大数据处理技术:从 Hadoop 到 Spark,探索数据处理新范式
发布时间: 2024-06-22 12:20:39 阅读量: 77 订阅数: 28 

Spark 大数据处理技术
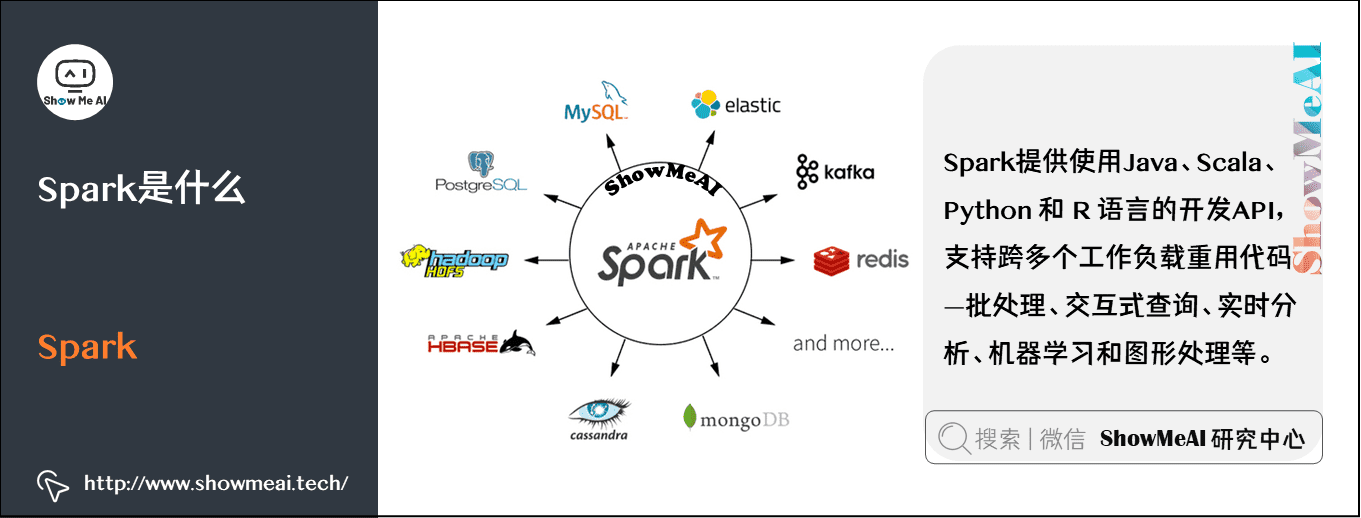
# 1. 大数据处理概述
大数据处理是指管理和分析海量、复杂、快速增长的数据集的过程。这些数据集通常包含各种格式和来源的数据,例如文本、图像、视频和传感器数据。大数据处理旨在从这些数据中提取有价值的见解,以支持决策制定、优化流程和改善客户体验。
大数据处理面临的挑战包括:
- **数据量大:**数据集通常包含数百万或数十亿条记录,需要强大的存储和处理能力。
- **数据复杂性:**数据可能具有不同的格式、结构和语义,需要灵活的数据处理工具。
- **数据速度:**数据不断生成和更新,需要实时处理和分析能力。
# 2. Hadoop 生态系统
Hadoop 生态系统是一个由多个组件组成的开源框架,旨在处理和存储大规模数据集。它提供了一个分布式文件系统、一个编程模型和一系列辅助组件,使组织能够有效地管理和分析海量数据。
### 2.1 Hadoop 分布式文件系统 (HDFS)
HDFS 是 Hadoop 生态系统中的一个核心组件,它提供了一个分布式文件系统,用于存储和管理大规模数据集。HDFS 将数据存储在多个数据块中,这些数据块分布在集群中的多个节点上。这种分布式存储架构提供了高容错性和高可用性,因为即使一个节点发生故障,数据也不会丢失。
#### HDFS 架构
HDFS 采用主从架构,其中一个 NameNode 负责管理文件系统元数据,而多个 DataNode 负责存储实际数据块。NameNode 维护文件系统目录结构和数据块的位置信息,而 DataNode 负责存储和管理数据块。
#### HDFS 特性
* **分布式存储:** HDFS 将数据存储在多个节点上,提供高容错性和高可用性。
* **块级存储:** 数据以块的形式存储,每个块的大小通常为 128MB。
* **高吞吐量:** HDFS 针对高吞吐量数据流进行了优化,可以快速读取和写入大量数据。
* **容错性:** HDFS 通过数据复制和块校验和机制提供高容错性,即使节点发生故障,数据也不会丢失。
### 2.2 Hadoop MapReduce 编程模型
MapReduce 是 Hadoop 生态系统中的另一个核心组件,它提供了一个编程模型,用于处理大规模数据集。MapReduce 程序由两个阶段组成:Map 阶段和 Reduce 阶段。
#### MapReduce 过程
* **Map 阶段:** Map 阶段将输入数据集拆分为较小的块,并将其分配给集群中的多个节点。每个节点上的 Map 任务处理一个数据块,并生成一组键值对。
* **Reduce 阶段:** Reduce 阶段将 Map 阶段生成的键值对分组在一起,并应用一个聚合函数(例如求和或求平均值)来生成最终结果。
#### MapReduce 特性
* **可扩展性:** MapReduce 程序可以轻松地扩展到处理海量数据集,因为它们可以并行执行在多个节点上。
* **容错性:** MapReduce 框架负责处理节点故障,并自动重新执行失败的任务。
* **易于编程:** MapReduce 编程模型相对简单,即使对于没有分布式计算经验的开发人员来说也是如此。
### 2.3 Hadoop 生态系统中的其他组件
除了 HDFS 和 MapReduce 之外,Hadoop 生态系统还包括一系列其他组件,这些组件提供了附加的功能和服务。这些组件包括:
* **YARN:** YARN 是 Hadoop 生态系统中的资源管理框架,它负责管理集群资源并调度作业。
* **Hive:** Hive 是一个数据仓库工具,它允许用户使用类似 SQL 的语言查询和分析数据。
* **Pig:** Pig 是一个数据流处理平台,它允许用户使用类似 Pig Latin 的语言编写数据处理脚本。
* **HBase:** HBase 是一个分布式 NoSQL 数据库,它用于存储和管理大规模非结构化数据。
# 3. Spark 架构和原理
### 3.1 Spark 的核心概念和组件
Spark 是一个基于内存的分布式计算框架,它提供了对大数据集进行快速、高效处理的 API。Spark 的核心概念包括:
- **弹性分布式数据集 (RDD)**:RDD 是 Spark 中的基本数据结构,它表示分布在集群中的一个不可变的元素集合。RDD 可以从各种数据源创建,如 HDFS、数据库或流。
- **转换和操作**:Spark 提供了一组丰富的转换和操作,用于处理 RDD。转换创建新的 RDD,而操作在现有 RDD 上执行计算。
- **懒惰求值**:Spark 采用懒惰求值,这意味着转换和操作仅在需要时才执行。这允许 Spark 优化执行计划,并仅在必要时执行计算。
- **容错性**:Spark 具有内置的容错机制,它可以自动从节点故障中恢复。
Spark 的主要组件包括:
- **Spark Core**:提供 RDD、转换、操作和容错性等核心功能。
- **Spark SQL**:提供对结构化数据的支持,包括 SQL 查询、数据帧和数据源连接。
- **Spark Streaming**:提供对流数据的支持,包括实时数据处理和分析。
- **Spark MLlib**:提供机器学习和数据挖掘算法库。
### 3.2 Spark 的分布式处理引擎
Spark 的分布式处理引擎由以下组件组成:
- **Driver 程序**:负责创建 SparkContext 并协调计算。
- **Executor**:在工作节点上运行,负责执行任务。
- **Task**:是 Spark 中最小的可调度计算单元。
- **Job**:是一组相关任务的集合。
Spark 使用一种称为 DAGScheduler 的调度程序来调度任务。DAGScheduler 将作业分解为阶段,每个阶段由一组任务组成。DAGScheduler 优化任务执行计划,以最小化数据传输和提高性能。
### 3.3 Spark SQL 和数据分析
Spark SQL 是 Spark 中的一个模块,它提供了对结构化数据的支持。Spark SQL 使用数据帧和数据集作为其核心数据结构。
- **数据帧**:是类似于关系表的分布式集合。数据帧可以包含各种数据类型,并支持 SQL 查询和操作。
- **数据集**:是数据帧的优化版本,它提供了更好的性能和更强的类型安全性。
Spark SQL 提供了一组丰富的 SQL 函数和操作,用于查询、转换和分析数据。它还支持与各种数据源的连接,如 HDFS、数据库和流。
**代码块:使用 Spark SQL 查询数据**
```python
# 创建 SparkSession
spark = SparkSession.builder.appName("Spark SQL Example").getOrCreate()
# 加载数据
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# 查询数据
df.filter(df["age"] > 18).show()
```
**逻辑分析:**
这段代码使用 Spark SQL 查询数据。首先,它创建了一个 SparkSession,这是 Spark SQL 的入口点。然后,它从 CSV 文件加载数据并创建数据帧。最后,它使用 SQL 查询过滤数据,只显示年龄大于 18 的行。
# 4. Hadoop 和 Spark 的比较
### 4.1 性能和可扩展性
Hadoop 和 Spark 在性能和可扩展性方面各有优势。
**Hadoop:**
* 具有良好的容错性和数据可靠性,适合处理海量数据。
* 采用分布式文件系统 (HDFS),数据分布在多个节点上,提高了数据访问速度。
* MapReduce 编程模型并行处理数据,提高了计算效率。
**Spark:**
* 内存计算引擎,数据处理速度快。
* 弹性分布式数据集 (RDD) 抽象,简化了数据处理流程。
* 流处理能力强,适合处理实时数据。
**比较:**
* **批处理:** Hadoop 在批处理方面更具优势,因为它可以高效地处理海量数据。
* **流处理:** Spark 在流处理方面更胜一筹,因为它可以快速处理实时数据。
* **可扩展性:** Hadoop 和 Spark 都具有良好的可扩展性,可以处理大规模数据。然而,Spark 的内存计算引擎使其在处理较小数据集时更具优势。
### 4.2 编程模型和复杂性
Hadoop 和 Spark 采用不同的编程模型,这影响了它们的复杂性。
**Hadoop:**
* 使用 MapReduce 编程模型,需要编写 Java 或 Python 代码。
* MapReduce 编程模型相对复杂,需要对分布式计算有较好的理解。
**Spark:**
* 使用弹性分布式数据集 (RDD) 抽象,简化了数据处理流程。
* 支持多种编程语言,包括 Scala、Java、Python 和 R。
* 提供丰富的 API,简化了复杂任务的开发。
**比较:**
* **编程复杂性:** Spark 的编程模型比 Hadoop 的 MapReduce 编程模型更简单。
* **语言支持:** Spark 支持多种编程语言,而 Hadoop 主要使用 Java。
* **API:** Spark 提供丰富的 API,简化了复杂任务的开发。
### 4.3 生态系统和支持
Hadoop 和 Spark 都有广泛的生态系统,提供各种工具和组件。
**Hadoop:**
* 拥有成熟的生态系统,包括 HDFS、MapReduce、Hive、Pig 等组件。
* 社区活跃,提供广泛的支持和文档。
**Spark:**
* 生态系统不断发展,包括 Spark SQL、Spark Streaming、MLlib 等组件。
* 社区活跃,提供广泛的支持和文档。
**比较:**
* **生态系统成熟度:** Hadoop 的生态系统更加成熟,具有更多的组件和工具。
* **社区支持:** Hadoop 和 Spark 都拥有活跃的社区,提供广泛的支持和文档。
* **组件集成:** Hadoop 和 Spark 的组件可以集成使用,提供更全面的数据处理解决方案。
# 5. 大数据处理实践
### 5.1 数据预处理和清洗
数据预处理和清洗是数据处理管道中至关重要的步骤,它可以确保数据质量,并为后续的分析和建模做好准备。数据预处理和清洗涉及以下主要任务:
- **数据清理:**去除数据集中重复、无效或缺失的值。
- **数据转换:**将数据转换为适合分析和建模的格式。
- **数据标准化:**确保数据值在相同的范围内,以便进行比较和分析。
- **数据集成:**将来自不同来源的数据合并到一个一致的数据集中。
### 5.2 数据分析和建模
数据分析和建模是利用数据来获取见解和预测未来的过程。数据分析涉及以下步骤:
- **探索性数据分析 (EDA):**使用统计方法和可视化工具来探索和理解数据。
- **数据建模:**创建数学模型来表示数据中的关系和模式。
- **模型评估:**评估模型的性能,并根据需要进行调整。
### 5.3 数据可视化和报告
数据可视化和报告是将数据转化为易于理解的图形和图表的过程。数据可视化和报告可以帮助:
- **识别模式和趋势:**可视化可以帮助识别数据中的模式和趋势,这些模式和趋势可能无法通过简单的统计分析发现。
- **传达见解:**图表和图形可以有效地传达数据分析和建模的结果,使非技术受众也能理解。
- **支持决策:**数据可视化和报告可以为决策者提供所需的信息,以便做出明智的决策。
**示例代码:**
```python
# 使用 Pandas 进行数据预处理和清洗
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 清理数据
df = df.dropna() # 去除缺失值
df = df.drop_duplicates() # 去除重复行
# 转换数据
df['date'] = pd.to_datetime(df['date']) # 将字符串日期转换为日期时间对象
# 标准化数据
df['age'] = df['age'].astype('float') # 将年龄转换为浮点数
# 集成数据
df2 = pd.read_csv('data2.csv')
df = pd.merge(df, df2, on='id') # 根据 'id' 列合并两个数据框
# 使用 Seaborn 进行数据可视化
import seaborn as sns
# 创建散点图
sns.scatterplot(x='age', y='salary', data=df)
```
**代码逻辑分析:**
1. 使用 Pandas 读取数据并进行预处理,包括去除缺失值、重复行和转换数据类型。
2. 使用 Seaborn 创建一个散点图,显示年龄与工资之间的关系。
# 6. 大数据处理未来趋势
大数据处理领域正在不断发展,新的技术和趋势正在塑造其未来。以下是一些关键趋势:
### 6.1 云计算和大数据
云计算平台,如 AWS、Azure 和 GCP,正在成为大数据处理的流行选择。这些平台提供可扩展、弹性和按需付费的计算和存储资源,使企业能够轻松地处理和分析大数据。
### 6.2 流数据处理
流数据处理技术正在兴起,用于处理不断生成的数据流。这些技术使企业能够实时分析数据,从而做出更明智的决策和采取更快的行动。
### 6.3 人工智能和大数据
人工智能(AI)技术,如机器学习和深度学习,正在与大数据相结合,以创建新的见解和自动化任务。AI算法可以分析大量数据,识别模式并做出预测,从而增强数据处理和分析能力。
**示例:**
考虑以下示例,说明云计算和大数据趋势如何融合:
```python
import boto3
# 创建一个 Amazon S3 客户端
s3 = boto3.client('s3')
# 创建一个 Amazon EMR 集群
emr = boto3.client('emr')
cluster_id = emr.run_job_flow(
Name='MyEMRCluster',
ReleaseLabel='emr-6.3.0',
Instances={
'MasterInstanceType': 'm5.xlarge',
'SlaveInstanceType': 'm5.xlarge',
'InstanceCount': 3
},
Applications=[
{'Name': 'Hadoop'},
{'Name': 'Spark'}
],
JobFlowRole='EMR_EC2_DefaultRole',
ServiceRole='EMR_DefaultRole'
)
# 上传数据到 Amazon S3
s3.upload_file('data.csv', 'my-bucket', 'data.csv')
# 在 Amazon EMR 集群上运行 Spark 作业
emr.add_job_flow_steps(
JobFlowId=cluster_id,
Steps=[
{
'Name': 'MySparkJob',
'ActionOnFailure': 'TERMINATE_CLUSTER',
'HadoopJarStep': {
'Jar': 's3://my-bucket/spark-job.jar',
'Args': ['data.csv', 'output.csv']
}
}
]
)
```
此代码展示了如何使用云计算平台(Amazon Web Services)来处理大数据。它创建了一个 Amazon EMR 集群,将数据上传到 Amazon S3,然后在集群上运行一个 Spark 作业。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 CentOS 7 Python 安装指南,从入门到高级优化,一步步教你轻松搞定。专栏深入剖析 Python 安装陷阱,帮你避免常见问题。此外,还提供 Python 在 CentOS 7 上的优化安装指南,提升性能和稳定性。专栏还涵盖了 MySQL 数据库性能优化秘籍,揭秘性能下降的幕后真凶及解决策略。深入分析 MySQL 死锁问题,教你如何分析并彻底解决。专栏还提供 MySQL 数据库索引失效案例分析与解决方案,揭秘索引失效的真相。最后,全面解析表锁问题,深度解读 MySQL 表锁问题及解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
DevOps实践手册:如何打造高效能的开发运维团队
# 摘要
本文全面探讨了DevOps的概念、核心价值、文化变革、组织变革以及与之相关的工具链和自动化实践。文章首先介绍了DevOps的核心理念及其对于组织文化的影响,随后深入分析了如何通过打破部门壁垒、促进团队协作来实践DevOps文化。接着,文章详细阐述了DevOps工具链的搭建,特别是自动化工
7个关键要点,全面解读:第五版医疗系统接口更新与优化
# 摘要
随着技术进步和医疗信息化的快速发展,医疗系统接口的更新与优化已成为提高医疗服务质量和效率的关键。本文全面探讨了医疗系统接口更新的必要性,分析了现有接口的问题与挑战以及新技术趋势对接口的更新要求。通过研究接口标准、协议选择以及架构设计原则,本文提出了一系列理论基础,旨在提高系统的兼容性、扩展性、性能和用户体验,同时强调数据安全与隐私保护的重要
nRF2401软件跳频实战:构建稳定无线通信系统的10大步骤
# 摘要
本文全面概述了nRF2401软件跳频技术,并深入探讨了其理论基础、硬件要求和编程基础。首先介绍了nRF2401的功能和跳频技术对无线通信稳定性的影响。随后,重点讲述了硬件平台的选择与准备、电源和干扰管理,以及如何进行初始化编程和实现跳频机制。文章还详细阐述了构建无线通信系统的实战演练,包括系统设计、
Arduino多任务编程秘籍:高效管理任务与定时器

# 摘要
本文系统地探讨了Arduino多任务编程的基础概念、技巧与实践。首先介绍了多任务编程的基础知识,然后深入探讨了任务管理、防止任务阻塞的方法以及任务间通信的策略。接着,文章详细阐述了定时器的高级应用,包括理论基础、编程实践以及创新应用。此外,本文还涵盖了实时操作系统(RTOS)在Arduino中的应用、内存管理和多任务代码调试等进阶技术。最后,通过智能家居系统的综合项目案例分析,展示了多任务编程在实际应用中的性能
H3C-MSR路由器故障诊断宝典:快速修复网络问题的8个步骤
# 摘要
本文全面介绍了H3C-MSR路由器的故障诊断方法,从基础知识讲起,深入探讨了网络故障诊断的理论基础,包括故障诊断的概念、理论模型、工具和技术。接着,文章详细阐述了H3C-MSR路由器的实践操作,涵盖了基本配置、快速故障定位以及实际案例分析。进一步,本文深入探讨了故障排除策略,性能优化方法和安全问题的应对。最后,文章展望了路由器故障诊断的高级应用,包括自动化诊断工具、网络自动化运维趋势以及未来研究方向和技术发展预测。
# 关键字
H3C-MSR路由器;故障诊断;网络故障;性能优化;安全问题;自动化运维
参考资源链接:[H3C MSR路由器升级教程:配置与步骤详解](https://
BT201音频流控制秘籍:揭秘高质量音频传输的实现
# 摘要
随着数字媒体技术的不断发展,音频流控制在高质量音频传输领域扮演着关键角色。本文首先介绍了音频流控制的基础知识,为理解后续内容奠定基础。随后,深入探讨了高质量音频传输的理论基础,为实现有效的音频流控制提供了理论支撑。第三章和第四章着重分析了BT201音频流控制器的实现原理及其实践操作方法,指出了控制器设计与应用中的关键要点。最后一章针对BT201音频流控制的进阶应用和优化策略进行了详细论
揭秘数据流图:业务建模的5个关键步骤及案例解析

# 摘要
数据流图(DFD)作为一种重要的系统分析和设计工具,在现代业务建模中发挥着不可或缺的作用。本文全面介绍了DFD的基本概念、构建过程以及在业务流程分析中的应用。首先概述了DFD的理论基础和与业务流程的关系,随后详细阐述了构建数据流图的关键步骤,包括确定范围、绘制技巧和验证优化。通过对实际业务案例的分析,本文进一步展示了如何在实践案例中应用DFD,并讨论了DFD在企业架构和敏捷开发中的整合及优化策略。最后,本
C语言编译器优化全攻略:解锁程序效能的秘密

# 摘要
C语言编译器优化是一个涉及多阶段处理的复杂问题。本文从编译器前端和后端优化技术两个维度对C语言编译器的优化进行了全面的概述。在前端优化技术中,我们分析了词法分析、语法分析、中间表示的优化策略以及代码优化基础。后端优化策略部分,则着重探讨了指令选择、调度优化、寄存器分配以及数据流分析的改进。此外,本文还讨论了在实际应用中面向性能的代码编写技巧,利用编译器特性进行优化,以及性能分析与调优的
【Verilog综合优化】:Cadence中的综合工具使用技巧

# 摘要
本文系统地介绍了Verilog综合的基础知识以及Cadence综合工具的理论基础、高级特性和实践操作。文章首先探讨了Verilog代码的综合过程,包括代码优化策略和综合过程中的关键步骤。随后,文章深入分析了Cadence综合工具的主要功能,如输入输出处理和参数设置,以及在综合过程中遇到的常见挑战及其解决方案。此外,本文还涵盖了Cadence综合工具的高级特性,例如设计优化技术、特定硬件的综合技巧和综合报告分析。在实践操作章节中,文章详细描述了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )