。通过硬件连接的接线指南和电路调试,以及软件编程中的I2C读写操作和数据处理与显示方法,本文为实
C++ Builder 6.0 界面设计速成课:打造用户友好界面的秘诀

# 摘要
本文全面介绍了C++ Builder 6.0在界面设计、控件应用、交互动效、数据绑定、报表设计以及项目部署和优化等方面的应用。首先概述了界面设计的基础知识和窗口组件的类别与功能。接着深入探讨了控件的高级应用,包括标准控件与高级控件的使用技巧,以及自定义控件的创建和第三方组件的集成。文章还阐述了
【GC032A医疗应用】:确保设备可靠性与患者安全的关键
# 摘要
本文详细探讨了GC032A医疗设备在应用、可靠性与安全性方面的综合考量。首先概述了GC032A的基本应用,紧接着深入分析了其可靠性的理论基础、提升策略以及可靠性测试和评估方法。在安全性实践方面,本文阐述了设计原则、实施监管以及安全性测试验证的重要性。此外,文章还探讨了将可靠性与安全性整合的必要性和方法,并讨论了全生命周期内设备的持续改进。最后,本文展望了GC03
【Python 3.9速成课】:五步教你从新手到专家
# 摘要
本文旨在为Python 3.9初学者和中级用户提供一个全面的指南,涵盖了从入门到高级特性再到实战项目的完整学习路径。首先介绍了Python 3.9的基础语法和核心概念,确保读者能够理解和运用变量、数据结构、控制流语句和面向对象编程。其次,深入探讨了迭代器、生成器、装饰器、上下文管理器以及并发和异步编程等高
【数字电路设计】:Logisim中的位运算与移位操作策略
# 摘要
本文旨在探讨数字电路设计的基础知识,并详细介绍如何利用Logisim软件实现和优化位运算以及移位操作。文章从基础概念出发,深入阐述了位运算的原理、逻辑门实现、以及在Logisim中的实践应用。随后,文章重点分析了移位操作的原理、Logisim中的实现和优化策略。最后,本文通过结合高级算术运算、数据存储处理、算法与数据结构的实现案例,展示了位运算与移位操作在数字电路设计中
Ledit项目管理与版本控制:无缝集成Git与SVN

# 摘要
本文首先概述了版本控制的重要性和基本原理,深入探讨了Git与SVN这两大版本控制系统的不同工作原理及其设计理念对比。接着,文章着重描述了Ledit项目中Git与SVN的集成方案,包括集成前的准备工作、详细集成过程以及集成后的项目管理实践。通过对Ledit项目管理实践的案例分析,本文揭示了版本控制系统在实际开发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )