Pylons.wsgiapp部署策略揭秘
发布时间: 2024-10-14 17:54:10 阅读量: 20 订阅数: 21 

孙允中临证实践录.pdf
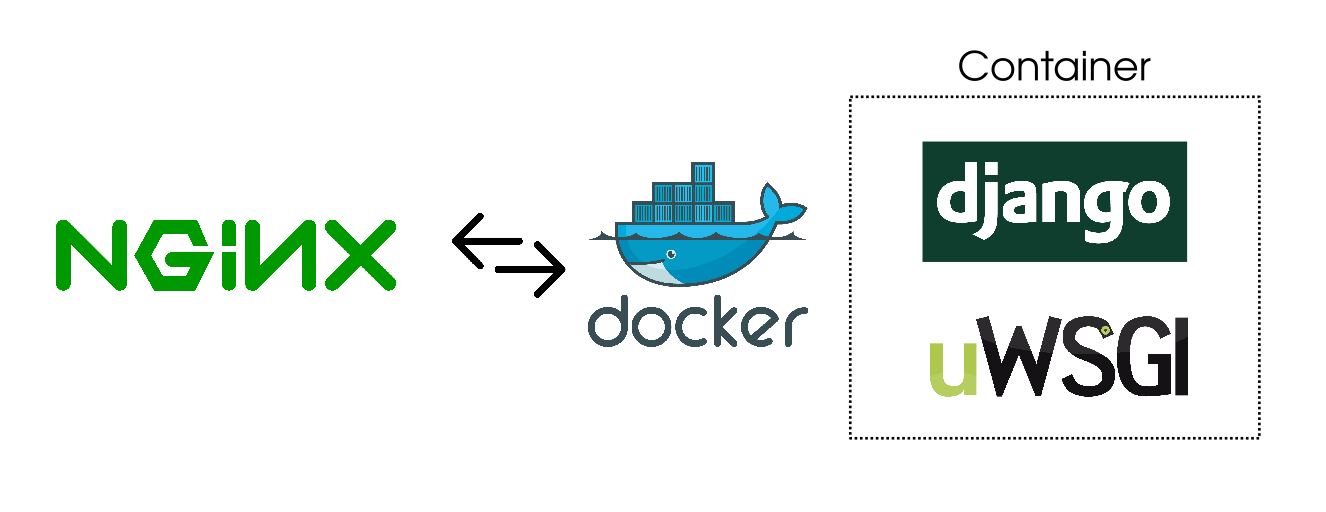
# 1. Pylons.wsgiapp概述
## 1.1 Pylons.wsgiapp简介
Pylons.wsgiapp是一个基于Python的Web应用框架,它遵循WSGI标准,提供了一套简洁、高效的方式来构建Web应用程序。Pylons以其轻量级、可扩展性和灵活性而闻名,适合构建企业级的Web应用。通过Pylons.wsgiapp,开发者可以利用Python的强大功能,轻松实现复杂的Web功能,包括数据库交互、表单处理、安全认证等。
## 1.2 Pylons.wsgiapp的核心特性
- **轻量级框架**:Pylons.wsgiapp没有复杂的依赖,易于安装和维护。
- **遵循WSGI标准**:这意味着它可以与任何兼容WSGI的应用程序服务器无缝工作。
- **MVC架构**:它采用模型-视图-控制器(MVC)架构,使得代码易于组织和维护。
- **强大的插件系统**:Pylons支持插件,允许开发者扩展其功能以满足特定需求。
- **灵活的路由机制**:支持REST风格的URL路由,提供了丰富的路由配置选项。
## 1.3 Pylons.wsgiapp的应用场景
Pylons.wsgiapp适用于多种应用场景,包括但不限于:
- **企业级Web应用**:Pylons的能力使其能够处理高并发的Web请求。
- **内容管理系统**(CMS):其灵活的插件系统非常适合创建定制的CMS解决方案。
- **Web API服务**:Pylons.wsgiapp支持RESTful服务的构建,适合开发API端点。
## 1.4 Pylons.wsgiapp与其他Web框架的比较
与其他流行的Python Web框架(如Django、Flask)相比,Pylons.wsgiapp更倾向于提供一套最小化的核心功能,以便开发者可以根据项目需求进行自由扩展。虽然Django提供了更多的开箱即用功能,Flask则以轻量级和简洁著称,Pylons.wsgiapp则在性能和扩展性方面表现出色,适合需要高度定制的大型Web项目。
# 2. Pylons.wsgiapp的部署环境准备
## 2.1 选择合适的服务器
在部署Pylons.wsgiapp应用之前,选择一个合适的服务器是至关重要的。服务器的选择不仅影响应用的性能,还直接关联到部署的复杂度和成本。我们将分别探讨Linux和Windows服务器的选取,以便为Pylons.wsgiapp应用找到最佳的宿主环境。
### 2.1.1 Linux服务器的选取
Linux服务器由于其开源、稳定、高效等特点,在生产环境中被广泛使用。Linux系统对于Python和Pylons框架有着良好的支持,尤其是基于Debian和RedHat的发行版。
**选择Linux发行版时需要考虑的因素:**
- **稳定性**:长期支持(LTS)版本的Linux发行版,如Ubuntu LTS或CentOS LTS,可以保证系统长时间的稳定性。
- **社区支持**:活跃的社区和大量的文档资源可以帮助解决部署中遇到的问题。
- **安全性**:安全更新及时的发行版,如Debian或CentOS,可以降低安全风险。
**常见的Linux服务器选项包括:**
- **Ubuntu**:新手友好,有大量的社区支持和文档。
- **CentOS**:企业级的选择,稳定性强,适合生产环境。
- **Fedora**:适合喜欢尝试新技术的用户,更新频率高。
在选择服务器时,应根据应用的具体需求和团队的技术能力来决定最合适的Linux发行版。
### 2.1.2 Windows服务器的选取
虽然Pylons.wsgiapp主要针对Linux环境设计,但也可以在Windows服务器上运行。Windows服务器在某些特定场景下有其独特的优势,例如与Microsoft产品生态的整合。
**选择Windows服务器时需要考虑的因素:**
- **应用兼容性**:确保Pylons应用能够在Windows上运行,特别是如果使用了特定于平台的库或功能。
- **成本**:Windows服务器通常是商业产品,需要考虑授权成本。
- **维护**:需要专业的Windows系统管理员来进行维护和管理。
**常见的Windows服务器选项包括:**
- **Windows Server**:适合企业级应用,整合了Active Directory等企业功能。
- **IIS**:作为Windows的原生Web服务器,可以提供Web服务。
在选择Windows服务器时,通常需要更多的专业知识和资源,但可以提供更好的企业级支持和安全性能。
## 2.2 服务器环境的配置
服务器配置是部署Pylons.wsgiapp应用的关键步骤,涉及到安装必要的软件和库,以及创建部署用户和用户组。
### 2.2.1 安装必要的软件和库
无论选择Linux还是Windows服务器,都需要安装Python解释器和必要的库。以下是安装Python和Pylons.wsgiapp依赖的示例步骤:
```bash
# 安装Python解释器和pip包管理器
sudo apt-get update
sudo apt-get install python3 python3-pip
# 安装Pylons.wsgiapp依赖的库
pip3 install virtualenv
pip3 install Pylons
```
### 2.2.2 创建部署用户和用户组
为了安全起见,建议不要使用root或administrator账户来运行应用。应该创建一个专用的部署用户和用户组。
```bash
# 创建部署用户
sudo adduser deploy
# 创建用户组
sudo groupadd deploy_users
# 将部署用户添加到用户组
sudo usermod -a -G deploy_users deploy
```
## 2.3 部署工具的介绍
为了简化部署流程,可以使用一些部署工具,如Fabric自动化部署和Ansible配置管理。
### 2.3.1 使用Fabric自动化部署
Fabric是一个Python库和命令行工具,用于简化本地或远程shell命令的执行。它可以用来自动化部署过程,包括代码部署、服务重启等。
**安装Fabric:**
```bash
pip3 install fabric
```
**一个简单的Fabric脚本示例:**
```python
# fabfile.py
from fabric.api import execute, run, sudo
def deploy():
# 部署应用代码
run('git clone ***')
# 安装依赖
run('pip3 install -r requirements.txt')
# 重启应用
sudo('systemctl restart myservice')
```
**执行部署:**
```bash
fab deploy
```
### 2.3.2 使用Ansible进行配置管理
Ansible是一个自动化运维工具,通过SSH来管理配置。它可以用来部署应用、配置系统和管理服务。
**安装Ansible:**
```bash
sudo apt-get install ansible
```
**一个简单的Ansible playbook示例:**
```yaml
# playbook.yml
- hosts: all
become: yes
vars:
app_user: deploy
tasks:
- name: Create deploy user
user:
name: "{{ app_user }}"
group: "{{ app_user }}"
createhome: yes
```
**执行playbook:**
```bash
ansible-playbook -i inventory playbook.yml
```
通过使用这些工具,可以大大简化部署流程,减少人为错误,并提高部署效率。下一章我们将深入探讨Pylons.wsgiapp的部署实践。
# 3. Pylons.wsgiapp的部署实践
#### 3.1 部署流程解析
##### 3.1.1 代码获取和依赖安装
在本章节中,我们将详细介绍Pylons.wsgiapp的部署流程,从代码获取到依赖安装,再到WSGI应用的配置。首先,我们需要获取Pylons项目的源代码。通常,这可以通过Git版本控制系统来完成。以下是获取代码的步骤:
1. **安装Git**:首先确保服务器上已安装Git,可以通过包管理器安装,例如在Ubuntu上使用`sudo apt-get install git`。
2. **克隆仓库**:使用`git clone`命令克隆Pylons项目到本地目录,例如`git clone ***`。
```bash
# 克隆Pylons项目
git clone ***
```
3. **安装依赖**:依赖安装通常使用pip工具,可以通过`requirements.txt`文件来管理。使用以下命令安装所有必需的Pyth

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Pylons.wsgiapp 库,为 Python 开发人员提供了全面的指南。从深入解析其内部机制到掌握调试技巧,再到性能调优和测试策略,本专栏涵盖了使用 Pylons.wsgiapp 的各个方面。此外,它还提供了代码重构、日志管理、缓存机制、异步处理和消息队列的使用指南,以及 API 设计的最佳实践。通过本专栏,Python 开发人员可以全面了解 Pylons.wsgiapp,并充分利用其功能来构建高效、可扩展的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
硬件优化秘籍:MV88芯片性能提升的10大策略

# 摘要
MV88芯片作为高性能计算平台的核心,面临诸多性能挑战。本文首先介绍了MV88芯片的基本架构及其性能挑战,随后深入探讨了硬件优化的理论基础,包括硬件优化的目标与意义、性能评估方法以及理论模型。在硬件性能提升方面,本文详述了电路设计、制造工艺改进和热管理等关键技术实践。软件协同优
【ANSYS Q3D Extractor 速成指南】:零基础开启电磁场分析之旅

# 摘要
本文全面介绍了ANSYS Q3D Extractor软件的使用,包括其简介、安装、基础操作、理论基础以及在实际项目中的应用。首先,我们讨论了软件的界面布局、功能模块、建立模型、网格划分和执行分析等基础操作。接着,
【南邮软件工程课程设计】:揭开教务系统构思与挑战的神秘面纱
# 摘要
教务系统作为高校信息化建设的重要组成部分,其设计与实现直接影响到教学管理的效率与质量。本文首先介绍了教务系统设计的概念框架,随后深入分析了核心功能,包括学生信息管理、课程与选课系统以及成绩管理系统的具体实现细节。在第三章中,本文讨论了教务系统的设计实践,包括数据库设计、系统架构的选择和安全性与可靠性设计。文章第四章探讨了教务系统在实际应用中面临的挑战,并提出了相应的解决方案。最后,通过
搭建与维护Maven仓库:中央与私有仓库的专家级指南

# 摘要
本文全面概述了Maven仓库的运作机制及其在软件构建过程中的重要性。通过探讨中央仓库的管理方式和私有仓库的搭建配置,本文为读者提供了深入理解和应用Maven仓库的实用指南。此外,本文着重分析了仓库管理的高级实践,讨论了仓库的安全性和备份策略,并提供了性能调优与故障排除的详细策略。文章旨在帮助开发团队更高效地管理软件依赖,确保构建过程的稳定性和安全性,同时
S57与S52标准深度对比:行业选择策略与关键差异
# 摘要
随着通信技术的发展,S57与S52标准在相关行业的应用变得尤为重要。本文首先概述了S57与S52标准的基本框架和行业背景,随后探讨了选择行业标准的策略,包括市场背景和技术兼容性等关键因素。在深度对比分析中,文章着重考察了两种标准在结构、性能、效率以及实施维护方面的差异。进一步,本文分析了这些关键差异对行业应用、产品开发以及最终用户的具体影响,并提出了实践中的策略建议。最后,通过案例研究,本文总结了行业选择策略的实际应用,并对未来的发展趋势进行了展望,同时指出了本研究的局限性和未来方向。
# 关键字
S57标准;S52标准;行业选择策略;技术兼容性;性能与效率;实施与维护
参考资源
Ubuntu文件系统揭秘:深度剖析Qt文件覆盖的根本原因

# 摘要
本文旨在深入探讨Ubuntu文件系统和Qt框架文件操作的交互作用,尤其是文件覆盖问题。首先,本文对Ubuntu文件系统进行概述,并阐述了Linux文件系统原理
家谱二叉树层次遍历:快速定位直系亲属的秘诀
/i.s3.glbimg.com/v1/AUTH_da025474c0c44edd99332dddb09cabe8/internal_photos/bs/2022/l/u/6Tw8o3QeeTFC5P5BArBA/pele-sete-filhos.jpg)
# 摘要
家谱二叉树作为一种重要的数据结构,在信息管理和遗传学研究中具有广泛应用。本文全
【DNAMAN高级应用】:8个技巧优化PCR条件,减少非特异性扩增
# 摘要
本文旨在介绍DNAman软件在PCR技术中的应用,并探讨优化PCR反应条件的理论基础与实验技巧。通过分析PCR的原理、关键要素、特异性影响因素,以及温度梯度、引物设计和模板质量的重要性,我们提出了一套理论策略来优化PCR条件。接着,本文展示了如何使用DNAman软件通过模拟实验进行PCR条件的优化,并讨论了如何分析PCR结果以微调参数。高级技巧部分详细介绍了减少非特异性扩增的方法,包括特殊
固体氧化物燃料电池性能测试标准与方法指南

# 摘要
本文综述了固体氧化物燃料电池的基本理论和技术,重点介绍了性能测试的基本理论与技术,并详述了实验室规模测试和现场应用性能评估的方法。通过对固体氧化物燃料电池的工作原理和材料特性的探讨,以及对国际标准的分析,本文揭示了关键性能参数如输出功率、能量效率和寿命的测试方法,并考虑了环境与负载对性能的影响。现场应用性能评估部分涵盖了准备工作、性能与环境适应性测试以及长期运行稳定性分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )