Kubernetes 集群管理:深入理解容器编排与调度
发布时间: 2024-06-22 12:14:55 阅读量: 76 订阅数: 31 

Kubernetes容器集群管理 完整清晰版 书籍

# 1. Kubernetes 集群管理概述
Kubernetes 是一种开源容器编排系统,用于自动化部署、管理和扩展容器化应用程序。它提供了管理容器集群所需的核心组件,包括调度程序、控制器和网络。
Kubernetes 集群由一组节点组成,其中包括一个或多个主节点和一组工作节点。主节点负责管理集群,而工作节点负责运行容器。Kubernetes 使用 Pod、Deployment 和 Service 等概念来管理容器,并提供自动调度、自我修复和负载均衡等功能。
# 2. Kubernetes 容器编排基础
### 2.1 Kubernetes 架构和组件
#### 2.1.1 Master 节点和 Worker 节点
Kubernetes 集群由两类节点组成:Master 节点和 Worker 节点。
- **Master 节点:**负责管理和控制集群,包括调度 Pod、维护集群状态和提供 API 访问。
- **Worker 节点:**负责运行 Pod,提供计算、存储和网络资源。
#### 2.1.2 Pod、Deployment 和 Service
Kubernetes 使用以下核心对象来管理容器:
- **Pod:**一个或多个容器的集合,共享相同的网络和存储资源。
- **Deployment:**管理 Pod 的声明性配置,确保所需数量的 Pod 始终处于运行状态。
- **Service:**抽象 Pod 的网络访问,提供负载均衡和服务发现。
### 2.2 容器编排原理
#### 2.2.1 Pod 调度算法
Kubernetes 使用以下算法来调度 Pod 到 Worker 节点:
- **BestEffort:**在任何可用节点上调度 Pod,不考虑资源需求。
- **NodeSelector:**根据节点标签选择特定节点。
- **NodeAffinity:**优先考虑具有特定标签的节点,但允许调度到其他节点。
- **NodeAntiAffinity:**避免在具有特定标签的节点上调度 Pod。
#### 2.2.2 Service 发现机制
Kubernetes 使用以下机制实现 Service 发现:
- **DNS:**为 Service 创建 DNS 记录,允许 Pod 通过名称解析 Service IP。
- **kube-proxy:**在每个节点上运行的代理,将 Service IP 映射到 Pod IP。
- **Endpoints:**存储 Service 关联的 Pod IP 列表。
**代码块:**
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- port: 80
targetPort: 8080
```
**逻辑分析:**
此 Service 定义了一个名为 "my-service" 的 Service,它将目标端口 8080 上运行的 Pod 暴露为端口 80。
**参数说明:**
- `apiVersion`:Kubernetes API 版本。
- `kind`:对象类型(Service)。
- `metadata.name`:Service 名称。
- `spec.selector`:用于选择 Service 关联的 Pod 的标签。
- `spec.ports`:Service 暴露的端口。
# 3. Kubernetes 集群管理实践
### 3.1 集群安装和配置
#### 3.1.1 单节点集群安装
单节点集群安装适用于开发环境或小型生产环境。它可以在一台机器上运行 Kubernetes 的所有组件,包括 master 节点和 worker 节点。
**步骤:**
1. 准备一台满足 Kubernetes 系统要求的机器。
2. 安装 kubeadm 工具:`sudo apt-get install kubeadm`
3. 初始化集群:`kubeadm init --pod-network-cidr=10.244.0.0/16`
4. 加入 worker 节点:`kubeadm join 192.168.0.100:6443 --token <token> --discovery-token-ca-cert-hash <hash>`
**参数说明:**
* `--pod-network-cidr`:指定 Pod 的网络范围。
* `--token`:用于加入集群的令牌。
* `--discovery-token-ca-cert-hash`:用于验证令牌的 CA 证书哈希值。
#### 3.1.2 多节点集群安装
多节点集群安装适用于生产环境或需要高可用性的场景。它需要多台机器,其中一台作为 master 节点,其余作为 worker 节点。
**步骤:**
1. 准备多台满足 Kubernetes 系统要求的机器。
2. 在 master 节点上安装 kubeadm 工具:`sudo apt-get install kubeadm`
3. 初始化集群:`kubeadm init --control-plane-endpoint=192.168.0.100:6443 --pod-network-cidr=10.244.0.0/16`
4. 在 worker 节点上安装 kubectl 工具:`sudo apt-get install kubectl`
5. 加入 worker 节点:`kubectl join 192.168.0.100:6443 --token <token> --discovery-token-ca-cert-hash <hash>`
**参数说明:**
* `--control-plane-endpoint`:指定 master 节点的地址和端口。
* `--token`:用于加入集群的令牌。
* `--discovery-token-ca-cert-hash`:用于验证令牌的 CA 证书哈希值。
### 3.2 集群监控和运维
#### 3.2.1 常用监控工具
* **Prometheus:**用于收集和存储集群指标。
* **Grafana:**用于可视化和分析 Prometheus 收集的指标。
* **Elasticsearch:**用于存储和查询日志数据。
* **Kibana:**用于可视化和分析 Elasticsearch 中的日志数据。
#### 3.2.2 故障排查和处理
**常见故障:**
* **Pod 无法启动:**检查 Pod 的日志和事件,查看是否有错误信息。
* **Service 无法访问:**检查 Service 的定义是否正确,并且 Pod 是否处于运行状态。
* **集群不可用:**检查 master 节点和 worker 节点是否正常运行,以及网络连接是否正常。
**故障排查步骤:**
1. **收集日志:**使用 `kubectl logs` 命令收集 Pod、Service 和 master 节点的日志。
2. **检查事件:**使用 `kubectl get events` 命令检查集群中的事件,查看是否有错误或警告信息。
3. **检查网络连接:**使用 `ping` 命令检查 master 节点和 worker 节点之间的网络连接。
4. **重启组件:**如果上述步骤无法解决问题,可以尝试重启 Pod、Service 或 master 节点。
# 4. Kubernetes 集群高级特性
### 4.1 存储管理
#### 4.1.1 持久卷和持久卷声明
**持久卷 (PV)** 是 Kubernetes 中存储资源的抽象,代表了集群中可用的物理或云存储空间。PV 可以由各种后端存储系统提供支持,例如本地磁盘、网络文件系统 (NFS) 或云存储服务。
**持久卷声明 (PVC)** 是用户对存储需求的声明。它指定了所需的存储容量、访问模式和持久卷的类型。Kubernetes 会根据 PVC 的要求自动将 PVC 绑定到合适的 PV。
**代码块:创建持久卷声明**
```yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
```
**逻辑分析:**
此代码块创建了一个名为 `my-pvc` 的持久卷声明,请求 1GiB 的存储空间。`accessModes` 指定了 PVC 的访问模式,在本例中为 `ReadWriteOnce`,这意味着该卷只能由一个 Pod 独占访问。
#### 4.1.2 云原生存储解决方案
Kubernetes 提供了多种云原生存储解决方案,用于管理和编排云存储资源。这些解决方案包括:
- **Container Storage Interface (CSI)**:CSI 是一种标准接口,允许 Kubernetes 与各种存储后端集成。
- **Rook**:Rook 是一个开源 Ceph 存储集群管理平台,用于在 Kubernetes 中提供分布式存储服务。
- **Portworx**:Portworx 是一个商业 Kubernetes 存储平台,提供持久卷管理、数据保护和灾难恢复功能。
**表格:云原生存储解决方案比较**
| 解决方案 | 类型 | 特性 |
|---|---|---|
| CSI | 接口 | 允许与各种存储后端集成 |
| Rook | Ceph 集群管理 | 分布式存储,高可用性 |
| Portworx | 商业平台 | 持久卷管理,数据保护,灾难恢复 |
### 4.2 网络管理
#### 4.2.1 Pod 网络模型
Kubernetes 为 Pod 提供了多种网络模型,包括:
- **Bridge 网络**:Pod 拥有自己的 IP 地址,并通过虚拟网桥连接到主机网络。
- **Host 网络**:Pod 与主机共享 IP 地址和网络命名空间。
- **Overlay 网络**:Pod 使用隧道在主机之间进行通信,并拥有自己的 IP 地址。
**代码块:配置 Pod 网络**
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
networkMode: bridge
```
**逻辑分析:**
此代码块配置了一个名为 `my-pod` 的 Pod,使用桥接网络模型。`networkMode` 指定了 Pod 的网络模式,在本例中为 `bridge`。
#### 4.2.2 网络策略和服务网格
**网络策略**用于控制 Pod 之间和 Pod 与外部网络之间的网络流量。它允许管理员定义允许或拒绝哪些网络连接。
**服务网格**是一种分布式系统,用于管理和控制微服务之间的网络通信。它提供高级功能,例如负载均衡、故障转移和可观察性。
**Mermaid 流程图:服务网格架构**
```mermaid
graph LR
subgraph Kubernetes
Pod[Pod]
Deployment[Deployment]
Service[Service]
end
subgraph Service Mesh
Ingress[Ingress]
Egress[Egress]
Service Mesh[Service Mesh]
Virtual Service[Virtual Service]
end
Pod --> Service Mesh
Service --> Service Mesh
Service Mesh --> Ingress
Service Mesh --> Egress
Ingress --> Virtual Service
Virtual Service --> Deployment
```
**参数说明:**
- **Ingress**:用于将外部流量路由到服务网格中的服务。
- **Egress**:用于将服务网格中的流量路由到外部网络。
- **Service Mesh**:服务网格的控制平面,负责管理和控制网络流量。
- **Virtual Service**:用于定义服务网格中服务的路由和策略。
# 5. Kubernetes 集群自动化运维
### 5.1 CI/CD 流程集成
#### 5.1.1 GitOps 工作流
GitOps 是一种软件开发实践,它将 Git 作为单一的事实来源,并通过自动化流程将代码更改部署到生产环境。在 Kubernetes 集群中,GitOps 工作流通常涉及以下步骤:
- **代码提交:**开发人员将代码更改推送到 Git 存储库。
- **持续集成(CI):**CI 工具(如 Jenkins 或 GitHub Actions)自动构建、测试和打包代码。
- **持续交付(CD):**CD 工具(如 Argo CD 或 Flux)将构建好的代码部署到 Kubernetes 集群。
GitOps 的主要优点包括:
- **版本控制:**所有代码更改都记录在 Git 存储库中,便于跟踪和审计。
- **自动化:**CI/CD 流程自动化了代码部署,减少了手动错误。
- **可审计性:**所有部署都记录在 Git 历史中,便于审查和故障排除。
#### 5.1.2 持续交付工具
Kubernetes 集群中常用的持续交付工具包括:
- **Helm:**Helm 是一个 Kubernetes 包管理器,允许用户轻松部署和管理 Kubernetes 应用程序。
- **Argo CD:**Argo CD 是一个 GitOps 部署平台,提供了一系列功能,包括自动部署、回滚和蓝绿部署。
- **Flux:**Flux 是一个 GitOps 操作符,允许用户将 Git 存储库中的声明性配置部署到 Kubernetes 集群。
### 5.2 自动化部署和回滚
#### 5.2.1 Helm 部署工具
Helm 是一个 Kubernetes 包管理器,它使用图表来定义和管理 Kubernetes 应用程序。图表包含应用程序的清单文件、值文件和依赖项。
```yaml
# my-app-chart/Chart.yaml
apiVersion: v2
name: my-app
description: A Helm chart for deploying my-app.
version: 1.0.0
```
```yaml
# my-app-chart/values.yaml
image: my-app:latest
replicaCount: 3
```
要使用 Helm 部署应用程序,可以运行以下命令:
```bash
helm install my-app my-app-chart
```
#### 5.2.2 Argo CD 部署平台
Argo CD 是一个 GitOps 部署平台,它允许用户使用 Git 存储库中的声明性配置来部署和管理 Kubernetes 应用程序。Argo CD 提供了一系列功能,包括:
- **自动部署:**Argo CD 会自动检测 Git 存储库中的更改并部署到 Kubernetes 集群。
- **回滚:**Argo CD 允许用户轻松回滚到以前的部署。
- **蓝绿部署:**Argo CD 支持蓝绿部署,允许用户在部署新版本之前测试新版本。
要使用 Argo CD 部署应用程序,可以运行以下命令:
```bash
argocd app create my-app --repo https://github.com/my-org/my-app.git --path my-app-chart
```
# 6.1 安全性最佳实践
### 6.1.1 Pod 安全上下文
Pod 安全上下文(Pod Security Context)用于定义 Pod 中容器的安全属性。它允许管理员限制容器的权限,以提高集群的安全性。Pod 安全上下文包含以下主要字段:
- **runAsUser 和 runAsGroup:**指定容器内进程运行的用户和组 ID。
- **fsGroup:**指定容器内进程访问文件系统的组 ID。
- **supplementalGroups:**指定容器内进程的附加组 ID。
- **seLinuxOptions:**指定容器内进程的 SELinux 安全上下文。
- **sysctls:**指定容器内进程可以调整的内核参数。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
securityContext:
runAsUser: 1000
runAsGroup: 1000
fsGroup: 1000
supplementalGroups: [1001, 1002]
seLinuxOptions:
user: "user_t"
sysctls:
- name: net.core.somaxconn
value: 1024
```
### 6.1.2 网络安全策略
网络安全策略(Network Policy)用于控制 Pod 之间的网络通信。它允许管理员定义网络规则,以限制 Pod 可以访问的 IP 地址、端口和协议。网络安全策略包含以下主要字段:
- **podSelector:**指定要应用策略的 Pod。
- **ingress:**指定允许进入 Pod 的网络流量。
- **egress:**指定允许从 Pod 发出的网络流量。
```yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: my-network-policy
spec:
podSelector:
matchLabels:
app: my-app
ingress:
- from:
- podSelector:
matchLabels:
app: my-other-app
ports:
- port: 80
protocol: TCP
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/16
ports:
- port: 443
protocol: TCP
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 CentOS 7 Python 安装指南,从入门到高级优化,一步步教你轻松搞定。专栏深入剖析 Python 安装陷阱,帮你避免常见问题。此外,还提供 Python 在 CentOS 7 上的优化安装指南,提升性能和稳定性。专栏还涵盖了 MySQL 数据库性能优化秘籍,揭秘性能下降的幕后真凶及解决策略。深入分析 MySQL 死锁问题,教你如何分析并彻底解决。专栏还提供 MySQL 数据库索引失效案例分析与解决方案,揭秘索引失效的真相。最后,全面解析表锁问题,深度解读 MySQL 表锁问题及解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
datasheet解读速成课:关键信息提炼技巧,提升采购效率

# 摘要
本文全面探讨了datasheet在电子组件采购过程中的作用及其重要性。通过详细介绍datasheet的结构并解析其关键信息,本文揭示了如何通过合理分析和利用datasheet来提升采购效率和产品质量。文中还探讨了如何在实际应用中通过标准采购清单、成本分析以及数据整合来有效使用datasheet信息,并通过案例分析展示了datasheet在采购决策中的具体应用。最后,本文预测了datasheet智能化处
【光电传感器应用详解】:如何用传感器引导小车精准路径

# 摘要
光电传感器在现代智能小车路径引导系统中扮演着核心角色,涉及从基础的数据采集到复杂的路径决策。本文首先介绍了光电传感器的基础知识及其工作原理,然后分析了其在小车路径引导中的理论应用,包括传感器布局、导航定位、信号处理等关键技术。接着,文章探讨了光电传感器与小车硬件的集成过程,包含硬件连接、软件编程及传感器校准。在实践部分,通过基
新手必看:ZXR10 2809交换机管理与配置实用教程
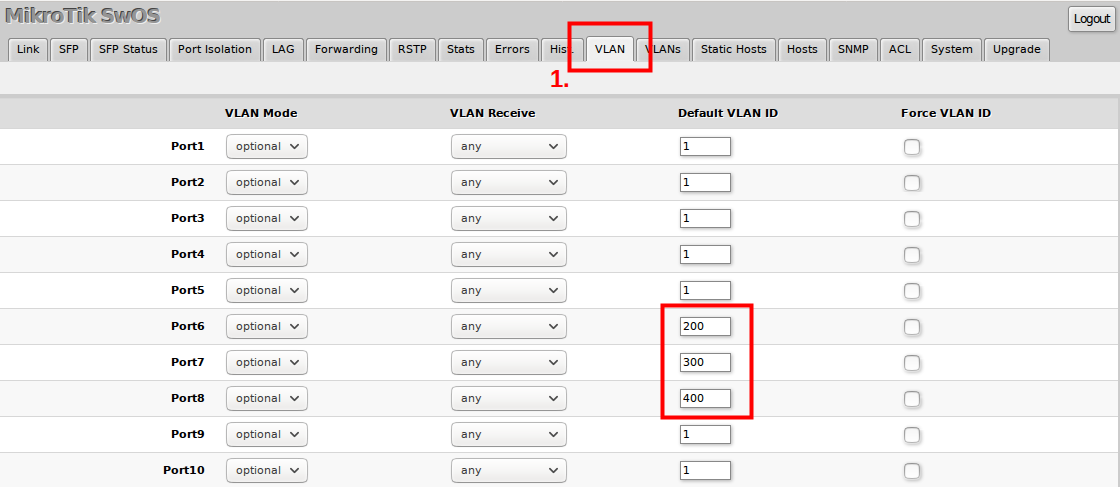
# 摘要
ZXR10 2809交换机作为网络基础设施的关键设备,其配置与管理是确保网络稳定运行的基础。本文首先对ZXR10 2809交换机进行概述,并介绍了基础管理知识。接着,详细阐述了交换机的基本配置,包括物理连接、初始化配置、登录方式以及接口的配置与管理。第三章深入探讨了网络参数的配置,VLAN的创建与应用,以及交换机的安全设置,如ACL配置和端口安全。第四章涉及高级网络功能,如路由配置、性能监控、故障排除和网络优
加密技术详解:专家级指南保护你的敏感数据
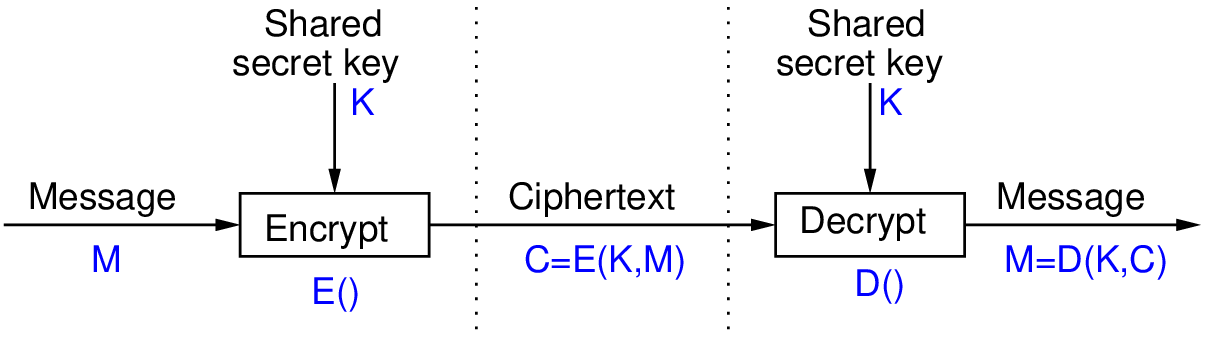
# 摘要
本文系统介绍了加密技术的基础知识,深入探讨了对称加密与非对称加密的理论和实践应用。分析了散列函数和数字签名在保证数据完整性与认证中的关键作用。进一步,本文探讨了加密技术在传输层安全协议TLS和安全套接字层SSL中的应用,以及在用户身份验证和加密策略制定中的实践。通过对企业级应用加密技术案例的分析,本文指出了实际应用中的挑战与解决方案,并讨论了相关法律和合规问题。最后,本文展望了加密技术的未来发展趋势,特别关注了量
【16串电池监测AFE选型秘籍】:关键参数一文读懂

# 摘要
本文全面介绍了电池监测AFE(模拟前端)的原理和应用,着重于其关键参数的解析和选型实践。电池监测AFE是电池管理系统中不可或缺的一部分,负责对电池的关键性能参数如电压、电流和温度进行精确测量。通过对AFE基本功能、性能指标以及电源和通信接口的分析,文章为读者提供了选择合适AFE的实用指导。在电池监测AFE的集成和应用章节中
VASPKIT全攻略:从安装到参数设置的完整流程解析

# 摘要
VASPKIT是用于材料计算的多功能软件包,它基于密度泛函理论(DFT)提供了一系列计算功能,包括能带计算、动力学性质模拟和光学性质分析等。本文系统介绍了VASPKIT的安装过程、基本功能和理论基础,同时提供了实践操作的详细指南。通过分析特定材料领域的应用案例,比如光催化、
【Exynos 4412内存管理剖析】:高速缓存策略与性能提升秘籍
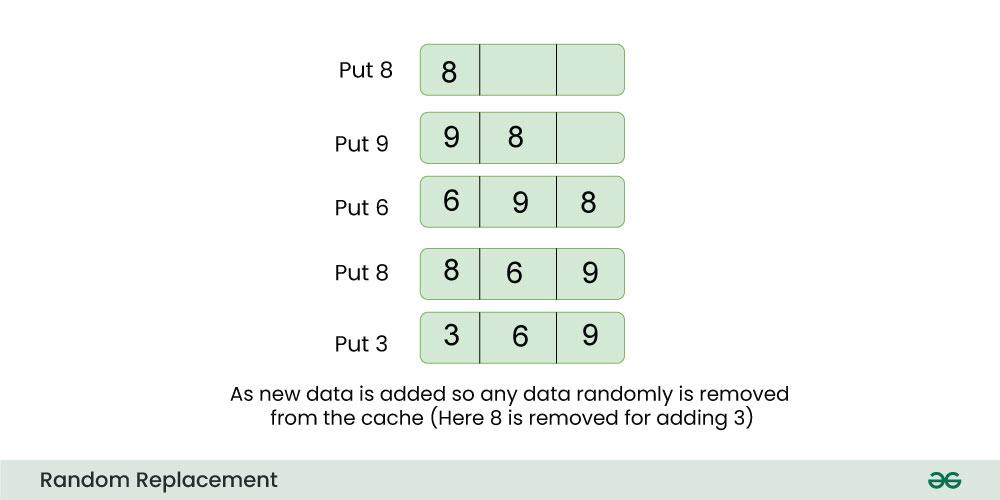
# 摘要
本文对Exynos 4412处理器的内存管理进行了全面概述,深入探讨了内存管理的基础理论、高速缓存策略、内存性能优化技巧、系统级内存管理优化以及新兴内存技术的发展趋势。文章详细分析了Exynos 4412的内存架构和内存管理单元(MMU)的功能,探讨了高速缓存架构及其对性能的影响,并提供了一系列内存管理实践技巧和性能提升秘籍。此外,
慧鱼数据备份与恢复秘籍:确保业务连续性的终极策略(权威指南)
# 摘要
本文全面探讨了数据备份与恢复的基础概念,备份策略的设计与实践,以及慧鱼备份技术的应用。通过分析备份类型、存储介质选择、备份工具以及备份与恢复策略的制定,文章提供了深入的技术见解和配置指导。同时,强调了数据恢复的重要性,探讨了数据恢复流程、策略以及慧鱼数据恢复工具的应用。此
【频谱分析与Time Gen:建立波形关系的新视角】:解锁频率世界的秘密
# 摘要
本文旨在探讨频谱分析的基础理论及Time Gen工具在该领域的应用。首先介绍频谱分析的基本概念和重要性,然后详细介绍Time Gen工具的功能和应用场景。文章进一步阐述频谱分析与Time Gen工具的理论结合,分析其在信号处理和时间序列分析中的作用。通过多个实践案例,本文展示了频谱分析与Time Gen工具相结合的高效性和实用性,并探讨了其在高级应用中的潜在方向和优势。本文为相关领域的研究人员和工程师
【微控制器编程】:零基础入门到编写你的首个AT89C516RD+程序
# 摘要
本文深入探讨了微控制器编程的基础知识和AT89C516RD+微控制器的高级应用。首先介绍了微控制器的基本概念、组成架构及其应用领域。随后,文章详细阐述了AT89C516RD+微控制器的硬件特性、引脚功能、电源和时钟管理。在软件开发环境方面,本文讲述了Keil uVision开发工具的安装和配置,以及编程语言的使用。接着,文章引导读者通过实例学习编写和调试AT89C516RD+的第一个程序,并探讨了微控制器在实践应用中的接口编程和中断驱动设计。最后,本文提供了高级编程技巧,包括实时操作系统的应用、模块集成、代码优化及安全性提升方法。整篇文章旨在为读者提供一个全面的微控制器编程学习路径,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )