【ZKTime考勤数据库案例分析】:常见问题与解决方案
发布时间: 2024-12-16 03:28:59 阅读量: 2 订阅数: 5 
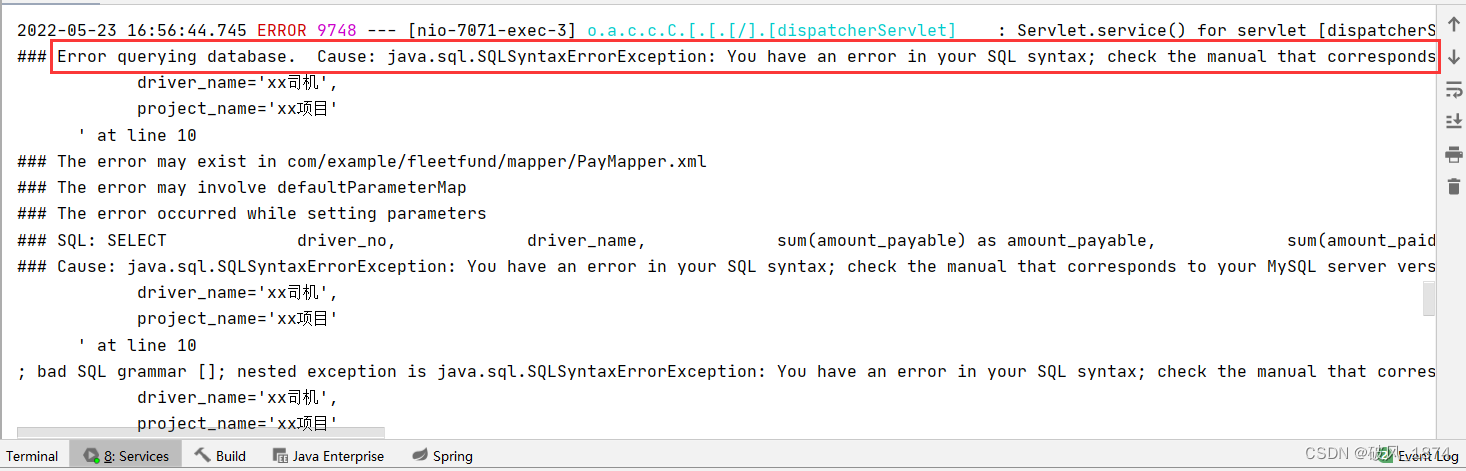
参考资源链接:[中控zktime考勤管理系统数据库表结构优质资料.doc](https://wenku.csdn.net/doc/2phyejuviu?spm=1055.2635.3001.10343)
# 1. ZKTime考勤系统概述
考勤系统在现代企业人力资源管理中扮演着至关重要的角色,有效地管理着员工的工作时间和出勤情况。ZKTime考勤系统以其高效的管理和简便的操作,成为了众多企业信赖的考勤解决方案。本文将对ZKTime考勤系统进行系统性的概述,旨在使读者对其有一个全面的认识。我们将从系统的基本功能入手,深入探讨其背后的技术实现,并分析在使用中可能遇到的问题,提供针对性的解决方案。最后,我们将展望ZKTime考勤系统的发展前景,探讨如何利用新兴技术进一步提升其智能化水平。随着企业对考勤数据管理需求的增长,ZKTime考勤系统如何适应这些变化,以及如何为企业提供更为精准和高效的考勤管理服务,将是本章的重点讨论内容。
# 2. ZKTime考勤数据库架构
### 2.1 数据库设计理论基础
在构建高效、可靠的考勤系统时,数据库的设计至关重要。ZKTime考勤系统依托先进的数据库理论来确保其数据组织和处理的科学性。
#### 2.1.1 数据库规范化理论
数据库规范化是保证数据库结构合理、数据冗余最小化的过程。规范化理论主要包括:
1. **第一范式(1NF)**:确保每个字段都是原子性的,不可再分。
2. **第二范式(2NF)**:在1NF的基础上,要求非主属性完全依赖于主键。
3. **第三范式(3NF)**:在2NF的基础上,消除传递依赖,即非主属性不依赖于其他非主属性。
规范化有助于提高数据的一致性和减少数据冗余,但过度规范化可能导致查询性能下降,因此需要根据实际情况作出平衡。
```sql
-- 示例SQL语句展示规范化操作
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
dept_name VARCHAR(50),
dept_head INT
);
-- 提升到第三范式,消除冗余
CREATE TABLE departments (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50),
dept_head INT
);
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
dept_id INT,
FOREIGN KEY (dept_id) REFERENCES departments(dept_id)
);
```
#### 2.1.2 数据库性能优化原则
优化原则包括但不限于:
- **索引优化**:合理使用索引可以显著提高查询速度。
- **查询优化**:优化SQL语句,减少不必要的数据处理。
- **事务优化**:合理控制事务的大小和复杂度,防止锁资源竞争。
- **缓存机制**:使用内存缓存减少对数据库的访问。
### 2.2 ZKTime数据库结构分析
ZKTime考勤系统的数据库结构设计考虑了考勤数据的特殊性,以满足实时性和准确性的需求。
#### 2.2.1 核心表结构解读
核心表是存储员工考勤信息的基础。以员工信息表(employees)和考勤记录表(attendance_records)为例:
- **员工信息表(employees)**:存储员工基本信息和所属部门信息。
- **考勤记录表(attendance_records)**:记录每一次打卡的具体时间和地点。
```sql
-- 员工信息表结构示例
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
dept_id INT,
hire_date DATE
);
-- 考勤记录表结构示例
CREATE TABLE attendance_records (
record_id INT PRIMARY KEY,
emp_id INT,
check_in_time DATETIME,
check_out_time DATETIME,
location VARCHAR(255),
FOREIGN KEY (emp_id) REFERENCES employees(emp_id)
);
```
#### 2.2.2 索引策略与查询优化
索引能够加速数据检索速度,但不当的索引设置同样会拖慢写入速度。因此索引策略至关重要。
- **单列索引**:针对单个字段建立索引,如员工ID或打卡时间。
- **复合索引**:针对两个或两个以上的字段建立索引,适用于多条件查询。
- **查询优化**:编写高效的SQL语句,例如使用`JOIN`代替子查询,使用`LIMIT`限制查询结果。
```sql
-- 单列索引示例
CREATE INDEX idx_emp_id ON attendance_records(emp_id);
-- 复合索引示例
CREATE INDEX idx_check_in_time_location ON attendance_records(check_in_time, location);
-- 查询优化示例
-- 假设要查询某个员工的考勤记录,避免使用子查询
SELECT * FROM attendance_records WHERE emp_id = ? LIMIT 100;
```
### 2.3 考勤数据的逻辑组织
考勤数据的存储逻辑影响着数据的访问效率和系统的可靠性。
#### 2.3.1 考勤记录的存储逻辑
为了提高检索效率,可以按照时间序列存储考勤记录,以日期为单位分区。
```sql
-- 创建分区表
CREATE TABLE attendance_records_partitioned (
record_id INT PRIMARY KEY,
emp_id INT,
check_in_time DATETIME,
check_out_time DATETIME,
location VARCHAR(255),
FOREIGN KEY (emp_id) REFERENCES employees(emp_id)
) PARTITION BY RANGE (UNIX_TIMESTAMP(check_in_time)) (
PARTITION p202301 VALUES LESS THAN (UNIX_TIMESTAMP('2023-02-01'
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【进销存管理系统架构设计】:揭秘高效可扩展业务系统的构建秘诀
参考资源链接:[进销存管理系统详细设计:流程、类图与页面解析](https://wenku.csdn.net/doc/6412b5b2be7fbd1778d44129?spm=1055.2635.3001.10343)
# 1. 进销存管理系统概述
进销存管理系统是企业进行日常业务活动的核心,它覆盖了商品的采购、销售和库存管理三大板块。本章将对进销存管理系统进行全面概述,为读者构建起一
【揭秘电路板设计】:PADS四层板盲孔技术应用与效率提升

参考资源链接:[PADS四层PCB盲孔的Gerber导出操作说明.pdf](https://wenku.csdn.net/doc/644bbd8efcc5391368e5f918?spm=1055.2635.3001.10343)
# 1. PADS软件基础与四层板设计概述
在电子设计自动化(EDA)领域,PADS软件作为一款流行的P
控制系统的加速器:RSLogix5000 PIDE指令响应性提升技巧

参考资源链接:[RSLogix5000中的PIDE指令详解:高级PID控制与操作模式](https://wenku.csdn.net/doc/6412b5febe7fbd1778d45211?spm=1055.2635.3001.10343)
# 1. RSLogix5000 PIDE指令
【内存管理艺术】:在CCS6.0中优化内存使用避免泄漏
参考资源链接:[CCS6.0安装与使用教程:从入门到精通](https://wenku.csdn.net/doc/7m0r9tckqt?spm=1055.2635.3001.10343)
# 1. 内存管理基础
在计算机系统中,内存是至关重要的资源之一,它负责存储数据和程序指令。合理管理内存资源不仅可以提高系统的运行效率,还能避免资源浪费以及
【Desigo CC 系统概述】:楼宇自动化的新视界

参考资源链接:[Desigo CC 培训资料.pdf](https://wenku.csdn.net/doc/6412b739be7fbd1778d49876?spm=1055.2635.3001.10343)
# 1. Desigo CC系统概念与架构
## Desigo CC系统简介
Desigo CC,作为楼宇自动化和智能建
无线充放电模块集成方案速成:T3168模块应用实战指南
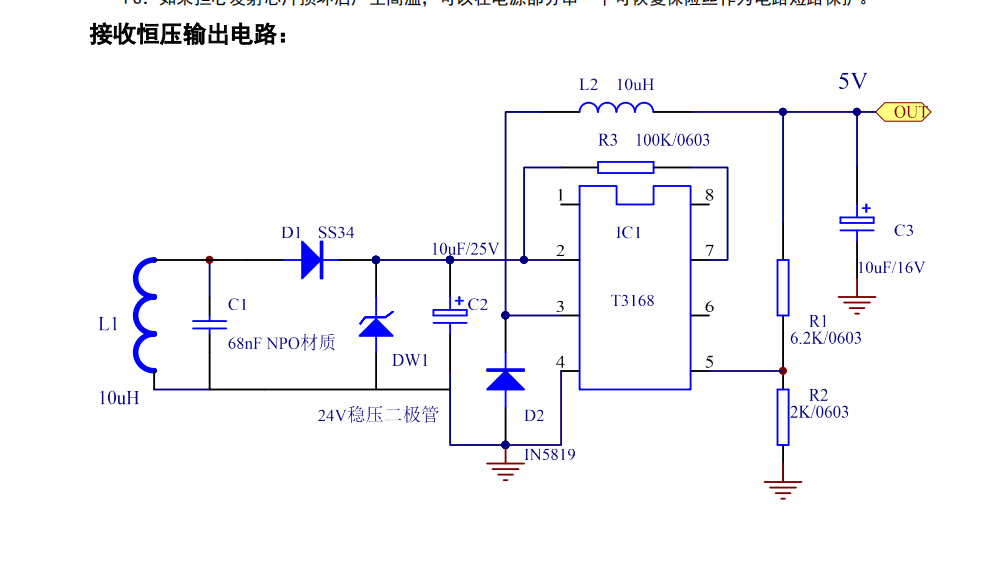
参考资源链接:[XKT-510与T3168:无线充电模块元器件详解与设计指南](https://wenku.csdn.net/doc/645daadc5928463033a1290f?spm=1055.2635.3001.10343)
# 1. 无线充放电技术概述
## 1.1 无线充放电技术的起源与演进
无线充放电技术起源于20世纪末期,其概念是基于电磁感应原理,用户无需插入电源即
【性能优化框架】:构建五维视角下的DSP程序性能测试策略

参考资源链接:[DSP程序运行时间测量:5种方法详解及代码示例](https://wenku.csdn.net/doc/6412b6
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )