yolo旋转目标检测移植在实战中的应用:案例解析,助力项目成功
发布时间: 2024-08-15 13:18:57 阅读量: 39 订阅数: 28 

使用YOLO进行实时目标检测:项目实战.md

# 1. YOLO旋转目标检测简介
YOLO(You Only Look Once)是一种单阶段目标检测算法,因其速度快、精度高而受到广泛关注。YOLO旋转目标检测是在YOLO算法的基础上,针对旋转目标检测任务而进行的改进。
与传统的目标检测算法不同,YOLO旋转目标检测算法能够同时检测目标的类别和旋转角度。这对于许多实际应用场景至关重要,例如安防监控、工业缺陷检测等。YOLO旋转目标检测算法通过引入旋转锚框和角度回归机制,实现了对旋转目标的高精度检测。
# 2. YOLO旋转目标检测移植实践
### 2.1 移植环境的搭建
#### 2.1.1 环境依赖的安装
YOLOv5旋转目标检测模型的移植需要满足以下环境依赖:
- **操作系统:** Ubuntu 18.04 或更高版本
- **Python:** 3.7 或更高版本
- **PyTorch:** 1.7.1 或更高版本
- **CUDA:** 10.2 或更高版本
- **cuDNN:** 7.6.5 或更高版本
安装依赖项的步骤如下:
```
# 更新系统包
sudo apt update && sudo apt upgrade
# 安装 Python 3.7
sudo apt install python3.7
# 安装 PyTorch
pip install torch torchvision torchaudio
# 安装 CUDA 和 cuDNN
# 根据你的系统和 CUDA 版本,执行以下命令之一:
# CUDA 10.2
sudo apt install cuda-10-2
sudo apt install libcudnn7=7.6.5-1+cuda10.2
# CUDA 11.0
sudo apt install cuda-11-0
sudo apt install libcudnn8=8.0.5-1+cuda11.0
```
#### 2.1.2 YOLOv5框架的获取
YOLOv5框架的官方代码库位于 GitHub 上:https://github.com/ultralytics/yolov5
克隆代码库并安装依赖项:
```
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
```
### 2.2 模型的训练和评估
#### 2.2.1 数据集的准备
旋转目标检测需要使用带有旋转标注的图像数据集。可以使用以下数据集:
- **BDD100K:** https://bdd100k.com/
- **KITTI:** http://www.cvlibs.net/datasets/kitti/eval_object.php
- **ICDAR 2015:** https://rrc.cvc.uab.es/?ch=11&com=tasks
将数据集下载到 `./datasets` 目录下,并使用以下命令创建训练和验证集:
```
python tools/create_rotated_dataset.py --dataset_path ./datasets/BDD100K --output_path ./datasets/BDD100K_rotated
```
#### 2.2.2 训练参数的设置
训练旋转目标检测模型时,需要修改 `./data/hyp.scratch.yaml` 文件中的训练参数。主要参数设置如下:
- **batch_size:** 训练批次大小,根据显存大小调整。
- **epochs:** 训练轮数,一般为 300-500。
- **lr0:** 初始学习率,一般为 0.01。
- **warmup_epochs:** 学习率热身轮数,一般为 5-10。
- **weight_decay:** 权重衰减,一般为 0.0005。
- **box:** 边界框相关参数,包括 `xywhc`(中心点、宽高、旋转角)的损失权重。
- **cls:** 分类损失权重。
- **obj:** 目标存在损失权重。
#### 2.2.3 模型的评估和优化
训练完成后,可以使用以下命令评估模型:
```
python tools/test.py --data ./datasets/BDD100K_rotated.yaml --weights ./weights/yolov5s-rotated.pt --img-size 640
```
评估结果将显示在控制台中,包括平均精度(mAP)、召回率和准确率等指标。
根据评估结果,可以调整训练参数或数据增强策略来优化模型性能。
# 3.1 目标检测算法的集成
**3.1.1 YOLOv5模型的部署**
在实战应用中,需要将训练好的YOLOv5模型部署到实际的系统中。常见的部署方式有:
1. **ONNX导出:**将YOLOv5模型导出为ONNX格式,然后使用ONNX Runtime等框架进行部署。
2. **TensorRT优化:**使用TensorRT对YOLOv5模型进行优化,以提高推理速度和降低延迟。
3. **C++部署:**将YOLOv5模型编译为C++代码,直接在C++程序中调用模型进行推理。
**部署代码示例:**
```cpp
#include <opencv2/opencv.hpp>
#include <yolov5.h>
int main() {
// 加载模型
YOLOv5 model("yolov5s.onnx");
// 加载图像
cv::Mat image = cv::imread("image.jpg");
// 推理
std::vector<Detection> detections = model.detect(image);
// 处理检测结果
...
}
```
**3.1.2 检测结果的处理**
目标检测模型输出的检测结果通常包含以下信息:
* **类别:**检测到的目标类别
* **置信度:**模型对检测结果的置信度
* **边界框:**目标在图像中的位置和大小
在实际应用中,需要对检测结果进行进一步的处理,例如:
*

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《yolo旋转目标检测移植》专栏是一份全面的指南,旨在帮助开发人员轻松移植和优化yolo旋转目标检测算法。专栏涵盖了从原理到实践的各个方面,包括移植指南、常见问题解答、性能优化秘籍和实战案例。通过深入的技术分析和详细的说明,专栏揭示了移植过程中的坑和解决方案,并提供了提高性能和效率的策略。此外,专栏还提供了性能评估、部署和维护指南,以及性能瓶颈分析和调优技巧。无论您是刚开始移植yolo旋转目标检测还是寻求提升性能,本专栏都为您提供了全面的资源和专家指导,让您轻松移植,快速上手,并获得最佳的性能和体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
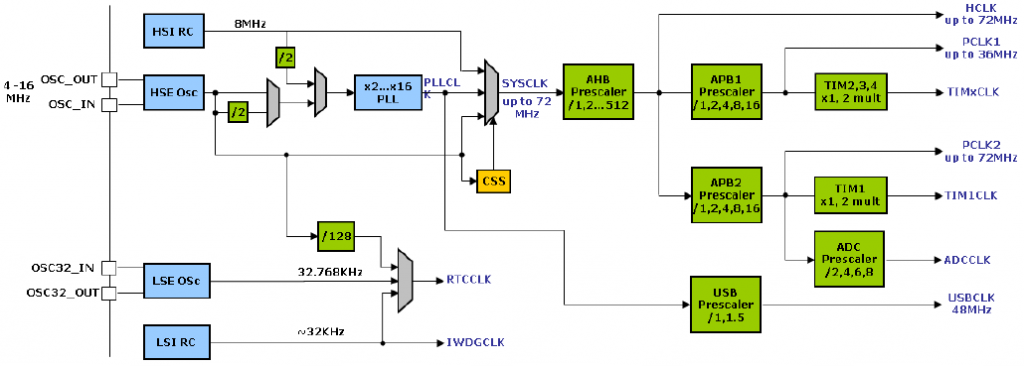
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
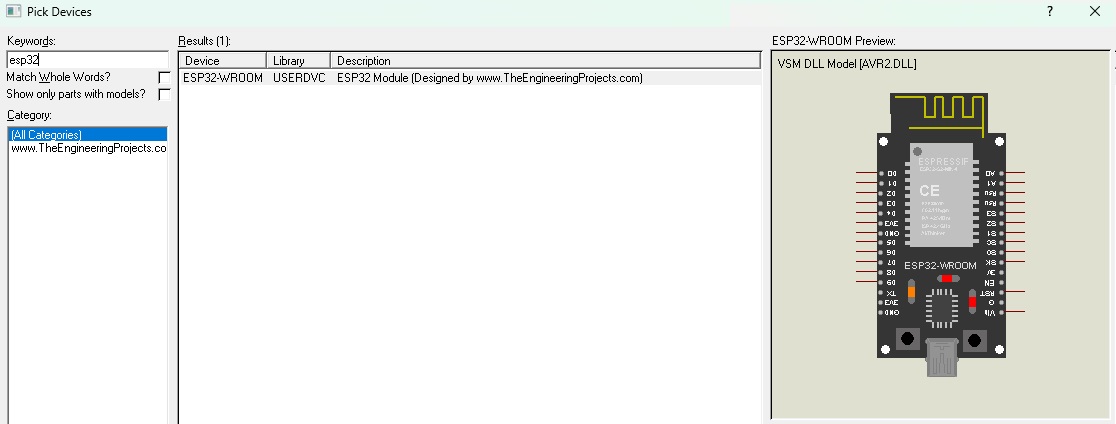
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )