Pygments库自定义样式:创建独一无二的代码高亮主题
发布时间: 2024-10-16 03:26:00 阅读量: 23 订阅数: 32 

pygments:y:male_sign:黑暗主题为Pygments
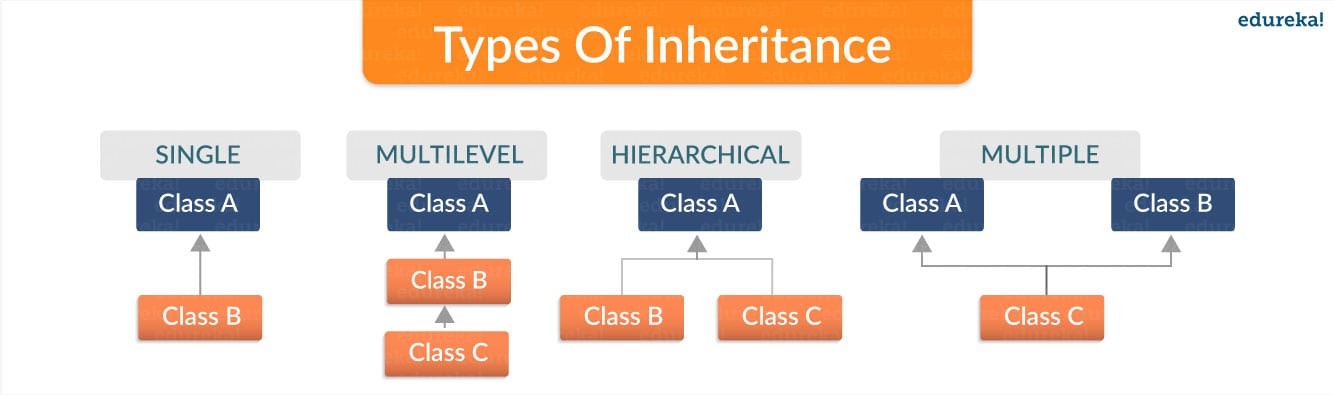
# 1. Pygments库基础介绍
Pygments是一个广泛使用的Python语法高亮库,它支持多种编程语言和标记语言,并能够生成美观的代码高亮效果。通过Pygments,开发者可以轻松地在他们的博客、文档或者代码展示中嵌入语法高亮的代码块。
## 简介Pygments
Pygments的使用非常简单,它提供了丰富的API接口和命令行工具,可以处理从简单的代码片段到大型的代码文件。用户只需要提供原始代码,Pygments就能自动分析代码并应用预定义或自定义的样式。
## Pygments的优势
Pygments的一个主要优势是它的灵活性和可扩展性。它允许用户通过简单的样式定义文件来自定义高亮样式,而且它的插件架构允许开发者为新语言添加词法分析器。此外,Pygments支持多种输出格式,包括HTML、RTF、LaTeX和ANSI颜色代码,使其成为跨平台项目中的理想选择。
接下来,我们将深入探讨Pygments的词法分析和样式应用,了解它是如何工作的,以及如何利用这些特性来增强我们的代码展示。
# 2. 深入理解Pygments的词法分析和样式应用
## 2.1 词法分析的原理和作用
### 2.1.1 词法分析在代码高亮中的角色
词法分析是编译过程中的一个基本阶段,它的主要任务是对源程序进行扫描和分解,将字符序列转换为标记(Token)序列。在代码高亮的场景中,词法分析器将源代码分解为一个个具有特定含义的词法单元,如关键字、操作符、标识符等。这些词法单元是代码风格样式的应用基础,每个词法单元对应不同的样式,使得最终的代码显示具有鲜明的视觉效果,提高了代码的可读性和美观性。
例如,考虑以下Python代码片段:
```python
def hello_world():
print("Hello, world!")
```
词法分析器会将上述代码分解为以下Token序列:
```
KEYWORD_DEF, IDENTIFIER_hello_world, PUNCTUATION_OPEN_PARENTHESIS, PUNCTUATION_CLOSE_PARENTHESIS, COLON, IDENTIFIER_print, PUNCTUATION_OPEN_PARENTHESIS, STRING_LITERAL_Heredoc, PUNCTUATION_CLOSE_PARENTHESIS, NEWLINE
```
每个Token都有其对应的样式规则,如`KEYWORD_DEF`可能对应一种颜色,而`IDENTIFIER`可能对应另一种颜色。这种分解和样式化的处理,使得代码高亮成为可能。
### 2.1.2 Pygments的词法分析器解析
Pygments通过内置的词法分析器解析源代码,并生成Token序列。词法分析器的工作过程可以分为以下几步:
1. **读取源代码**:词法分析器从源代码中读取字符流。
2. **字符分类**:将字符流中的字符分类,如是否为字母、数字、操作符等。
3. **生成Token**:根据字符的分类生成相应的Token。
4. **应用样式**:将样式应用到相应的Token上,完成代码高亮。
Pygments内置了大量的词法分析器,几乎涵盖了所有主流编程语言和标记语言。开发者可以通过调用`Pygments`库中的`lexers`模块来使用这些分析器。下面是一个简单的Python代码示例,展示如何使用Pygments的词法分析器:
```python
from pygments import lexers
from pygments.token import Token
# 定义一个简单的Python代码
code = """def hello_world():
print("Hello, world!")"""
# 获取Python的词法分析器
lexer = lexers.get_lexer_by_name('python')
# 生成Token序列
tokens = lexer.lex(code)
# 输出Token及其类型
for token, token_type in tokens:
print(f"{token_type.name}: {token}")
```
在上述代码中,`lexers.get_lexer_by_name('python')`获取了Python的词法分析器,`lexer.lex(code)`将代码转换为Token序列,并打印每个Token及其类型。
词法分析是Pygments中非常核心的功能,它是后续生成代码高亮显示的基础。理解词法分析的原理和作用,对于深入学习和自定义Pygments样式至关重要。
## 2.2 样式应用的机制
### 2.2.1 样式定义和应用流程
Pygments的样式定义是通过样式文件来完成的,这些样式文件通常包含了一个或多个样式规则,用于定义不同Token类型的颜色、背景色、字体样式等。样式定义通常使用CSS语法,但Pygments还扩展了一些自定义的属性。
样式应用流程如下:
1. **样式定义**:开发者定义或选择一个样式文件。
2. **样式应用**:通过词法分析器生成Token序列后,应用样式文件中的规则到Token序列。
3. **生成高亮代码**:将样式化的Token序列转换为HTML或其他格式,以便在Web页面或文档中显示。
下面是一个简单的样式定义示例,使用了Pygments的默认样式`manni`:
```css
/* manni样式文件的一部分 */
***ment { color: #888888; }
span.token.string { color: #BA2121; }
span.token.keyword { color: #1990B8; }
```
在Pygments中,样式文件通常具有以下扩展名:`.conf`、`.py`、`.css`、`.js`、`.json`、`.yaml`等。
### 2.2.2 如何通过样式控制代码高亮
通过样式文件,开发者可以精确控制代码高亮的各个方面。样式文件中的每一条规则都指定了一个Token类型应该使用的样式。样式规则的语法如下:
```css
span.token.{type} {样式属性;}
```
其中`{type}`是Token的类型,`样式属性`可以是颜色、字体大小、背景色等。例如,以下规则将Python代码中的字符串Token显示为红色:
```css
span.token.string { color: red; }
```
在Pygments中,样式文件中的样式规则应用到Token上是基于优先级的。样式文件中的规则优先于默认样式,用户自定义的样式文件优先于内置样式文件。开发者可以通过以下方式应用自定义样式:
```python
from pygments import style_from_pygments_dict
from pygments.styles.default import DefaultStyle
# 自定义样式
my_style = style_from_pygments_dict({
Token.String: '#FF0000', # 字符串颜色设置为红色
Token.Number: '#00FF00', # 数字颜色设置为绿色
})
# 应用自定义样式
lexer = lexers.get_lexer_by_name('python')
formatter = PygmentsHTMLFormatter(style=my_style)
```
在上述代码中,我们创建了一个新的样式对象`my_style`,它将字

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Pygments 库,这是一个强大的 Python 代码高亮库。它涵盖了从基础到高级的各种主题,包括:
* 掌握代码高亮的实用技巧
* 优化性能以加速代码高亮
* 创建自定义高亮器的分步指南
* 快速诊断和解决常见错误
* 增强代码视觉效果的技巧
* 无缝集成 Pygments 库到开发流程
* 开发新语法解析器的指南
* 探索有用的插件和模板
* 编写高质量代码的关键实践
* 符合 PEP8 编码标准的指南
* 深入探讨复杂问题的解决方案
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决兼容性难题:Aspose.Words 15.8.0 如何与旧版本和平共处

# 摘要
Aspose.Words是.NET领域内用于处理文档的强大组件,广泛应用于软件开发中以实现文档生成、转换、编辑等功能。本文从版本兼容性问题、新版本改进、代码迁移与升级策略、实际案例分析
【电能表软件更新完全手册】:系统最新状态的保持方法

# 摘要
电能表软件更新是确保电能计量准确性和系统稳定性的重要环节。本文首先概述了电能表软件更新的理论基础,分析了电能表的工作原理、软件架构以及更新的影响因素。接着,详细阐述了更新实践步骤,包括准备工作、实施过程和更新后的验证测试。文章进一步探讨了软件更新的高级应用,如自动化策略、版
全球视角下的IT服务管理:ISO20000-1:2018认证的真正益处
# 摘要
本文综述了IT服务管理的最新发展,特别是针对ISO/IEC 20000-1:2018标准的介绍和分析。文章首先概述了IT服务管理的基础知识,接着深入探讨了该标准的历史背景、核心内容以及与旧版标准的差异,并评估了这些变化对企业的影响。进一步,文章分析了获得该认证为企业带来的内部及外部益处,包括服务质量和客户满意度的提升,以及市场竞争力的增强。随后,
Edge与Office无缝集成:打造高效生产力环境
# 摘要
随着数字化转型的加速,企业对于办公生产力工具的要求不断提高。本文深入探讨了微软Edge浏览器与Office套件集成的概念、技术原理及实践应用。分析了微软生态系统下的技术架构,包括云服务、API集成以
开源HRM软件:选择与实施的最佳实践指南(稀缺性:唯一全面指南)

# 摘要
本文针对开源人力资源管理系统(HRM)软件的市场概况、选择、实施、配置及维护进行了全面分析。首先,概述了开源HRM软件的市场状况及其优势,接着详细讨论了如何根据企业需求选择合适软件、评估社区支持和技术实力、探索定制和扩展能力。然后,本文提出了一个详尽的实施计划,并强调
性能优化秘籍:提升Quectel L76K信号强度与网络质量的关键

# 摘要
本文首先介绍了Quectel L76K模块的基础知识及其性能影响因素。接着,在理论基础上阐述了无线通信信号的传播原理和网络质量评价指标,进一步解读了L76K模块的性能参数与网络质量的关联。随后,文章着重分析了信号增强技术和网络质量的深度调优实践,包括降低延迟、提升吞吐量和增强网络可靠性的策略。最后,通过案例研究探讨了L76K模块在不同实际应用场景中
【SPC在注塑成型中的终极应用】:揭开质量控制的神秘面纱
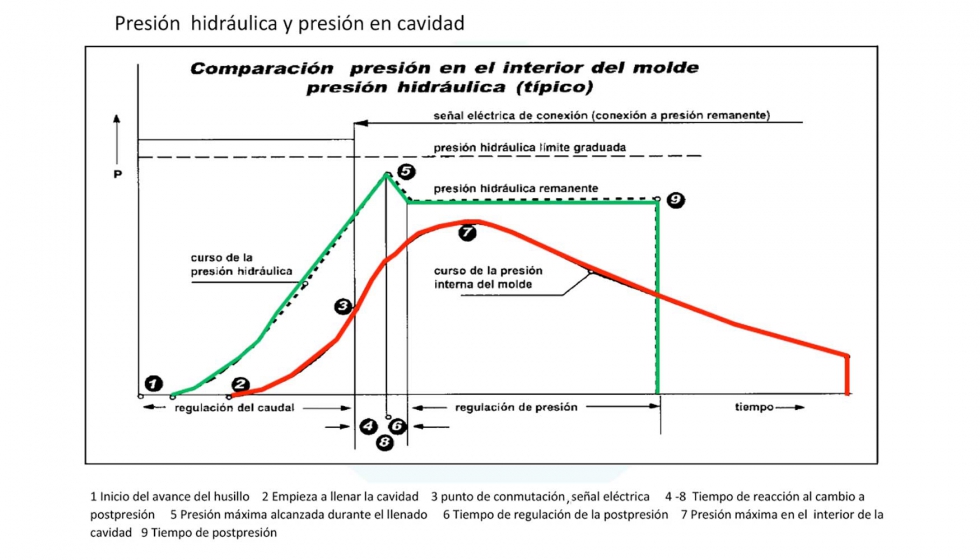
# 摘要
统计过程控制(SPC)是确保注塑成型产品质量和过程稳定性的关键方法。本文首先介绍了SPC的基础概念及其与质量控制的紧密联系,随后探讨了SPC在注塑成型中的实践应用,包括质量监控、设备整合和质量改进案例。文章进一步分析了SPC技术的高级应用,挑战与解决方案,并展望了其在智能制造和工业4.0环境下的未来趋势。通过对多个行业案例的研究,本文总结了SPC成功实施的关键因素,并提供了基于经验教训的优化策略。本文的研究强调了SPC在
YXL480高级规格解析:性能优化与故障排除的7大技巧

# 摘要
YXL480作为一款先进的设备,在本文中对其高级规格进行了全面的概览。本文深入探讨了YXL480的性能特性,包括其核心架构、处理能力、内存和存储性能以及能效比。通过量化分析和优化策略的介绍,本文揭示了YXL480如何实现高效能。此外,文章还详细介绍了YXL480故障诊断与排除的技巧,从理论基础到实践应用,并探讨了性能优化的方法论,提供了硬件与软
西门子PLC与HMI集成指南:数据通信与交互的高效策略

# 摘要
本文详细介绍了西门子PLC与HMI集成的关键技术和应用实践。首先概述了西门子PLC的基础知识和通信协议,探讨了其工作原理、硬件架构、软件逻辑和通信技术。接着,文章转向HMI的基础知识与界面设计,重点讨论了人机交互原理和界面设计的关键要素。在数据通信实践操
【视觉SLAM入门必备】:MonoSLAM与其他SLAM方法的比较分析

# 摘要
视觉SLAM(Simultaneous Localization and Mapping)技术是机器人和增强现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )