PyLith脚本编程:自动化模拟流程的实现与优化
发布时间: 2024-12-27 09:20:00 阅读量: 3 订阅数: 9 
# 摘要
本论文全面介绍了PyLith脚本编程的各个方面,从基础知识到进阶技术以及在实际项目中的应用。首先,论文探讨了PyLith脚本的基础知识,包括数据结构和控制流程。随后,第二章深入分析了PyLith脚本的理论与实践结合,重点放在模块化设计上。第三章着重讲解了PyLith脚本在自动化模拟应用中的构建与实施,强调了与外部工具的集成以及性能监控的重要性。第四章介绍了PyLith脚本的高级数据处理技术、编写技巧和安全性及稳定性优化。最后,第五章通过案例分析展示了PyLith脚本在实际项目中的应用,探讨了自动化模拟流程的推广与应用,以及在持续集成和DevOps环境中的实践。论文旨在为读者提供一个全面的PyLith脚本编程指南,帮助他们有效地在工程计算和科学模拟中应用PyLith脚本。
# 关键字
PyLith脚本;数据结构;模块化设计;自动化模拟;性能监控;DevOps集成
参考资源链接:[PyLith 2.2.1 用户手册:地球动力学数值模拟](https://wenku.csdn.net/doc/1knsut419g?spm=1055.2635.3001.10343)
# 1. PyLith脚本编程基础
在开始编写PyLith脚本之前,了解其基础语法和结构是至关重要的。本章节旨在提供一个全面的概述,涵盖PyLith脚本的基本概念,以及如何实现简单的脚本编写和执行。我们将探讨PyLith脚本的语法基础、变量和数据类型,以及最基本的输入输出操作。
## 1.1 PyLith脚本的语法基础
PyLith脚本语言依托于Python,因此其语法相对简洁且易于理解。它继承了Python的诸多特性,例如缩进规则、动态类型系统和广泛的库支持。在编写脚本之前,熟悉以下基础概念是必要的:
- 语句和表达式:理解语句的结构和表达式的构建是编写PyLith脚本的关键。
- 缩进规则:与Python一样,PyLith对代码块的缩进有严格的要求,通常以4个空格为一个缩进级别。
- 模块和包:学习如何导入和使用外部模块,以及如何组织代码为模块和包。
```python
# 一个简单的PyLith脚本示例
print("Hello, PyLith!") # 输出信息到控制台
# 使用变量存储值
number = 42
print("The answer is:", number) # 输出变量内容到控制台
```
## 1.2 变量和数据类型
在PyLith脚本中,变量是存储数据的容器。学习如何定义变量以及变量的类型,是进行有效编程的基础。
- 基本数据类型:包括整数、浮点数、字符串和布尔值等。
- 变量命名规则:变量命名需遵循特定的规则,以确保代码的清晰和可维护性。
- 数据类型转换:理解如何在不同数据类型之间进行转换,以适应不同的编程需求。
```python
# 变量和数据类型的使用示例
age = 25 # 整数类型
temperature = 36.6 # 浮点数类型
name = "Alice" # 字符串类型
is_student = True # 布尔值类型
# 数据类型转换示例
float_age = float(age)
```
## 1.3 输入和输出操作
与用户进行交互是脚本编写中不可或缺的一部分。PyLith脚本提供了多种方法来接收用户输入和输出信息。
- 输入操作:使用`input()`函数从用户那里获取输入。
- 输出操作:通过`print()`函数将信息输出到控制台。
```python
# 输入和输出操作的示例
user_input = input("Please enter your name: ") # 用户输入
print("Hello,", user_input) # 输出用户输入的内容
```
通过本章的学习,您将掌握PyLith脚本编程的核心基础,为进一步深入学习脚本的高级特性和应用打下坚实的基础。接下来的章节将介绍如何利用PyLith进行更复杂的编程任务。
# 2. PyLith脚本中的理论与实践结合
### 2.1 PyLith脚本的数据结构和操作
在进行复杂地质模型的模拟时,选择合适的数据结构是至关重要的。PyLith脚本支持多种数据结构,包括数组、列表、字典和集合等,它们各有优势。其中,字典因支持键值对的存储方式,特别适用于存储与地质模型相关的多维数据。
#### 2.1.1 数据结构的选择与使用
在PyLith中,字典是数据存储的常用选择。字典的键通常是字符串,值则可以是任何数据类型。例如,在存储地震模型的参数时,可以使用字典来表示不同断层的参数,如下所示:
```python
fault_params = {
"fault_1": {
"strike": 90.0,
"dip": 60.0,
"rake": -10.0,
"slip": 2.0
},
"fault_2": {
"strike": 180.0,
"dip": 45.0,
"rake": 90.0,
"slip": 1.5
}
}
```
#### 2.1.2 数据处理和操作实践
数据处理是PyLith脚本中的重要环节,涉及到数据的增删改查。对字典中的数据进行操作的一个基本例子是,遍历字典并更新其值:
```python
for fault_name, params in fault_params.items():
# 假设我们需要根据某些条件修改断层滑动
if params["slip"] > 1.0:
params["slip"] *= 1.1 # 将滑动增加10%
```
这段代码通过遍历字典,对于每个断层参数进行检查,并对滑动距离大于1.0的断层进行10%的增加。
### 2.2 PyLith脚本的控制流程
在PyLith脚本中实现控制流程,包括条件判断和循环控制,对于构建复杂的模拟逻辑至关重要。理解这些控制结构是编写高效脚本的基础。
#### 2.2.1 条件判断和循环控制
条件判断在PyLith脚本中通过`if`、`elif`和`else`语句实现。下面是一个关于条件判断和循环控制的例子:
```python
# 假设我们要根据不同的断层类型应用不同的摩擦律
for fault_name, params in fault_params.items():
if params["fault_type"] == "reverse":
fault_params[fault_name]["friction_law"] = "Byerlee"
elif params["fault_type"] == "strike-slip":
fault_params[fault_name]["friction_law"] = "Amontons"
else:
fault_params[fault_name]["friction_law"] = "Coulomb"
```
#### 2.2.2 异常处理和流程控制实践
异常处理通过`try`、`except`、`finally`语句实现,它能够帮助脚本在遇到错误时优雅地处理。下面是一个异常处理的例子:
```python
try:
# 尝试打开一个文件进行读取
with open("model_parameters.txt", "r") as file:
lines = file.readlines()
except IOError as e:
# 文件不存在或其他IO错误,进行错误处理
print(f"Error occurred: {e}")
finally:
# 无论是否发生异常,都会执行
print("File read attempt completed.")
```
### 2.3 PyLith脚本的模块化设计
模块化编程是软件开发中的一个重要概念,它能提升代码的可读性和可维护性。
#### 2.3.1 模块化编程的重要性
模块化意味着将复杂系统分解为更小、更易管理的部分,这有助于代码复用和团队协作。在PyLith脚本中,模块化可以通过创建函数和类来实现。
```python
def calculate_displacement(params):
# 基于给定的参数计算位移
return params["slip"] * math.sin(math.radians(params["dip"]))
# 在主脚本中调用
displacement = calculate_displacement(fault_params["fault_1"])
```
#### 2.3.2 实现模块化编程的方法和案例
为了进一步展示模块化的优势,我们可以创建一个专门处理断层参数的模块:
```python
# fault_module.py
def process_fault_parameters(params):
# 这里是复杂的处理逻辑
processed_params = {}
processed_params["slip_rate"] = params["slip"] / params["period"]
return processed_params
if __name__ == "__main__":
params = {"slip": 1.0, "period": 100.0}
print(process_fault_parameters(params))
```
然后,在主脚本中使用这个模块:
```python
# main_script.py
import fault_module
# 假设fault_params是一个预先定义的字典
fault_params["fault_1"] = fault_module.process_fault_parameters(fault_params["fault_1"])
```
在上述案例中,通过将参数处理逻辑封装在`fault_module`模块中,我们不仅使得主脚本更加简洁,还增强了代码的复用性和可维护性。
# 3. PyLith脚本自动化模拟应用
### 3.1 自动化模拟流程的构建
#### 3.1.1 设计模拟流程的策略
在设计自动化模拟流程

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
PyLith专栏是一份全面的指南,涵盖了PyLith软件的各个方面。从安装和配置到高级功能和脚本编程,该专栏提供了深入的教程和实用技巧。通过涵盖从边界条件设置到网格划分技巧等主题,该专栏旨在帮助用户从初学者到熟练用户快速提升技能。此外,该专栏还提供了有关材料属性管理、时间步进控制和本构模型选择的深入指南,使用户能够优化模拟并获得准确的结果。对于寻求提高PyLith性能和解决常见问题的用户来说,该专栏提供了宝贵的见解和实战技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
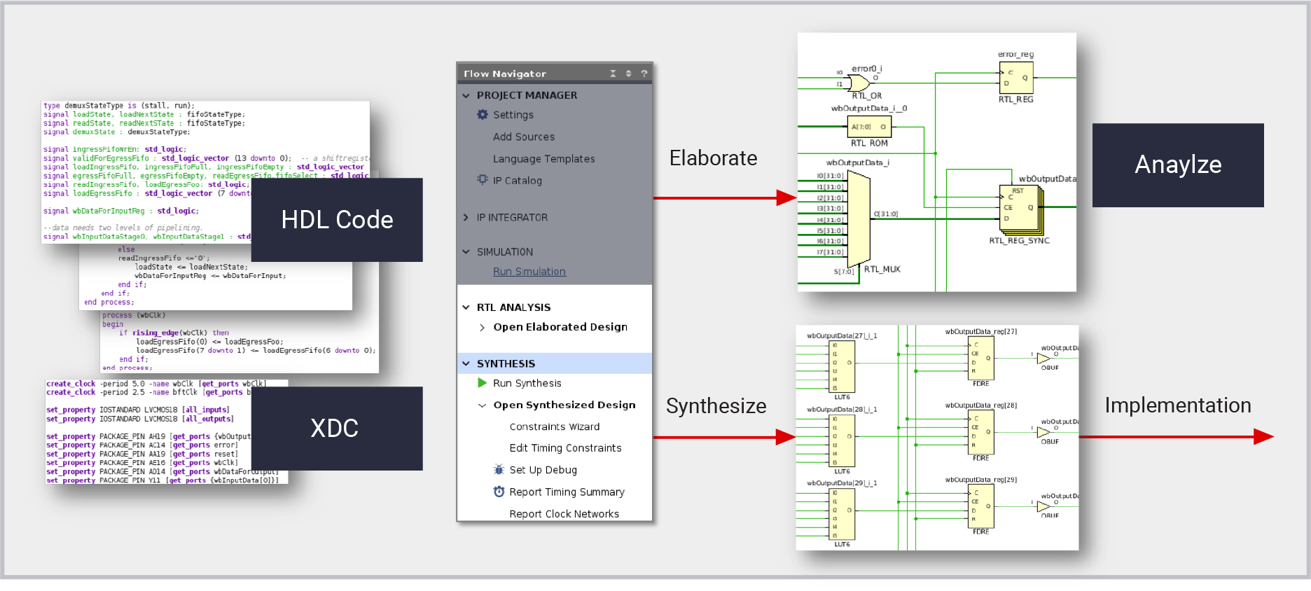
【FPGA项目从零到英雄】:VIVADO 2021.2项目实战全面解析
# 摘要
本文是一份综合指南,专门针对Xilinx的VIVADO 2021.2设计套件及其在FPGA设计中的应用。入门指南部分为初学者提供了软件操作的基础知识,而后续章节深入探讨了FPGA技术的核心概念和VIVADO设计流程,包括硬件描述语言(HDL)的使用、设计输入、仿真、综合、实现与布线等关键步骤。进阶技巧与高级应用章节涵盖了IP核集成、动
美团风控系统:实时数据处理技术的架构剖析
# 摘要
本文全面介绍了实时数据处理技术在美团风控系统中的应用,以及该系统的设计理念、架构和高级特性。首先,本文概述了实时数据处理的重要性及其与风控系统的关联。随后,深入分析了风控系统的理论基础和核心需求,包括风险识别、评估及技术挑战。接着,探讨了系统的架构设计,包括架构理念、关键组件、数据流处理及容错扩展策略。在实践应用部分,文章详述了实时监控、告警系统和风险分析决策支持系统的构建。最后,本文展望了风控系统未来的发展趋势,讨论了技术进步对系
C#委托与事件揭秘:原理深入,应用广泛
# 摘要
本文全面探讨了C#编程语言中委托和事件的机制及其在实际开发中的应用。首先介绍了委托的定义、声明、实例化、链式调用和闭包,并详细阐述了委托与匿名方法、Lambda表达式的关系。接着,文章深入分析了事件的定义、特性、发布和订阅过程,以及Multicast委托在实现事件中的作用。最后,本文通过实例展示了委托与事件在异步编程、事件驱动编程中的应用,以及在框架和库设计中的模式和实现。通过对委托与事件的深入理解,本文旨在提供给开发者更高效的编程工具,以应对复杂应用程序的开发挑战。
# 关键字
C#;委托;事件;链式调用;异步编程;事件驱动编程
参考资源链接:[C# WinForm界面特效源码集
【性能基准测试】:极智AI与商汤OpenPPL在实时视频分析中的终极较量

# 摘要
实时视频分析技术在智能监控、安全验证和内容分析等多个领域发挥着越来越重要的作用。本文从实时视频分析技术的性能基准测试出发,对比分析了极智AI和商汤OpenPPL的技术原理、性能指标以及实践案例。通过对关键性能指标的对比,详细探讨了两者的性能优势与劣势。文章进一步提出了针对两大技术的性能优化策略,并预测了实时视频分析技术的未来发展趋势及其面临的挑战。研究发现,硬件加速技术和软件算法优化是提升实时视频
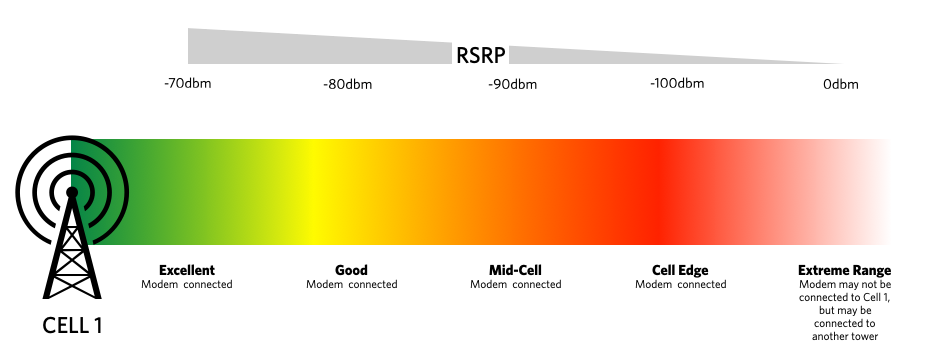
高通modem搜网注册流程详解:信号强度影响与注册成功率提升(专家实战指南)
# 摘要
高通modem的搜网注册是一个复杂的流程,它涉及到硬件和软件的紧密协作,以确保终端设备能够有效地与网络通信。本文全面概述了搜网注册的基础理论,探讨了搜网注册流程的理论基础和影
STM32F030-UART1_DMA调试神技:追踪和解决通信错误的有效方法

# 摘要
本文系统介绍了STM32F030单片机通过UART1接口与DMA(直接内存访问)进行高效通信的技术细节。首先,概述了STM32F030与UART1_DMA通信的基础知识。接着,深入探讨了UART通信协议、DMA传输机制以及STM32F030与UART1_DMA结合的原理
Allegro元件封装更换流程:案例分析与步骤详解(新手到专家版)

# 摘要
Allegro作为电子设计自动化(EDA)领域中广泛使用的一款软件,其元件封装的管理和更换技术对于高效电路设计至关重要。本文首先对Allegro元件封装的概念进行了详细解析,并介绍了基础操作,包括界面熟悉、封装创建与修改、库文件管理和版本控制。随后,文章通过案例分析,深入探讨了常见封装问题的识别与解决方案,并对不同封装类型进行了比较选择。文章进一步提供了一系列实践操作步骤和故障排
【RN8209D技术手册深度解读】:全面揭示硬件规格及接口秘密

# 摘要
本文详细介绍了RN8209D技术的核心架构、性能特点及其在不同应用领域中的实际应用。首先,我们深入解析了RN8209D的硬件架构,包括其核心组件、电源管理和性能分析,并着重探讨了不同接口技术的设计和应用。其次,文章重点描述了RN8209D软件开发环境的搭建和开发过程中的编程语言选择、接口编程、调试和性能优化技巧。最后,通过几个实战案例分析,探讨了
【权威解析Kindle Fire HDX7】:深度解读其硬件架构与操作系统

# 摘要
本文全面概述了Kindle Fire HDX7的特点、硬件架构、操作系统架构以及性能表现。首先介绍了Kindle Fire HDX7的基本概况,然后深入探讨了其硬件架构,包括处理器和内存的性能、显示技术、存储及扩展性。接着分析了基于Android的定制操作系
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )