YOLO训练集标注规范全解析:确保高质量数据标注
发布时间: 2024-08-17 05:27:15 阅读量: 130 订阅数: 22 

基于springboot的酒店管理系统源码(java毕业设计完整源码+LW).zip

# 1. YOLO训练集标注规范概述
YOLO(You Only Look Once)是一种实时目标检测算法,其训练集的标注规范对模型的性能至关重要。本章概述了YOLO训练集标注规范,包括其目的、重要性和遵循规范的必要性。
# 2. YOLO训练集标注理论基础
### 2.1 YOLO模型的原理和特点
YOLO(You Only Look Once)是一种实时目标检测算法,其特点是将目标检测任务转化为单次卷积神经网络(CNN)预测问题。与传统的目标检测算法(如R-CNN系列)需要生成候选区域并逐个进行分类不同,YOLO直接在输入图像上进行预测,一次性输出目标的位置和类别。
YOLO模型的网络结构通常分为两部分:
- **特征提取网络:**用于提取图像中的特征信息,通常采用预训练的CNN模型,如VGGNet、ResNet等。
- **检测网络:**负责将特征信息转换为目标检测结果,包括目标位置和类别预测。
YOLO模型的特点包括:
- **速度快:**由于采用单次预测,YOLO模型的检测速度非常快,可以达到实时检测水平。
- **精度高:**尽管速度快,但YOLO模型的检测精度也相当高,在目标检测领域具有领先地位。
- **泛化性强:**YOLO模型可以在各种场景和数据集上进行训练和部署,具有较强的泛化能力。
### 2.2 标注规范对模型训练的影响
标注规范对YOLO模型的训练影响至关重要。高质量的标注数据可以提高模型的检测精度和泛化能力,而低质量的标注数据则会导致模型性能下降。
标注规范主要包括以下几个方面:
- **标注精度:**目标位置和尺寸的标注必须准确,否则会影响模型对目标的检测和定位。
- **标注一致性:**不同的标注人员应遵循相同的标注规则,确保标注结果的一致性。
- **标注完整性:**标注数据应包含所有目标,包括小目标和遮挡目标,以避免模型训练时的偏差。
- **标注属性:**除了目标位置和尺寸外,还应标注目标的类别、姿态、遮挡程度等属性,以丰富模型的训练数据。
高质量的标注规范可以确保模型训练数据的准确性和一致性,从而提高模型的检测性能。
# 3. YOLO训练集标注实践指南
### 3.1 标注工具的选择和使用
选择合适的标注工具对于高效和准确的标注至关重要。以下是一些常用的标注工具:
- **LabelImg:**一款开源的图像标注工具,易于使用,支持多种标注类型。
- **CVAT:**一款基于浏览器的标注工具,提供丰富的标注功能,支持协作标注。
- **VGG Image Annotator:**一款基于Web的标注工具,具有直观的界面和强大的标注功能。
在选择标注工具时,应考虑以下因素:
- **标注类型:**工具是否支持所需的标注类型,如边界框、多边形、分割等。
- **易用性:**工具的界面是否直观,操作是否方便。
- **协作功能:**如果需要协作标注,工具是否支持多人同时标注。
### 3.2 标注流程和注意事项
YOLO训练集标注流程主要分为以下几个步骤:
#### 3.2.1 图像预处理
在标注之前,需要对图像进行预处理,以提高标注效率和准确性。预处理步骤包括:
- **图像缩放:**将图像缩放至合适的尺寸,以适应标注工具。
- **图像增强:**对图像进行增强,如调整对比度、亮度等,以提高目标的可见性。
- **图像分割:**将图像分割成多个子区域,以提高标注效率。
#### 3.2.2 物体标注
物体标注是YOLO训练集标注的核心步骤。标注时应注意以下事项:
- **标注准确性:**确保标注框与目标的边界紧密贴合。
- **标注一致性:**不同标注员标注同一目标时,应保持一致的标准。
- **标注全面性:**标注所有可见的目标,包括部分遮挡的目标。
#### 3.2.3 标注属性
除了标注目标的边界框外,还需标注目标的属性,如类别、大小、姿态等。属性标注有助于模型更好地理解目标的特征。
**代码块:**
```python
import cv2
import numpy as np
# 加载图像
image = cv2.imread('image.jpg')
# 图像缩放
scaled_image = cv2.resize(image, (640, 480))
# 图像增强
enhanced_image = cv2.equalizeHist(scaled_image)
# 图像分割
segmented_image = cv2.watershed(enhanced_image)
# 物体标注
bounding_boxes = []
for i in range(len(segmented_image)):
for j in range(len(segmented_image[0])):
if segmented_image[i][j] > 0:
x, y, w, h = cv2.boundingRect(segmented_image[i][j])
bounding_boxes.append([x, y, w, h])
# 标注属性
attributes = []
for bounding_box in bounding_boxes:
attributes.append(['car', 1.0, 'frontal'])
# 保存标注结果
np.save('annotations.npy', np.array(bounding_boxes))
np.save('attributes.npy', np.array(attributes))
```
**代码逻辑分析:**
该代码实现了YOLO训练集图像的预处理、物体标注和属性标注。具体逻辑如下:
- 加载图像并进行缩放和增强。
- 使用分水岭算法分割图像。
- 遍历分割后的图像,标注每个目标的边界框。
- 为每个目标标注属性,包括类别、置信度和姿态。
- 将标注结果保存为NumPy数组。
**参数说明:**
- `image`:输入图像。
- `scaled_image`:缩放后的图像。
- `enhanced_image`:增强后的图像。
- `segmented_image`:分割后的图像。
- `bounding_boxes`:目标的边界框列表。
- `attributes`:目标的属性列表。
# 4. YOLO训练集标注质量评估
### 4.1 标注质量评估指标
标注质量评估是确保训练集质量的关键步骤。以下是一些常用的标注质量评估指标:
- **准确率(Precision):**标注的边界框与真实边界框重叠面积与标注边界框面积的比值。
- **召回率(Recall):**标注的边界框与真实边界框重叠面积与真实边界框面积的比值。
- **F1得分:**准确率和召回率的调和平均值。
- **平均交并比(mAP):**在不同IoU阈值下的平均准确率。
- **IoU(交并比):**标注的边界框与真实边界框重叠面积与两者并集面积的比值。
### 4.2 标注质量评估方法
标注质量评估方法主要分为人工评估和自动评估两种。
#### 4.2.1 人工评估
人工评估是通过人工检查标注的边界框和属性是否准确。这种方法准确性高,但效率低,适用于小规模数据集。
#### 4.2.2 自动评估
自动评估是利用算法自动计算标注质量评估指标。这种方法效率高,但准确性略低于人工评估。
### 4.2.3 评估工具
常用的标注质量评估工具包括:
- **COCO评估工具:**用于评估COCO数据集的标注质量。
- **PASCAL VOC评估工具:**用于评估PASCAL VOC数据集的标注质量。
- **YOLO评估工具:**用于评估YOLO数据集的标注质量。
### 4.2.4 评估流程
标注质量评估流程通常包括以下步骤:
1. **收集标注数据:**收集需要评估的标注数据。
2. **选择评估指标:**根据评估目的选择合适的评估指标。
3. **使用评估工具:**使用评估工具计算评估指标。
4. **分析评估结果:**分析评估结果,找出标注质量存在的问题。
5. **优化标注流程:**根据评估结果优化标注流程,提高标注质量。
### 4.2.5 代码示例
```python
import numpy as np
import cv2
def calculate_iou(bbox1, bbox2):
"""计算两个边界框的IoU。
Args:
bbox1 (list): 第一个边界框[xmin, ymin, xmax, ymax]。
bbox2 (list): 第二个边界框[xmin, ymin, xmax, ymax]。
Returns:
float: IoU值。
"""
# 获取两个边界框的坐标
xmin1, ymin1, xmax1, ymax1 = bbox1
xmin2, ymin2, xmax2, ymax2 = bbox2
# 计算两个边界框的面积
area1 = (xmax1 - xmin1) * (ymax1 - ymin1)
area2 = (xmax2 - xmin2) * (ymax2 - ymin2)
# 计算两个边界框的重叠面积
xmin_inter = max(xmin1, xmin2)
ymin_inter = max(ymin1, ymin2)
xmax_inter = min(xmax1, xmax2)
ymax_inter = min(ymax1, ymax2)
area_inter = max(0, xmax_inter - xmin_inter) * max(0, ymax_inter - ymin_inter)
# 计算IoU
iou = area_inter / (area1 + area2 - area_inter)
return iou
def calculate_mAP(bboxes, labels, gt_bboxes, gt_labels, iou_thresholds=[0.5, 0.75]):
"""计算平均准确率(mAP)。
Args:
bboxes (list): 标注的边界框列表。
labels (list): 标注的类别标签列表。
gt_bboxes (list): 真实边界框列表。
gt_labels (list): 真实类别标签列表。
iou_thresholds (list): IoU阈值列表。
Returns:
float: mAP值。
"""
# 初始化mAP
mAP = 0
# 遍历IoU阈值
for iou_threshold in iou_thresholds:
# 初始化准确率列表
precisions = []
# 遍历真实边界框
for gt_bbox, gt_label in zip(gt_bboxes, gt_labels):
# 初始化匹配标志
matched = False
# 遍历标注的边界框
for bbox, label in zip(bboxes, labels):
# 计算IoU
iou = calculate_iou(bbox, gt_bbox)
# 如果IoU大于阈值,则匹配
if iou >= iou_threshold:
# 如果类别标签相同,则匹配成功
if label == gt_label:
matched = True
break
# 如果匹配成功,则计算准确率
if matched:
precisions.append(1)
else:
precisions.append(0)
# 计算平均准确率
mAP += np.mean(precisions)
# 返回mAP
return mAP / len(iou_thresholds)
```
# 5. YOLO训练集标注优化策略
### 5.1 标注数据扩充
**目的:**增加训练数据的多样性,增强模型的泛化能力。
**方法:**
- **随机裁剪:**将图像随机裁剪成不同大小和宽高比,以增加图像的尺寸和形状变化。
- **随机翻转:**将图像水平或垂直翻转,以增加图像的镜像变化。
- **随机旋转:**将图像随机旋转一定角度,以增加图像的旋转变化。
- **添加噪声:**向图像添加高斯噪声或椒盐噪声,以增加图像的噪声变化。
- **颜色抖动:**随机调整图像的亮度、对比度、饱和度和色相,以增加图像的颜色变化。
**代码示例:**
```python
import cv2
import numpy as np
# 随机裁剪
def random_crop(image, size):
h, w = image.shape[:2]
x = np.random.randint(0, w - size[0])
y = np.random.randint(0, h - size[1])
return image[y:y+size[1], x:x+size[0]]
# 随机翻转
def random_flip(image):
if np.random.rand() < 0.5:
return cv2.flip(image, 1) # 水平翻转
else:
return cv2.flip(image, 0) # 垂直翻转
# 随机旋转
def random_rotate(image):
angle = np.random.randint(-30, 30)
return cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE, angle)
# 添加噪声
def add_noise(image):
noise = np.random.normal(0, 10, image.shape)
return image + noise
# 颜色抖动
def color_jitter(image):
brightness = np.random.uniform(0.5, 1.5)
contrast = np.random.uniform(0.5, 1.5)
saturation = np.random.uniform(0.5, 1.5)
hue = np.random.uniform(-0.1, 0.1)
return cv2.cvtColor(image, cv2.COLOR_BGR2HSV) * np.array([brightness, contrast, saturation, hue])
```
### 5.2 标注数据清洗
**目的:**去除错误或不准确的标注,提高训练数据的质量。
**方法:**
- **人工审核:**由经验丰富的标注人员手动检查标注数据,识别并更正错误。
- **自动过滤:**使用算法或规则自动检测和过滤掉异常或不一致的标注。
**代码示例:**
```python
import pandas as pd
# 人工审核
def manual_review(annotations):
df = pd.DataFrame(annotations)
df['is_valid'] = df.apply(lambda row: row['label'] != 'None' and row['x'] >= 0 and row['y'] >= 0, axis=1)
return df[df['is_valid'] == True]
# 自动过滤
def auto_filter(annotations):
df = pd.DataFrame(annotations)
df = df[(df['width'] > 0) & (df['height'] > 0) & (df['x'] >= 0) & (df['y'] >= 0) & (df['x'] + df['width'] <= df['image_width']) & (df['y'] + df['height'] <= df['image_height'])]
return df
```
### 5.3 标注数据自动化
**目的:**使用自动化工具或算法减少人工标注的工作量。
**方法:**
- **半自动标注:**使用工具辅助标注人员进行标注,如自动生成边界框或分割掩码。
- **全自动标注:**使用算法自动生成标注,如目标检测算法或语义分割算法。
**代码示例:**
```python
import cv2
import numpy as np
# 半自动标注
def semi_auto_annotation(image):
# 使用算法生成边界框建议
boxes = cv2.selectROIs('Image', image, False, False)
# 标注人员微调边界框
for box in boxes:
x, y, w, h = box
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
return image
# 全自动标注
def auto_annotation(image):
# 使用目标检测算法生成边界框
model = cv2.dnn.readNetFromDarknet('yolov3.cfg', 'yolov3.weights')
blob = cv2.dnn.blobFromImage(image, 1/255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
model.setInput(blob)
detections = model.forward()
# 解析检测结果
boxes = []
for detection in detections[0, 0]:
if detection[5] > 0.5:
x, y, w, h = detection[0:4] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
boxes.append([int(x), int(y), int(w), int(h)])
return boxes
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“YOLO训练集格式解析”专栏,在这里,我们将深入探讨YOLO目标检测模型的训练集格式和构建策略。专栏涵盖广泛的主题,包括:
* 数据增强技术,以提高模型精度和泛化能力。
* 标注规范,确保高质量的数据标注。
* 常见问题解答,解决训练过程中的难题。
* 优化策略,提升训练效率和性能。
* 评估指标,全面评估模型训练效果。
* 生成工具推荐,高效构建高质量训练集。
* 数据集管理策略,组织和管理训练集。
* 版本更新速递,了解最新训练集格式和规范。
* 训练集与目标检测训练集的对比分析。
* 在不同场景中的应用指南。
* 训练集质量对模型性能的影响。
* 标注工具选用指南。
* 数据清洗实战和数据扩充秘籍。
* 训练集可视化探索和基准测试指南。
* 错误分析实战和性能优化技巧。
* 并行化秘籍,加速训练过程。
通过阅读本专栏,您将获得构建和管理高质量YOLO训练集所需的全面知识,从而提升模型精度、泛化能力和训练效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【工业相机镜头全攻略】:从选型到保养,一步到位掌握核心技术

# 摘要
工业相机镜头是机器视觉系统中至关重要的组成部分,本文首先介绍了工业相机镜头的基础知识,随后详细探讨了镜头选型的要点,包括镜头参数解析、类型与应用场景以及实践考量。文章还阐述了镜头的正确
【C语言学生成绩管理系统】:掌握编程技巧,提升数据分析效率(全套教程)

# 摘要
本文深入探讨了使用C语言开发的学生成绩管理系统的设计与实现。首先概述了系统的基本架构,随后详细介绍了C语言基础和数据结构在系统中的应用,包括结构体、数组、链表及函数等概念。文章进一步阐述了系统的核心功能,例如成绩的输入存储、查询修改以及统计分析,并解释了高级编程技巧和优化方法在提升系统性能中的重要性。最后,本文讨论了用户界面设计原则、系统测试及未来功能拓展的策略,强调了系统集
帧同步与频偏校正:通信系统可靠性的关键提升

# 摘要
本文系统性地介绍了帧同步与频偏校正的基础理论、技术分析、实践应用、联合优化策略、系统仿真与性能评估以及未来的发展趋势和挑战。首先,阐述了帧同步的基本概念、方法和状态机设计,随后对频偏产生的原理、影响以及校正技术进行了深入探讨。进一步,文章提出联合优化框架,并探讨了算法设计与实现细节,以及在通信系统中的应用效果。仿真与性能评估章节通
STEP7指针编程速成课程:掌握PLC地址引用至性能调优15大技巧

# 摘要
本文旨在深入探讨STEP7指针编程的基础知识和高级应用,同时详细解释了PLC内存地址结构及其在数据处理和故障诊断中的重要性。通过对指针操作、数据块应用、间接寻址技术以及性能调优技巧的讲解,本文为读者提供了提高PLC系统效率与稳定性的实用方法。案例分析部分通过实际场景加深理解,并总结了故障排除和复杂逻辑控制的实施经验。课程总结与未来展
BT201模块故障排查手册:音频和蓝牙连接问题的快速解决之道
# 摘要
BT201模块作为一种广泛应用的音频与蓝牙通信设备,其稳定性和故障排除对于用户体验至关重要。本文针对BT201模块的音频连接和蓝牙连接问题进行了系统性分析,包括理论基础、故障诊断与解决方法,并通过实际案例深入探讨了故障排查流程和预防维护策略。此外,文中还介绍了高级故障排查工具和技巧,旨在为技术人员提供全面的故障处理方案。通过对BT201模块故障的深入研究与实践案例分析,本文为未来的故障排查提供了经验总结和技术创新的展望。
# 关键字
音频连接;蓝牙连接;故障诊断;预防维护;故障排查工具;技术展望
参考资源链接:[BT201蓝牙模块用户手册:串口控制与音频BLE/SPP透传](ht
提升无线通信:nRF2401跳频协议的信号处理技术优化指南
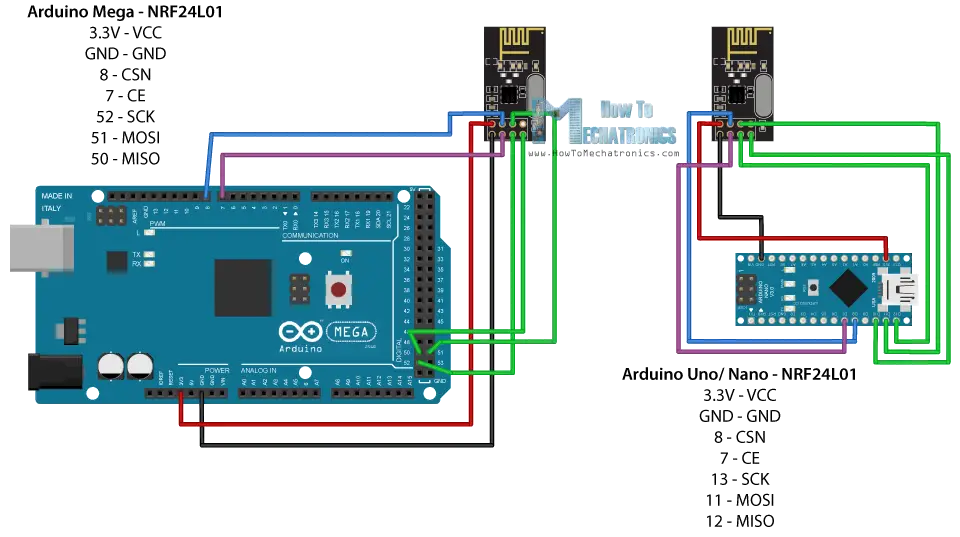
# 摘要
nRF2401跳频协议是无线通信领域的关键技术,本文首先概述了该协议的基本原理和应用场景。随后,深入探讨了信号处理的基础理论,包括跳频技术的工作原理、信号处理的数学模型以及噪声与干扰的影响分析。文章第三部分重点关注了nRF2401协议在信号处理实践中的策略,如发射端与接收端的处理方法,以及信号质量的检
【新手必学】:Protel 99se PCB设计,BOM导出从入门到精通
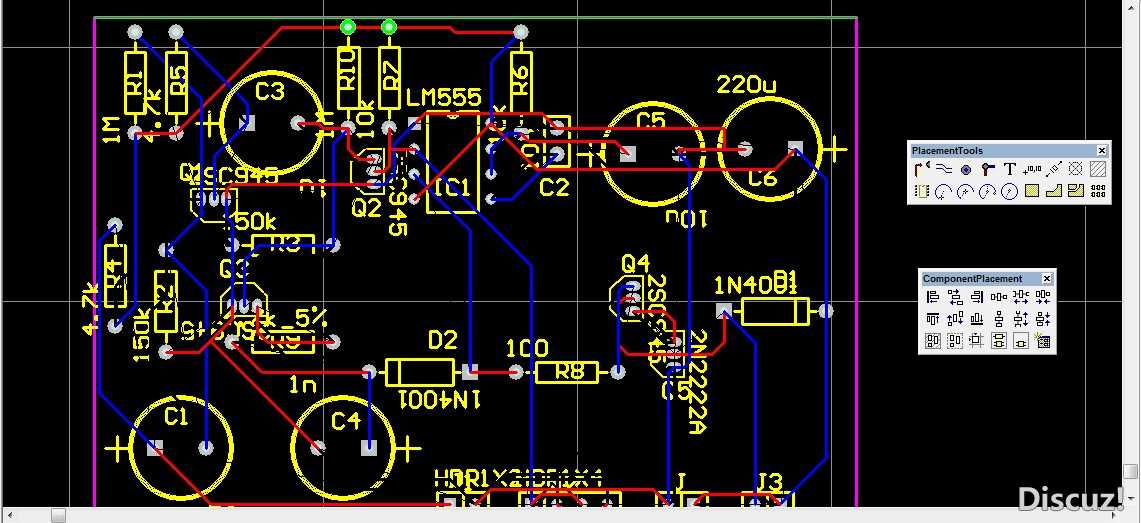
# 摘要
本文旨在详细介绍Protel 99se在PCB设计中的应用基础,深入探讨物料清单(BOM)与PCB设计的紧密关系及其导出流程。通过阐述BOM的作用、分类和在设计数据关联中的重要性,本文提供了PCB设计实践操作的指导,包括前期准备、原理图绘制、PCB布局生成以及BOM导出。同时,文章还讨论了BOM导出的高级技巧与优化,以及BOM在PC
【多相流仿真高级解析】:ANSYS CFX多相流模型的6大应用场景

# 摘要
多相流仿真在工程和科学领域中具有重要的应用价值,特别是在复杂的化工、生物反应器和矿物输送等场景。本文首先概述了多相流仿真及其重要性,并详细介绍了ANSYS CFX多相流模型的基础理论和设置方法。通过具体案例实践,如气液两相流、固液两相流和多组分混合过程的仿真,本文展示了多相流仿真的实际应用。此外,本文还探讨了高级应用,例如液滴与颗粒运动
医疗数据标准化实战:7中心系统接口数据结构深度解析

# 摘要
医疗数据标准化是提高医疗信息系统互操作性和数据质量的关键,本文深入探讨了医疗数据接口标准的理论基础、数据结构设计、实现技术及挑战对策。文章从接口标准的定义、
数据流图在业务流程改进中的7大作用与案例

# 摘要
数据流图
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )