【YOLOv8自定义数据集训练实战】:按照这些步骤,你也能成为专家
发布时间: 2024-12-11 21:09:25 阅读量: 5 订阅数: 16 

目标检测-使用Yolov5+Pytorch训练自己的数据集-超详细流程教程-优质项目实战.zip

# 1. YOLOv8介绍与安装
## YOLOv8简介
YOLO(You Only Look Once)是目标检测领域内广受欢迎的实时检测算法之一。YOLOv8作为该系列的最新成员,继承了YOLO家族快速准确的核心特点,同时引入了多项创新以适应更广泛的应用场景和提高模型性能。其优化的架构和改进的训练技巧,使得它在处理图像和视频流中的物体识别任务上,拥有超越前代的优势。
## 安装YOLOv8
安装YOLOv8的第一步是确保依赖环境准备就绪。YOLOv8兼容于Linux系统,推荐使用Python 3.6或更高版本,并且安装PyTorch深度学习框架。安装步骤如下:
1. 克隆YOLOv8仓库:
```bash
git clone https://github.com/ultralytics/yolov8
```
2. 创建并激活Python环境:
```bash
cd yolov8 && pip install -r requirements.txt
```
3. 下载预训练模型权重,以进行模型评估或微调:
```bash
python tools/download_weights.py
```
YOLOv8安装完成后,可进一步进行模型配置、训练和部署等操作。
> 注意:确保系统中已经安装了CUDA和cuDNN以支持GPU加速,若仅使用CPU进行操作,性能将显著下降。
# 2. 自定义数据集的准备与标注
### 2.1 数据集的收集与组织
#### 2.1.1 数据来源的选择和采集
在进行深度学习模型训练之前,获取充足且高质量的数据集是至关重要的一步。对于目标检测任务,我们需要收集并标注大量的图像样本,这些样本应覆盖我们模型需要识别的所有对象类别。
在选择数据来源时,首先需要明确我们的目标检测任务以及对应的场景。例如,如果我们的任务是监控视频中的人群异常行为检测,我们就需要收集来自不同监控摄像头的视频数据。这些数据可以是公开数据集、自录视频或者通过API获取的实时监控流。
数据采集的具体步骤如下:
1. **确定数据需求**:根据任务需求,明确需要识别的物体类别、场景类型以及数据集的最小规模。
2. **采集数据**:
- **公开数据集**:许多研究机构或公司会公开一些标注好的数据集,如COCO、ImageNet等,这些数据集可以作为起点,但可能需要根据自己的任务需求进一步扩展。
- **自录视频**:如果公开数据集不能满足需求,可以通过自己录制视频并截取帧图像来收集数据。使用高质量的摄像头可以提高数据质量。
- **网络爬虫**:对于互联网上的图像数据,可以通过编写爬虫程序来自动化地下载相关图像。需要确保遵守相关网站的使用条款,尊重版权和隐私权。
3. **数据存储**:采集到的数据需要有组织地存储,以便于后续处理和分析。可以使用数据库或文件夹结构来管理数据集。
#### 2.1.2 数据集的分类与命名规范
为了方便管理和使用,我们需要对收集的数据进行分类,并制定一套命名规范。
1. **分类原则**:根据目标物体的类别将图像分为多个子集,每个子集包含一种类别的图像。例如,若我们识别的类别包括“汽车”和“行人”,则需要建立“car”和“pedestrian”两个子集。
2. **命名规范**:每个图像的命名应反映其所属类别和采集信息,例如可以采用“类别_序号.扩展名”的命名方式,如“car_001.jpg”和“pedestrian_002.jpg”。
此外,为保持一致性,图像格式应统一为模型支持的格式,如JPEG或PNG。
### 2.2 数据集的标注工具使用
#### 2.2.1 标注工具的选择与安装
标注工作是将图像中目标物体的位置和类别信息标记出来,为模型训练提供监督信息。因此,选择一个合适的标注工具对于提高标注效率和准确性至关重要。
目前,市面上有许多标注工具可供选择,包括但不限于LabelImg、CVAT、LabelBox等。这些工具各有优劣,主要考虑因素包括:
- **易用性**:工具的用户界面是否友好,标注流程是否直观。
- **兼容性**:支持的文件格式是否满足需求,是否支持跨平台操作。
- **功能性**:是否支持批量操作,是否提供快捷键等辅助功能。
以LabelImg为例,这是一个常用的开源标注工具,支持图像标注并生成标注文件(如Pascal VOC或YOLO格式)。其安装步骤如下:
1. **安装依赖**:确保系统中已安装Python和pip。
2. **安装LabelImg**:通过pip安装LabelImg。
```bash
pip install labelImg
```
3. **运行LabelImg**:在命令行中输入`labelImg`启动工具。
#### 2.2.2 标注流程与技巧
标注流程主要包括以下几个步骤:
1. **加载图像**:打开LabelImg后,加载需要标注的图像。
2. **创建标注框**:使用工具提供的功能在目标物体周围绘制边界框,为每个目标物体创建一个标注框。
3. **设置类别和属性**:为标注框设置正确的类别标签。部分工具还允许设置物体的属性(如遮挡程度、姿态等)。
4. **保存标注**:完成一个图像的所有标注后,保存标注结果,通常会生成一个对应的标注文件。
标注技巧:
- **一致性**:确保在所有图像中对同一类别的物体使用相同的标注方式。
- **准确性**:尽可能精确地绘制边界框,避免漏标或错标。
- **高效性**:利用工具提供的快捷键和批量处理功能,提高标注效率。
### 2.3 数据集的质量控制
#### 2.3.1 数据不平衡处理
在实际的图像数据集中,经常会遇到不同类别物体的数量不均衡的情况。这种不平衡会影响模型的训练效果,可能导致模型对某些类别过拟合,而对稀有类别表现不佳。
为了解决数据不平衡问题,可以采取以下策略:
1. **重采样**:对数据集中的类别进行重采样,增加稀有类别的样本数量,可以通过过采样(重复使用已有样本)或欠采样(减少多数类样本)的方法实现。
2. **合成新样本**:对于稀有类别,可以使用数据增强方法生成新的合成样本,如图像旋转、裁剪、颜色变换等。
3. **类别权重调整**:在模型训练时,对不同类别的样本赋予不同的权重,给予稀有类别更高的权重。
#### 2.3.2 数据增强策略
数据增强是通过应用一系列转换(如旋转、缩放、剪切、颜色变化等)来人为增加数据多样性的一种技术。这有助于提高模型的泛化能力,并减少过拟合的风险。
常用的图像增强策略包括:
- **几何变换**:如旋转、缩放、平移等。
- **颜色变换**:如改变亮度、对比度、饱和度、色调等。
- **噪声注入**:如添加高斯噪声或椒盐噪声。
- **随机裁剪**:随机选择图像的一部分作为新的训练样本。
这些增强操作可以在训练前或训练过程中动态执行。例如,可以将数据增强操作集成到数据加载器中,每次迭代时随机选择一组变换来增强图像。
通过合理的数据增强策略,可以在不增加实际数据采集成本的情况下,有效提升模型性能。
# 3. YOLOv8模型的配置与训练
随着深度学习技术的飞速发展,YOLOv8作为该领域最新的目标检测模型之一,其训练过程显得尤为重要。本章将详细介绍YOLOv8模型的配置与训练步

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在全面提升 YOLOv8 模型的精度。从基础到高级技巧,涵盖模型调优、训练策略、正则化技术、迁移学习、模型评估、超参数调优、后处理技巧和自定义数据集训练。通过这些实用技巧,读者可以一步到位掌握提升 YOLOv8 模型精度的方法,包括防止过拟合、提高泛化能力、优化训练速度、提升检测准确性等。此外,专栏还对比了 YOLOv8 与传统检测算法的优势和局限,帮助读者深入了解 YOLOv8 的特点。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GT-POWER网格划分技术提升:模型精度与计算效率的双重突破

参考资源链接:[GT-POWER基础培训手册](https://wenku.csdn.net/doc/64a2bf007ad1c22e79951b5
【MAC版SAP GUI快捷键大全】:提升工作效率的黄金操作秘籍

参考资源链接:[MAC版SAP GUI快速安装与配置指南](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a168?spm=1055.2635.3001.10343)
# 1. MAC版SAP GUI简介与安装
## 简介
SAP GUI(Graphical User Interface)是访问SAP系统
【隧道设计必修课】:FLAC3D网格划分与本构模型选择实用技巧
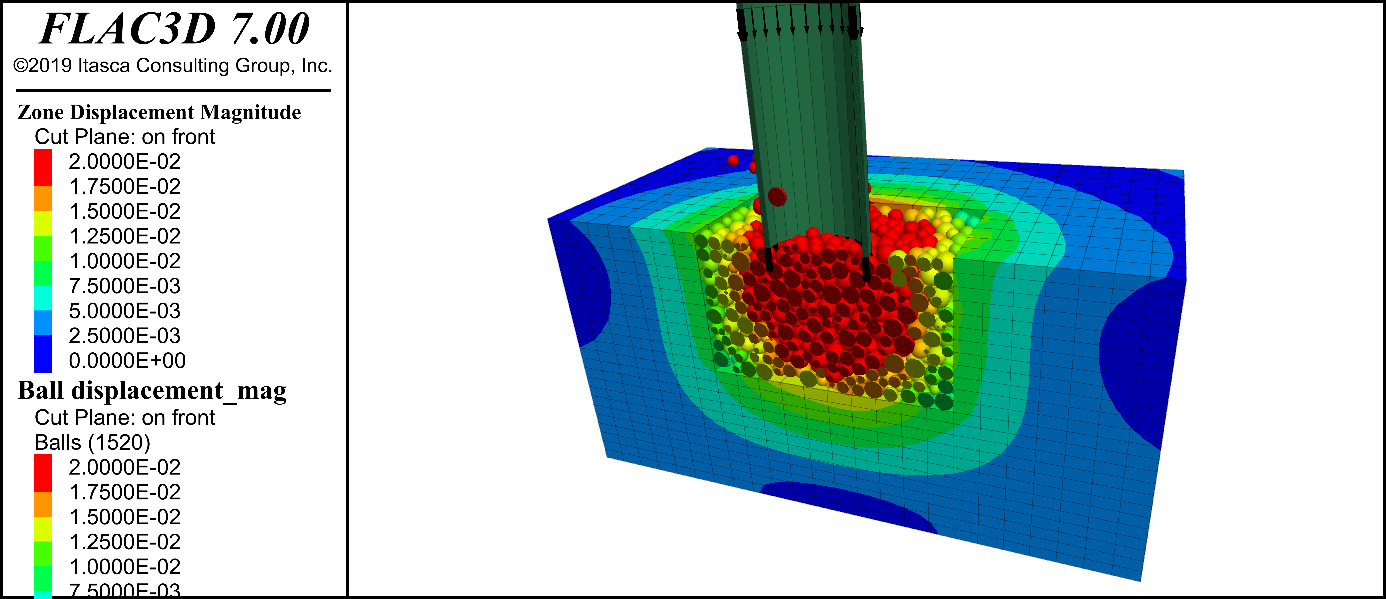
参考资源链接:[FLac3D计算隧道作业](https://wenku.csdn.net/doc/6412b770be7fbd1778d4a4c3?spm=1055.2635.3001.10343)
# 1. FLAC3D简介与应用基础
在本章中,我们将为您介绍FLAC3D(Fast Lagrangian Analysis of Continua in 3 Dimensions)的基础知识以及如何在工程
【故障诊断】:扭矩控制常见问题的西门子1200V90解决方案

参考资源链接:[西门子V90PN伺服驱动参数读写教程](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a36a?spm=1055.2635.3001.10343)
# 1. 扭矩控制概念与西门子1200V90介绍
在自动化与精密工程领域中,扭矩控制是实现设备精确
【Android设备安全必备】:Unknown PIN问题的彻底解决方案
参考资源链接:[unknow PIn解决方案](https://wenku.csdn.net/doc/6412b731be7fbd1778d496d4?spm=1055.2635.3001.10343)
# 1. Unknown PIN问题概述
## 1.1 问题的定义与重要性
Unknown PIN问题通常指用户在忘记或错误输入设备_PIN码后,导致设备锁定,无
【启动速度翻倍】:提升Java EXE应用性能的10大技巧
参考资源链接:[Launch4j教程:JAR转EXE全攻略](https://wenku.csdn.net/doc/6401aca7cce7214c316eca53?spm=1055.2635.3001.10343)
# 1. Java EXE应用性能概述
Java作为广泛使用的编程语言,其应用程序的性能直接影响用户体验和系统的稳定性。Java EXE应用是指那些通过特定打包工具(如Launc
Python Requests高级技巧大揭秘:动态请求头与Cookies管理

参考资源链接:[python requests官方中文文档( 高级用法 Requests 2.18.1 文档 )](https://wenku.csdn.net/doc/646c55d4543f844488d076df?spm=1055.2635.3001.10343)
# 1. 动态请求头与Cookies管理基础
## 1.1 互联网通信
iOS实时视频流传输秘籍:构建无延迟的直播系统
参考资源链接:[iOS平台视频监控软件设计与实现——基于rtsp ffmpeg](https://wenku.csdn.net/doc/4tm4tt24ck?spm=1055.2635.3001.10343)
# 1. 实时视频流传输基础
## 1.1 视频流传输的核心概念
- 视频流传输是构建实时直播系统的核心技术之一,涉及到对视频数据的捕捉、压缩、传输和解码等环节。掌握这些基本概念对于实现高质量
【绘制软件大比拼】:AutoCAD与其它工具在平断面图中的真实对决

参考资源链接:[输电线路设计必备:平断面图详解与应用](https://wenku.csdn.net/doc/6dfbvqeah6?spm=1055.2635.3001.10343)
# 1. 绘制软件大比拼概览
绘制软件领域竞争激烈,为满足不同用户的需求,各种工具应运而生。本章将为读者提供一个概览,介绍市场上流行的几款绘制软件及其主要功能,帮助您快速了解每款软件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )