【NSGA-II在工程设计中的应用】:案例研究与效果评估,专家深度剖析
发布时间: 2024-12-27 00:44:05 阅读量: 4 订阅数: 10 

NSGA-II:NSGA-II在Java中的实现
# 摘要
NSGA-II算法作为一种先进的多目标优化技术,广泛应用于工程设计领域以解决复杂问题。本文首先概述NSGA-II算法及其基础理论,包括多目标优化问题的定义、算法原理与优势、数学模型、以及参数设置与调优策略。随后,深入分析NSGA-II在机械设计、电子工程和土木工程中的应用案例,展示其在实际问题解决中的有效性。通过对算法性能的评估和与MOGA、SPEA2等其他算法的对比分析,本文总结了NSGA-II算法的当前成果和应用前景,并提出未来改进方向与对工程设计领域的建议。
# 关键字
NSGA-II算法;多目标优化;非支配排序;密度估计;参数调优;工程设计应用
参考资源链接:[NSGA-II算法详解:多目标优化与Pareto最优解](https://wenku.csdn.net/doc/87dsdawwwu?spm=1055.2635.3001.10343)
# 1. NSGA-II算法概述
NSGA-II(非支配排序遗传算法 II)是一种流行的多目标优化遗传算法,由Kalyanmoy Deb等人在2002年提出,用于同时处理多个、往往相互冲突的目标函数。相较于传统的单目标优化方法,NSGA-II能有效识别出一组多样化的最优解,即Pareto最优解集。这些解在多个目标函数之间提供了最佳的权衡,从而使决策者可以根据具体需要选择最合适的解。NSGA-II通过特定的遗传操作和排序机制,保证了解的多样性和收敛性,特别适用于工程设计、经济模型和环境规划等领域的复杂问题优化。
# 2. NSGA-II的基础理论分析
在上一章节的简介中,我们对NSGA-II算法有了初步的认识。这一章节,我们将深入探讨NSGA-II算法的理论基础,包括多目标优化问题的定义,算法的原理、优势,数学模型和机制,以及参数设置和调优的策略。
## 2.1 多目标优化问题与NSGA-II
### 2.1.1 多目标优化问题的定义
在工程设计和科学计算中,多目标优化问题广泛存在。这些问题涉及同时优化两个或两个以上的冲突目标。一个典型的例子是,在设计一辆汽车时,我们需要考虑燃油效率、安全性能、成本和环境影响等多个因素。每个因素都可以被看作是一个优化目标,而且它们通常相互矛盾,提升一个目标往往以牺牲另一个目标为代价。在数学上,一个多目标优化问题可以表示为:
\[
\begin{align*}
\text{minimize/maximize} \quad & F(x) = (f_1(x), f_2(x), \ldots, f_n(x)) \\
\text{subject to} \quad & g_i(x) \leq 0, \quad i = 1, \ldots, m \\
& h_j(x) = 0, \quad j = 1, \ldots, p \\
& x \in \Omega
\end{align*}
\]
这里,\( F(x) \)是一个向量值函数,\( f_i(x) \)是第\( i \)个目标函数,\( x \)是决策变量向量,\( g_i(x) \leq 0 \)和\( h_j(x) = 0 \)是约束条件,\( \Omega \)是决策空间。
### 2.1.2 NSGA-II算法的原理与优势
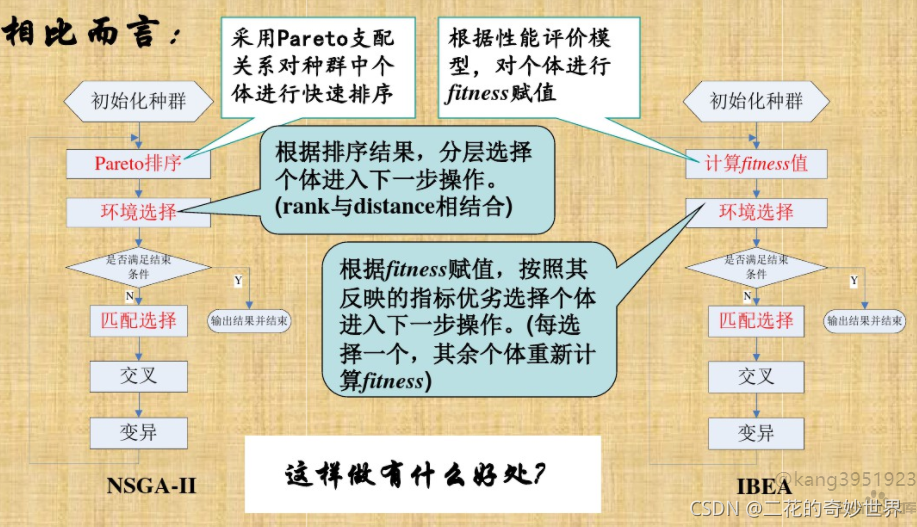
NSGA-II(Non-dominated Sorting Genetic Algorithm II)是解决多目标优化问题的有效算法之一。它在第一代NSGA的基础上进行了重要的改进,特别是在非支配排序和拥挤距离概念的引入。NSGA-II的特点是快速、鲁棒性强,能够产生多样性和密集的Pareto前沿面,从而为决策者提供更多的选择。
NSGA-II的原理是通过遗传算法中的选择、交叉和变异操作,迭代地更新种群,直到满足终止条件。算法的主要优势体现在非支配排序机制和拥挤距离方法的使用,这有助于更好地保留多样化的解集,并促进种群的多样性和Pareto前沿面的广泛覆盖。
## 2.2 NSGA-II的数学模型与机制
### 2.2.1 非支配排序的原理
在NSGA-II算法中,非支配排序是一种核心概念。一个解如果在所有目标上都优于另一个解,那么它被称为支配另一个解。非支配排序的目的是将种群划分为不同的支配级别。具体来说,第一级非支配前沿是所有未被任何其他解支配的解的集合。之后的每个级别是在其前一级别被支配的解的集合。
### 2.2.2 密度估计与拥挤距离的概念
拥挤距离是在非支配解的基础上定义的,用于度量解在其邻域中的拥挤程度。在NSGA-II中,拥挤距离用于保持种群的多样性,防止算法过早地收敛到Pareto前沿的局部区域。拥挤距离越大,表明解在其邻域中越不拥挤,从而更有可能被选中进入下一代。
### 2.2.3 精英保留策略的影响
NSGA-II采用了精英保留策略,确保了优秀个体在遗传操作中的遗传。在新一代种群产生之前,当前种群中最好的个体被直接复制到下一代种群中。精英策略有助于保持算法的收敛性能,确保优秀基因不会在迭代过程中丢失。
## 2.3 NSGA-II算法的参数设置与调优
### 2.3.1 参数重要性与选择
NSGA-II算法中有几个关键参数,它们包括种群大小、交叉率、变异率等。这些参数对算法的性能有直接影响。合适的参数设置能够显著提高NSGA-II的优化效果和收敛速度。
### 2.3.2 参数调优方法与实践
参数调优通常需要根据具体问题的特点和经验进行。一些常用的参数调优方法包括自适应调整参数、使用参数优化算法(如网格搜索、随机搜索、贝叶斯优化等),以及结合实际问题进行启发式调整。在实践中,可能需要多次尝试和实验来找到最合适的参数组合。
为了更清晰地理解这些概念,下面提供一个简化的代码示例和对算法运行机制的说明。
```python
import numpy as np
# 简化的NSGA-II算法示例
def non支配_sorting(population, num_of_objectives):
# 按目标函数值进行排序
sorted_population = np.argsort(population, axis=0)
front = []
fronts = []
dominated = [False] * len(population)
for i in range(len(population)):
front.clear()
fronts.append(front)
for j in range(len(population)):
if all(dominated[j] or population[j] <= population[i] for j, dominated_j in enumerate(dominated)):
front.append(i)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 NSGA-II 多目标优化算法的权威指南!本专栏深入探讨了 NSGA-II 算法的各个方面,从基础概念到高级应用。通过一系列全面且易于理解的文章,您将掌握:
* NSGA-II 算法的 7 个基本概念和应用场景
* NSGA-II 的核心原理和 6 个关键步骤
* 从理论到实践的 NSGA-II 求解过程
* NSGA-II 与 Pareto 前沿的比较和最佳实践
* NSGA-II 参数调优的 5 大技巧
* NSGA-II 在工程设计、资源分配、环境科学、供应链管理、电力系统和生物信息学中的应用
* NSGA-II 的并行化处理策略
* NSGA-II 与其他多目标算法的优劣对比
* NSGA-II 多目标决策支持系统的集成
* NSGA-II 算法在不同领域的案例研究和效果评估
无论您是刚接触多目标优化的新手,还是经验丰富的从业者,本专栏都将为您提供全面的知识和实践指导,帮助您有效解决复杂的多目标优化问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CTS模型:从基础到高级,构建地表模拟的全过程详解

# 摘要
本文对CTS模型进行了全面介绍,从基础理论到实践操作再到高级应用进行了深入探讨。CTS模型作为一种重要的地表模拟工具,在地理信息系统(GIS)中有着广泛的应用。本文详细阐述了CTS模型的定义、组成、数学基础和关键算法,并对模型的建立、参数设定、迭代和收敛性分析等实践操作进行了具体说明。通过对实地调查数据和遥感数据的收集与处理,本文展示了模型在构建地表模拟时的步
【升级前必看】:Python 3.9.20的兼容性检查清单

# 摘要
Python 3.9.20版本的发布带来了多方面的更新,包括语法和标准库的改动以及对第三方库兼容性的挑战。本文旨在概述Python 3.9.20的版本特点,深入探讨其与既有代码的兼容性问题,并提供相应的测试策略和案例分析。文章还关注在兼容性升级过程中如何处理不兼容问题,并给出升级后的注意事项。最后,
【Phoenix WinNonlin数据可视化】:结果展示的最佳实践和技巧

# 摘要
本文旨在全面介绍Phoenix WinNonlin软件在数据可视化方面的应用,概念与界面功能概览,以及数据可视化技术的深入探讨。通过章节内容对软件界面的核心组件、功能操作流程进行解析,强调了数据图表化和高级数据处理技巧的重要性。实践案例分析
【Allegro脚本编程:自动化设计的终极指南】

# 摘要
Allegro脚本作为一种强大的自动化工具,广泛应用于电子设计自动化领域。本文从脚本的基础知识讲起,深入探讨了其语法、高级特性以及在实践中的具体应用,包括自动化流程设计、数据管理、交互式脚本编写。随后,文章详细介绍了脚本优化与调试技巧,以提升执行效率和故障处理能力。最后,文章探索了Allegro脚本在PCB设计自动化、IC封装设计等不同领域的
AnyLogic工作流与决策模拟:精通业务流程设计只需72小时
# 摘要
本文全面概述了业务流程模拟与决策分析的理论与实践,特别聚焦于AnyLogic软件的应用。首先,对AnyLogic的基础知识和界面布局进行了介绍,并探讨了创建新模拟项目的步骤。接着,文章深入探讨了业务流程模拟的理论基础和建模技术,以及如何通过流程图和模拟分析来支持决策。此外,还详细讲解了面向对象模拟方法在AnyLogic中的实现,构建高级决策模型的技巧,以及仿真实验的设计与结果分析。最后,文章探讨了AnyLogi
【网络性能调优实战】:ifconfig在加速Linux网络中的10大应用
# 摘要
本文全面介绍了网络性能调优的基础知识,并着重探讨了Linux系统中广泛使用的网络配置工具ifconfig在性能加速和优化配置中的关键应用。通过对网络接口参数的优化、流量控制与速率调整以及网络故障的诊断与监控,本文提供了一系列实用的ifconfig应用技巧。进一步,本文讨论了ifconfig的高级应用,包括虚拟网络接口配置、多网络环境性能优化和安全性能提升。最后,本文比较了i
CMW500-LTE自动化测试脚本编写:从零基础到实战,提升测试效率

# 摘要
随着移动通信技术的快速发展,CMW500-LTE作为一款先进的测试设备,在无线通信领域占据重要地位。本文系统性地介绍了CMW500-LTE的自动化测试方法,涵盖了测试概述、基础理论、实践操作、性能优化、实战案例以及未来展望。通过对CMW500-LTE设备和接口的介绍,自动化测试环境的搭建,测试脚本编写理论与实践的深入
S4 ABAP编程数据处理

# 摘要
本文对S4 ABAP编程进行了全面的介绍和分析,从基础的数据定义与类型到数据操作与处理,再到数据集成与分析,以及实际应用和性能调优。特别指出S4 ABAP在供应链管理和财务流程中数据处理的重要性,并提供了性能瓶颈诊断和错误处理的策略。文章还探讨了面向对象编程在ABAP中的应用和S4 ABAP的未来创新技术趋势,强调了HANA数据库和云平台对AB
【BK2433高级定时器应用宝典】:定时器配置与应用手到擒来

# 摘要
定时器技术是嵌入式系统和实时操作系统中的核心组件,本文首先介绍了定时器的基础配置和高级配置策略,包括精确度设置、中断管理以及节能模式的实现。随后,文中详细探讨了定时器在嵌入式系统中的应用场景,如实时操作系统中的多任务调度集成
Eclipse MS5145扫码枪维护必修课:预防常见问题
# 摘要
Eclipse MS5145扫码枪作为一款广泛使用的条码读取设备,在日常使用和维护中需要特别关注其性能和可靠性。本文系统地概述了Eclipse MS5145扫码枪的维护基础,并深入探讨了其硬件组成部分及其工作原理,包括传感器、光源、解码引擎,以及条码扫描和数据传输机制。同时,本文详细介绍了日常维护流程、故障诊断与预防措施,以及如何实施高级维护技术如性能测试
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )