如何安装Oracle 11gR2数据库
发布时间: 2024-02-24 16:54:05 阅读量: 42 订阅数: 26 
# 1. 准备工作
1.1 检查系统要求
在安装Oracle 11gR2数据库之前,首先需要确保系统满足以下要求:
- 操作系统:Oracle官方支持的操作系统版本,如Oracle Linux、Red Hat Enterprise Linux、Windows Server等。
- 内存:建议至少4GB RAM以确保数据库正常运行。
- 存储空间:至少需要11GB用于安装Oracle数据库软件及创建数据库实例。
- CPU:建议至少双核CPU以提供良好的性能。
1.2 下载Oracle 11gR2安装文件
访问Oracle官方网站,下载适用于您操作系统的Oracle 11gR2安装文件。请确保选择正确的版本,并将安装文件保存在您的系统中以便后续安装使用。
1.3 准备数据库安装所需的环境设置
在开始安装Oracle数据库之前,您需要进行一些环境设置,以确保安装过程顺利进行。
- 创建一个新的组和用户,用于安装Oracle数据库软件及管理数据库实例。
- 确保操作系统的参数设置满足Oracle的要求,如内核参数、用户/文件描述符限制等。
- 设置正确的环境变量,如ORACLE_HOME、ORACLE_SID等,以便数据库软件正常运行。
在完成上述准备工作后,您就可以开始安装Oracle 11gR2数据库软件了。
# 2. 安装Oracle数据库软件
在本章中,我们将详细介绍如何安装Oracle 11gR2数据库软件,包括创建Oracle安装用户、设置环境变量、启动Oracle安装向导、选择安装类型及安装位置以及最终安装Oracle 11gR2数据库软件的步骤。让我们一步步进行操作:
### 2.1 创建Oracle安装用户
首先,我们需要创建一个专门用于安装Oracle数据库软件的用户。请按照以下步骤执行:
```bash
# 创建名为oracle的用户
sudo useradd -m -s /bin/bash oracle
# 设置oracle用户密码
sudo passwd oracle
```
### 2.2 设置环境变量
接下来,我们需要设置一些必要的环境变量,以确保安装过程顺利进行。请按照以下步骤执行:
```bash
# 编辑oracle用户的.bashrc文件
sudo su - oracle
vi ~/.bashrc
# 在文件末尾添加以下环境变量配置
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/11.2.0/dbhome_1
export ORACLE_SID=orcl
export PATH=$PATH:$ORACLE_HOME/bin
# 保存并退出文件,然后执行以下命令使配置生效
source ~/.bashrc
```
### 2.3 启动Oracle安装向导
现在,我们可以启动Oracle安装向导来开始安装数据库软件。请按照以下步骤执行:
```bash
# 切换到Oracle安装文件的目录
cd /path/to/oracle/installation/files
# 使用oracle用户身份启动安装向导
./runInstaller
```
安装向导会引导您完成安装过程,您只需根据提示一步步进行操作即可。
### 2.4 选择安装类型及安装位置
在安装过程中,您将需要选择安装类型(例如单实例数据库安装、集群数据库安装等)和安装位置。根据您的需求进行选择,并确保设置正确的安装路径。
### 2.5 安装Oracle 11gR2数据库软件
最后,安装向导将开始安装Oracle 11gR2数据库软件。安装过程可能会需要一些时间,请耐心等待直至安装完成。
至此,您已成功完成Oracle数据库软件的安装。在接下来的章节中,我们将继续进行Oracle实例的配置以及数据库的创建和管理。祝您顺利!
# 3. 配置Oracle实例
在这一章节中,我们将会详细说明如何配置Oracle数据库实例,包括创建数据库实例、配置实例参数、设置监听器以及配置网络服务名称。
#### 3.1 创建数据库实例
首先,我们需要使用SQL*Plus或者Oracle Enterprise Manager等工具连接到数据库,然后执行以下SQL语句创建数据库实例:
```sql
CREATE DATABASE instance_name
```
这条命令将会创建一个名为instance_name的数据库实例。
#### 3.2 配置实例参数
接下来,我们需要配置数据库实例的参数,可以通过以下SQL语句修改参数配置:
```sql
ALTER SYSTEM SET parameter_name = value SCOPE = SPFILE;
```
在这里,parameter_name是要修改的参数名称,value是新的参数取值。
#### 3.3 设置监听器
Oracle数据库使用监听器来监听客户端连接请求,并将这些请求转发给适当的数据库实例。要设置监听器,可以编辑listener.ora文件,添加类似如下内容:
```
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = hostname)(PORT = port))
)
)
```
在这里,hostname是监听器所在主机的主机名,port是监听器所监听的端口号。
#### 3.4 配置网络服务名称
最后,在客户端连接数据库时,需要配置网络服务名称以便正确连接到数据库实例。可以通过编辑tnsnames.ora文件来配置网络服务名称,例如:
```
SERVICE_NAME =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = hostname)(PORT = port))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = instance_name)
)
)
```
在这里,hostname和port分别是数据库实例所在主机的主机名和端口号,instance_name是数据库实例的名称。
希望通过以上步骤能够成功配置Oracle数据库实例,使其能够正常运行并接受客户端连接请求。
# 4. 创建并管理数据库
#### 4.1 使用SQL*Plus创建数据库
```sql
-- 创建数据库
CREATE DATABASE mydb
USER SYS IDENTIFIED BY mypassword
USER SYSTEM IDENTIFIED BY mypassword
LOGFILE GROUP 1 ('/u01/oradata/mydb/redo01.log') SIZE 100M,
GROUP 2 ('/u01/oradata/mydb/redo02.log') SIZE 100M,
GROUP 3 ('/u01/oradata/mydb/redo03.log') SIZE 100M
MAXLOGFILES 5
MAXLOGHISTORY 100
MAXLOGMEMBERS 3
MAXDATAFILES 100
CHARACTER SET AL32UTF8;
```
**代码总结:**
- 使用SQL*Plus创建名为mydb的数据库。
- 分配SYS和SYSTEM用户的密码为mypassword。
- 配置日志文件组,最大日志文件数,字符集等数据库参数。
**结果说明:**
- 数据库成功创建,日志文件和参数设置完毕。
#### 4.2 运行数据库校验工具
```sql
-- 运行数据库校验工具
DBMS_DDL.CHECK_DATABASE;
```
**代码总结:**
- 使用DBMS_DDL包中的CHECK_DATABASE过程对数据库进行校验。
**结果说明:**
- 数据库校验工具运行成功,未发现数据库逻辑结构问题。
#### 4.3 创建表空间和用户
```sql
-- 创建表空间
CREATE TABLESPACE myts DATAFILE '/u01/oradata/mydb/myts01.dbf' SIZE 100M;
-- 创建用户
CREATE USER myuser IDENTIFIED BY mypassword DEFAULT TABLESPACE myts QUOTA UNLIMITED ON myts;
GRANT CONNECT, RESOURCE TO myuser;
```
**代码总结:**
- 创建名为myts的表空间,指定数据文件大小为100M。
- 创建名为myuser的用户,指定默认表空间为myts,授予CONNECT和RESOURCE角色。
**结果说明:**
- 表空间和用户创建成功,用户拥有对表空间的无限制配额。
#### 4.4 导入/导出数据
```sql
-- 导出数据
EXPDP myuser/mypassword@mydb DIRECTORY=datapump_dir DUMPFILE=expdat.dmp SCHEMAS=myuser
-- 导入数据
IMPDP myuser/mypassword@mydb DIRECTORY=datapump_dir DUMPFILE=expdat.dmp REMAP_SCHEMA=myuser:newuser
```
**代码总结:**
- 使用数据泵工具导出名为myuser的用户的数据到expdat.dmp文件。
- 使用数据泵工具导入expdat.dmp中的数据到名为newuser的用户。
**结果说明:**
- 数据成功导出到expdat.dmp文件,并成功从该文件导入到名为newuser的用户中。
这就是第四章的内容,包括了在Oracle 11gR2数据库中创建和管理数据库的过程,涵盖了数据库创建、校验、表空间和用户的管理,以及数据的导入和导出等操作。
# 5. 数据库备份与恢复
数据备份和恢复对于数据库的稳定性和安全性至关重要。在本章节中,我们将介绍如何配置数据库备份计划,使用RMAN备份数据库以及进行数据库恢复操作。
### 5.1 配置备份计划
在配置备份计划之前,我们需要确定备份的策略,包括完整备份、增量备份、差异备份等。确保备份频率和保留策略满足业务需求。
```sql
-- 示例代码:配置完整备份每周日执行
BEGIN
DBMS_SCHEDULER.create_job (
job_name => 'FULL_BACKUP_JOB',
job_type => 'BACKUP',
job_action => 'BEGIN DBMS_BACKUP_RESTORE.BACKUP_DATABASE; END;',
start_date => SYSTIMESTAMP,
repeat_interval => 'FREQ=WEEKLY; BYDAY=SUN',
enabled => TRUE
);
END;
/
```
**注解:** 以上示例代码使用DBMS_SCHEDULER创建一个定时任务,每周日执行完整备份操作。根据业务需求灵活调整备份策略。
### 5.2 使用RMAN备份数据库
利用RMAN(Recovery Manager)工具可以实现高效、可靠的数据库备份。以下是一个简单的RMAN备份操作示例:
```sql
-- 示例代码:使用RMAN进行完整备份
rman target /
RMAN> RUN {
2> BACKUP DATABASE PLUS ARCHIVELOG;
3> }
```
**结果说明:** 以上代码将备份数据库和归档日志,确保数据完整性和一致性。
### 5.3 恢复数据库
在发生数据库故障或数据丢失时,需要进行数据库恢复操作。以下是一个简单的数据库恢复示例:
```sql
-- 示例代码:使用RMAN恢复数据库到指定时间点
rman target /
RMAN> RUN {
2> SET UNTIL TIME '2022-01-01 12:00:00';
3> RESTORE DATABASE;
4> RECOVER DATABASE;
5> }
```
**结果说明:** 以上代码将数据库恢复到指定时间点的状态,确保数据的一致性和完整性。
通过上述步骤,我们可以有效地配置数据库备份计划、使用RMAN进行备份以及进行数据库恢复操作,保障数据库的安全和稳定性。
# 6. 性能优化和故障排除
在数据库管理过程中,除了数据库的安装和配置外,我们还需要重点关注数据库的性能优化和故障排除。在本章节中,我们将详细讨论如何监控数据库的性能,优化SQL查询,以及处理常见的故障和问题。
#### 6.1 监控数据库性能
在实际运行过程中,我们需要时刻监控数据库的性能,以便及时发现并解决潜在的性能问题。Oracle提供了丰富的性能监控工具,比如AWR报告、ASH报告和系统视图等,可以用来收集和分析数据库的性能数据。通过这些工具,我们可以了解数据库的运行状态、性能瓶颈所在,并及时采取相应的优化措施。
```sql
-- 举例:生成数据库性能报告
SELECT * FROM V$ACTIVE_SESSION_HISTORY WHERE SAMPLE_TIME > SYSDATE - 1;
```
#### 6.2 优化SQL查询
SQL查询是数据库操作的核心,优化SQL查询可以显著提升数据库的性能。在优化SQL查询时,我们可以通过分析执行计划、创建合适的索引、重新编写SQL语句等方式来提高查询效率。同时,我们还可以利用Oracle提供的SQL调优工具,比如SQL Tuning Advisor和SQL Access Advisor,来帮助我们发现和解决潜在的性能问题。
```sql
-- 举例:查看SQL执行计划
EXPLAIN PLAN FOR
SELECT * FROM employees WHERE department_id = 10;
```
#### 6.3 故障排除和常见问题解决
在数据库运行过程中,可能会遇到各种故障和常见问题,比如数据丢失、性能下降、连接超时等。针对这些问题,我们需要及时分析故障现象的原因,并采取相应的措施进行排除。另外,我们还可以根据Oracle数据库提供的错误日志、警告日志和故障诊断日志来辅助排查和解决故障问题。
```sql
-- 举例:查看错误日志
SELECT * FROM V$LOG WHERE TYPE = 'ERROR';
```
希望通过本章节的学习,读者可以掌握数据库性能优化和故障排除的基本方法,从而更好地管理和维护Oracle数据库。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入探讨Oracle 11gR2数据库的技术知识,涵盖了从基础架构概述到高级操作的多个主题。您将学习如何安装Oracle 11gR2数据库,进行简单的查询操作,理解索引原理,编写存储过程,应用约束与触发器,掌握视图原理与用法,学习数据备份与恢复,管理用户和权限,以及优化执行计划等内容。通过本专栏的学习,将帮助您建立扎实的Oracle数据库技术基础,提升在实际工作中的应用能力和解决问题的能力。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大规模深度学习系统:Dropout的实施与优化策略
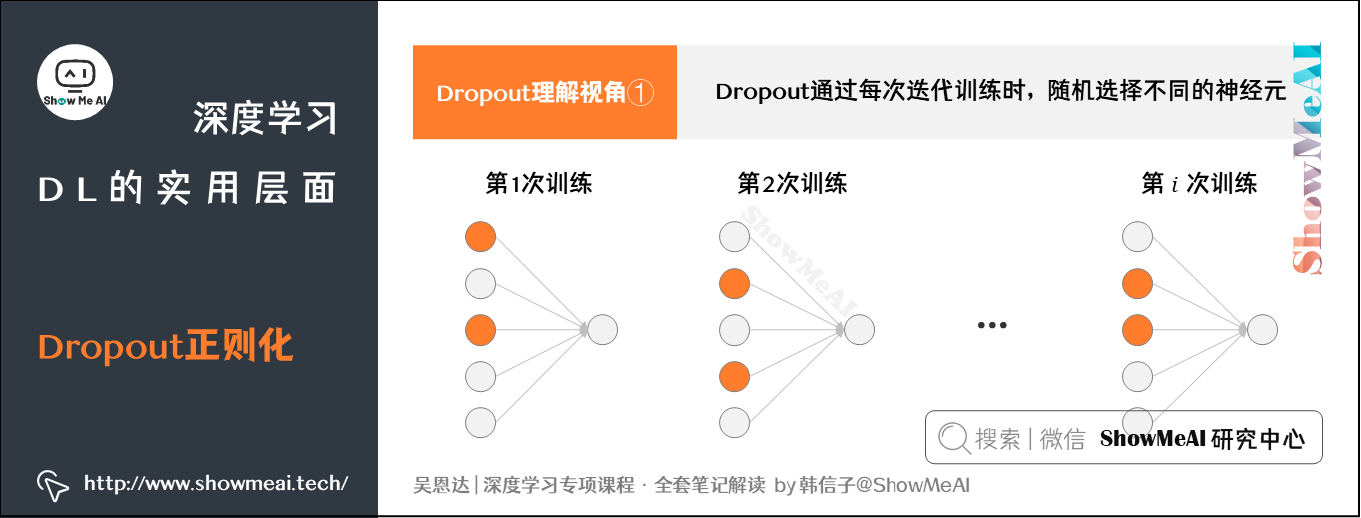
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
机器学习中的变量转换:改善数据分布与模型性能,实用指南
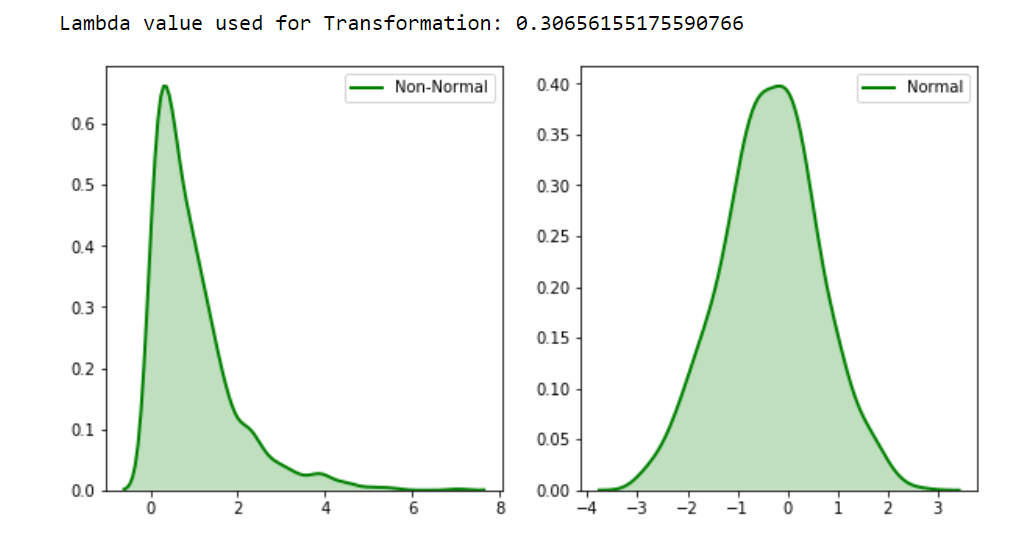
# 1. 机器学习与变量转换概述
## 1.1 机器学习的变量转换必要性
在机器学习领域,变量转换是优化数据以提升模型性能的关键步骤。它涉及将原始数据转换成更适合算法处理的形式,以增强模型的预测能力和稳定性。通过这种方式,可以克服数据的某些缺陷,比如非线性关系、不均匀分布、不同量纲和尺度的特征,以及处理缺失值和异常值等问题。
## 1.2 变量转换在数据预处理中的作用
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
贝叶斯方法与ANOVA:统计推断中的强强联手(高级数据分析师指南)
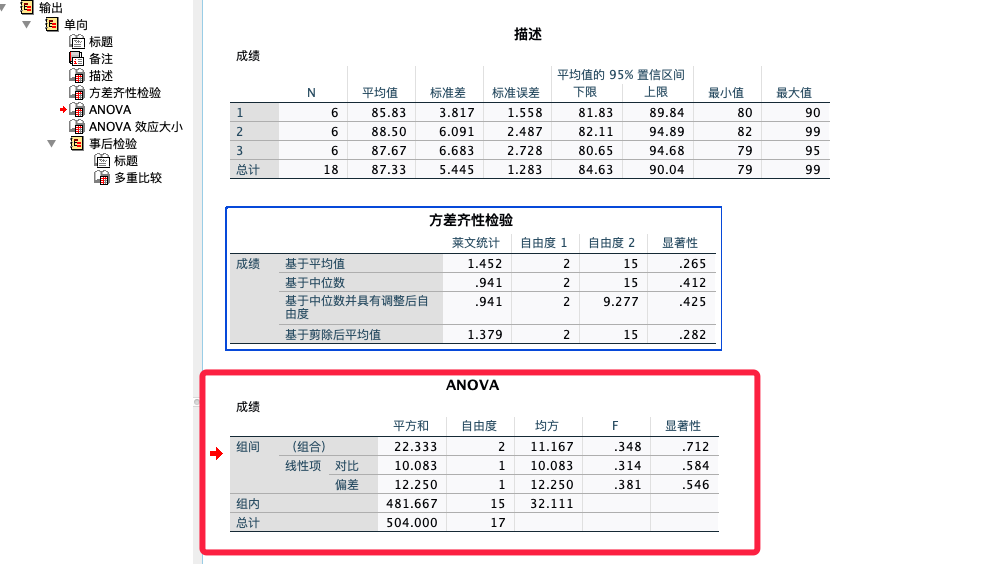
# 1. 贝叶斯统计基础与原理
在统计学和数据分析领域,贝叶斯方法提供了一种与经典统计学不同的推断框架。它基于贝叶斯定理,允许我们通过结合先验知识和实际观测数据来更新我们对参数的信念。在本章中,我们将介绍贝叶斯统计的基础知识,包括其核心原理和如何在实际问题中应用这些原理。
## 1.1 贝叶斯定理简介
贝叶斯定理,以英国数学家托马斯·贝叶斯命名
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
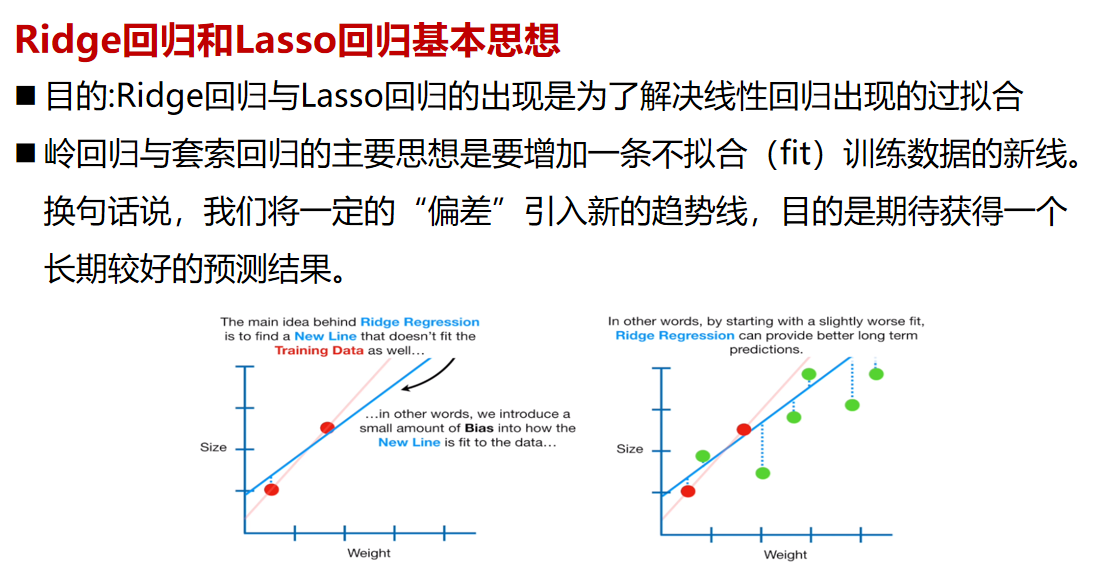
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
推荐系统中的L2正则化:案例与实践深度解析
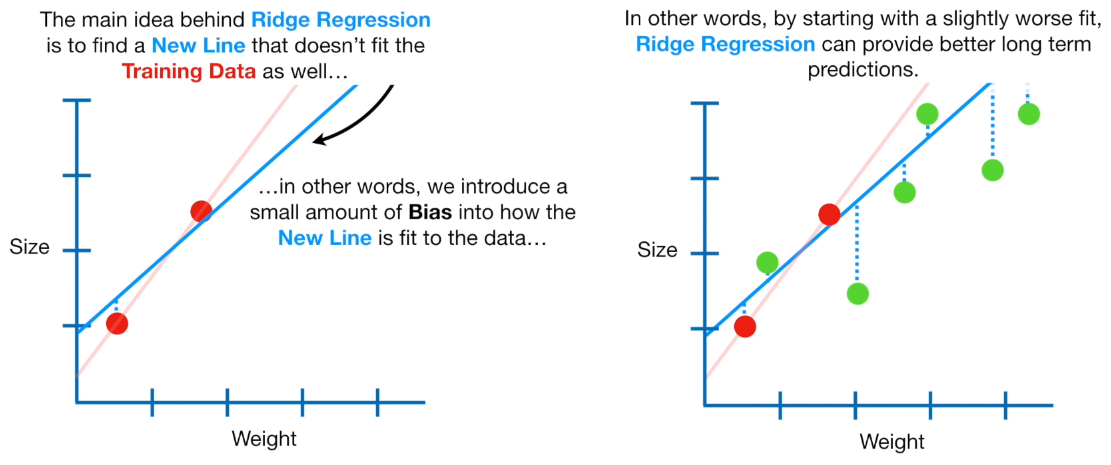
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
预测建模精准度提升:贝叶斯优化的应用技巧与案例

# 1. 贝叶斯优化概述
贝叶斯优化是一种强大的全局优化策略,用于在黑盒参数空间中寻找最优解。它基于贝叶斯推理,通过建立一个目标函数的代理模型来预测目标函数的性能,并据此选择新的参数配置进行评估。本章将简要介绍贝叶斯优化的基本概念、工作流程以及其在现实世界
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
【过拟合克星】:网格搜索提升模型泛化能力的秘诀

# 1. 网格搜索在机器学习中的作用
在机器学习领域,模型的选择和参数调整是优化性能的关键步骤。网格搜索作为一种广泛使用的参数优化方法,能够帮助数据科学家系统地探索参数空间,从而找到最佳的模型配置。
## 1.1 网格搜索的优势
网格搜索通过遍历定义的参数网格,可以全面评估参数组合对模型性能的影响。它简单直观,易于实现,并且能够生成可重复的实验结果。尽管它在某些
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )