Linux内核模块的结构与生命周期
发布时间: 2024-01-05 07:01:05 阅读量: 71 订阅数: 23 
# 第一章:引言
## 1.1 为什么需要内核模块
在Linux操作系统中,内核扮演着非常重要的角色。它负责管理系统的各种硬件资源、提供系统调用接口、处理各种中断等。然而,内核并不是一个"完美"的实现,可能存在着一些功能的缺失或者需要定制化的需求。在这种情况下,内核模块的出现便弥补了这一缺失。内核模块可以动态地向内核添加代码,以扩展、修改或增强内核的功能。这样就能够在不重新编译整个内核的情况下,对内核进行定制化开发。
## 1.2 Linux内核模块的定义和作用
Linux内核模块可以简单地理解为一段可插入内核的代码,它不会独立运行,而是依附于内核存在。内核模块的作用主要有两个方面:
- 扩展内核功能:内核模块可以向内核添加新的功能和驱动程序,从而满足特定的需求。例如,我们可以通过编写一个内核模块来支持新硬件设备。
- 修改内核行为:内核模块可以修改内核的行为,例如更改内核参数、调整内核策略等。这样可以为不同的用户或应用程序提供不同的内核环境。
总之,内核模块的存在使得Linux内核具有了更高的灵活性和可定制性,可以根据用户的实际需求进行个性化的开发和优化。
接下来,我们将深入探讨内核模块的基本结构。
### 2. 内核模块的基本结构
内核模块是一种可以动态加载到Linux内核中并扩展其功能的代码。了解内核模块的基本结构对于编写和维护内核模块至关重要。本节将介绍内核模块的基本结构,包括模块的源代码文件和Makefile、初始化和清理函数、模块参数和许可证声明等内容。
#### 2.1 模块的源代码文件和Makefile
通常情况下,一个内核模块由一个或多个源代码文件组成。在使用C语言编写内核模块时,每个源文件都应包含必要的头文件,并实现初始化和清理函数。此外,为了方便编译和构建,需要编写一个Makefile来定义编译规则和依赖关系。
```c
// 模块源代码文件 example_module.c
#include <linux/init.h>
#include <linux/module.h>
static int __init example_init(void) {
printk(KERN_INFO "Example module initialized\n");
return 0;
}
static void __exit example_exit(void) {
printk(KERN_INFO "Example module removed\n");
}
module_init(example_init);
module_exit(example_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("Example Kernel Module");
```
```make
# Makefile
obj-m += example_module.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
```
在上面的示例中,我们展示了一个简单的内核模块源代码文件和对应的Makefile。源代码文件包含了模块的初始化和清理函数,并使用了Linux内核模块的宏来定义这些函数。Makefile中定义了obj-m变量来指定要构建的模块,并包含了编译和清理规则。
#### 2.2 初始化和清理函数
内核模块需要包含初始化和清理函数,在模块加载和卸载时会分别调用这两个函数。初始化函数通常用于注册模块的功能,而清理函数则用于注销这些功能并释放资源。这两个函数使用特定的宏进行定义,以确保在模块加载和卸载时被正确调用。
#### 2.3 模块参数和许可证声明
内核模块可以接受参数,这些参数可以在加载模块时进行配置。为了支持模块参数,需要在模块中定义相应的变量,并使用特定的宏进行声明。此外,模块还需要包含许可证声明和作者信息,以确保遵守相应的许可证规定。
在下一节中,我们将讨论内核模块的加载和卸载过程,以及使用insmod和rmmod命令来进行操作。
### 3. 内核模块的加载和卸载
在前面的章节中,我们已经了解了内核模块的基本结构和编译安装方法。本章节将介绍内核模块的加载和卸载方式,以及模块的依赖关系和加载卸载流程。
#### 3.1 使用insmod和rmmod加载和卸载模块
内核模块可以通过insmod命令加载,使用rmmod命令卸载。这两个命令是Linux内核提供的工具,用于加载和卸载内核模块。
使用insmod命令加载模块的语法为:
```shell
insmod module_name
```
其中,module_name为要加载的模块名称。加载成功后,内核模块就会被加载到内核的模块列表中。
使用rmmod命令卸载模块的语法为:
```shell
rmmod module_name
```
其中,module_name为要卸载的模块名称。卸载成功后,内核模块会从内核的模块列表中移除。
#### 3.2 模块的依赖关系和自动加载
在加载内核模块时,有时候会发现一些模块依赖于其他模块,这就涉及到了模块的依赖关系。例如,模块A依赖于模块B,那么在加载模块A之前,需要先加载模块B。
为了自动解决模块的依赖关系,Linux内核提供了modprobe命令。modprobe命令会自动加载指定模块,并且会根据模块的依赖关系自动加载所依赖的其他模块。
使用modprobe命令加载模块的语法为:
```shell
modprobe module_name
```
其中,module_name为要加载的模块名称。modprobe命令会自动加载模块及其依赖的其他模块。
#### 3.3 模块的加载和卸载流程
在加载内核模块时,主要的步骤如下:
1. 首先,检查模块的依赖关系,确保所有依赖的模块都已经加载。
2. 然后,将模块的二进制代码加载到内核中,并分配内存空间。
3. 接着,执行模块的初始化函数,完成模块的初始化操作。
4. 最后,将模块添加到内核的模块列表中,表示该模块已经加载成功。
在卸载内核模块时,主要的步骤如下:
1. 首先,检查是否有其他模块依赖于当前模块,如果有,则卸载失败。
2. 然后,执行模块的清理函数,完成模块的清理操作。
3. 接着,释放模块占用的内存空间。
4. 最后,将模块从内核的模块列表中移除,表示该模块已经卸载成功。
通过加载和卸载内核模块,可以在运行时动态地扩展和收缩系统功能。这种灵活性使得内核模块在Linux系统中得到了广泛的应用。
### 结论
本章节介绍了内核模块的加载和卸载方式,包括使用insmod和rmmod命令加载和卸载模块,以及使用modprobe命令自动解决模块的依赖关系。同时,我们还了解了模块的加载和卸载流程,以及内核模块的灵活性和应用场景。下一章节将介绍内核模块的编译和安装方法。
### 4. 内核模块的编译和安装
编写好内核模块的源代码后,我们需要将其编译成可加载的内核模块,然后进行安装和卸载。
#### 4.1 基本编译步骤和工具
在编译内核模块之前,需要确保已经安装了必要的开发工具和内核源代码。以下是编译内核模块的基本步骤:
1. 下载并解压内核源代码。
2. 进入内核源代码目录,使用`make menuconfig`命令配置内核,确保加载了所需的模块支持。
3. 进入内核模块的源代码目录,创建一个`Makefile`文件,用于编译和链接内核模块。
4. 编写内核模块的源代码文件。
5. 使用`make`命令编译内核模块,生成`.ko`文件。
在编译过程中,我们可以使用一些工具进行辅助,例如 `gcc` 编译器、`insmod` 和 `rmmod` 命令等。
#### 4.2 使用Kbuild系统编译模块
`Kbuild` 是一个内核构建系统,它提供了一种简化和自动化的方式来编译内核模块。
在内核模块的源代码目录中,创建一个名为 `Kbuild` 的文件,并在其中添加编译规则和依赖信息。以下是一个示例:
```makefile
# Makefile
obj-m += my_module.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
$(MAKE) -C $(KDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KDIR) M=$(PWD) clean
```
在上面的示例中,`obj-m` 定义了我们要编译的模块文件。`KDIR` 定义了内核源代码的路径。`PWD` 获取当前目录的路径。
通过执行 `make` 命令,可以编译出内核模块的二进制文件。
#### 4.3 模块的安装和卸载
加载和卸载内核模块可以使用 `insmod` 和 `rmmod` 命令。以下是示例命令:
```bash
$ sudo insmod my_module.ko # 加载模块
$ sudo rmmod my_module # 卸载模块
```
加载模块时,可以使用`-f`参数指定模块源代码文件的路径。
为了方便起见,可以将加载和卸载模块的命令写入脚本文件。例如,创建一个名为 `load.sh` 的脚本文件,内容如下:
```bash
#!/bin/bash
sudo insmod my_module.ko
```
然后在终端中执行 `./load.sh` 命令即可加载模块。
至此,我们已经完成了内核模块的编译和安装过程,可以开始调试和测试内核模块。
#### 总结
本章介绍了内核模块的编译和安装过程。通过使用 `Makefile` 或 `Kbuild` 系统,可以简化和自动化内核模块的编译。同时,通过 `insmod` 和 `rmmod` 命令,可以加载和卸载内核模块。在实际项目中,需要根据具体需求进行定制化编译和安装流程。
在下一章中,将介绍内核模块的调试和错误处理方法。
### 5. 内核模块的调试和错误处理
在开发和使用内核模块的过程中,调试和错误处理是非常重要的环节。本章将介绍一些常用的调试工具和技巧,以及处理错误和记录日志的方法。
#### 5.1 调试工具和技巧
在调试内核模块时,有一些常用的工具可以帮助开发者查找和解决问题。以下是一些常用的调试工具和技巧:
1. printk函数:printk是Linux内核中的一个函数,可以将信息输出到内核日志中。在调试内核模块时,可以使用printk来输出变量的值、函数的调用路径等信息,以便定位问题所在。例如:
```c
int foo = 10;
printk(KERN_INFO "The value of foo is %d\n", foo);
```
2. GDB调试器:GDB是一个强大的调试工具,可以用来调试内核模块。通过在模块代码中加入调试符号,然后使用GDB来启动内核并调试模块,可以方便地查看变量的值、设置断点、单步执行等。具体使用方法可以参考GDB的文档和教程。
3. printk_ratelimit函数:当内核模块中的printk语句过于频繁时,会导致内核日志溢出或性能下降。为了避免这种情况,可以使用printk_ratelimit函数来限制printk语句的输出频率,并在一定时间内只输出一次。
```c
int foo = 10;
printk_ratelimited(KERN_INFO "The value of foo is %d\n", foo);
```
#### 5.2 错误处理和日志记录
在编写内核模块时,错误处理和日志记录是非常重要的。当模块发生错误时,应该采取相应的措施来处理错误,并记录相关信息以便查看和分析。以下是一些常用的错误处理和日志记录方法:
1. 返回错误码:在模块的函数中,如果发生错误,应该返回适当的错误码,以便上层调用者知道发生了什么错误。例如,可以使用标准的errno.h头文件中定义的错误码来表示不同的错误类型。
```c
int my_function(void)
{
if (condition) {
return -ENOMEM; // 内存分配失败
}
// 正常情况下返回0
return 0;
}
```
2. 使用内核日志:在模块中使用printk来输出错误信息,以便在系统日志中查看。可以使用不同级别的内核日志来区分不同重要程度的错误。例如,使用KERN_ERR表示严重错误,使用KERN_WARNING表示警告信息。
```c
printk(KERN_ERR "An error occurred: %s\n", error_message);
```
3. 错误恢复和清理:在模块中,当发生错误时需要进行一些清理工作和错误恢复操作,以避免系统状态异常。例如,释放已分配的资源、重置数据结构等。
```c
void cleanup_module(void)
{
// 清理操作
if (error) {
// 错误恢复
}
}
```
#### 5.3 内核模块的性能优化和测试
为了提高内核模块的性能,可以采取一些优化措施和进行性能测试。以下是一些常用的性能优化和测试方法:
1. 减少内存使用:内核模块通常运行在有限的资源环境中,因此应该尽量减少内存的使用。可以使用静态分配代替动态分配、减少数据结构的大小等方法来降低内存使用量。
2. 使用高效算法和数据结构:在编写内核模块时,选择合适的算法和数据结构是非常重要的。应该根据模块的需求和场景选择最适合的算法和数据结构,以提高模块的性能。
3. 进行性能测试:对于关键的内核模块,需要进行性能测试以验证其性能。可以使用一些性能测试工具和框架来评估模块的性能,并根据测试结果进行优化。
总结:
本章介绍了在调试和错误处理过程中的常用工具和技巧,包括printk函数、GDB调试器和printk_ratelimit函数。另外,还介绍了错误处理和日志记录的方法,以及如何进行性能优化和测试。在开发和使用内核模块时,合理使用这些方法可以提高模块的可靠性和性能。
下一章将讨论内核模块的未来发展趋势,包括使用场景、开源社区和内核模块的安全性。
## 6. 内核模块的未来发展趋势
随着技术的不断进步和发展,内核模块作为Linux系统的重要组成部分,也在不断演化和发展。本章将探讨内核模块的未来发展趋势,以及相关的使用场景、开源社区和内核模块生态系统、以及内核模块的安全性和可靠性。
### 6.1 内核模块的使用场景和发展方向
内核模块具有良好的灵活性和可扩展性,在不需要重新编译整个内核的情况下,可以动态加载和卸载,从而实现对内核功能的扩展和定制。由于内核模块在运行时可以直接访问内核的数据结构和函数,因此被广泛应用于设备驱动、文件系统、网络协议栈等领域。
随着云计算、物联网、人工智能等新兴技术的快速发展,内核模块的使用场景也在不断扩大。比如,在云计算环境中,可以使用内核模块来优化网络性能、管理虚拟化资源;在物联网中,可以利用内核模块与外设设备进行通信和控制;在人工智能领域,可以通过内核模块来优化计算和存储资源的调度。因此,内核模块将在更多领域发挥重要作用,并且会持续发展和创新。
### 6.2 开源社区和内核模块生态系统
开源社区对于内核模块的发展起到了关键作用。在开源社区的支持和推动下,内核模块的功能不断增强,性能不断提升,稳定性和可靠性也得到了极大地改善。
开源社区中有许多著名的内核模块开发者和贡献者,他们为内核模块的发展做出了巨大贡献。同时,开源社区也提供了丰富的文档和教程,帮助开发者更好地理解和掌握内核模块的开发技术。开源社区还提供了各种工具和平台,方便开发者分享和交流内核模块的经验和成果。
内核模块生态系统也在不断壮大和丰富。越来越多的第三方开发者和厂商加入到内核模块的开发中,推动了内核模块的技术创新和功能扩展。开发者可以通过内核模块生态系统获取到各种现有的内核模块、工具和资源,从而快速开发和部署自己的内核模块。
### 6.3 内核模块的安全性和可靠性
在安全性和可靠性方面,内核模块仍然面临一些挑战。由于内核模块具有直接访问内核的能力,恶意的内核模块可能会破坏系统的稳定性和安全性。因此,内核模块的安全性是一个非常重要的问题。
随着内核模块的使用越来越广泛,也越来越多的关注和研究在内核模块的安全性方面。开发者需要遵循一些安全编程的最佳实践,比如进行输入参数的验证和过滤,进行内存访问的限制和保护,避免使用不安全的API等。
此外,开源社区和厂商也积极投入到内核模块的安全性研究中,推动内核模块的安全性技术的发展和应用。例如,Linux内核社区发布的新版本中,通常会加入一些安全性增强的功能和机制,以提高内核模块的安全性。
总的来说,内核模块在未来的发展中将继续发挥重要作用,其使用场景将更加广泛,其开源社区和生态系统也将更加健全和成熟。同时,内核模块的安全性和可靠性问题也需要得到更多的关注和研究,以确保其在系统运行中的稳定和安全。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Linux内核模块开发》专栏是一本面向Linux内核开发者的入门指南。通过深入剖析Linux内核模块的结构与生命周期,读者将学会编写并初始化清理Linux内核模块。本专栏还涵盖了参数传递、依赖关系、加载顺序的探索,以及动态调试和工具的使用。同时,读者还将学习如何使用Proc文件系统和Sysfs在Linux内核模块中进行信息交互,并通过实战编写一个简单的字符设备驱动模块。进一步,本专栏还探讨了中断处理程序、同步机制和内存管理等重要主题,以及Netlink套接字实现模块间通信、定时器与延时的实现,以及调试与排查内存泄漏的方法。最后,本专栏还讲解了使用ioctl实现设备控制,以及信号处理和任务调度与进程管理的技术。通过学习本专栏,读者将全面了解内核模块开发并掌握各种重要的技术与工具。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
Python编程风格

# 1. Python编程风格概述
Python作为一门高级编程语言,其简洁明了的语法吸引了全球众多开发者。其编程风格不仅体现在代码的可读性上,还包括代码的编写习惯和逻辑构建方式。好的编程风格能够提高代码的可维护性,便于团队协作和代码审查。本章我们将探索Python编程风格的基础,为后续深入学习Python编码规范、最佳实践以及性能优化奠定基础。
在开始编码之前,开发者需要了解和掌握Python的一些核心
Android二维码实战:代码复用与模块化设计的高效方法

# 1. Android二维码技术概述
在本章,我们将对Android平台上二维码技术进行初步探讨,概述其在移动应用开发中的重要性和应用背景。二维码技术作为信息交换和移动互联网连接的桥梁,已经在各种业务场景中得到广泛应用。
## 1.1 二维码技术的定义和作用
二维码(QR Code)是一种能够存储信息的二维条码,它能够以
【MATLAB雷达信号处理】:理论与实践结合的实战教程
# 1. MATLAB雷达信号处理概述
在当今的军事与民用领域中,雷达系统发挥着至关重要的作用。无论是空中交通控制、天气监测还是军事侦察,雷达信号处理技术的应用无处不在。MATLAB作为一种强大的数学软件,以其卓越的数值计算能力、简洁的编程语言和丰富的工具箱,在雷达信号处理领域占据着举足轻重的地位。
在本章中,我们将初步介绍MATLAB在雷达信号处理中的应用,并
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
Vue.js数据绑定与响应式系统:从入门到精通
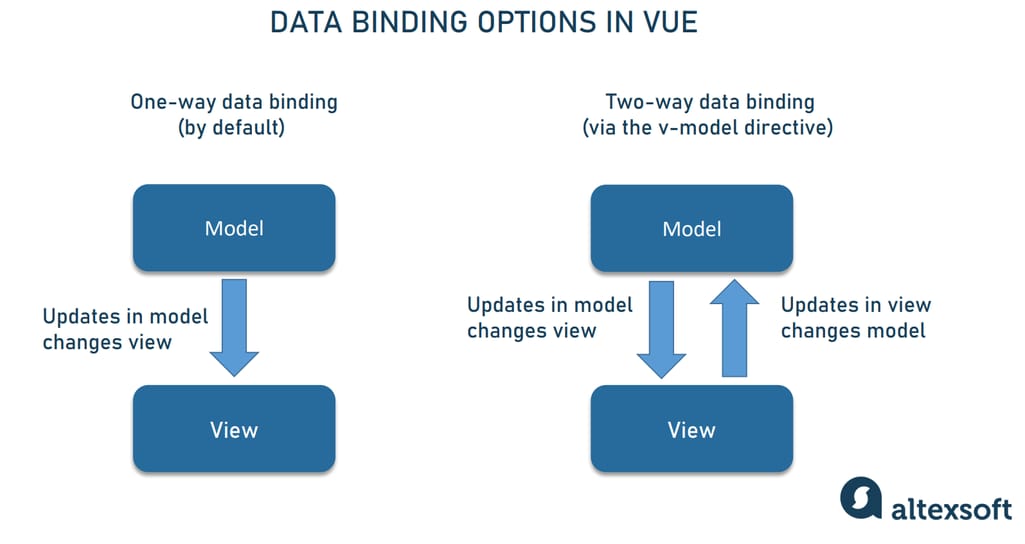
# 1. Vue.js数据绑定基础
## 1.1 Vue.js的数据绑定入门
Vue.js是一个构建用户界面的渐进式框架,其核心是数据驱动与组件化的开发方式。在这一章中,我们将介绍Vue.js如何实现数据和视图之间的双向绑定,这是其作为现代前端框架的基石之一。
在Vue.js中,最基础的数据绑定形式是使用`{{}}`插值表达式,这样可以将数据对象中的属
【制造业时间研究:流程优化的深度分析】

# 1. 制造业时间研究概念解析
在现代制造业中,时间研究的概念是提高效率和盈利能力的关键。它是工业工程领域的一个分支,旨在精确测量完成特定工作所需的时间。时间研究不仅限于识别和减少浪费,而且关注于创造一个更为流畅、高效的工作环境。通过对流程的时间分析,企业能够优化生产布局,减少非增值活动,从而缩短生产周期,提高客户满意度。
在这一章中,我们将解释时间研究的核心理念和定义,探讨其在制造业中的作用和重要性。通过
直播推流成本控制指南:PLDroidMediaStreaming资源管理与优化方案
# 1. 直播推流成本控制概述
## 1.1 成本控制的重要性
直播业务尽管在近年来获得了爆发式的增长,但随之而来的成本压力也不容忽视。对于直播平台来说,优化成本控制不仅能够提升财务表现,还能增强市场竞争力。成本控制是确保直播服务长期稳定运
【电子密码锁用户交互设计】:提升用户体验的关键要素与设计思路

# 1. 电子密码锁概述与用户交互的重要性
## 1.1 电子密码锁简介
电子密码锁作为现代智能家居的入口,正逐步替代传统的物理钥匙,它通过数字代码输入来实现门锁的开闭。随着技术的发展,电子密码锁正变得更加智能与安全,集成指纹、蓝牙、Wi-Fi等多种开锁方式。
## 1.2 用户交互
全球高可用部署:MySQL PXC集群的多数据中心策略

# 1. 高可用部署与MySQL PXC集群基础
在IT行业,特别是在数据库管理系统领域,高可用部署是确保业务连续性和数据一致性的关键。通过本章,我们将了解高可用部署的基础以及如何利用MySQL Percona XtraDB Cluster (PXC) 集群来实现这一目标。
## MySQL PXC集群的简介
MySQL PXC集群是一个可扩展的同步多主节点集群解决方案,它能够提供连续可用性和数据一致
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )