三菱PLC与台达VFD-L通讯优化实战:稳定数据传输的5大策略
发布时间: 2024-12-16 20:16:24 阅读量: 4 订阅数: 6 

三菱PLC_与台达VFD-L_变频器通讯(RS485)程序

参考资源链接:[三菱PLC与台达VFD-L变频器RS485通讯详解及设置](https://wenku.csdn.net/doc/6451ca45ea0840391e7382a7?spm=1055.2635.3001.10343)
# 1. 三菱PLC与台达VFD-L通讯概述
在工业自动化领域,实现设备之间的有效通信是至关重要的。三菱PLC(可编程逻辑控制器)与台达VFD-L(变频器)之间的通讯连接,是许多制造系统中常见的任务。这种通讯能够让PLC控制变频器的运行,从而精确控制电机的速度和扭矩。
在本章中,我们将探讨三菱PLC与台达VFD-L通讯的基本概念和要点。我们会讨论如何配置这两种设备以实现无缝通讯,以及可能遇到的一些常见问题和解决方案。接下来的章节将深入探讨具体的通讯协议、数据格式、错误检测机制,以及如何优化数据传输和通讯稳定性。通过这些讨论,读者将获得实现高效、稳定通讯的实用知识和技术。
# 2. 通讯协议基础和数据格式
## 2.1 通讯协议的理论基础
### 2.1.1 三菱PLC通讯协议简介
三菱PLC(Programmable Logic Controller)使用的通讯协议主要包括MELSEC协议和CC-Link协议。MELSEC协议是三菱电机自己开发的一套通讯协议,分为串行通讯和网络通讯两大类。在串行通讯中,最为常见的有RS-422/485协议,它们广泛应用于低速通讯环境。在以太网通讯方面,三菱PLC支持Modbus TCP、Ethernet/IP、CC-Link IE等多种工业通讯协议,满足不同场合的需求。
三菱PLC通讯协议的一个重要特点就是具备高度的可靠性和兼容性,能够支持各种通讯速率,以及灵活的网络拓扑结构。开发者在设计与三菱PLC通讯的系统时,需要遵循这些协议的规定,保证数据的准确传输。
### 2.1.2 台达VFD-L通讯协议简介
台达VFD-L系列变频器支持多种通讯协议,包括Modbus RTU、BACnet以及专用于台达设备的协议。Modbus RTU是一种广泛应用于工业通讯的串行协议,它基于主从架构,能够实现简单的数据交换。
台达变频器的通讯协议不仅支持标准的功能码,还具有特定的功能码来实现复杂的功能,例如对变频器参数的读写、状态监控等。通讯接口一般为RS-485接口,虽然这种方式的通讯速率有限,但在近距离和低数据量的场合下足够使用。
## 2.2 数据格式与编码规则
### 2.2.1 数据格式的种类和选择
在通讯协议中,数据格式的定义至关重要,它关系到数据在传输过程中的准确性和效率。数据格式一般可以分为二进制格式和文本格式。二进制格式具有更高的传输效率和解析速度,但不如文本格式直观易懂;文本格式易于阅读和调试,但往往需要更多的传输空间。
在实际应用中,选择何种数据格式需要根据通讯的实时性要求、系统的资源消耗以及开发的便利性等多方面因素综合考虑。例如,对于通讯实时性要求高的场合,更推荐使用二进制格式以提高数据处理速度。
### 2.2.2 字节序列与编码的转换方法
在通讯过程中,经常需要将各种数据转换为统一的字节序列进行传输,而接收端则需要将这些字节序列还原成原始数据。这种转换涉及到了编码规则,比如整数、浮点数在内存中如何存储,以及字符如何编码为字节等。
对于整数的编码,常见的有小端序(Least Significant Byte first)和大端序(Most Significant Byte first)。小端序将低字节放在前面,而大端序则相反。浮点数在IEEE 754标准中定义了编码方式,分为单精度和双精度。字符编码常用ASCII或者Unicode。开发者在进行通讯编程时,必须确保发送端和接收端使用相同的编码规则,否则可能导致数据错误。
### 2.2.3 转换方法的实践应用
下面提供一个简单的示例代码,展示如何在Python中进行字节序列和整数的转换。
```python
def int_to_bytes(number, length):
"""将整数转换为指定长度的字节序列"""
if length == 1:
return number.to_bytes(length, 'big')
elif length == 2:
return (number >> 8).to_bytes(length, 'big') + (number & 0xFF).to_bytes(length, 'big')
elif length == 4:
return (number >> 24).to_bytes(length, 'big') + \
((number >> 16) & 0xFF).to_bytes(length, 'big') + \
((number >> 8) & 0xFF).to_bytes(length, 'big') + \
(number & 0xFF).to_bytes(length, 'big')
else:
raise ValueError("Unsupported length")
def bytes_to_int(bytes_data):
"""将字节序列转换为整数"""
return int.from_bytes(bytes_data, 'big')
# 示例:整数转换为字节序列
number = 0x12345678
bytes_sequence = int_to_bytes(number, 4)
print(f"字节序列为: {bytes_sequence.hex()}") # 输出: 12345678
# 示例:字节序列转换为整数
recovered_number = bytes_to_int(bytes.fromhex("12345678"))
print(f"恢复的整数为: {recovered_
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
小米鲁班MTB软件深度剖析:掌握设计精髓,实现高效开发

参考资源链接:[小米手机鲁班MTB V6.0.5-13-33软件参数调整指南](https://wenku.csdn.net/doc/jmd7inyjra?spm=1055.2635.3001.10343)
# 1. 小米鲁班MTB软件概述
小米鲁班MTB软件作为小米公司的新一代管理工具,为企业的项目管
【RX N5多任务处理】:提升性能的4项关键策略

参考资源链接:[Nextchip N5 RX规格书v0.0版本发布](https://wenku.csdn.net/doc/45bayfzh7a?spm=1055.2635.3001.10343)
# 1. 多任务处理在RX N5中的重要性
多任务处理是现代操作系统和微处理器设计的关键组成部分。随着计算机科学的
三菱M70参数全面解读:5步优化设备性能的秘密武器

参考资源链接:[三菱M70关键参数详解:系统、轴数与控制设置](https://wenku.csdn.net/doc/249i46rdgf?spm=1055.2635.3001.10343)
# 1. 三菱M70数控系统的概述
数控系统是现代制造业的核心,它决定着机械设备运行的精度与效率。三菱M70数控系统作为业界一款较为先进的数控系统,广泛应用于各种精密加工设备中。它具备多种高级功能,如自适应控制、多
ELMO驱动器故障急救手册:10大常见问题及快速解决方案

参考资源链接:[ELMO驱动器配置与故障排除指南](https://wenku.csdn.net/doc/6462df54543f844488998bf7?spm=1055.2635.3001.
Sentinel-1 数据集分析:SNAP 遥感数据处理的高效之道

参考资源链接:[SNAP教程:哨兵-1 SAR数据处理入门与关键操作](https://wenku.csdn.net/doc/6401abc5cce7214c316e9718?spm=1055.2635.3001.10343)
# 1. 遥感数据处理概述
遥感技术是通过不
GeoDa坐标系转换完全指南:地理空间数据坐标体系掌握
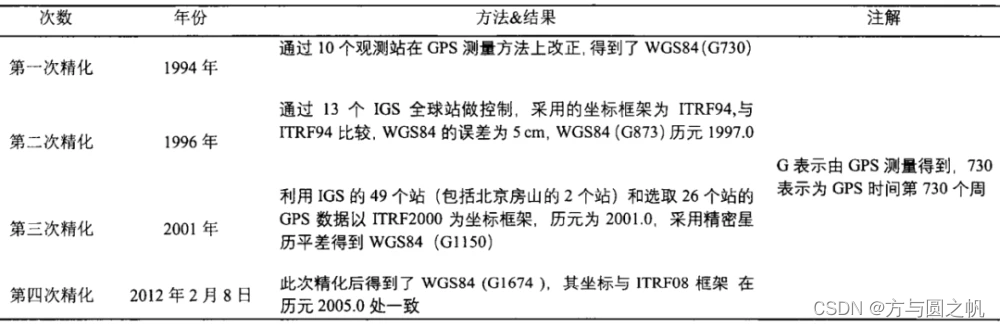
参考资源链接:[GeoDa使用手册(中文版)](https://wenku.csdn.net/doc/6412b654be7fbd1778d4655b?spm=1055.2635.3001.10343)
# 1. 坐标系转换的基础理论
在地理信息系统(GIS)应用中,坐标系转换是一个至关重要且广泛存在的技术需求。本章将为读者提供坐标系转换的基本概念、数学模型和分类方法,作为深入理解GeoDa等GIS
APT与PPA管理:Ubuntu 14.04软件控制的艺术
参考资源链接:[ubuntu-14.04-desktop-amd64.iso(网盘链接,永久有效)](https://wenku.csdn.net/doc/6412b76ebe7fbd1778d4a452?spm=1055.2635.3001.10343)
# 1. APT与PPA在Ubuntu中的角色与重要性
## 1.1 Ubuntu软件管理概述
Ubunt
EIDORS文档样式定制:个性化外观的终极指南

参考资源链接:[EIDORS教程:电阻抗层析成像步骤解析](https://wenku.csdn.net/doc/62x8x7s0q8?spm=1055.2635.3001.10343)
# 1. EIDORS文档样式定制概述
在信息技术不断进步的今天,文档的样式定制已经成为提升用户体验和品牌价值的重要手段。EIDORS文档样式
【深度学习模型部署】:深入模型转换的实践技术

参考资源链接:[MARS使用教程:代码与数据导出](https://wenku.csdn.net/doc/5vsdzkdy26?spm=1055.2635.3001.10343)
# 1. 深度学习模型部署
【数据质量控制】:云总线平台确保数据准确性的实践方法
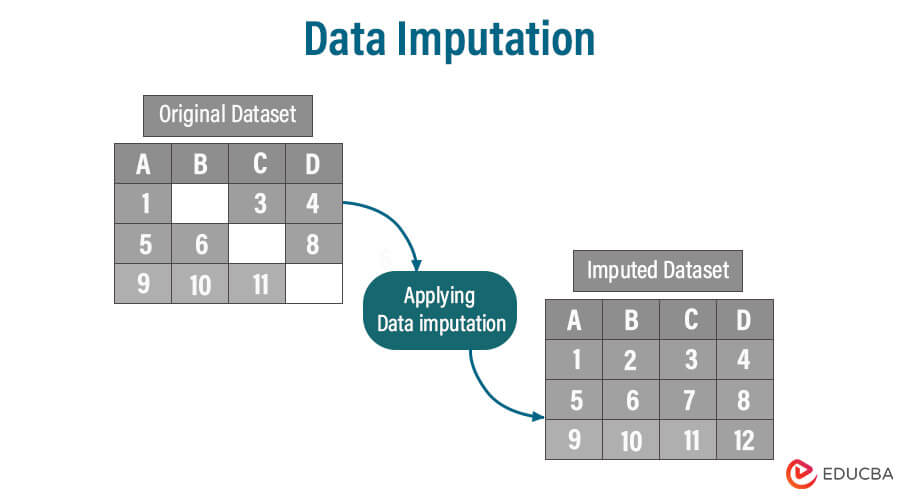
参考资源链接:[阿里云服务总线CSB操作手册](https://wenku.csdn.net/doc/7gabnevyke?spm=1055.2635.3001.10343)
# 1. 数据质量控制在云总线平台的重要性
在当今大数据时代,数据已成为企业和组织最为重要的资产之一。随着企业上云和数字化转型的不断推进,数据质量控制在云总线平台中的作用愈发重要。数据质量直接影响到决策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )