利用pandas进行高级数据转换与处理
发布时间: 2024-04-17 07:00:46 阅读量: 77 订阅数: 30 
# 1.1 什么是pandas库?
pandas库是一个开源的数据分析工具,基于NumPy构建,提供了高效的数据结构和数据分析工具,使数据处理变得更加简单和快速。pandas库主要包含两种数据结构:Series(一维数组)和DataFrame(二维表格),能处理各种类型的数据,包括时间序列数据等。其优势在于灵活的数据处理能力和丰富的数据操作函数,使得数据清洗、转换、分析变得更加高效。在数据处理中,pandas库被广泛应用于数据导入导出、数据清洗与处理、数据筛选与排序等方面,为数据分析工作提供了强大的支持。
pandas库的出现填补了Python在数据处理领域的空白,成为数据科学家和分析师们首选的数据处理工具之一。
# 2. 基本数据处理操作
2.1 数据读取与查看
#### 2.1.1 读取csv文件
读取数据是数据处理的第一步,pandas库提供了`pd.read_csv()`函数来读取csv文件。通过指定文件路径参数,我们可以将csv文件中的数据加载到DataFrame中进行后续处理。
```python
import pandas as pd
# 读取csv文件
df = pd.read_csv('data.csv')
```
#### 2.1.2 查看数据的基本信息
要查看数据的基本信息,可以使用`df.info()`方法。这将显示数据框的行数、列数,每列的名称和非空值数量,以及每列的数据类型。
```python
# 查看数据的基本信息
df.info()
```
#### 2.1.3 使用head和tail方法预览数据
`df.head()`和`df.tail()`方法可以用来查看数据框的前几行和最后几行数据。默认情况下,它们会显示前5行数据,但你也可以指定显示的行数。
```python
# 查看数据的前5行
df.head()
# 查看数据的后5行
df.tail()
```
2.2 数据清洗与处理
#### 2.2.1 处理缺失值
缺失值是数据处理中常见的问题。使用`df.isnull().sum()`可以查看每列缺失值的数量,而`df.dropna()`或`df.fillna()`可以处理缺失值的方法。
```python
# 查看缺失值数量
df.isnull().sum()
# 删除包含缺失值的行
df.dropna()
# 使用均值填充缺失值
df.fillna(df.mean())
```
#### 2.2.2 删除重复数据
重复数据可能会导致分析结果不准确,可以使用`df.duplicated()`和`df.drop_duplicates()`来检测和删除重复数据。
```python
# 检测重复数据
df.duplicated()
# 删除重复数据
df.drop_duplicates()
```
#### 2.2.3 数据类型转换
数据类型转换是数据清洗的关键步骤之一。可以使用`df.astype()`方法将某列数据转换为指定数据类型,比如将字符串类型转换为数值类型。
```python
# 将字符串列转换为数值列
df['column_name'] = df['column_name'].astype(float)
```
2.3 数据筛选与排序
#### 2.3.1 使用条件筛选数据
通过条件筛选可以轻松筛选出符合特定条件的数据行,使用布尔索引来实现条件筛选。
```python
# 筛选出满足条件的数据
df_filtered = df[df['column_name'] > 10]
```
#### 2.3.2 对数据进行排序
对数据进行排序有助于更好地观察数据的规律。可以使用`df.sort_values()`方法按指定列对数据进行排序。
```python
# 对数据按照某列排序
df_sorted = df.sort_values('column_name')
```
#### 2.3.3 利用apply函数处理数据
`df.apply()`方法可以对数据框中的行或列应用指定的函数,实现对数据的批量处理。
```python
# 对某列数据应用自定义函数
def custom_function(x):
return x*2
df['new_column'] = df['column_name'].apply(custom_function)
```
这些基本的数据处理操作将为我们后续更深入和复杂的数据处理技巧奠定基础。
# 3.1 数据合并与拼接
数据合并是处理多个数据集的常见操作,能够将不同数据源中的相关数据整合在一起,为后续数据分析提供便利。
#### 3.1.1 使用concat方法进行数据合并
在 pandas 中,可以使用 concat 方法按指定轴将多个 DataFrame 连接在一起,轴参数 axis=0 表示沿着行的方向进行连接,axis=1 表示沿着列的方向进行连接。
```python
import pandas as pd
data1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
data2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
result = pd.concat(
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了使用 Python Pandas 库读取、写入和处理 XLSX 文件的最佳实践和故障排除技巧。它从安装库的基本知识开始,然后深入探讨了读取和写入 Excel 文件的不同方法,包括处理缺失值、筛选和排序数据,以及数据清洗和预处理。此外,该专栏还涵盖了数据统计分析、数据合并和连接、数据透视和透视表分析、时间序列分析、高级数据分组和聚合、数据可视化以及优化 Pandas 性能的技巧。它还提供了处理异常值、重复数据和跨表格数据关联的详细指南。通过遵循本专栏中的步骤,用户可以掌握 Pandas 库,有效地管理和分析 XLSX 文件中的数据。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MySQL窗函数详解:理解窗函数的原理和使用,实现复杂数据分析

# 1. MySQL窗函数概述**
窗函数是一种特殊的聚合函数,它可以对一组数据进行计算,并返回每个数据行的计算结果。窗函数与传统的聚合函数不同,它可以在一组数据内对数据进行分组、排序和移动,从而实现更复杂的数据分析。
窗函数在MySQL中主要用于
数据转JSON最佳实践:业界经验分享,提升转换质量,打造高效数据处理流程
# 1. 数据转JSON基础**
数据转换至JSON(JavaScript Object Notation)是一种广泛应用于数据交换和存储的常用技术。JSON是一种轻量级、基于文本的数据格式,具有易于解析和处理的特点。
数据转JSON的基本过程涉及将数据从其原始格式(如CSV、XML或关系型数据库)转换为JSON格式。此过程通常包括以下步骤:
- **数据提取:**从原始
PHP数据库查询中的字符集和排序规则:处理多语言和特殊字符,提升数据兼容性
# 1. PHP数据库查询中的字符集和排序规则概述
在PHP数据库查询中,字符集和排序规则是两个重要的概念,它们决定了数据在数据库中的存储和检索方式。字符集定义了数据中使用的字符集,而排序规则则决定了数据在排序和比较时的顺序。
字符集和排序规则对于多语言数据处理、特殊字符处理和数据兼容性至关重要。了解和正确使用字符集和排序规则可以确保数据准
MySQL云平台部署指南:弹性扩展与成本优化,轻松上云

# 1. MySQL云平台部署概述**
MySQL云平台部署是一种将MySQL数据库部署在云计算平台上的方式,它提供了弹性扩展、成本优化和高可用性等优势。
云平台部署可以根据业务需求进行灵活扩展,自动伸缩机制可以根据负载情况自动调整数据库资源,实现弹性伸缩。同时,云平台提供了多种存储类型
MySQL JSON数据在金融科技中的应用:支持复杂数据分析和决策,赋能金融科技创新
# 1. MySQL JSON数据简介
JSON(JavaScript Object Notation)是一种轻量级数据交换格式,广泛用于金融科技领域。它是一种基于文本的数据格式,用于表示复杂的数据结构,如对象、数组和键值对。MySQL支持JSON数据类型,允许用户存储和处理JSON数据。
MySQL JSON数据类型提供了丰富的功能,包括:
- **JSONPath查询和过滤:*
MySQL排序规则与事务:事务中排序规则的应用和影响
# 1. MySQL排序规则概述**
MySQL的排序规则定义了数据排序的顺序。它决定了如何比较和排序不同类型的数据,包括数字、字符串、日期和时间
MySQL数据库连接池扩展:满足高并发需求

# 1. MySQL数据库连接池概述**
连接池是一种软件组件,它管理数据库连接的集合,以提高应用程序的性能和可扩展性。通过使用连接池,应用程序可以避免每次与数据库交互时创建和销毁连接的开销。
连接池主要用于高并发环境,其中应用程序需要频繁地与数据库交互。它通过预先创建和维护一定数量的数据库连接来优化数据库访问,从而减少连接
揭秘MySQL数据库删除过程:深入理解删除机制,掌握安全删除技巧
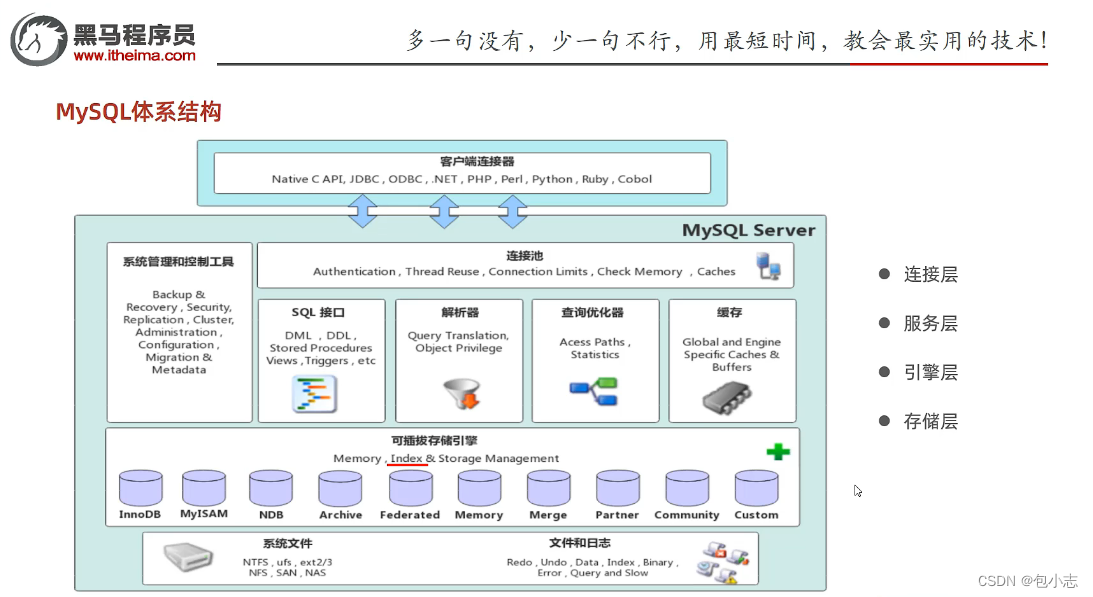
# 1. MySQL数据库删除机制概述
MySQL数据库中的删除操作是一种用于从表中移除数据的操作。它是一种不可逆的操作,因此在执行删除操作之前必须仔细考虑。MySQL提供了多种删除操作,包括:
* `DELETE` 语句:用于删除表中满足指定条件的行。
* `TRUNCATE TABLE` 语句:用于快速删除表中的所有行,比 `DELETE` 语句更快,但不能用于有外键约束的表。
* `DROP TABLE` 语句:用于删除整个表,包
MySQL数据库压缩与数据可用性:分析压缩对数据可用性的影响
# 1. MySQL数据库压缩概述**
MySQL数据库压缩是一种技术,通过减少数据在存储和传输过程中的大小,从而优化数据库性能。压缩可以提高查询速度、减少存储空间和降低网络带宽消耗。MySQL提供多种压缩技术,包括行级压缩和页级压缩,适用于不同的数据类型和查询模式。
MySQL数据库可视化在数据库性能优化中的4个应用
# 1. MySQL数据库可视化概述
数据库可视化是一种通过图形化界面展示数据库信息的技术,它可以帮助数据库管理员和开发人员更直观地理解数据库结构、性能和数据分布。MySQL数据库可视化工具可以提供多种功能,例如数据库结构图、表关系图、慢查询分析和资源使用情况监控。
MySQL数据库可视化的好处包括:
- **提高理解力:**图形化界面可以帮助用户更轻松地理解复杂的数据结构和关系。
-
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )