Apache Flink中的任务并行度与资源管理优化
发布时间: 2024-02-22 02:27:49 阅读量: 42 订阅数: 31 
# 1. Apache Flink简介与并行计算模型
## 1.1 Apache Flink框架概述
Apache Flink是一个开源的流式处理引擎,提供了高吞吐量和低延迟的数据流处理能力。它支持事件驱动的应用程序,能够处理无界的数据流,并在批处理和流处理之间提供平滑的过渡。Flink具有强大的状态管理机制和容错机制,可保证数据处理的准确性。
## 1.2 Flink的并行计算模型介绍
Flink的并行计算模型基于流处理时间概念,将数据流划分为无界的事件流。Flink引入了基于状态的流处理模型,能够在保证一致性的前提下实现高效的并行计算。通过任务链和任务图的形式来组织和调度并行任务,支持任务的水平扩展和任务并行度的动态调整。
## 1.3 任务并行度的概念及重要性
任务并行度是指作业中并行任务的数量,直接影响作业的并行处理能力和性能。合理设置任务并行度能够充分利用集群资源,提高作业的执行效率和吞吐量。在实际应用中,需要根据作业的特性和运行环境来调整任务并行度,以达到最佳的性能表现。
# 2. 任务并行度的影响因素分析
在Apache Flink中,任务并行度的设置对作业的性能和效率有着重要的影响。了解任务并行度的影响因素可以帮助优化作业的执行。下面将对任务并行度的影响因素进行分析。
### 2.1 数据量与计算复杂度对任务并行度的影响
数据量和计算复杂度是决定任务并行度的重要因素之一。通常情况下,当数据量较大或计算复杂度较高时,适当提高任务并行度可以加速作业的执行。然而,过高的并行度可能会导致资源竞争和通信开销增加,需要权衡。
```java
// Java示例代码,计算任务并行度的简单示例
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Integer> input = env.fromElements(1, 2, 3, 4, 5);
DataSet<Integer> result = input
.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) {
return value * 2;
}
})
.setParallelism(2); // 设置任务并行度为2
result.print();
```
**总结:** 数据量和计算复杂度会影响任务并行度的选择,需要根据实际情况进行调整。
### 2.2 Flink作业图及数据流图分析
Flink作业图是描述作业执行流程的重要工具,其中包含了作业中各个算子和它们之间的依赖关系。通过分析作业图,可以了解各个算子之间的数据传输路径,从而优化任务并行度设置。
```python
# Python示例代码,分析Flink作业数据流图
env = StreamExecutionEnvironment.get_execution_environment()
data_stream = env.from_collection([1, 2, 3, 4, 5])
word_count = data_stream \
.map(lambda x: (x, 1)) \
.key_by(lambda x: x[0]) \
.sum(1) \
.set_parallelism(4) # 设置任务并行度为4
word_count.print()
```
**总结:** 分析Flink作业图和数据流图有助于合理设置任务并行度,提升作业性能。
### 2.3 状态管理与一致性保证在任务并行度上的作用
在一些有状态的Flink作业中,状态管理和一致性保证对任务并行度也有影响。合理管理状态和保证一致性可以减少不必要的通信开销,提高作业的执行效率。
```go
// Go示例代码,展示状态管理对任务并行度的影响
package main
func main() {
env := flink.NewExecutionEnvironment()
dataStream := env.AddSource(mySource)
result := dataStream
.map(myMapFunction)
.keyBy(myKeySelector)
.process(myProcessFunction)
.setParallelism(3) // 设置任务并行度为3
env.Execute("Stateful Flink Job")
}
```
**总结:** 合理管理状态和保证一致性可以优化任务并行度设置,提高作业的执行效率。
通过对任务并行度影响因素的分析,可以更好地理解如何优化任务并行度设置,提升作业的性能和效率。
# 3. 任务并行度优化策略
在Apache Flink中,任务并行度的优化策略是非常重要的,它直接影响作业的性能和资源利用效率。下面将介绍几种常见的任务并行度优化策略。
#### 3.1 动态任务并行度调整策略
动态任务并行度调整是指根据作业运行时的状态和负载情况,动态地调整任务的并行度。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Apache Flink-实时流处理专栏深入探讨了 Apache Flink 在实时数据处理领域的应用和原理。从介绍 Apache Flink 的基本概念和架构,到比较流数据与批数据处理,再到详细解析流处理程序的开发流程,本专栏全方位展现了 Apache Flink 的强大功能。同时,通过讲解数据源、窗口函数、表达式语言、数据一致性等关键组成部分以及任务并行度与资源管理的优化,读者能深入了解 Apache Flink 的内部机制和操作原理。此外,专栏还提供了与 Apache Kafka、Hadoop、Hive、Spark 等主流技术集成的实践指南,帮助读者更好地应用 Apache Flink 在实际项目中。如果你对实时流处理感兴趣,本专栏将为你打开 Apache Flink 的大门,带领你进入实时数据处理的精彩世界。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【时间序列分析深度解析】:15个关键技巧让你成为数据预测大师

# 摘要
时间序列分析是处理和预测按时间顺序排列的数据点的技术。本文
【Word文档处理技巧】:代码高亮与行号排版的终极完美结合指南
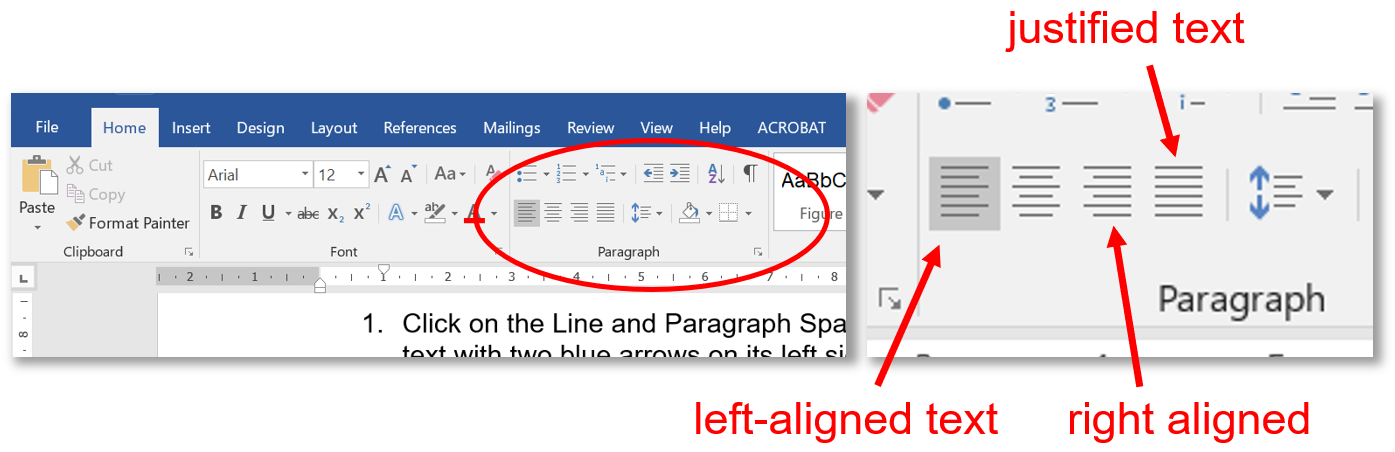
# 摘要
本文旨在为技术人员提供关于Word文档处理的深入指导,涵盖了从基础技巧到高级应用的一系列主题。首先介绍了Word文档处理的基本入门知识,然后着重讲解了代码高亮的实现方法,包括使用内置功能、自定义样式及第三方插件和宏。接着,文中详细探讨了行号排版的策略,涉及基础理解、在Word中的插入方法以及高级定制技巧。第四章讲述了如何将代码高亮与行号完美结
LabVIEW性能优化大师:图片按钮内存管理的黄金法则
# 摘要
本文围绕LabVIEW软件平台的内存管理进行深入探讨,特别关注图片按钮对象在内存中的使用原理、优化实践以及管理工具的使用。首先介绍LabVIEW内存管理的基础知识,然后详细分析图片按钮在LabVIEW中的内存使用原理,包括其数据结构、内存分配与释放机制、以及内存泄漏的诊断与预防。第三章着重于实践中的内存优化策略,包括图片按钮对象的复用、图片按钮数组与簇的内存管理技巧,以及在事件结构和循环结构中的内存控制。接着,本文讨论了LabVIEW内存分析工具的使用方法和性能测试的实施,最后提出了内存管理的最佳实践和未来发展趋势。通过本文的分析与讨论,开发者可以更好地理解LabVIEW内存管理,并
【CListCtrl行高设置深度解析】:算法调整与响应式设计的完美融合
# 摘要
CListCtrl是广泛使用的MFC组件,用于在应用程序中创建具有复杂数据的列表视图。本文首先概述了CListCtrl组件的基本使用方法,随后深入探讨了行高设置的理论基础,包括算法原理、性能影响和响应式设计等方面。接着,文章介绍了行高设置的实践技巧,包括编程实现自适应调整、性能优化以及实际应用案例分析。文章还探讨了行高设置的高级主题,如视觉辅助、动态效果实现和创新应用。最后,通过分享最佳实践与案例,本文为构建高效和响应式的列表界面提供了实用的指导和建议。本文为开发者提供了全面的CListCtrl行高设置知识,旨在提高界面的可用性和用户体验。
# 关键字
CListCtrl;行高设置
邮件排序与筛选秘籍:SMAIL背后逻辑大公开
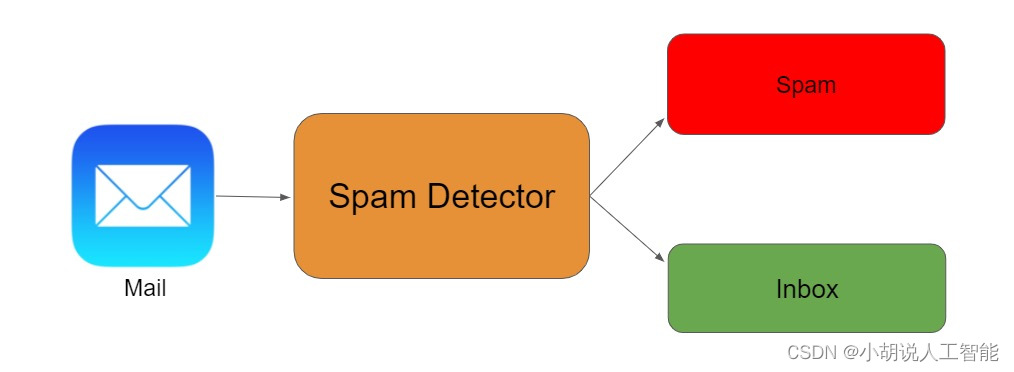
# 摘要
本文全面探讨了邮件系统的功能挑战和排序筛选技术。首先介绍了邮件系统的功能与面临的挑战,重点分析了SMAIL的排序算法,包括基本原理、核心机制和性能优化策略。随后,转向邮件筛选技术的深入讨论,包括筛选逻辑的基础构建、高级技巧和效率提升方法。文中还通过实际案例分析,展示了邮件排序与筛选在不同环境中的应用,以及个人和企业级的邮件管理策略。文章最后展望了SMAIL的未来发展趋势,包括新技术的融入和应对挑战的策
AXI-APB桥在SoC设计中的关键角色:微架构视角分析

# 摘要
本文对AXI-APB桥的技术背景、设计原则、微架构设计以及在SoC设计中的应用进行了全面的分析与探讨。首先介绍了AXI与APB协议的对比以及桥接技术的必要性和优势,随后详细解析了AXI-APB桥的微架构组件及其功能,并探讨了设计过程中面临的挑战和解决方案。在实践应用方面,本文阐述了AXI-APB桥在SoC集成、性能优化及复杂系统中的具体应用实例。此外,本文还展望了AXI-APB桥的高级功能扩展及其
CAPL脚本高级解读:技巧、最佳实践及案例应用
# 摘要
CAPL(CAN Access Programming Language)是一种专用于Vector CAN网络接口设备的编程语言,广泛应用于汽车电子、工业控制和测试领域。本文首先介绍了CAPL脚本的基础知识,然后详细探讨了其高级特性,包括数据类型、变量管理、脚本结构、错误处理和调试技巧。在实践应用方面,本文深入分析了如何通过CAPL脚本进行消息处理、状态机设计以
【适航审定的六大价值】:揭秘软件安全与可靠性对IT的深远影响
# 摘要
适航审定作为确保软件和IT系统符合特定安全和可靠性标准的过程,在IT行业中扮演着至关重要的角色。本文首先概述了适航审定的六大价值,随后深入探讨了软件安全性与可靠性的理论基础及其实践策略,通过案例分析,揭示了软件安全性与可靠性提升的成功要素和失败的教训。接着,本文分析了适航审定对软件开发和IT项目管理的影响,以及在遵循IT行业标准方面的作用。最后,展望了适航审定在
CCU6定时器功能详解:定时与计数操作的精确控制

# 摘要
CCU6定时器是工业自动化和嵌入式系统中常见的定时器组件,本文系统地介绍了CCU6定时器的基础理论、编程实践以及在实际项目中的应用。首先概述了CCU
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )