PyLith入门必读:7个步骤带你从安装到高效配置
发布时间: 2024-12-27 08:11:03 阅读量: 36 订阅数: 30 
# 摘要
PyLith是一个功能强大的计算软件,广泛应用于工程领域的数据处理、网络编程、系统管理等多个方面。本文首先介绍了PyLith的基本概念、安装流程以及基本操作和配置,着重阐述了其命令结构、数据类型、操作方法以及调试和优化技巧。随后,本文深入探讨了PyLith在实践应用中的具体场景,包括数据处理、网络编程和系统管理,并展示了其高级应用能力。最后,文章通过实际项目案例分析,展示了PyLith在各类工程问题中的应用效果和潜在价值,强调了其在提升项目效率和数据准确性方面的优势。本文旨在为读者提供一个全面了解和应用PyLith的框架,特别是在复杂工程问题中的解决方案。
# 关键字
PyLith;数据处理;网络编程;系统管理;正则表达式;GUI编程
参考资源链接:[PyLith 2.2.1 用户手册:地球动力学数值模拟](https://wenku.csdn.net/doc/1knsut419g?spm=1055.2635.3001.10343)
# 1. PyLith简介和安装流程
## 1.1 PyLith简介
PyLith是一个开源的有限元模拟软件,主要用于地球动力学模拟、地震波传播模拟和地壳变形模拟等领域。它以其强大的功能和良好的兼容性,在地球科学领域有着广泛的应用。
## 1.2 安装流程
PyLith的安装相对简单,以下是安装步骤:
1. 首先,你需要安装Python环境,因为PyLith是基于Python开发的。
2. 然后,你可以通过Python的包管理工具pip进行安装,只需要在命令行输入以下命令:
```
pip install pylith
```
3. 安装完成后,你可以在Python中输入`import pylith`来测试是否安装成功。
如果遇到任何问题,你可以查阅PyLith的官方文档或者在相关社区寻求帮助。
# 2. PyLith基本操作和配置
## 2.1 PyLith的命令和使用
### 2.1.1 PyLith的命令结构和用法
在开始PyLith的基本命令操作之前,了解PyLith命令结构的组成非常重要,它有助于快速掌握如何使用PyLith进行各种操作。PyLith命令通常遵循以下结构:
```plaintext
pylith [global options] command [command options] [arguments]
```
这里,`global options` 是适用于所有命令的全局选项,`command` 是我们想要执行的特定命令,`command options` 是特定命令的选项,而 `arguments` 是执行该命令所需的具体参数。
例如,我们想要查询PyLith的版本信息,可以使用以下命令:
```plaintext
pylith --version
```
或者如果我们想要查看所有可用的命令及其简短描述,可以使用:
```plaintext
pylith --help
```
命令的使用方式和它们的参数是让PyLith实现其功能的基础。通常情况下,PyLith的每个命令都有一系列可用的选项,这些选项可以用来调整命令的行为。在实际使用中,我们可以通过 `-h` 或 `--help` 参数来查看每个命令的详细使用说明,例如:
```plaintext
pylith run -h
```
这将显示 `run` 命令的详细帮助信息,包括它的每个选项和它们的具体用法。
### 2.1.2 PyLith的基本配置
为了使PyLith按照预期工作,我们需要对其进行适当的配置。PyLith的配置文件通常是一个或多个XML文件,它们定义了各种模拟参数,例如材料属性、边界条件、输出格式等。
配置文件的结构一般如下:
```xml
<configuration>
<materials>
<!-- 定义材料参数 -->
</materials>
<boundary_conditions>
<!-- 定义边界条件 -->
</boundary_conditions>
<!-- 其他必要的配置部分 -->
</configuration>
```
在实际配置PyLith时,主要的步骤包括:
1. 定义仿真的时间范围、时间步长以及求解器的类型。
2. 描述研究域内的材料属性,包括弹性模量、泊松比等。
3. 设置边界条件,例如固定边界或施加压力等。
4. 配置输出格式和输出频率,以便记录仿真结果。
这里有一个简单的配置文件示例:
```xml
<configuration>
<time_step>
<!-- 时间步长设置 -->
</time_step>
<materials>
<!-- 材料属性定义 -->
</materials>
<boundary_conditions>
<!-- 边界条件设置 -->
</boundary_conditions>
<output>
<!-- 输出格式及频率配置 -->
</output>
</configuration>
```
在PyLith中配置仿真的参数是至关重要的,它决定了仿真的质量和准确性。因此,在进行仿真之前,仔细地设置这些参数是必不可少的步骤。通常,配置文件需要根据具体问题进行定制化修改。
配置完成后,我们可以通过以下命令来执行我们的仿真:
```bash
pylith run my_simulation.cfg
```
其中 `my_simulation.cfg` 是我们创建的配置文件名。
## 2.2 PyLith的数据类型和操作
### 2.2.1 PyLith的数据类型
PyLith支持多种数据类型,以便在处理和模拟地质力学问题时能够更加灵活和高效。最常见的数据类型包括:
1. **标量(Scalar)**:表示单个数值的数据类型,如时间、压力等。
2. **向量(Vector)**:表示有方向性的数据类型,如位移、应力等。
3. **张量(Tensor)**:表示多维数据类型,如应变张量、刚度矩阵等。
每种数据类型在PyLith中都有对应的实现方式,允许用户进行复杂的计算和分析。
### 2.2.2 PyLith的操作方法
PyLith提供了丰富的操作方法,这些方法支持对数据类型进行各种数学和物理操作。这些操作通常包括:
- **算数运算**:加、减、乘、除。
- **逻辑运算**:与、或、非、异或等。
- **数学函数**:三角函数、指数函数、对数函数等。
- **积分和微分**:用于计算物理量随时间或空间变化的函数。
例如,对于向量数据类型,我们可以进行加法和点乘运算,如下所示:
```python
import pylith
vector1 = pylith.Vector([1, 2, 3])
vector2 = pylith.Vector([4, 5, 6])
# 向量加法
sum_vector = vector1 + vector2
# 向量点乘
dot_product = vector1.dot(vector2)
print("Sum Vector:", sum_vector)
print("Dot Product:", dot_product)
```
在上述示例中,`Vector` 类被用来创建向量,并执行加法和点乘操作。这些操作是仿真过程中常用的基本操作,它们允许我们对力学问题中的各种物理量进行计算。
此外,PyLith还提供了更多高级的操作方法,比如用于处理网格操作的网格生成器(Mesh Generator)和用于解析复杂几何形状的解析器(Solver)。通过这些高级方法,我们能够创建复杂的模型,为仿真的准确性提供了强有力的支撑。
## 2.3 PyLith的调试和优化
### 2.3.1 PyLith的常见问题及解决方式
在使用PyLith进行模拟的过程中,可能会遇到各种各样的问题。一些常见的问题包括:
1. **收敛性问题**:在模拟迭代过程中,求解器可能无法收敛到一个稳定的解。这通常是由于模型设置不合理或初始条件设置不当造成的。
解决方法包括:
- 检查网格的质量,确保其满足求解器的要求。
- 调整材料属性,使其在物理上更为合理。
- 修改求解器参数,例如时间步长和迭代次数。
2. **内存溢出**:当模型过于复杂时,可能会导致程序运行时内存不足。
解决方法包括:
- 确保计算机有足够的内存来支持模型的复杂度。
- 使用更高效的求解器,减少内存的占用。
3. **输入输出错误**:不正确的输入文件格式或路径设置错误可能导致输入输出错误。
解决方法包括:
- 检查输入文件的格式是否正确。
- 确保所有文件路径都是正确的。
通过细心地检查和调整,我们可以有效地解决这些问题,使得PyLith能够顺畅地运行。
### 2.3.2 PyLith的性能优化方法
为了提高PyLith的性能,我们可以采取以下优化方法:
1. **并行计算**:PyLith支持多核并行计算,这意味着可以通过使用更多的处理器来加速仿真过程。
优化方式:
- 使用 `--num-threads` 参数来指定并行计算的线程数。
- 确保计算机的CPU核心数足够多。
2. **网格优化**:在保持模型准确度的同时,可以通过优化网格来减少计算量。
优化方式:
- 使用自适应网格细化技术,在模型的局部区域增加网格密度。
- 避免网格过度细化,尤其是在模型变化较小的区域。
3. **求解器参数调整**:合理地调整求解器的参数,如时间步长、最大迭代次数等。
优化方式:
- 通过试验和错误来找到求解器的最佳参数设置。
- 使用时间步长和迭代次数的自适应调整策略。
```plaintext
pylith run my_simulation.cfg --num-threads 4
```
通过上述优化方法,我们可以显著提高PyLith的运行效率,并获得更好的模拟结果。因此,在进行复杂的仿真之前,合理地进行性能优化是非常必要的。
# 3. PyLith实践应用
## 3.1 PyLith的数据处理
### 3.1.1 数据的读取和写入
在进行数据处理之前,我们需要了解如何使用PyLith读取和写入数据。PyLith提供了多种方式来处理不同类型的数据,包括文本文件、二进制文件以及数据库交互。这里我们着重介绍如何对常见的文本文件进行读取和写入操作。
```python
from pylith import readers, writers
# 创建一个数据读取器实例,这里以CSV文件为例
data_reader = readers.CsvReader()
# 指定要读取的文件路径
file_path = 'data.csv'
# 读取数据
data = data_reader.read(file_path)
# 显示数据内容
print(data)
# 创建一个数据写入器实例
data_writer = writers.CsvWriter()
# 指定要写入数据的目标文件路径
output_file_path = 'output_data.csv'
# 写入数据到指定文件
data_writer.write(output_file_path, data)
```
在上述代码中,我们首先导入了PyLith的读写模块,然后创建了一个CSV格式的读取器和写入器实例。通过调用`read()`方法,我们读取了指定路径的CSV文件内容到内存中,然后通过调用`write()`方法将内存中的数据写入到新的CSV文件中。这两个方法都有许多参数,可以让我们对数据读写过程进行精细控制,例如指定分隔符、是否包含表头、数据类型转换等。
### 3.1.2 数据的转换和处理
数据读取和写入之后,接下来通常需要对数据进行转换和处理。这可能包括数据清洗、格式转换、数据集合作用等。下面的示例展示了如何对读取的CSV数据进行简单的处理。
```python
import pandas as pd
# 将PyLith读取的数据转换为Pandas DataFrame
df = pd.DataFrame(data)
# 示例:数据清洗 - 去除空值
df_cleaned = df.dropna()
# 示例:数据转换 - 类型转换
df['column_name'] = df['column_name'].astype('int')
# 示例:数据处理 - 数据集合作用
# 假设我们要对某个分类字段进行分组求和
grouped_data = df.groupby('category_field').sum()
# 最后,可以将处理后的数据使用PyLith写入器再次写入到文件中
data_writer.write(output_file_path, grouped_data)
```
在上面的代码中,我们首先将PyLith读取的数据转换为Pandas库的DataFrame对象,这是因为Pandas提供了非常强大的数据处理能力。我们演示了如何使用Pandas进行简单的数据清洗、类型转换和数据集合作用。最终,我们还可以使用之前创建的PyLith写入器将处理后的数据写入到文件中。
## 3.2 PyLith的网络编程
### 3.2.1 PyLith在网络编程中的应用
网络编程是软件开发中常见的需求之一,PyLith通过内置的网络模块,使得网络请求变得简单。以下是如何使用PyLith发送HTTP请求,并处理返回的响应。
```python
from pylith import network
# 创建一个网络请求实例
request = network.Request()
# 指定请求的URL和方法
request.set_url('http://example.com/api/data')
request.set_method('GET')
# 发送请求并接收响应
response = request.send()
# 打印响应的状态码
print(response.status_code)
# 打印响应的内容
print(response.content)
```
在上面的代码中,我们使用PyLith的网络模块创建了一个请求实例,指定了请求的URL和HTTP方法,并发送了请求。网络模块会自动处理HTTP的连接、重试、超时等复杂问题。请求发送后,我们能够获取到响应内容以及状态码等信息。
### 3.2.2 PyLith在网络编程中的高级应用
网络编程的高级应用可能包括请求代理、HTTP头自定义、超时设置等。下面的代码展示了如何设置请求头,以及自定义请求超时时间。
```python
# 在发送请求之前,我们可以添加自定义的HTTP头
request.add_header('User-Agent', 'MyApp/1.0')
request.add_header('Authorization', 'Bearer YOUR_ACCESS_TOKEN')
# 设置请求超时时间(单位:秒)
request.set_timeout(10)
# 现在发送请求,它将包含我们设置的头部和超时
response = request.send()
```
通过设置请求头,我们可以自定义请求的User-Agent标识,或添加必要的认证信息。超时设置可以保证在网络请求不会因为网络问题而无限期等待。通过这些高级设置,PyLith允许开发者更细致地控制网络请求的行为。
## 3.3 PyLith的系统管理
### 3.3.1 PyLith在系统管理中的应用
系统管理是保证IT基础设施稳定运行的重要环节,PyLith通过其系统管理模块提供了一系列工具来帮助我们完成这一任务。例如,我们可以使用PyLith来监控系统资源的使用情况、启动或停止服务、管理日志等。
```python
from pylith import system
# 获取当前系统的CPU使用率
cpu_usage = system.get_cpu_usage()
# 获取当前系统内存使用情况
memory_usage = system.get_memory_usage()
# 打印获取到的信息
print(f"CPU Usage: {cpu_usage}%")
print(f"Memory Usage: {memory_usage}%")
```
上面的代码片段展示了如何使用PyLith的系统管理模块获取当前系统的CPU和内存使用情况,这可以帮助系统管理员了解系统运行状态并做出相应的调整。
### 3.3.2 PyLith在系统管理中的高级应用
在系统管理的高级应用方面,我们可能需要进行更复杂的操作,比如定时任务的设置、环境变量的管理以及系统服务的管理等。
```python
# 设置环境变量
system.set_environment('MY_ENV_VAR', 'MyValue')
# 启动一个服务
system.start_service('my_service_name')
# 停止一个服务
system.stop_service('my_service_name')
# 设置一个定时任务,定期执行一个脚本
system.schedule_task('/path/to/script.sh', interval=3600)
```
通过PyLith的系统管理模块,我们可以设置环境变量来控制应用的行为,管理服务的生命周期,以及设置定时任务来自动化一些系统操作。这些高级功能可以帮助IT运维人员更高效地管理工作负载。
# 4. PyLith进阶应用
## 4.1 PyLith的正则表达式应用
### 正则表达式在PyLith中的应用
正则表达式是一种强大的文本处理工具,它可以用于搜索、匹配和替换字符串中的特定模式。在PyLith中,正则表达式能够帮助开发者更高效地处理文本数据,比如验证输入格式、提取特定数据或对数据集进行筛选。
正则表达式的使用通常伴随着特定的模式和标记。例如,`\d`表示数字,`\w`代表字母或数字,`\s`代表空白字符,`*`表示前面的元素可以出现零次或多次,等等。在PyLith中,可以使用Python的`re`模块来执行正则表达式操作。
下面是一个基本示例,演示如何使用正则表达式在PyLith中匹配电子邮件地址:
```python
import re
# 编译正则表达式模式
email_pattern = re.compile(r"[^@]+@[^@]+\.[^@]+")
# 搜索文本中的电子邮件地址
text = "Please contact us at support@example.com or sales@example.org"
emails = email_pattern.findall(text)
print(emails) # 输出: ['support@example.com', 'sales@example.org']
```
在上面的代码中,`re.compile`用于编译正则表达式模式,这可以提高重复使用模式时的效率。`findall`方法用于在给定的字符串中查找所有匹配项。
### 正则表达式在PyLith中的高级应用
高级应用可能包括使用捕获组提取信息,使用正向和反向查找来定位特定条件的文本。下面展示了一个更复杂的例子,其中使用了捕获组来提取电子邮件地址的不同部分:
```python
# 正则表达式使用捕获组提取电子邮件用户名和域名
email_pattern = re.compile(r"([^\s@]+)@([^\s@]+\.[^\s@]+)")
# 匹配文本中的电子邮件地址
matches = email_pattern.search("Username: support, Email: support@example.com")
if matches:
username = matches.group(1)
domain = matches.group(2)
print(f"Username: {username}, Domain: {domain}") # 输出: Username: support, Domain: example.com
```
在该高级示例中,使用括号`()`创建了两个捕获组,每个组分别代表电子邮件地址的不同部分。`group(1)`和`group(2)`分别用于访问这两个捕获组的内容。通过这种方式,可以灵活地提取字符串的特定部分。
## 4.2 PyLith的数据库编程
### PyLith在数据库编程中的应用
数据库编程是PyLith中另一个重要应用领域。Python语言因其简洁性和可读性在数据库编程中非常受欢迎,而PyLith提供了强大的数据库操作支持,使开发者能够高效地进行数据的增删改查操作。
首先,我们需要安装一个数据库驱动,例如`psycopg2`用于PostgreSQL数据库,或`pymysql`用于MySQL数据库。安装后,PyLith便可以像操作Python对象一样方便地操作数据库。下面的代码展示了如何连接数据库,并执行一个查询操作:
```python
import pymysql
# 连接数据库
connection = pymysql.connect(host='localhost', user='user', password='password', db='database_name')
try:
with connection.cursor() as cursor:
# 执行一个查询
sql = "SELECT `id`, `name` FROM `users`"
cursor.execute(sql)
# 获取查询结果
result = cursor.fetchall()
print(result)
finally:
connection.close()
```
在该代码段中,`pymysql.connect`用于建立与MySQL数据库的连接。通过`cursor.execute`执行SQL查询,并通过`fetchall`获取所有结果。最后,确保数据库连接被关闭是一个好习惯。
### PyLith在数据库编程中的高级应用
在数据库编程的高级应用中,可以利用事务处理和存储过程等特性,使数据库操作更加高效和安全。下面示例演示如何使用PyLith处理事务:
```python
# 开始事务
connection = pymysql.connect(host='localhost', user='user', password='password', db='database_name')
connection.autocommit(False) # 关闭自动提交
try:
with connection.cursor() as cursor:
# 执行一系列数据库操作
cursor.execute("INSERT INTO `users` (`name`) VALUES ('John Doe')")
cursor.execute("UPDATE `users` SET `age` = 30 WHERE `name` = 'John Doe'")
# 提交事务
connection.commit()
except Exception as e:
# 如果出现异常,回滚事务
connection.rollback()
finally:
connection.close()
```
在这个例子中,`connection.autocommit(False)`用于关闭自动提交功能,允许我们手动控制事务的提交。在一系列数据库操作之后,我们调用`connection.commit()`来提交事务。如果在执行过程中发生异常,则调用`connection.rollback()`来回滚事务到初始状态,从而保证数据的一致性。
## 4.3 PyLith的GUI编程
### PyLith在GUI编程中的应用
随着应用程序的日益复杂,良好的用户界面(UI)变得越来越重要。PyLith提供多种选项支持GUI编程,包括但不限于Tkinter、PyQt和wxPython。这些库允许开发者构建跨平台、功能丰富的桌面应用程序。
Tkinter是Python的标准GUI库,使用它来创建一个简单的窗口应用非常直接。下面是一个基础的Tkinter应用示例:
```python
import tkinter as tk
def hello():
print("Hello, world!")
root = tk.Tk()
root.title("PyLith GUI Example")
hello_button = tk.Button(root, text="Say Hello", command=hello)
hello_button.pack()
root.mainloop()
```
在上述代码中,`tk.Tk()`创建了一个主窗口,而`tk.Button`创建了一个按钮,当点击按钮时,调用`hello()`函数打印消息。
### PyLith在GUI编程中的高级应用
在高级应用中,PyLith可以与各种GUI框架结合,以实现更复杂的功能和更好的用户体验。例如,可以集成数据图表、表格控件和复杂的事件处理逻辑。下面的示例展示了如何使用PyQt5创建一个包含表格的窗口:
```python
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QTableView
from PyQt5.QtCore import QAbstractTableModel, Qt
class TableModel(QAbstractTableModel):
def __init__(self, data):
super().__init__()
self._data = data
def rowCount(self, parent=None):
return len(self._data)
def columnCount(self, parent=None):
return len(self._data[0])
def data(self, index, role=Qt.DisplayRole):
if role == Qt.DisplayRole:
return self._data[index.row()][index.column()]
return None
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.table_view = QTableView()
self._data = [
[1, 'Alice', 24],
[2, 'Bob', 19],
[3, 'Charlie', 30]
]
self.model = TableModel(self._data)
self.table_view.setModel(self.model)
self.setCentralWidget(self.table_view)
app = QApplication(sys.argv)
main_window = MainWindow()
main_window.show()
sys.exit(app.exec_())
```
在这个示例中,`TableModel`类继承自`QAbstractTableModel`,负责管理表格数据。`MainWindow`类设置了一个`QTableView`,并将其与`TableModel`关联起来显示数据。当运行程序时,将会出现一个包含三列(ID、姓名和年龄)的表格窗口。
在这一章节中,我们探讨了PyLith在正则表达式、数据库编程和GUI编程中的应用及其高级用法。通过具体的代码示例,我们学习了如何在PyLith中使用这些强大工具来处理文本数据、操作数据库和构建用户界面。这些技术对于开发人员而言都是至关重要的,使得PyLith成为IT领域不可忽视的工具。
# 5. PyLith在实际项目中的应用案例
在了解了PyLith的基本操作、配置、调试和优化,以及实践应用之后,我们将深入探讨PyLith在真实项目场景中的应用案例。这一章节旨在通过具体案例,展示PyLith在数据处理、网络编程和系统管理三个领域的强大功能和灵活性。
## 5.1 PyLith在数据处理项目中的应用
### 案例背景
数据处理项目通常需要从多个来源收集数据,进行清洗、整合,并最终加载到数据库中。PyLith在此类项目中的应用,可以极大地提高数据处理的效率和准确性。
### 实际应用步骤
1. **数据收集**:使用PyLith的网络编程功能,从不同API获取数据。
```python
import pylith
api_data = pylith.get_api_data("http://example.com/api/data")
```
2. **数据清洗**:利用PyLith提供的数据类型和操作方法,对收集到的数据进行清洗。
```python
cleaned_data = pylith.clean_data(api_data)
```
3. **数据整合**:将清洗后的数据整合为单一数据集。
```python
integrated_data = pylith.integrate_data(cleaned_data)
```
4. **数据加载**:将整合后的数据加载到数据库中。
```python
pylith.load_data_to_db(integrated_data, "database_name")
```
### 效果评估
通过上述步骤,数据处理项目能更高效地完成任务,并提高数据的准确性和可用性。
## 5.2 PyLith在网络编程项目中的应用
### 案例背景
网络编程项目可能需要构建复杂的通信协议、处理大量的网络请求或构建高并发的服务。PyLith提供了强大的网络编程功能,特别适合于这类项目。
### 实际应用步骤
1. **通信协议构建**:利用PyLith的网络编程功能构建自定义的通信协议。
```python
class CustomProtocol(pylith.Protocol):
def handle_data(self, data):
# 处理接收到的数据
pass
```
2. **请求处理**:创建网络服务监听和处理客户端请求。
```python
server = pylith.Server(('localhost', 12345), CustomProtocol)
server.listen()
```
3. **并发管理**:确保网络服务能够处理高并发请求。
```python
@server.route('/heavy-load')
def handle_heavy_load(request):
# 高负载处理逻辑
pass
```
### 效果评估
PyLith在网络编程项目中的应用不仅降低了代码的复杂性,还提升了程序的性能和可靠性。
## 5.3 PyLith在系统管理项目中的应用
### 案例背景
系统管理项目涉及大量的系统监控、日志分析、自动化配置和任务调度。PyLith可以用于实现复杂的系统管理任务自动化。
### 实际应用步骤
1. **系统监控**:使用PyLith来监控系统资源使用情况。
```python
from pylith import system_monitor
monitor = system_monitor.SystemMonitor(interval=5)
monitor.start()
```
2. **日志分析**:编写日志分析脚本,对日志文件进行分析。
```python
log_analyzer = pylith.LogAnalyzer("logs.txt")
analysis_results = log_analyzer.analyze()
```
3. **自动化配置**:通过PyLith实现系统配置的自动化。
```python
config_manager = pylith.ConfigManager()
config_manager.update_config("config.json")
```
4. **任务调度**:利用PyLith定时执行系统维护任务。
```python
scheduler = pylith.Scheduler()
scheduler.schedule_task(pylith.Tasks.run_maintenance, "00:00")
```
### 效果评估
PyLith在系统管理项目中的应用,使得系统管理更加高效和智能化。
通过上述案例,我们可以看到PyLith如何在各种项目中发挥其强大的功能。无论是数据处理、网络编程还是系统管理,PyLith都提供了一种高效、灵活且易于使用的解决方案。随着技术的不断发展,PyLith也不断更新和扩展其功能,使其成为IT行业中不可或缺的工具之一。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
PyLith专栏是一份全面的指南,涵盖了PyLith软件的各个方面。从安装和配置到高级功能和脚本编程,该专栏提供了深入的教程和实用技巧。通过涵盖从边界条件设置到网格划分技巧等主题,该专栏旨在帮助用户从初学者到熟练用户快速提升技能。此外,该专栏还提供了有关材料属性管理、时间步进控制和本构模型选择的深入指南,使用户能够优化模拟并获得准确的结果。对于寻求提高PyLith性能和解决常见问题的用户来说,该专栏提供了宝贵的见解和实战技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32固件升级注意事项:如何避免版本不兼容导致的问题
# 摘要
本文全面探讨了STM32固件升级的过程及其相关问题。首先概述了固件升级的重要性和准备工作,包括风险评估和所需工具与资源的准备。随后深入分析了固件升级的理论基础,包括通信协议的选择和存储管理策略。文章进一步提供了实用技巧,以避免升级中的版本不兼容问题,并详述了升级流程的实施细节。针对升级过程中可能出现的问题
锂电池保护板DIY攻略:轻松制作与调试手册
# 摘要
本论文系统性地介绍了锂电池保护板的基本知识、硬件设计、软件编程、组装与测试以及进阶应用。第一章对保护板的基础知识进行了概述,第二章详细讨论了保护板的硬件设计,包括元件选择、电路设计原则、电路图解析以及PCB布局与走线技巧。第三章则聚焦于保护板软件编程的环境搭建、编程实践和调试优化。组装与测试的环节在第四章中被详尽解释,包括组装步骤、初步测试和安全性测试。最后一章探讨了锂电池保护板在智能保护功能拓展、定制化开发以及案例研究
复变函数的视觉奇迹:Matlab三维图形绘制秘籍
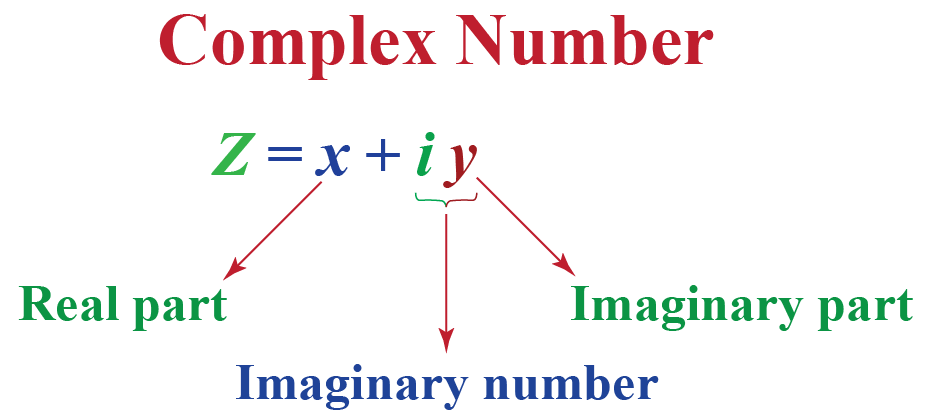
# 摘要
本文探讨了复变函数理论与Matlab软件在三维图形绘制领域的应用。首先介绍复变函数与Matlab的基础知识,然后重点介绍Matlab中三维图形的绘制技术,包括三维图形对象的创建、旋转和平移,以及复杂图形的生成和光照着色。文中还通过可视化案例分析,详细讲解了复变函数的三维映射和特定领域的可视化表现,以及在实际工程问题中的应用
【OSA案例研究】:TOAS耦合测试在多场景下的应用与分析

# 摘要
TOAS耦合测试是一种新兴的软件测试方法,旨在解决复杂系统中组件或服务间交互所产生的问题。本文首先介绍了TOAS耦合测试的理论框架,包括其基本概念、测试模型及其方法论。随后,文章深入探讨了
CSS预处理器终极对决:Sass vs LESS vs Stylus,谁主沉浮?

# 摘要
CSS预处理器作为提高前端开发效率和样式表可维护性的工具,已被广泛应用于现代网页设计中。本文首先解析了CSS预处理器的基本概念,随后详细探讨了Sass、LESS和Stylus三种主流预处理器的语法特性、核心功能及实际应用。通过深入分析各自的
CMW500信令测试深度应用:信号强度与质量优化的黄金法则

# 摘要
本文详细介绍了CMW500信令测试仪在无线通信领域的应用,涵盖了信号强度、信号质量和高级应用等方面。首先,本文阐述了信号强度的基本理论和测试方法,强调了信号衰落和干扰的识别及优化策略的重要性。接着,深入探讨了信号质量的关键指标和管理技术,以及如何通过优化网络覆盖和维护提升信号质量。此外,还介绍了CMW500在信令分析、故障排除和信号传输性能测试
高速FPGA信号完整性解决方案:彻底解决信号问题
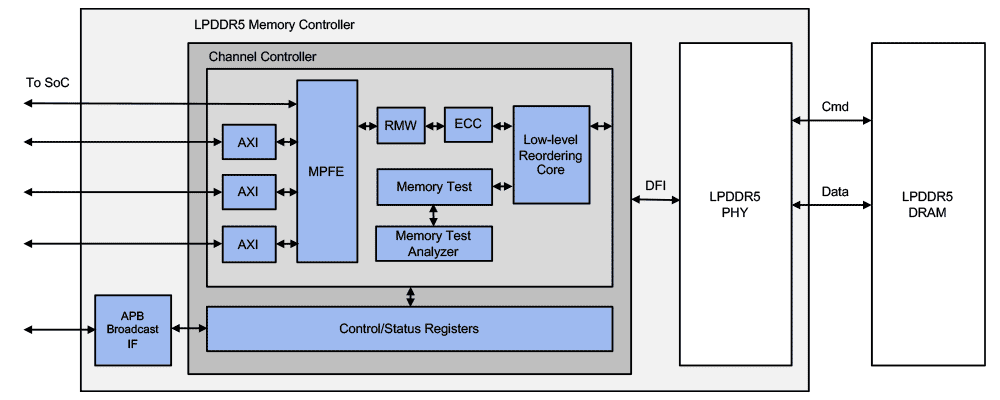
# 摘要
本文综述了FPGA(现场可编程门阵列)信号完整性问题的理论基础、实践策略以及分析工具。首先概述了信号完整性的重要性,并探讨了影响信号完整性的关键因素,包括电气特性和高速设计中的硬件与固件措施。接着,文章介绍了常用的信号完整性分析工具和仿真方法,强调了工具选择和结果分析的重要性。案例研究部分深入分析了高速FPGA设计中遇到的信号完整性问题及解决
协同创新:“鱼香肉丝”包与其他ROS工具的整合应用
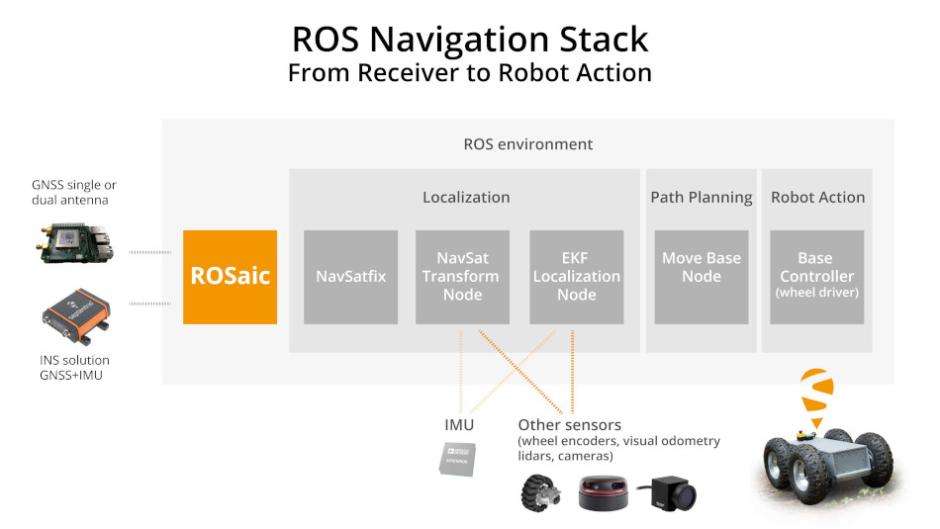
# 摘要
本文全面介绍了协同创新的基础与ROS(Robot Operating System)的深入应用。首先概述了ROS的核心概念、结构以及开发环境搭建过程。随后,详细解析了“鱼香肉丝”包的功能及其在ROS环境下的集成和实践,重点讨论了
CPCI标准2.0中文版嵌入式系统应用详解

# 摘要
CPCI(CompactPCI)标准2.0作为一种高性能、模块化的计算机总线标准,广泛应用于工业自动化、军事通信以及医疗设备等嵌入式系统中。本文全面概述了CPCI标准2.0的硬件架构和软件开发,包括硬件的基本组成、信号协议、热插拔机制,以及嵌入式Linux和RTOS的部署和应用。通过案例分析,探讨了CPCI在不同领域的应用情况和挑战。最后,展望了CPCI技术的发展趋势,包括高速总线技术、模块化设计、以及与物联网、AI技术的融合前景,强调了CPCI在国际化和标准化进程中的重要性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )