【Python util库网络编程技巧】:打造你的HTTP客户端与服务器
发布时间: 2024-09-29 23:22:15 阅读量: 130 订阅数: 32 

果壳处理器研究小组(Topic基于RISCV64果核处理器的卷积神经网络加速器研究)详细文档+全部资料+优秀项目+源码.zip

# 1. Python网络编程基础
## 1.1 网络编程的基本概念和协议
### 1.1.1 了解网络协议栈与TCP/IP模型
网络编程涉及的基础是协议和协议栈的概念。TCP/IP模型是互联网的核心协议栈,包括四个层次:应用层、传输层、网络层、链路层。每一层负责不同的网络任务,确保数据从一台计算机通过网络传递到另一台计算机。
### 1.1.2 掌握HTTP协议的基本工作原理
超文本传输协议(HTTP)是应用层协议,是网络编程中经常使用的协议之一。HTTP工作在TCP之上,以请求-响应模型进行通信。客户端发送请求,服务器处理后返回响应。理解请求和响应的结构、状态码、头部信息等对于网络编程至关重要。
## 1.2 Python中的网络编程接口概述
### 1.2.1 Python标准库中的网络编程模块
Python的标准库提供了丰富的网络编程模块,例如`socket`、`http.server`、`urllib`等。`socket`模块是进行底层网络通信的基础,允许Python程序发送和接收数据。这些模块为实现网络应用提供了便捷的接口。
### 1.2.2 第三方库如requests与Flask的简介
除了标准库之外,第三方库如`requests`提供了更高级的网络请求处理能力,`Flask`等则允许开发者快速构建Web应用。这些库是对标准库功能的扩展,使得网络编程更加高效和直观。
接下来,我们将通过具体实例和代码演示,深入探讨如何利用Python进行网络编程。我们会从基本的HTTP客户端实现开始,逐步涉及服务器搭建以及更高级的网络编程技巧。
# 2. 利用Python标准库打造HTTP客户端
### 2.1 使用urllib库进行网络请求
urllib是Python标准库的一部分,它提供了用于读取和写入URL的功能。通过urllib,我们能够进行各种网络请求,如GET、POST等,并且可以处理重定向、Cookies、代理等。
#### 2.1.1 urllib的安装和基础使用方法
由于urllib是Python标准库的一部分,因此不需要额外安装。我们可以直接导入使用。以下是urllib库最基础的使用示例:
```python
import urllib.request
# 获取网页内容
response = urllib.request.urlopen('***')
html_content = response.read()
print(html_content.decode('utf-8'))
```
在上述代码中,我们首先导入了urllib中的request模块,然后使用`urlopen`方法发起一个GET请求到`***`。`response.read()`方法用于读取服务器返回的数据。最后,我们打印出网页的内容,并将其从字节码解码成可读的文本。
#### 2.1.2 构建GET和POST请求
构建GET请求时,我们通常使用`urllib.parse`模块中的`urlparse`和`urlencode`方法来解析URL和编码查询字符串。
```python
from urllib.parse import urlencode, urlparse
params = {'key1': 'value1', 'key2': 'value2'}
query_string = urlencode(params)
url = '***' + query_string
response = urllib.request.urlopen(url)
data = response.read()
print(data.decode('utf-8'))
```
在该例子中,我们构建了一个带有查询参数的GET请求。`urlencode`方法将字典转换成了URL的查询字符串格式。而构建POST请求时,则需要设置请求头,并将要发送的数据编码后传递给`urlopen`方法。
```python
from urllib.parse import urlencode
# 构造POST请求数据
post_data = urlencode({'key': 'value'}).encode()
# 创建Request对象,模拟表单提交的POST请求
request = urllib.request.Request(url='***', data=post_data, method='POST')
# 发送请求并获取响应
response = urllib.request.urlopen(request)
data = response.read()
print(data.decode('utf-8'))
```
在这个POST请求的示例中,我们首先将数据进行编码处理,然后创建了一个`Request`对象来指定请求的URL、数据和请求方法。之后,使用`urlopen`发送请求并读取响应内容。
### 2.2 利用requests库简化HTTP请求过程
requests库是一个第三方库,它使得HTTP请求变得异常简单。相比于urllib,requests提供的接口更加简洁易用,因此在实际项目中被广泛采用。
#### 2.2.1 requests库的特点和安装
requests库的特点包括直观的API、易于理解和使用、支持多种认证方式、能够处理多种类型的HTTP请求等。安装requests库可以通过pip进行:
```bash
pip install requests
```
#### 2.2.2 发送请求和处理响应
使用requests库发送请求和处理响应的代码如下:
```python
import requests
# 发起GET请求
response = requests.get('***')
# 获取响应内容
content = response.content
# 获取响应文本
text = response.text
# 获取响应状态码
status_code = response.status_code
print("Status Code:", status_code)
# 获取响应头
headers = response.headers
print("Headers:", headers)
# 发起POST请求
post_response = requests.post('***', data={'key': 'value'})
# 获取POST请求响应
post_content = post_response.content
print(post_content)
```
在上面的代码中,我们使用`requests.get`和`requests.post`方法发送GET和POST请求,并获取了响应的内容、文本、状态码和头信息。requests库的响应对象提供了非常丰富的接口来获取请求的各种细节信息。
通过比较,我们可以看到requests库的代码更加简洁明了,易于编写和理解,这也是它流行的原因之一。
在下一章节中,我们将深入探讨如何使用Python构建自己的HTTP服务器,这将是理解网络编程中客户端-服务器架构的关键一步。
# 3. 构建Python HTTP服务器
随着网络应用的不断发展,能够自行构建服务器的能力变得越来越重要。Python语言以其简洁的语法和强大的标准库,使得开发者可以轻松构建HTTP服务器。本章将深入探讨如何使用Python构建HTTP服务器,并展示如何通过标准库和Flask框架创建更高级的Web服务。
## 3.1 使用Python的http.server模块快速搭建服务器
Python内置的`http.server`模块提供了一个基础的HTTP服务器实现,适用于学习、测试和开发原型。本小节将详细介绍如何使用此模块,并实现一个简单的文件服务器。
### 3.1.1 了解http.server模块的工作机制
`http.server`模块遵循HTTP协议,能够处理HTTP请求和响应。它是基于socket编程的一个高级封装,允许开发者通过定义请求处理逻辑来创建自己的HTTP服务。其工作流程如下:
1. 初始化HTTP服务器对象并绑定到指定的地址和端口。
2. 服务器监听网络接口上的连接请求。
3. 一旦接收到请求,服务器分析请求头并根据请求的路径,生成响应。
4. 将响应头和内容返回给客户端。
### 3.1.2 实现一个简单的文件服务器
以下是一个使用`http.server`模块实现的简单文件服务器示例代码:
```python
from http.server import SimpleHTTPRequestHandler, HTTPServer
def run_file_server(root_dir):
server_address = ('', 8000) # 监听本机所有接口的8000端口
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
print(f"Serving at port {server_address[1]}")
httpd.serve_forever()
if __name__ == "__main__":
import sys
run_file_server(sys.argv[1] if len(sys.argv) > 1 else "./")
```
在此代码中:
- `HTTPServer`类用于创建HTTP服务器,需要一个地址和一个请求处理类。
- `SimpleHTTPRequestHandler`类用于处理静态文件的请求,是`http.server`模块提供的一个基础请求处理器。
- `server_address`变量设置为监听所有接口的8000端口。
- `run_file_server`函数接受一个目录路径作为参数,这个路径就是文件服务器要提供服务的根目录。
运行此脚本后,你可以通过浏览器访问`***`来查看根目录下的文件列表。
### 表格:http.server模块的请求处理器类比较
| 请求处理器类 | 用途 | 特点 |
| --- | --- | --- |
| SimpleHTTPRequestHandler | 处理静态文件请求 | 支持目录列表,不适用于生产环境 |
| CGIHTTPRequestHandler | 支持CGI脚本 | 用于运行CGI程序的Web服务器 |
| BaseHTTPRequestHandler | 用于自定义请求处理器 | 基类,需要自定义解析请求逻辑 |
### mermaid流程图:http.server模块的请求处理流程
```mermaid
graph LR
A[监听端口] --> B{接收到请求?}
B -- 是 --> C[解析请求头]
C --> D{请求是文件吗?}
D -- 是 --> E[读取文件]
D -- 否 --> F[404文件未找到]
E --> G[返回文件内容]
G --> H[等待下一个请求]
F --> H
B -- 否 --> I[等待请求]
I --> B
```
在上面的流程图中,我们可以清晰地看到服务器处理请求的过程,从监

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 Python 标准库中的 util 模块,旨在提升开发者的编码效率和编程水平。从基础知识到高级技巧,专栏涵盖了 util 模块的方方面面,包括异常处理、模块化、文件操作、日期和时间管理、网络编程、文本处理、数据解析和生成、安全特性、算法实现、国际化、并发编程、高级 I/O 操作、日志记录和系统管理。通过深入浅出的讲解和丰富的示例代码,专栏帮助开发者掌握 util 模块的强大功能,从而编写更健壮、高效和可维护的 Python 代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
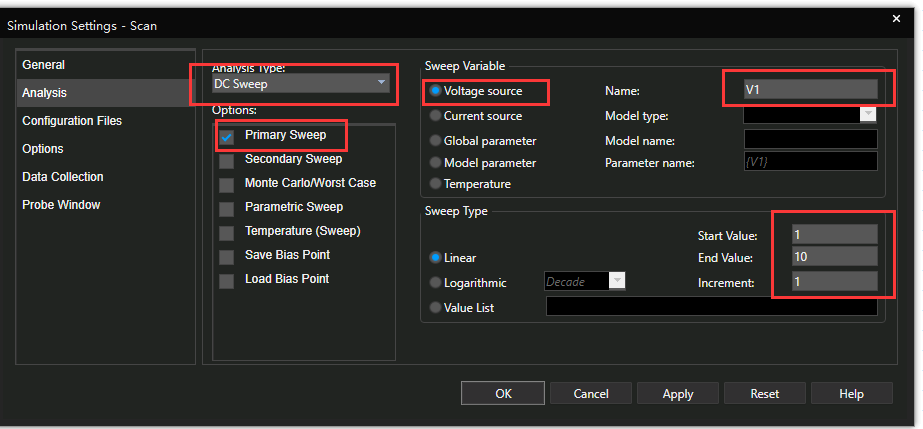
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )