【U8运行时错误代码重构宝典】:代码重构与维护的最佳实践指南
发布时间: 2024-12-01 06:32:10 阅读量: 5 订阅数: 7 

参考资源链接:[U8 运行时错误 440,运行时错误‘6’溢出解决办法.pdf](https://wenku.csdn.net/doc/644bc130ea0840391e55a560?spm=1055.2635.3001.10343)
# 1. U8运行时错误代码重构的重要性
## 1.1 代码重构的基本概念
代码重构是在不改变软件外部行为的前提下,提高代码质量,优化代码结构的过程。对U8运行时错误代码进行重构,意味着修复和改善已存在的错误,提高程序的可读性、可维护性以及性能。
## 1.2 运行时错误代码问题的严重性
运行时错误代码会导致程序崩溃、数据丢失或安全漏洞,对系统的稳定性和用户体验产生严重影响。重构这类代码能够提前识别和规避潜在问题,减少系统故障。
## 1.3 重构对业务连续性的重要性
在IT行业,业务连续性至关重要。通过重构,可以确保系统能够在不断变化的需求下依然稳定运行,适应业务发展,减少因错误代码引起的系统停机时间。这不仅对技术团队,对整个企业来说都具有长远意义。
# 2. 理解U8运行时错误代码结构
## 2.1 U8错误代码的基本组成
### 2.1.1 错误代码的分类与识别
在U8系统中,运行时错误代码是一组特定的标识符,用于指示程序在执行过程中遇到的问题。这些错误代码可以分为三大类:逻辑错误、资源错误和系统错误。
- **逻辑错误**:通常是由于程序中的算法或业务逻辑不正确导致的错误。例如,参数检查失败或无效的业务操作。
- **资源错误**:通常与程序无法正常访问外部资源有关。这可能包括文件读写错误、网络连接失败等。
- **系统错误**:这些错误与操作系统级别的问题相关,例如内存不足或进程权限问题。
要准确识别错误代码,首先需要熟悉U8错误代码的命名规则。一般而言,U8错误代码由四部分组成:模块标识、错误类型、错误级别和错误序号。例如,“E01001”可能表示模块标识为E01的第一个错误类型,且是级别1的错误。
### 2.1.2 错误代码的数据结构分析
错误代码背后的数据结构是理解其工作机制的关键。这些数据结构通常包括错误消息、错误代码本身、发生错误的文件名和行号以及可能的解决方案。
一个典型的U8错误代码的数据结构可能如下所示:
```c++
struct U8Error {
int moduleID;
int errorType;
int errorLevel;
int sequenceNumber;
std::string errorMessage;
std::string errorFile;
int errorLine;
std::string solution;
};
```
这个结构体为错误代码提供了清晰的分类和详细信息,从而使得错误追踪和处理变得更为直接。
## 2.2 U8错误代码的生成机制
### 2.2.1 错误生成的触发条件
在U8系统中,错误的生成通常由特定的触发条件引起,这些条件包括但不限于:
- 输入数据不合法或不符合预期格式。
- 系统资源未能按照预期进行分配或被正确使用。
- 程序试图访问其权限范围之外的资源。
- 内部程序逻辑判断为错误情况。
为了生成错误代码,U8系统通常会检查上述条件,并在条件满足时触发错误生成机制。
### 2.2.2 错误代码与程序状态的关联
U8运行时错误代码的生成机制还涉及将错误代码与程序状态相关联。程序状态可能包括系统环境、当前操作、用户信息等。错误代码生成时,这些状态信息被记录下来,并与错误代码一起存储。
通过关联这些状态信息,开发人员可以获得错误发生时的上下文环境,这对于准确识别和修复错误至关重要。如下面的代码块所示,错误状态可以通过一个日志记录函数记录下来:
```c++
void LogError(U8Error &error) {
// 记录错误消息和状态
std::ofstream logFile("error.log", std::ios::app);
logFile << "Error: " << error.errorMessage;
logFile << " at " << error.errorFile << ":" << error.errorLine;
logFile << " in module " << error.moduleID << " - Type: " << error.errorType;
logFile << " Level: " << error.errorLevel << " Sequence: " << error.sequenceNumber;
logFile << "\nSolution: " << error.solution << std::endl;
}
```
## 2.3 U8错误代码的跟踪与监控
### 2.3.1 错误跟踪的策略与方法
为了有效跟踪和处理错误,U8系统采用了一系列策略和方法。这些方法包括但不限于:
- **日志记录**:将错误信息记录到日志文件中,便于后续分析。
- **即时通知**:在关键操作中遇到错误时,实时通知开发者或系统管理员。
- **错误仪表板**:提供一个集中的监控界面,显示最新的错误信息和统计指标。
此外,采用适当的日志级别,如DEBUG、INFO、WARN、ERROR和FATAL,可以进一步帮助开发者定位错误发生的位置。
### 2.3.2 错误监控工具与日志分析
为了实现有效的错误监控,U8系统会集成一些监控工具,如ELK(Elasticsearch, Logstash, Kibana)栈或Prometheus和Grafana。这些工具可以帮助开发团队跟踪错误的发生频率、影响范围以及可能的根本原因。
下面是一个简化的示例代码,演示如何将错误信息发送到一个假设的监控系统中:
```c++
void SendErrorToMonitoringSystem(U8Error &error) {
// 模拟发送错误信息到监控系统
std::cout << "Sending error to monitoring system: " << error.errorMessage << std::endl;
// 在实际应用中,这里的代码会与监控系统API进行交互
}
```
通过综合使用日志分析工具和监控系统,U8系统能够有效地跟踪错误,并及时采取措施来修复和防止错误再次发生。
# 3. U8错误代码重构的理论基础
## 3.1 重构的原则与目标
### 3.1.1 重构的定义与核心原则
重构是一种软件开发过程中的技术,它不改变软件的外部行为,只改变其内部结构,以提高软件的可读性和可维护性。重构的核心原则在于逐步、有计划地改进现有代码的设计,而不影响其功能表现。这意味着开发者在不添加新功能的前提下,对系统进行小范围的修改,以解决代码中的问题,提高其效率和可理解性。
### 3.1.2 重构的目标与预期效果
重构的目标是改进软件的质量。通过重构,开发者可以减少代码中的冗余和复杂性,使代码更加模块化。预期效果包括代码易于理解、易于修改、易于扩展,从而降低维护成本。此外,重构还能帮助发现并修复隐藏的缺陷,提高软件的整体稳定性。
## 3.2 设计模式在U8重构中的应用
### 3.2.1 设计模式概述
设计模式是一套被反复使用、多数人知晓、经过分类编目、代码设计经验的总结。在U8错误代码重构中,设计模式可以帮助开发者更好地组织代码结构,使得代码更加清晰、可维护。常见的设计模式包括单例模式、工厂模式、策略模式等,每种模式针对不同的设计问题提供了通用的解决方案。
### 3.2.2 设计模式在错误代码重构中的实例
以工厂模式为例,它提供了一种创建对象的最佳方式。在错误代码重构过程中,如果存在多种不同类型的错误代码对象,可以使用工厂模式来创建这些对象,从而避免直接实例化具体错误类,增加代码的灵活性和可扩展性。例如,在U8系统中,不同的错误类型可以通过工厂类统一管理,当需要处理一个错误时,只需调用工厂类来获取相应类型的错误对象。
```java
// 工厂模式示例代码
public interface ErrorFactory {
Error createError(String code);
}
public class S
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【对比分析】Romax CAD-Fusion与其他CAD软件:哪个更适合你?
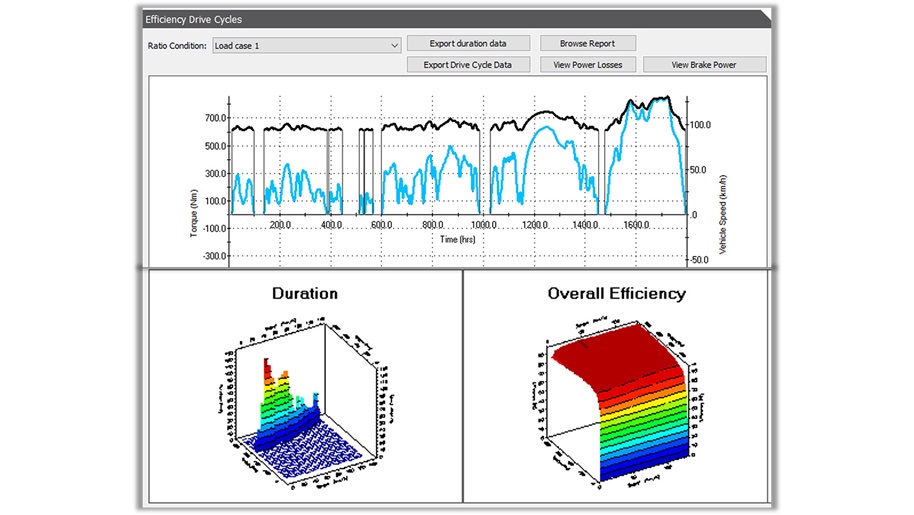
参考资源链接:[Romax软件教程:CAD Fusion几何模型的导入与导出](https://wenku.csdn.net/doc/54igq1bm01?spm=1055.2635.3001.10343)
# 1. CAD软件概述与
三星K2200打印机乱码问题终结者:维修模式下的精准解决方案(清晰输出)

参考资源链接:[三星K2200打印机进入维修模式并且清除传输卷寿命的方法.docx](https://wenku.csdn.net/doc/6412b6d0be7fbd1778d48144?spm=1055.2635.3001.10343)
# 1. 三星K2200打印机乱码现象概述
在现代办公环境中,打印机是不可或缺的设备之一。然而,当打印机输出
CST OPERA中的时域分析:深入理解与应用的关键点!

参考资源链接:[OPERA电磁仿真软件操作指南:从建模到分析全流程详解](https://wenku.csdn.net/doc/68j8dur3r0?spm=1055.2635.3001.10343)
# 1. CST OPERA简介与基础设置
CST OPERA 是一款在电磁场仿真领域中广泛应用的软件,它提供了一套完整的解决方案,包括时域和频域分析、静态场分析以及耦合场分析等。本章将首先介绍CST OPERA的基本概念,然后逐步引导读者完成软
【5G网络与物联网】:物联网在5G中的新机遇,把握未来脉搏

参考资源链接:[NR5G网络拒绝码-5gsm_cause = 36 (0x24) (Regular deactivation).docx](https://wenku.csdn.net/doc/644b82f1fcc5391368e5ef6a?spm=1055.2635.3001.10343)
# 1. 5G网络与物联网的融合
## 简介
随着技术的进步,5G网络与物联网的融合正在逐渐改变我们的世界。5G的高
自由能计算在GROMACS模拟中的方法与技巧:专家分享
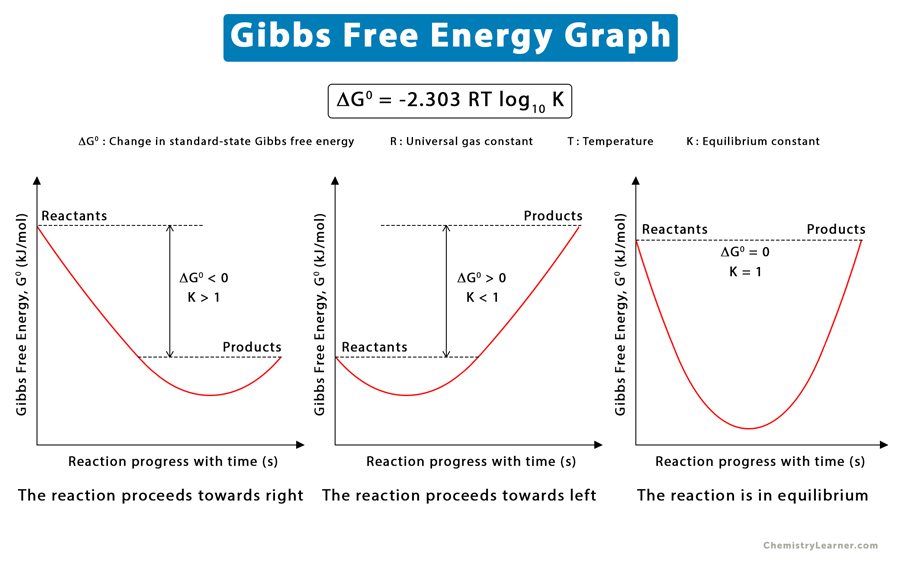
参考资源链接:[Gromacs模拟教程:从pdb到gro,top文件生成及初步模拟](https://wenku.csdn.net/doc/2d8k99rejq?spm=1055.2635.3001.10343)
# 1. GROMACS模拟简介与安装配置
## 1.1 GROMACS模拟简介
GROMACS(GROningen MAchine for
灾难恢复与权限管理:RunAsTool在危机中的关键作用

参考资源链接:[RunAsTool:轻松赋予应用管理员权限](https://wenku.csdn.net/doc/6412b72bbe7fbd1778d49559?spm=1055.2635.3001.10343)
# 1. 灾难恢复的基本概念与策略
## 1.1 灾难恢复的重要性
在数字化时代,企业依赖于信息系统进行日常运营。任何系统故障或数据丢失都可能导致业务中断,对企业的财务和声誉造成重
新能源汽车电力心脏:PLECS在电动汽车电池管理系统的应用探究
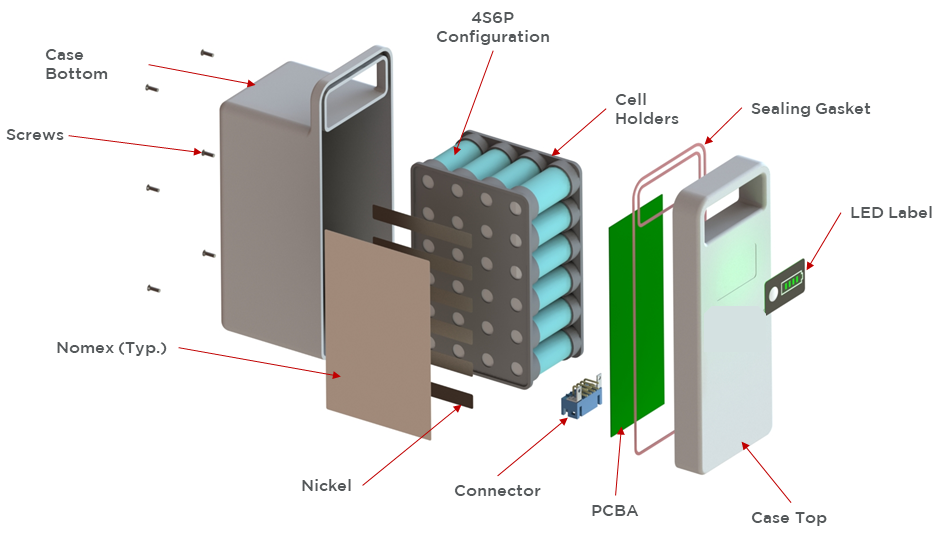
参考资源链接:[PLECS中文使用手册:电力电子系统建模与仿真指南](https://wenku.csdn.net/doc/6401abd1cce7214c316e99bb?spm=1055.2635.3001.10343)
# 1. 电动汽车电池管理系统概述
随着全球能源转型和环境保护意识的增强,电动汽车(EV)成为了未来汽车工业发展的重要方向
【故障诊断】:清华Virtuoso常见问题快速诊断与解决方案

参考资源链接:[清华微电子所Cadence Virtuoso教程:从入门到精通](ht
Abaqus发布周期规划:巧妙升级避免兼容性陷阱

参考资源链接:[低版本ABAQUS开启高版本模型:去除版本冲突教程](https://wenku.csdn.net/doc/6412b6a1be7fbd1778d476b2?spm=1055.2635.3001.10343)
# 1. Abaqus发布周期规划概览
## 1.1 认识Abaqus及其发布周期的重要性
Abaqus是一款强大的有限元分析软件,广泛应用于工程模拟、计算力学等领域。了解其
SM25QH256MX深度剖析:掌握编程、故障排除及优化技巧(全面攻略)
参考资源链接:[国微SM25QH256MX:256Mb SPI Flash 存储器规格说明书](https://wenku.csdn.net/doc/1s6cz8fsd9?spm=1055.2635.3001.10343)
# 1. SM25QH256MX存储器概述
SM25QH256MX是华邦电子推出的一款高容量存储器,采用了先进的SMIC 40nm工艺技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )