【Java Locale类深度剖析】:掌握国际化编程的核心技巧与优化秘籍
发布时间: 2024-10-21 00:03:38 阅读量: 54 订阅数: 21 

java+sql server项目之科帮网计算机配件报价系统源代码.zip

# 1. Java Locale类入门知识
Java Locale类是国际化编程的基础,它代表一个特定的地理、政治或文化地区。对于开发者而言,了解Locale类是实现多语言支持和文化敏感功能的第一步。本章节将介绍Locale类的基本概念和如何在Java中创建和使用Locale对象。
## 1.1 Locale类的基本概念
Locale类位于java.util包中,用于表示特定的地理、政治和文化区域。在处理语言相关数据时,如日期、时间、数字和货币格式,正确使用Locale类可以确保这些信息按照目标文化环境的约定正确显示。例如,同一数字在不同的Locale中可能有不同的千位分隔符和小数点表示。
## 1.2 创建Locale对象
创建一个Locale对象非常简单。可以使用构造函数传入语言代码、国家代码和可选的变体代码,也可以使用预定义的常量来获取标准的Locale实例。以下是一个简单的示例代码:
```java
Locale defaultLocale = Locale.getDefault(); // 获取系统默认Locale
Locale usLocale = new Locale("en", "US"); // 创建代表美国英语的Locale
Locale franceLocale = Locale.FRANCE; // 获取预定义的法国Locale实例
```
## 1.3 Locale类的使用场景
Locale类在Java中的使用非常广泛,尤其是在处理国际化文本时。它被用于设置区域相关的日期、时间和数字格式器。例如,如果我们希望在Java程序中打印出货币值,我们需要使用Locale类来定义货币值应当以哪种格式显示,比如美元应该使用逗号作为千位分隔符,而欧元则使用点。
通过本章内容,我们对Locale类有了基本的认识,接下来将深入探讨Locale类的内部机制和如何在复杂场景下正确应用Locale类。
# 2. 深入理解Locale类的内部机制
### 2.1 Locale类的数据结构分析
#### 2.1.1 Locale类的构造方法和常用实例
在Java编程中,`Locale`类被用来表示特定的地理、政治或文化地区。为了实现这一目的,`Locale`类提供了多种构造方法,允许开发者以不同的方式创建地区实例。
最直接的构造方法是使用`Locale(String language)`。此构造函数接受一个标准的ISO 639语言代码作为参数,这可以是一个小写或大写的双字母语言代码(如"en"表示英语),或者是三字母代码(如"eng"表示英语)。例如:
```java
Locale enLocale = new Locale("en");
```
同时,`Locale`类还支持更细粒度的地区标识,比如`Locale(String language, String country)`,在这里`language`参数遵循上述的语言代码规范,`country`参数遵循ISO 3166国家代码标准。例如:
```java
Locale enUSLocale = new Locale("en", "US");
```
还有`Locale(String language, String country, String variant)`构造函数,它允许指定一个变体值,该变体值可以用来指定语言的某个变种,比如特定的方言或者类型。例如:
```java
Locale enUSVariantLocale = new Locale("en", "US", "Omitting_Punctuation");
```
#### 2.1.2 Locale类的内部存储和比较机制
内部存储方面,`Locale`类使用私有字段来存储语言、国家和变体信息。这些字段可以是`languageTag`的一个子集,`languageTag`是一个遵循RFC 5646的完整语言标签字符串,例如`en-Latn-US`。
比较机制方面,`Locale`类提供`getDisplayName(Locale inLocale)`方法来获取地区名称的显示版本,这通常是在给定的`inLocale`语境下最合适的本地化名称。此外,`Locale`类中的`equals`, `hashCode`, 和`compare`方法依赖于`languageTag`的值进行比较,确保了地区比较的一致性和正确性。
### 2.2 Locale类与国际化标准的关系
#### 2.2.1 RFC 4646语言标签的构成
RFC 4646定义了语言标签的构成规则,它是一个用来标识语言的标准化字符串。语言标签由一个或多个子标签组成,用来表示语言、脚本、地区、变体、扩展和私有使用子标签等,如`zh-Hans-CN`表示简体中文在中国的使用。一个语言标签的构成通常如下:
- 语言部分:这是语言标签的核心,通常是两个小写字母(ISO 639-1)或三个字母(ISO 639-2/T)。
- 脚本部分:可选,大写字母加上四个小写字母,如`Hans`表示简体中文。
- 地区部分:可选,表示国家或地理区域,由两个大写字母(ISO 3166-1 alpha-2)或三个数字(ISO 3166-1 alpha-3)组成。
- 变体部分:可选,是区分语言使用变体的标识符,如`POSIX`。
`Locale`类遵循这些规则,使得开发者可以创建符合标准的地区实例,并能与其他遵循标准的应用程序和库进行互操作。
#### 2.2.2 Locale类在国际化中的作用和限制
`Locale`类作为Java国际化基础的一部分,扮演着非常关键的角色。它能够协助确定:
- 日期、时间和数字的格式化规则。
- 文本的排序规则。
- 文化相关的元素,如货币、日历系统等。
然而,`Locale`类也有它的局限性。由于语言和地区非常多样,`Locale`提供的地区代码集并不能覆盖所有的地区差异和方言。这就需要开发者在处理某些特定地区时,可能会需要扩展`Locale`类或寻找其他替代方案。
### 2.3 Locale类的最佳实践和案例分析
#### 2.3.1 实例解析:如何为应用选择合适的Locale
在为应用选择合适的`Locale`实例时,一般会考虑用户的系统设置、应用配置以及用户的偏好设置。一个常见做法是先获取用户的默认`Locale`:
```java
Locale userLocale = Locale.getDefault();
```
然后根据业务需求进行检查,可能需要覆盖默认设置,比如提供一个设置界面让用户选择他们的首选语言。根据用户选择或配置文件,应用应能够使用相应的`Locale`实例进行初始化:
```java
Locale appLocale = new Locale("fr", "CA"); // 设置为加拿大法语
```
#### 2.3.2 案例研究:跨语言环境下的数据格式化问题
在跨语言环境的数据格式化中,需要特别注意日期、时间和数字的处理。不同地区对日期和时间格式有不同的要求。例如,在美国,日期通常表示为月/日/年,而大多数欧洲国家使用日/月/年的格式。
```java
// 示例:美国地区使用MM/dd/yyyy格式
SimpleDateFormat dateFormatInUS = new SimpleDateFormat("MM/dd/yyyy", Locale.US);
```
而在数字和货币格式化方面,不同的地区可能有不同的千位分隔符和小数点符号。使用正确的`Locale`是避免这些常见问题的关键。
```java
NumberFormat currencyFormat = NumberFormat.getCurrencyInstance(Locale.US);
```
在处理这些数据格式化问题时,最佳实践是尽可能使用`Locale`相关的API,并确保你的应用可以处理用户设置的不同`Locale`实例。这样可以提高用户体验,同时避免数据格式错误导致的潜在问题。
# 3. Java Locale类在国际化编程中的应用
国际化编程是指创建能够适应不同地区、语言和文化背景的软件应用。在Java中, Locale类是用来实现国际化编程的一个重要工具。它提供了大量的数据和方法,帮助开发者处理不同地区的日期、时间、数字和货币等信息。
## 3.1 Locale类与日期时间格式化
### 3.1.1 时区和语言环境对日期时间的影响
在多语言和多地区的应用程序中,正确显示日期和时间对于用户体验至关重要。由于时区和语言环境的不同,同一时间点可能需要在不同的方式下展示给用户。例如,美国东部时间2023年3月1日15:00在印度的本地时间显示将会是2023年3月2日凌晨3:30,这不仅关系到时区的转换,还可能涉及到语言环境下的日期格式和星期表示方法。
Java的Locale类能够与Calendar类、DateFormat类配合使用,实现根据用户所在地区的时间格式和语言环境显示日期和时间。
```java
import java.util.Calendar;
import java.util.Locale;
import java.text.SimpleDateFormat;
public class DateTimeFormattingExample {
public static void main(String[] args) {
Calendar calendar = Calendar.getInstance();
// 获取用户的默认语言环境
Locale currentLocale = Locale.getDefault();
// 创建一个日期时间格式器,以当前语言环境为基准
SimpleDateFormat formatter = new SimpleDateFormat("EEE MMM dd HH:mm:ss zzz yyyy", currentLocale);
// 输出格式化后的日期时间
System.out.println("Formatted Date: " + formatter.format(calendar.getTime()));
}
}
```
### 3.1.2 创建和管理Locale特定的日期时间格式器
除了使用默认语言环境来格式化日期和时间外,还可以根据需要创建特定的Locale对象,来获取相应的日期时间格式器。
```java
import java.text.DateFormat;
import java.util.Locale;
public class LocaleSpecificDateTimeFormatter {
public static void main(String[] args) {
// 以法国为例,创建一个特定的Locale对象
Locale frenchLocale = new Locale("fr", "FR");
// 获取对应Locale的日期时间格式器
DateFormat dateFormat = DateFormat.getDateTimeInstance(DateFormat.FULL, DateFormat.FULL, frenchLocale);
// 打印示例
System.out.println(dateFormat.format(new java.util.Date()));
}
}
```
在上面的代码中,我们创建了一个针对法国地区的日期时间格式器,这样就可以输出以法国文化习惯表示的日期和时间了。
## 3.2 Locale类在数字和货币格式化中的角色
### 3.2.1 数字格式化工具类NumberFormat
Java中处理数字格式化的类是NumberFormat。这个类允许开发者根据不同的Locale设置来格式化数字。例如,一个数字在英语和法语环境下的表达方式是不同的。下面是一个示例代码:
```java
import java.text.NumberFormat;
import java.util.Locale;
public class NumberFormatExample {
public static void main(String[] args) {
double number = 1234567.89;
// 获取默认Locale的NumberFormat
NumberFormat defaultFormat = NumberFormat.getInstance();
// 获取法国Locale的NumberFormat
NumberFormat frenchFormat = NumberFormat.getInstance(Locale.FRANCE);
// 格式化数字,并输出
System.out.println("Default Locale: " + defaultFormat.format(number));
System.out.println("French Locale: " + frenchFormat.format(number));
}
}
```
### 3.2.2 货币值的本地化表示
在处理不同地区的货币值时,需要考虑货币符号、小数点和千位分隔符的差异。Java的NumberFormat类同样可以用来格式化货币,通过使用`getCurrencyInstance(Locale locale)`方法,我们可以得到一个针对特定Locale的货币格式器。
```java
import java.text.NumberFormat;
import java.util.Locale;
public class CurrencyFormatExample {
public static void main(String[] args) {
double amount = 123456.789;
// 获取默认Locale的货币格式器
NumberFormat defaultCurrencyFormat = NumberFormat.getCurrencyInstance();
// 获取日本Locale的货币格式器
NumberFormat japaneseCurrencyFormat = NumberFormat.getCurrencyInstance(Locale.JAPAN);
// 格式化货币,并输出
System.out.println("Default Currency: " + defaultCurrencyFormat.format(amount));
System.out.println("Japanese Currency: " + japaneseCurrencyFormat.format(amount));
}
}
```
## 3.3 Locale类与文本排序和比较
### 3.3.1 Collator类的使用和自定义
文本排序和比较也是国际化编程中重要的一部分。Java提供了Collator类来处理不同语言环境下的文本比较和排序规则。Collator类可以按照特定Locale的规则来比较字符串。
```java
import java.text.Collator;
import java.util.Locale;
public class CollatorExample {
public static void main(String[] args) {
String[] strings = {"apple", "banana", "grape", "mango"};
Collator collator = Collator.getInstance(Locale.US); // 使用美国的比较规则
collator.setStrength(Collator.PRIMARY); // 设置比较强度
// 对数组进行排序
java.util.Arrays.sort(strings, collator);
// 输出排序结果
for(String str : strings) {
System.out.println(str);
}
}
}
```
### 3.3.2 文本排序规则在不同Locale下的表现
在不同的Locale下,文本的排序规则是不同的。下面使用mermaid流程图来表示Collator类的使用流程。
```mermaid
graph TD;
A[开始] --> B[创建Collator实例]
B --> C[设置Locale]
C --> D[设置排序强度]
D --> E[定义比较规则]
E --> F[应用Collator进行文本排序]
F --> G[结束]
```
以上流程图描述了使用Collator类进行文本排序的步骤。由于不同语言环境下的排序规则可能大相径庭,因此设定正确的Locale和排序强度是实现准确文本比较的关键。
至此,我们已经介绍了Locale类在Java国际化编程中的核心应用,包括日期时间、数字和货币格式化以及文本排序和比较。这些内容为我们构建国际化应用提供了强大的工具和方法。下一章节我们将探讨Locale类的进阶使用技巧以及性能优化方法。
# 4. Java Locale类的进阶使用技巧和性能优化
在本章,我们将深入探讨Java Locale类的进阶使用技巧以及如何优化其性能。这一阶段的学习将帮助我们更高效地进行国际化编程,并确保应用能够以最小的性能开销适应不同地区的语言环境。
## 4.1 Locale敏感的操作和性能影响
### 4.1.1 性能基准测试:Locale对操作的影响
当我们处理大量需要根据Locale进行格式化的数据时,比如日期时间、数字和货币等,Locale的选择和配置可能会对性能产生显著的影响。为了直观理解这种影响,我们可以进行一系列的性能基准测试。
以下是一个基准测试的例子,它展示了不同的Locale配置对日期格式化操作性能的影响:
```java
public class LocalePerformanceTest {
@Test
public void testDateFormattingPerformance() {
Locale[] locales = {
Locale.ENGLISH, // Fastest for English locales
Locale.CHINESE, // Slower than English locales
// Add more locales for the test
};
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.SHORT);
for (Locale locale : locales) {
formatter.withLocale(locale);
long startTime = System.nanoTime();
for (int i = 0; i < 1000000; i++) {
formatter.format(now);
}
long endTime = System.nanoTime();
System.out.println("Locale: " + locale + " - Time: " + (endTime - startTime) / 1000000 + " ms");
}
}
}
```
在测试过程中,我们会发现对于某些Locale的配置,格式化操作的性能明显慢于其他配置。这样的测试结果可以帮助我们选择在性能和功能之间进行权衡。
### 4.1.2 如何最小化Locale敏感操作的性能开销
在了解到Locale敏感操作对性能的影响后,我们需要学习如何最小化这种开销。以下是一些优化建议:
- **重用Locale对象**:Locale对象是不可变的,因此一旦创建,它们就可以被无限次地重用。避免在循环或者频繁调用的方法中重复创建Locale对象。
- **缓存格式化器**:对于频繁使用的格式化器,比如`NumberFormat`和`DateTimeFormatter`,应该创建它们的实例并缓存起来,而不是每次需要的时候都创建一个新的。
- **批量处理**:如果可能,尽量将需要格式化的数据集中在一起处理,减少格式化操作的调用次数。
- **合理选择Locale**:避免使用那些需要额外步骤进行字符串转换的Locale,因为这会增加处理时间。
## 4.2 Locale类的内存管理和资源回收
### 4.2.1 Locale对象的不可变性和内存特性
Java中的Locale对象是不可变的,这意味着一旦创建,其内部状态就不能被改变。因此,多个Locale对象可以安全地共享,不需要复制内部状态,从而减少了内存的使用。
不可变性使得Locale对象非常适合用于多线程环境中,因为它们不需要同步控制即可安全地共享。然而,需要注意的是,不可变对象也意味着每次对Locale的修改操作(如`withLanguage`)都会创建一个新的对象。
### 4.2.2 使用Locale时的内存优化策略
虽然Locale对象本身的设计有助于内存优化,但在实际应用中,我们还可以采取一些策略进一步优化:
- **Locale池化**:为了避免重复创建Locale对象,可以实现一个Locale池。这个池可以是一个简单的HashMap,键为Locale的字符串表示,值为对应的Locale实例。
- **使用Locale.Builder**:创建特定的Locale对象时,可以使用`Locale.Builder`类,它允许我们分步骤构建Locale,而不是一次性提供所有参数。这样做在某些情况下可以减少中间对象的创建。
```java
Locale.Builder builder = new Locale.Builder();
builder.setLanguage("en");
builder.setRegion("US");
Locale locale = builder.build();
```
- **监控内存使用情况**:通过使用JVM的监控工具,比如VisualVM或者JProfiler,我们可以监控和分析内存使用情况,找到潜在的内存泄漏或者可以优化的地方。
## 4.3 Java虚拟机的Locale环境配置
### 4.3.1 JVM级别设置和应用级别的Locale差异
Java虚拟机允许我们为整个JVM设置默认的Locale环境。这与在应用级别指定Locale是两个不同的概念。
JVM级别设置主要影响Java运行时的默认行为,例如,它会影响日期、时间、数字和货币等的显示格式。我们可以使用系统属性`user.language`、`user.country`和`user.variant`来设置JVM级别的Locale。
```shell
java -Duser.language=en -Duser.country=US -Duser.variant=WIN -jar your-app.jar
```
而应用级别的Locale通常用于应用需要显示或处理特定地区的数据时。例如,一个用户界面可能需要根据用户的地理位置来显示本地化的消息。
### 4.3.2 JVM选项和环境变量对Locale行为的影响
JVM的选项和环境变量可以在启动Java应用前配置,从而影响应用的行为。这些配置项可以用来指定或覆盖默认的Locale设置,影响应用的国际化行为。
- **`user.language`**: 设置默认的语言代码。
- **`user.country`**: 设置默认的国家代码。
- **`user.variant`**: 设置默认的变体代码。
- **`java.locale.providers`**: 指定Java国际化数据的来源。
这些环境变量和选项的组合使用,使得我们能够根据实际需要灵活地调整应用的国际化行为,同时还可以在不同环境之间保持一致性和可预测性。
```shell
export JAVA_TOOL_OPTIONS="-Duser.language=en -Duser.country=US"
```
在本章中,我们已经探讨了如何使用Java Locale类进行进阶的编程技巧,以及如何优化其性能。接下来,我们将了解Java Locale类的未来展望以及国际化编程的替代方案。
# 5. Locale类的未来展望和替代方案
随着Java技术的发展,对于国际化编程的需求也在不断提升。作为处理本地化信息的核心类,Locale类已经伴随Java走过了许多个版本。在Java新版本中,Locale类得到了一定的改进,同时,也出现了一些新的替代方案。开发者们需要了解这些新动态,以构建更加健壮和符合现代需求的国际化应用。
## 5.1 Locale类在Java新版本中的改进和未来方向
Java 11作为LTS(长期支持)版本,对国际化相关的API进行了一些改进,以提升开发者的编程体验。例如,增加了对Unicode CLDR的更紧密集成,使得日期、数字等本地化数据格式化更为准确和灵活。
### 5.1.1 Java 11及后续版本中Locale的变化
Java 11引入了`java.text.spi.BreakIteratorProvider` SPI接口,该接口允许开发者提供自定义的文本边界分析器,从而在不同语言环境中进行更准确的文本处理。同时,`java.text.NumberFormat`等类也得到了增强,以支持更复杂的本地化需求。
### 5.1.2 Java国际化API的现代化和改进路径
为了更好地支持国际化,Java的国际化API正在不断地被现代化。这一趋势包括了更广泛的Unicode支持、更灵活的区域设置管理以及与现代操作系统和语言环境的更好兼容。开发者们应关注这些改进,并考虑在未来的项目中应用新的API来提升软件的国际化水平。
## 5.2 探索Java国际化编程的替代方案
尽管Java平台提供了Locale类,但其能力可能不足以应对所有国际化需求。因此,探索和评估第三方库及国际化的替代方案变得十分重要。
### 5.2.1 第三方库的使用和评估
目前,有一些流行的第三方库可以提供扩展的国际化支持,如Apache Commons Lang提供的`LocaleUtils`,以及国际化工具库如i18next和FormatJS等。这些库提供了额外的功能,如更丰富的日期和数字格式化选项,以及对语言环境变化更灵敏的反应。
### 5.2.2 基于Unicode CLDR的国际化处理方法
Unicode Common Locale Data Repository(CLDR)是当前国际化的标准数据仓库,提供了大量关于语言、国家、货币、数字格式等的数据。将CLDR集成到应用程序中,能够提供更准确和全面的本地化支持。Java 9及之后的版本开始更好地与CLDR集成,但开发者也可以考虑直接使用CLDR数据,或者使用如ICU4J这样的库,它提供了对CLDR数据的访问。
## 5.3 构建面向未来的国际化应用
随着应用越来越全球化,构建一个能够适应未来变化的国际化应用变得更加重要。
### 5.3.1 跨平台兼容性和国际化库的选择
在选择国际化库时,需要考虑库的维护状态、社区支持以及兼容性。例如,选择能够跨平台工作的库可以确保应用在不同的环境中都能提供一致的用户体验。同时,开发者也应关注库是否与新兴的Java国际化API保持同步,以及是否易于集成到现有的构建系统中。
### 5.3.2 实现国际化应用的最佳实践和开发建议
为了实现最佳的国际化应用,开发者应遵循一些实践原则,例如:
- 保持语言数据和应用程序代码分离,以方便管理和更新。
- 使用Unicode字符集,确保文本处理的正确性。
- 实现动态语言选择功能,为用户提供灵活的语言选项。
- 进行彻底的本地化测试,确保应用在不同语言环境中都能正常工作。
结合上述章节的内容,可以看出,Java Locale类虽然作为国际化的基础工具,在新版本中有所改进,但开发者仍需关注其发展动态和性能优化。同时,通过探索替代方案和最佳实践,我们可以构建更强大、更灵活的国际化应用,以面对不断变化的全球市场。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Java Locale类(地区设置)”专栏,这里将深入探讨Locale类,掌握国际化编程的核心技巧和优化秘籍。我们将深入理解Locale类的用法和最佳实践,并探索处理复杂地区化问题的实战策略。此外,还将揭秘Java多线程地区设置的线程安全和地区敏感数据处理指南。专栏还将深入研究Calendar和Locale类的协同机制,以及Locale类在Swing中的应用和性能提升。最后,我们将探讨解析器地区设置支持的深入理解,以及编写地区敏感测试用例的策略和技巧。通过本专栏,您将全面掌握Locale类,提升您的国际化编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【硬件实现】:如何构建性能卓越的PRBS生成器

# 摘要
本文全面探讨了伪随机二进制序列(PRBS)生成器的设计、实现与性能优化。首先,介绍了PRBS生成器的基本概念和理论基础,重点讲解了其工作原理以及相关的关键参数,如序列长度、生成多项式和统计特性。接着,分析了PRBS生成器的硬件实现基础,包括数字逻辑设计、FPGA与ASIC实现方法及其各自的优缺点。第四章详细讨论了基于FPGA和ASIC的PRBS设计与实现过程,包括设计方法和验
NUMECA并行计算核心解码:掌握多节点协同工作原理
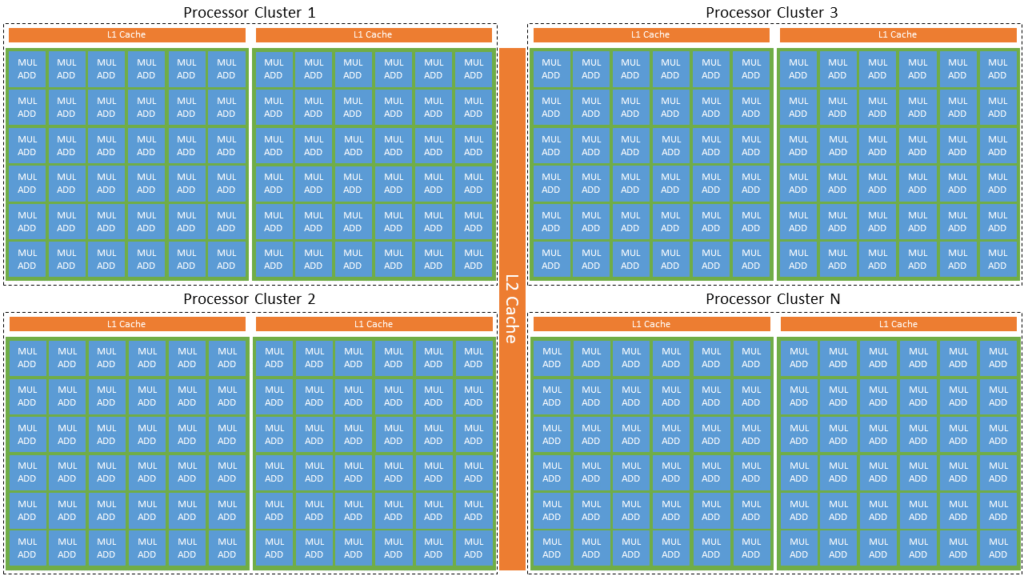
# 摘要
NUMECA并行计算是处理复杂计算问题的高效技术,本文首先概述了其基础概念及并行计算的理论基础,随后深入探讨了多节点协同工作原理,包括节点间通信模式以及负载平衡策略。通过详细说明并行计算环境搭建和核心解码的实践步骤,本文进一步分析了性能评估与优化的重要性。文章还介绍了高级并行计算技巧,并通过案例研究展示了NUMECA并行计算的应用。最后,本文展望了并行计
提升逆变器性能监控:华为SUN2000 MODBUS数据优化策略

# 摘要
逆变器作为可再生能源系统中的关键设备,其性能监控对于确保系统稳定运行至关重要。本文首先强调了逆变器性能监控的重要性,并对MODBUS协议进行了基础介绍。随后,详细解析了华为SUN2000逆变器的MODBUS数据结构,阐述了数据包基础、逆变器的注册地址以及数据的解析与处理方法。文章进一步探讨了性能数据的采集与分析优化策略,包括采集频率设定、异常处理和高级分析技术。
小红书企业号认证必看:15个常见问题的解决方案

# 摘要
本文系统地介绍了小红书企业号的认证流程、准备工作、认证过程中的常见问题及其解决方案,以及认证后的运营和维护策略。通过对认证前准备工作的详细探讨,包括企业资质确认和认证材料
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
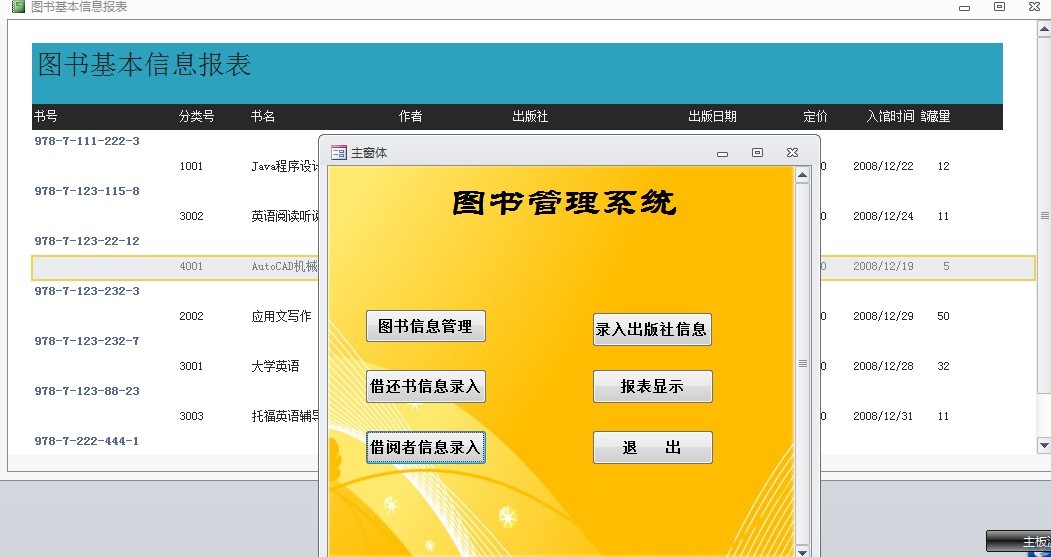
【UML类图与图书馆管理系统】:掌握面向对象设计的核心技巧
# 摘要
本文旨在探讨面向对象设计中UML类图的应用,并通过图书馆管理系统的需求分析、设计、实现与测试,深入理解UML类图的构建方法和实践。文章首先介绍了UML类图基础,包括类图元素、关系类型以及符号规范,并详细讨论了高级特性如接口、依赖、泛化以及关联等。随后,文章通过图书馆管理系统的案例,展示了如何将UML类图应用于需求分析、系统设计和代码实现。在此过程中,本文强调了面向对象设计原则,评价了UML类图在设计阶段
【虚拟化环境中的SPC-5】:迎接虚拟存储的新挑战与机遇
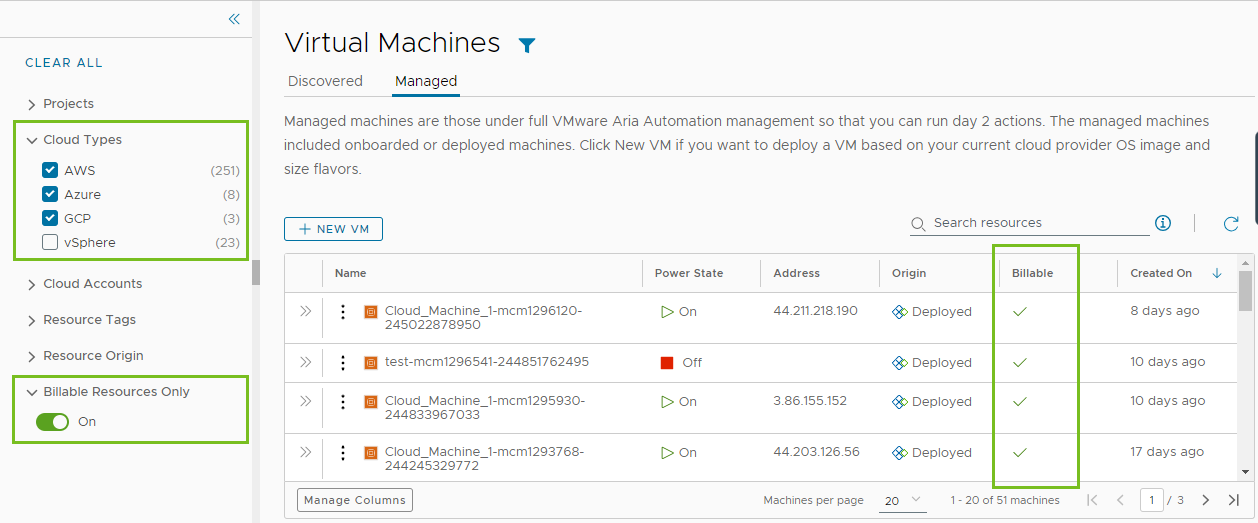
# 摘要
本文旨在全面介绍虚拟化环境与SPC-5标准,深入探讨虚拟化存储的基础理论、存储协议与技术、实践应用案例,以及SPC-5标准在虚拟化环境中的应用挑战。文章首先概述了虚拟化技术的分类、作用和优势,并分析了不同架构模式及SPC-5标准的发展背景。随后
硬件设计验证中的OBDD:故障模拟与测试的7大突破
# 摘要
OBDD(有序二元决策图)技术在故障模拟、测试生成策略、故障覆盖率分析、硬件设计验证以及未来发展方面展现出了强大的优势和潜力。本文首先概述了OBDD技术的基础知识,然后深入探讨了其在数字逻辑故障模型分析和故障检测中的应用。进一步地,本文详细介绍了基于OBDD的测试方法,并分析了提高故障覆盖率的策略。在硬件设计验证章节中,本文通过案例分析,展示了OBDD的构建过程、优化技巧及在工业级验证中的应用。最后,本文展望了OBDD技术与机器学习等先进技术的融合,以及OBDD工具和资源的未来发展趋势,强调了OBDD在AI硬件验证中的应用前景。
# 关键字
OBDD技术;故障模拟;自动测试图案生成
海康威视VisionMaster SDK故障排除:8大常见问题及解决方案速查
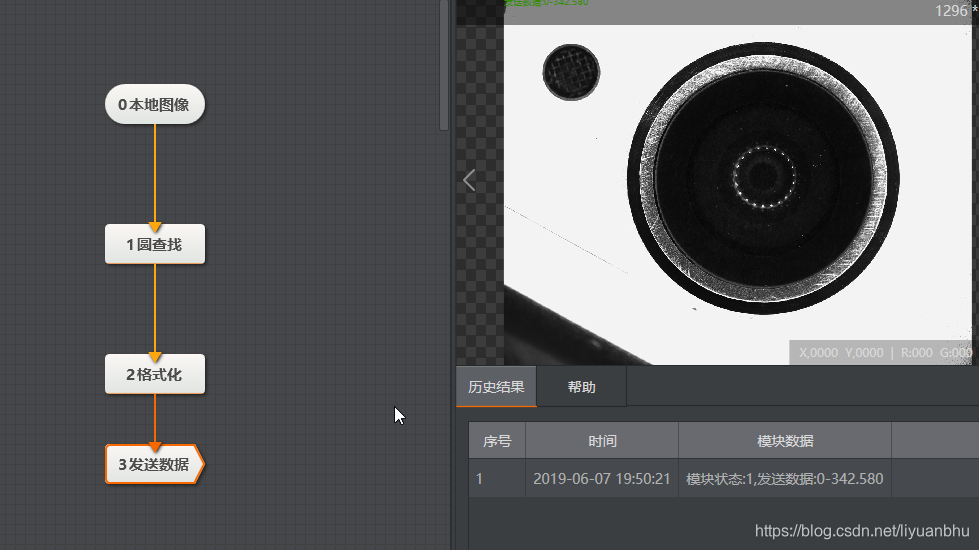
# 摘要
本文全面介绍了海康威视VisionMaster SDK的使用和故障排查。首先概述了SDK的特点和系统需求,接着详细探讨了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )