Java压缩算法深度剖析:从原理到实战,掌握压缩技术精髓
发布时间: 2024-08-27 19:36:37 阅读量: 24 订阅数: 30 
# 1. Java压缩算法基础**
压缩算法是将数据编码成更小表示的技术,从而节省存储空间和传输时间。Java提供了广泛的压缩算法,可用于各种应用程序。这些算法分为无损压缩和有损压缩。
**无损压缩**算法可将数据压缩到较小的表示形式,同时保持原始数据的完整性。这意味着解压缩后,数据将与原始数据完全相同。无损压缩算法通常用于文本文件、代码和文档等数据类型。
**有损压缩**算法可将数据压缩到更小的表示形式,但会牺牲一些数据精度。这意味着解压缩后,数据可能与原始数据略有不同。有损压缩算法通常用于图像、音频和视频等数据类型,因为这些数据类型可以容忍一定程度的失真。
# 2. 无损压缩算法
无损压缩算法是一种数据压缩技术,它可以将数据压缩到更小的尺寸,同时不丢失任何原始信息。这意味着在解压缩后,可以完全恢复原始数据。无损压缩算法通常用于压缩文本、图像和音频文件,其中数据完整性至关重要。
### 2.1 霍夫曼编码
#### 2.1.1 基本原理
霍夫曼编码是一种基于频率的无损压缩算法。它通过为每个符号分配可变长度的代码来工作,其中出现频率较高的符号分配较短的代码。这使得可以更有效地压缩数据,因为较短的代码用于更频繁出现的符号。
#### 2.1.2 算法实现
霍夫曼编码算法的实现涉及以下步骤:
1. **计算符号频率:**计算输入数据中每个符号的出现频率。
2. **创建优先级队列:**将符号及其频率放入优先级队列中,其中频率较低的符号具有较高的优先级。
3. **合并符号:**从优先级队列中取出频率最低的两个符号,并创建一个新的符号,其频率等于两个符号频率之和。
4. **为新符号分配代码:**为新符号分配一个代码,该代码是其两个子符号代码的连接。
5. **重复步骤 3 和 4:**重复步骤 3 和 4,直到优先级队列中只剩下一个符号。
6. **生成编码表:**将每个符号与其分配的代码一起存储在编码表中。
```java
import java.util.HashMap;
import java.util.Map;
import java.util.PriorityQueue;
public class HuffmanEncoder {
private Map<Character, String> codeTable;
public HuffmanEncoder() {
codeTable = new HashMap<>();
}
public String encode(String input) {
// 计算符号频率
Map<Character, Integer> frequencies = calculateFrequencies(input);
// 创建优先级队列
PriorityQueue<HuffmanNode> queue = new PriorityQueue<>();
for (Map.Entry<Character, Integer> entry : frequencies.entrySet()) {
queue.add(new HuffmanNode(entry.getKey(), entry.getValue()));
}
// 合并符号并分配代码
while (queue.size() > 1) {
HuffmanNode left = queue.poll();
HuffmanNode right = queue.poll();
HuffmanNode parent = new HuffmanNode(null, left.frequency + right.frequency);
parent.left = left;
parent.right = right;
queue.add(parent);
}
// 生成编码表
generateCodeTable(queue.peek());
// 编码输入数据
StringBuilder encoded = new StringBuilder();
for (char c : input.toCharArray()) {
encoded.append(codeTable.get(c));
}
return encoded.toString();
}
private Map<Character, Integer> calculateFrequencies(String input) {
Map<Character, Integer> frequencies = new HashMap<>();
for (char c : input.toCharArray()) {
frequencies.put(c, frequencies.getOrDefault(c, 0) + 1);
}
return frequencies;
}
private void generateCodeTable(HuffmanNode root) {
if (root == null) {
return;
}
generateCodeTable(root.left, "0");
generateCodeTable(root.right, "1");
}
private void generateCodeTable(HuffmanNode node, String code) {
if (node.isLeaf()) {
codeTable.put(node.character, code);
return;
}
generateCodeTable(node.left, code + "0");
generateCodeTable(node.right, code + "1");
}
private static class HuffmanNode implements Comparable<HuffmanNode> {
private Character character;
private Integer frequency;
private HuffmanNode left;
private HuffmanNode right;
public HuffmanNode(Character character, Integer frequency) {
this.character = character;
this.frequency = frequency;
}
public boolean isLeaf() {
return left == null && right == null;
}
@Override
public int compareTo(HuffmanNode other) {
return this.frequency - other.frequency;
}
}
}
```
### 2.2 LZW算法
#### 2.2.1 基本原理
LZW(Lempel-Ziv-Welch)算法是一种字典编码算法,它通过构建一个动态字典来压缩数据。字典中包含从输入数据中遇到的符号序列派生的代码。算法通过将输入数据中的符号序列替换为字典中的代码来工作,从而实现压缩。
#### 2.2.2 算法实现
LZW算法的实现涉及以下步骤:
1. **初始化字典:**将所有可能的单字符符号添加到字典中。
2. **处理输入数据:**逐个字符处理输入数据。
3. **查找字典:**在字典中查找当前字符序列。
4. **如果找到:**输出字典中字符序列的代码。
5. **如果未找到:**将当前字符序列添加到字典中,并输出其代码。
6. **重复步骤 2-5:**直到处理完所有输入数据。
```java
import java.util.HashMap;
import java.util.Map;
public class LZWEncoder {
private Map<String, Integer> dictionary;
private int nextCode;
public LZWEncoder() {
dictionary = new HashMap<>();
for (int i = 0; i < 256; i++) {
dictionary.put(String.valueOf((char) i), i);
}
nextCode = 256;
}
public String encode(String input) {
StringBuilder encoded = new StringBuilder();
String current = "";
for (char c : input.toCharArray()) {
String next = current + c;
if (dictionary.containsKey(next)) {
current = next;
} else {
encoded.append(dictionary.get(current));
dictionary.put(next, nextCode++);
current = String.valueOf(c);
}
}
encoded.append(dictionary.get(current));
return encoded.toString();
}
}
```
### 2.3 LZMA算法
#### 2.2.1 基本原理
LZMA(Lempel-Ziv-Markov chain Algorithm)算法是一种基于字典和概率模型的无损压缩算法。它使用滑动窗口来存储最近遇到的数据,并使用Markov链模型来预测下一个符号的概率。算法通过将输入数据中的符号序列替换为字典中的代码和概率来工作,从而实现压缩。
#### 2.2.2 算法实现
LZMA算法的实现涉及以下步骤:
1. **初始化字典:**将所有可能的单字符符号添加到字典中。
2. **处理输入数据:**逐个字符处理输入数据。
3. **查找字典:**在字典中查找当前字符序列。
4. **如果找到:**输出字典中字符序列的代码和概率。
5. **如果未找到:**将当前字符序列添加到字典中,并输出其代码和概率。
6. **更新滑动窗口:**将当前字符添加到滑动窗口,并从窗口中删除最旧的字符。
7. **更新Markov链模型:**更新Markov链模型,以反映当前字符序列和滑动窗口中的数据。
8. **重复步骤 2-7:**直到处理完所有输入数据。
```java
import net.jpountz.lzma.LZMAEncoder;
public class LZMAEncoder {
public static byte[] encode(byte[] input) {
LZMAEncoder encoder = new LZMAEncoder();
return encoder.encode(input);
}
}
```
# 3. 有损压缩算法**
有损压缩算法通过牺牲一定程度的图像质量来实现更高的压缩率。与无损压缩算法不同,有损压缩算法会丢弃一些不重要的数据,从而减小文件大小。
### 3.1 JPEG算法
JPEG(Joint Photographic Experts Group)算法是一种广泛用于图像压缩的标准。它采用离散余弦变换(DCT)将图像分解为频率分量,然后对这些分量进行量化和编码。
**3.1.1 基本原理**
JPEG算法的工作原理如下:
1. 将图像分成8x8像素的块。
2. 对每个块进行DCT变换,将图像数据转换为频率分量。
3. 对DCT系数进行量化,丢弃高频分量。
4. 对量化后的系数进行编码,生成压缩后的图像数据。
**3.1.2 算法实现**
以下代码展示了如何使用Java实现JPEG压缩:
```java
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileOutputStream;
public class JPEGCompression {
public static void main(String[] args) throws Exception {
// 读取原始图像
BufferedImage originalImage = ImageIO.read(new File("original.jpg"));
// 创建JPEG输出流
FileOutputStream outputStream = new FileOutputStream("compressed.jpg");
// 使用ImageIO进行JPEG压缩
ImageIO.write(originalImage, "jpg", outputStream);
// 关闭输出流
outputStream.close();
}
}
```
### 3.2 MPEG算法
MPEG(Moving Picture Experts Group)算法是一种用于视频压缩的标准。它采用运动补偿和离散余弦变换(DCT)技术,可以有效地减少视频文件的大小。
**3.2.1 基本原理**
MPEG算法的工作原理如下:
1. 将视频分解为一系列帧。
2. 对相邻帧进行运动补偿,预测当前帧中的运动。
3. 对预测误差进行DCT变换,将图像数据转换为频率分量。
4. 对DCT系数进行量化和编码,生成压缩后的视频数据。
**3.2.2 算法实现**
以下代码展示了如何使用Java实现MPEG压缩:
```java
import javax.media.jai.JAI;
import javax.media.jai.PlanarImage;
import java.awt.image.RenderedImage;
import java.io.File;
import java.io.FileOutputStream;
public class MPEGCompression {
public static void main(String[] args) throws Exception {
// 读取原始视频
RenderedImage originalVideo = JAI.create("fileload", new File("original.mp4"));
// 创建MPEG输出流
FileOutputStream outputStream = new FileOutputStream("compressed.mp4");
// 使用JAI进行MPEG压缩
JAI.create("MPEGEncode", originalVideo).encode(outputStream);
// 关闭输出流
outputStream.close();
}
}
```
### 3.3 H.264算法
H.264(又称AVC)算法是一种用于视频压缩的高级标准。它采用先进的编码技术,可以实现更高的压缩率和更低的视频失真。
**3.3.1 基本原理**
H.264算法的工作原理如下:
1. 将视频分解为一系列帧。
2. 对相邻帧进行运动补偿,预测当前帧中的运动。
3. 对预测误差进行整数DCT变换,将图像数据转换为频率分量。
4. 对DCT系数进行量化和熵编码,生成压缩后的视频数据。
**3.3.2 算法实现**
以下代码展示了如何使用Java实现H.264压缩:
```java
import com.google.common.io.ByteStreams;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import org.bytedeco.ffmpeg.global.avcodec;
import org.bytedeco.ffmpeg.global.avutil;
import org.bytedeco.ffmpeg.libavcodec.AVCodec;
import org.bytedeco.ffmpeg.libavcodec.AVCodecContext;
import org.bytedeco.ffmpeg.libavformat.AVFormatContext;
import org.bytedeco.ffmpeg.libavformat.AVOutputFormat;
import org.bytedeco.ffmpeg.libavutil.AVFrame;
import org.bytedeco.ffmpeg.libavutil.AVPacket;
import org.bytedeco.ffmpeg.libavutil.AVRational;
public class H264Compression {
public static void main(String[] args) throws Exception {
// 读取原始视频
AVFormatContext inputFormatContext = new AVFormatContext(null);
avformat.avformat_open_input(inputFormatContext, "original.mp4", null, null);
// 创建H.264输出流
AVFormatContext outputFormatContext = new AVFormatContext(null);
avformat.avformat_alloc_output_context2(outputFormatContext, null, null, "compressed.mp4");
// 查找H.264编码器
AVCodec encoder = avcodec.avcodec_find_encoder(avcodec.AV_CODEC_ID_H264);
// 创建编码器上下文
AVCodecContext encoderContext = new AVCodecContext(null);
avcodec.avcodec_get_context_defaults3(encoderContext, encoder);
// 设置编码器参数
encoderContext.width(inputFormatContext.streams(0).width());
encoderContext.height(inputFormatContext.streams(0).height());
encoderContext.time_base(inputFormatContext.streams(0).time_base());
encoderContext.gop_size(10);
encoderContext.max_b_frames(0);
encoderContext.pix_fmt(avutil.AVPixelFormat.AV_PIX_FMT_YUV420P);
// 打开编码器
avcodec.avcodec_open2(encoderContext, encoder, null);
// 创建输出流
AVStream outputStream = outputFormatContext.new_stream(encoder);
outputStream.codecpar(encoderContext.parameters());
// 创建帧和数据包
AVFrame frame = new AVFrame();
AVPacket packet = new AVPacket();
// 压缩视频
while (avformat.av_read_frame(inputFormatContext, packet) >= 0) {
if (packet.stream_index() == 0) {
avcodec.avcodec_send_packet(encoderContext, packet);
while (avcodec.avcodec_receive_frame(encoderContext, frame) >= 0) {
avcodec.av_frame_make_writable(frame);
packet.pts(frame.pts());
packet.dts(frame.dts());
packet.duration(frame.pkt_duration());
packet.stream_index(0);
packet.size(frame.pkt_size());
avformat.av_packet_rescale_ts(packet, encoderContext.time_base(), outputStream.time_base());
avformat.av_interleaved_write_frame(outputFormatContext, packet);
}
}
av_packet.av_packet_unref(packet);
}
// 刷新编码器
avcodec.avcodec_send_frame(encoderContext, null);
while (avcodec.avcodec_receive_frame(encoderContext, frame) >= 0) {
avcodec.av_frame_make_writable(frame);
packet.pts(frame.pts());
packet.dts(frame.dts());
packet.duration(frame.pkt_duration());
packet.stream_index(0);
packet.size(frame.pkt_size());
avformat.av_packet_rescale_ts(packet, encoderContext.time_base(), outputStream.time_base());
avformat.av_interleaved_write_frame(outputFormatContext, packet);
}
// 关闭编码器和输出流
avcodec.avcodec_close(encoderContext);
avio.avio_close(outputFormatContext.pb());
// 释放资源
avformat.avformat_free_context(inputFormatContext);
avformat.avformat_free_context(outputFormatContext);
avutil.av_frame_free(frame);
avutil.av_packet_free(packet);
}
}
```
# 4. Java压缩算法实践**
**4.1 文件压缩和解压缩**
**4.1.1 使用ZipInputStream和ZipOutputStream**
ZipInputStream和ZipOutputStream是Java标准库中用于文件压缩和解压缩的类。使用它们,我们可以轻松地将多个文件压缩成一个ZIP存档,或将ZIP存档解压缩为单个文件。
```java
import java.io.*;
import java.util.zip.*;
public class FileCompression {
public static void compress(String source, String destination) throws IOException {
try (ZipOutputStream out = new ZipOutputStream(new FileOutputStream(destination))) {
try (FileInputStream in = new FileInputStream(source)) {
ZipEntry entry = new ZipEntry(source);
out.putNextEntry(entry);
byte[] buffer = new byte[1024];
int len;
while ((len = in.read(buffer)) > 0) {
out.write(buffer, 0, len);
}
}
}
}
public static void decompress(String source, String destination) throws IOException {
try (ZipInputStream in = new ZipInputStream(new FileInputStream(source))) {
ZipEntry entry;
while ((entry = in.getNextEntry()) != null) {
try (FileOutputStream out = new FileOutputStream(destination + File.separator + entry.getName())) {
byte[] buffer = new byte[1024];
int len;
while ((len = in.read(buffer)) > 0) {
out.write(buffer, 0, len);
}
}
}
}
}
}
```
**代码逻辑分析:**
* `compress()`方法:
* 使用`ZipOutputStream`创建ZIP存档。
* 遍历源文件,将每个文件写入存档。
* `decompress()`方法:
* 使用`ZipInputStream`读取ZIP存档。
* 遍历存档中的条目,将每个条目解压缩到目标目录。
**4.1.2 使用第三方库(如Apache Commons Compress)**
Apache Commons Compress是一个功能丰富的压缩库,提供了多种压缩算法和工具。我们可以使用它来简化文件压缩和解压缩的过程。
```java
import org.apache.commons.compress.archivers.zip.ZipArchiveEntry;
import org.apache.commons.compress.archivers.zip.ZipArchiveInputStream;
import org.apache.commons.compress.archivers.zip.ZipArchiveOutputStream;
public class FileCompressionWithCommonsCompress {
public static void compress(String source, String destination) throws IOException {
try (ZipArchiveOutputStream out = new ZipArchiveOutputStream(new FileOutputStream(destination))) {
try (FileInputStream in = new FileInputStream(source)) {
ZipArchiveEntry entry = new ZipArchiveEntry(source);
out.putArchiveEntry(entry);
byte[] buffer = new byte[1024];
int len;
while ((len = in.read(buffer)) > 0) {
out.write(buffer, 0, len);
}
out.closeArchiveEntry();
}
}
}
public static void decompress(String source, String destination) throws IOException {
try (ZipArchiveInputStream in = new ZipArchiveInputStream(new FileInputStream(source))) {
ZipArchiveEntry entry;
while ((entry = in.getNextZipEntry()) != null) {
try (FileOutputStream out = new FileOutputStream(destination + File.separator + entry.getName())) {
byte[] buffer = new byte[1024];
int len;
while ((len = in.read(buffer)) > 0) {
out.write(buffer, 0, len);
}
}
}
}
}
}
```
**代码逻辑分析:**
* `compress()`方法:
* 使用`ZipArchiveOutputStream`创建ZIP存档。
* 遍历源文件,将每个文件写入存档。
* `decompress()`方法:
* 使用`ZipArchiveInputStream`读取ZIP存档。
* 遍历存档中的条目,将每个条目解压缩到目标目录。
# 5. Java压缩算法性能优化
### 5.1 并行压缩
在处理海量数据时,并行压缩可以显著提高性能。Java提供了多种并行编程框架,如Fork/Join框架和线程池。
#### 5.1.1 使用Fork/Join框架
Fork/Join框架是一种基于分治思想的并行编程框架。它将任务分解为较小的子任务,并行执行这些子任务。在压缩场景中,我们可以将文件或数据流分解为多个块,并使用Fork/Join框架并行压缩这些块。
```java
// 使用Fork/Join框架并行压缩文件
public static void parallelCompress(String inputFile, String outputFile) {
// 创建Fork/Join任务
ForkJoinTask<Void> task = new RecursiveAction() {
@Override
protected void compute() {
// 如果文件大小小于阈值,则直接压缩
if (inputFile.length() < threshold) {
compress(inputFile, outputFile);
return;
}
// 将文件分为两部分
long mid = inputFile.length() / 2;
String leftFile = inputFile.substring(0, mid);
String rightFile = inputFile.substring(mid);
// 创建两个子任务
RecursiveAction leftTask = new RecursiveAction() {
@Override
protected void compute() {
parallelCompress(leftFile, leftFile + ".compressed");
}
};
RecursiveAction rightTask = new RecursiveAction() {
@Override
protected void compute() {
parallelCompress(rightFile, rightFile + ".compressed");
}
};
// 并行执行子任务
invokeAll(leftTask, rightTask);
// 合并压缩后的文件
merge(leftFile + ".compressed", rightFile + ".compressed", outputFile);
}
};
// 提交任务并等待完成
ForkJoinPool pool = new ForkJoinPool();
pool.invoke(task);
}
```
#### 5.1.2 使用线程池
线程池是一种管理线程的机制。它可以创建和管理一组线程,并根据需要分配线程来执行任务。在压缩场景中,我们可以使用线程池并行压缩多个文件或数据流。
```java
// 使用线程池并行压缩文件
public static void parallelCompress(String[] inputFiles, String outputDir) {
// 创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
// 创建任务列表
List<Callable<Void>> tasks = new ArrayList<>();
for (String inputFile : inputFiles) {
tasks.add(() -> {
String outputFile = outputDir + File.separator + inputFile + ".compressed";
compress(inputFile, outputFile);
return null;
});
}
// 提交任务并等待完成
executorService.invokeAll(tasks);
// 关闭线程池
executorService.shutdown();
}
```
### 5.2 缓存和预处理
缓存和预处理技术可以减少重复计算和数据访问时间,从而提高压缩性能。
#### 5.2.1 使用内存缓存
内存缓存是一种将经常访问的数据存储在内存中的技术。在压缩场景中,我们可以将压缩后的数据缓存到内存中,以避免重复压缩。
```java
// 使用内存缓存提高压缩性能
public static void compressWithCache(String inputFile, String outputFile) {
// 创建内存缓存
Map<String, byte[]> cache = new ConcurrentHashMap<>();
// 压缩文件
byte[] compressedData = compress(inputFile);
// 将压缩后的数据放入缓存
cache.put(inputFile, compressedData);
// 从缓存中获取压缩后的数据
byte[] cachedData = cache.get(inputFile);
// 写入压缩后的数据到输出文件
writeToFile(outputFile, cachedData);
}
```
#### 5.2.2 使用磁盘缓存
磁盘缓存是一种将经常访问的数据存储在磁盘上的技术。在压缩场景中,我们可以将压缩后的数据缓存到磁盘上,以避免重复压缩。
```java
// 使用磁盘缓存提高压缩性能
public static void compressWithDiskCache(String inputFile, String outputFile) {
// 创建磁盘缓存目录
File cacheDir = new File("cache");
cacheDir.mkdirs();
// 压缩文件
byte[] compressedData = compress(inputFile);
// 将压缩后的数据写入缓存文件
File cacheFile = new File(cacheDir, inputFile + ".compressed");
writeToFile(cacheFile, compressedData);
// 从缓存文件中读取压缩后的数据
byte[] cachedData = readFromFile(cacheFile);
// 写入压缩后的数据到输出文件
writeToFile(outputFile, cachedData);
}
```
### 5.3 算法选择
根据数据类型和压缩率要求选择合适的压缩算法至关重要。
#### 5.3.1 根据数据类型选择算法
不同的数据类型有不同的压缩特性。例如,文本数据适合使用无损压缩算法,而图像和视频数据适合使用有损压缩算法。
#### 5.3.2 根据压缩率和执行时间权衡
不同的压缩算法具有不同的压缩率和执行时间。在选择算法时,需要根据具体需求权衡压缩率和执行时间。例如,如果需要高压缩率,则可以选择压缩率较高的算法,但执行时间也会较长。
# 6. Java压缩算法应用场景
Java压缩算法在实际应用中有着广泛的应用场景,涵盖了数据存储和传输、多媒体处理以及备份和恢复等多个领域。
### 6.1 数据存储和传输
**6.1.1 数据库压缩**
数据库压缩通过对存储在数据库中的数据进行压缩,可以有效减少数据库文件的大小,从而降低存储成本和提高查询性能。例如,MySQL支持使用InnoDB引擎的压缩特性,可以对表中的数据进行透明压缩。
**6.1.2 网络传输优化**
在网络传输中,压缩算法可以减少数据的大小,从而提高传输速度和降低带宽消耗。例如,HTTP协议支持使用Gzip和Brotli等压缩算法,可以对Web页面和文件进行压缩传输。
### 6.2 多媒体处理
**6.2.1 图像和视频编辑**
图像和视频编辑软件通常使用压缩算法来减少文件大小,从而方便存储和传输。例如,JPEG和PNG是图像压缩的常用格式,而MPEG和H.264是视频压缩的常用格式。
**6.2.2 流媒体服务**
流媒体服务需要将视频和音频内容实时传输给用户。压缩算法可以减少内容的大小,从而降低带宽消耗和提高播放流畅度。例如,HLS和DASH流媒体协议支持使用多种压缩算法,如H.264和HEVC。
### 6.3 备份和恢复
**6.3.1 数据备份压缩**
数据备份压缩可以减少备份文件的大小,从而降低存储成本和加快备份速度。例如,Zip和Tar等压缩格式常用于备份文件和目录。
**6.3.2 数据恢复优化**
在数据恢复过程中,压缩算法可以减少损坏数据的体积,从而提高恢复效率和降低恢复成本。例如,一些数据恢复软件支持使用压缩算法来优化恢复过程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“最快的压缩算法 Java”深入探讨了 Java 压缩算法的方方面面,为开发者提供了全面且实用的指南。从性能对比到原理剖析,再到优化指南和常见问题解析,专栏全面覆盖了压缩技术的各个方面。此外,它还重点介绍了压缩算法在分布式系统、数据分析、图像处理、视频处理、音频处理、文本处理、网络传输、移动应用、物联网、金融科技、医疗保健、教育和娱乐等领域的应用。通过深入浅出的讲解和丰富的示例,专栏旨在帮助开发者掌握压缩技术,提升系统效率,优化资源利用,并改善用户体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MapReduce优化工具】:使用高级工具与技巧,提高处理速度与数据质量
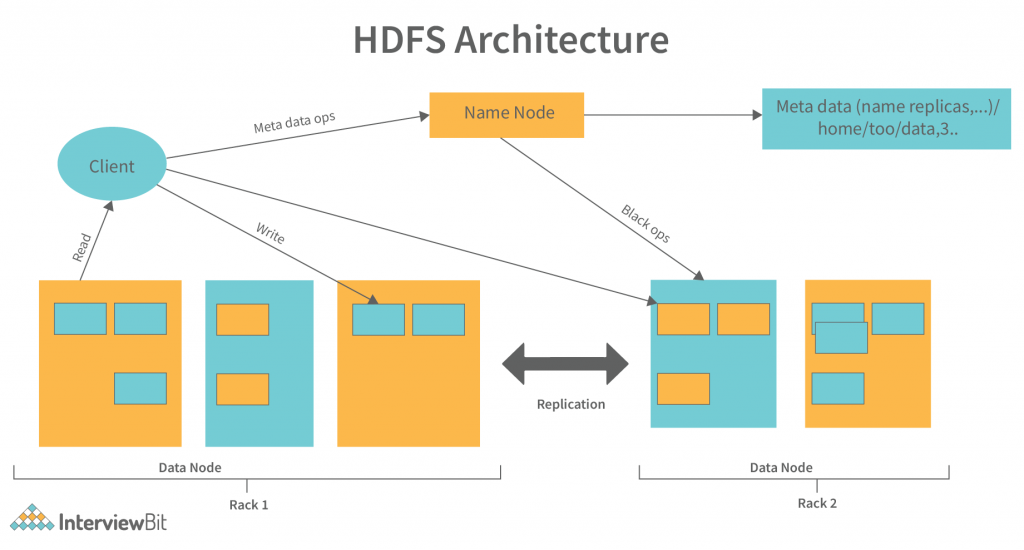
# 1. MapReduce优化工具概述
MapReduce是大数据处理领域的一个关键框架,随着大数据量的增长,优化MapReduce作业以提升效率和资源利用率已成为一项重要任务。本章节将引入MapReduce优化工具的概念,涵盖各种改进MapReduce执行性能和资源管理的工具与策略。这不仅包括Hadoop生态内的工具,也包括一些自定义开发的解决方案,旨在帮助
系统不停机的秘诀:Hadoop NameNode容错机制深入剖析
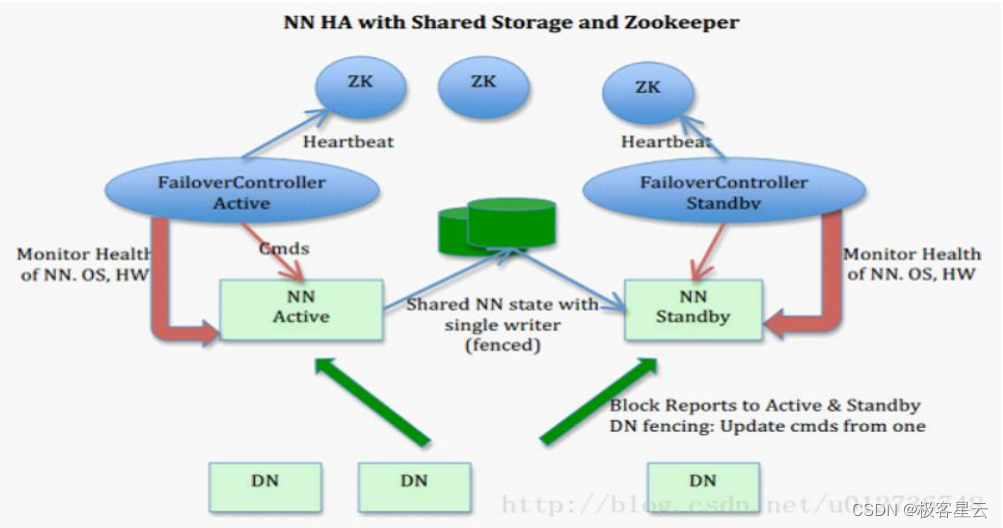
# 1. Hadoop NameNode容错机制概述
在分布式存储系统中,容错能力是至关重要的特性。在Hadoop的分布式文件系统(HDFS)中,NameNode节点作为元数据管理的中心点,其稳定性直接影响整个集群的服务可用性。为了保障服务的连续性,Hadoop设计了一套复杂的容错机制,以应对硬件故障、网络中断等潜在问题。本章将对Hadoop NameNode的容错机制进行概述,为理解其细节
MapReduce在云计算与日志分析中的应用:优势最大化与挑战应对
# 1. MapReduce简介及云计算背景
在信息技术领域,云计算已经成为推动大数据革命的核心力量,而MapReduce作为一种能够处理大规模数据集的编程模型,已成为云计算中的关键技术之一。MapReduce的设计思想源于函数式编程中的map和reduce操作,它允许开发者编写简洁的代码,自动并行处理分布在多台机器上的大量数据。
云计算提供了一种便捷的资源共享模式,让数据的存储和计算不再受物理硬件的限制,而是通过网络连接实现资源的按需分配。通过这种方式,MapReduce能够利用云计算的弹性特性,实现高效的数据处理和分析。
本章将首先介绍MapReduce的基本概念和云计算背景,随后探
【MapReduce故障诊断】:快速定位问题,确保作业稳定运行

# 1. MapReduce故障诊断概览
MapReduce作为大数据处理领域的一种编程模型和处理框架,在分布式计算领域拥有广泛的应用。然而,在实际的业务运行中,MapReduce也会因为各种原因遭遇故障。故障诊断对于快速定位问题并恢复正常运行至关重要。本章
HDFS写入数据IO异常:权威故障排查与解决方案指南

# 1. HDFS基础知识概述
## Hadoop分布式文件系统(HDFS)简介
Hadoop分布式文件系统(HDFS)是Hadoop框架中的核心组件之一,它设计用来存储大量数据集的可靠存储解决方案。作为一个分布式存储系统,HDFS具备高容错性和流数据访问模式,使其非常适合于大规模数据集处理的场景。
## HDFS的优势与应用场景
HDFS的优
HDFS数据本地化:优化datanode以减少网络开销

# 1. HDFS数据本地化的基础概念
## 1.1 数据本地化原理
在分布式存储系统中,数据本地化是指尽量将计算任务分配到存储相关数据的节点上,以此减少数据在网络中的传输,从而提升整体系统的性能和效率。Hadoop的分布式文件系统HDFS采用数据本地化技术,旨在优化数据处理速度,特别是在处理大量数据时,可以显著减少延迟,提高计算速度。
## 1
数据完整性校验:Hadoop NameNode文件系统检查的全面流程
# 1. Hadoop NameNode数据完整性概述
Hadoop作为一个流行的开源大数据处理框架,其核心组件NameNode负责管理文件系统的命名空间以及维护集群中数据块的映射。数据完整性是Hadoop稳定运行的基础,确保数据在存储和处理过程中的准确性与一致性。
在本章节中,我们将对Hadoop NameNode的数据完
HDFS数据上传与查询安全攻略:权限配置与管理的终极技巧

# 1. HDFS基础与数据安全概述
在当今的大数据时代,Hadoop分布式文件系统(HDFS)成为存储海量数据的关键技术。本章节首先介绍HDFS的基本概念和架构,然后探讨与数据安全相关的核心问题。我们从HDFS的基础知识开始,逐步深入到数据安全性的挑战和解决方案。
## HDFS基本概念和架构
HDFS是一种为高吞吐量和大数据存储而优化的分布式文件系统。它被设计为
数据同步的守护者:HDFS DataNode与NameNode通信机制解析
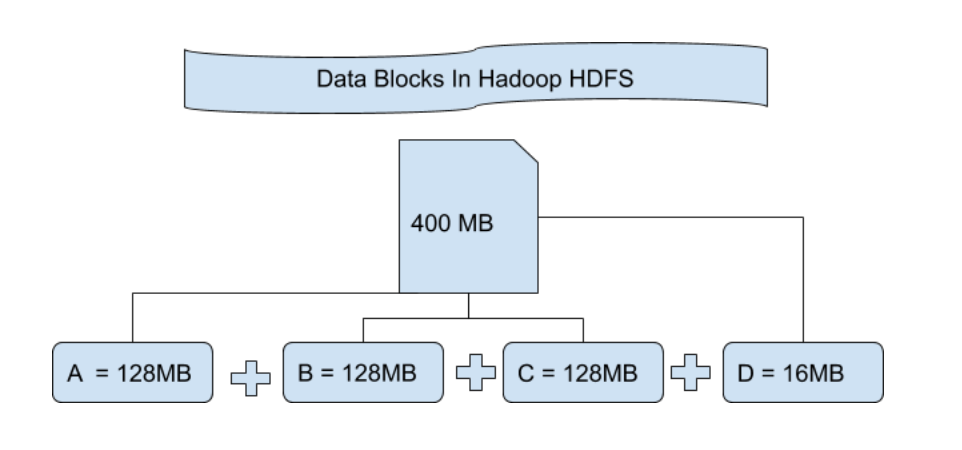
# 1. HDFS架构与组件概览
## HDFS基本概念
Hadoop分布式文件系统(HDFS)是Hadoop的核心组件之一,旨在存储大量数据并提供高吞吐量访问。它设计用来运行在普通的硬件上,并且能够提供容错能力。
## HDFS架构组件
- **NameNode**: 是HDFS的主服务器,负责管理文件系统的命名空间以及客户端对文件的访问。它记录了文
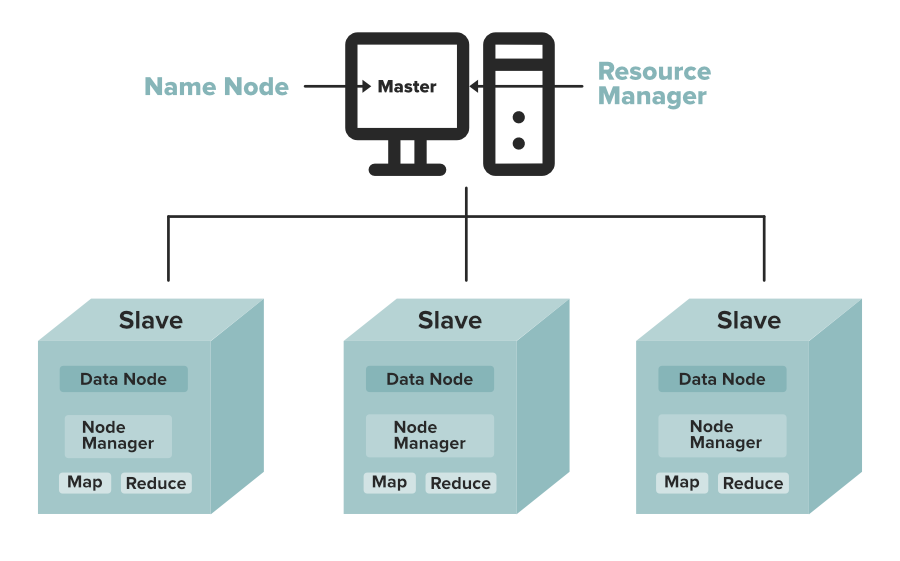
Hadoop资源管理与数据块大小:YARN交互的深入剖析
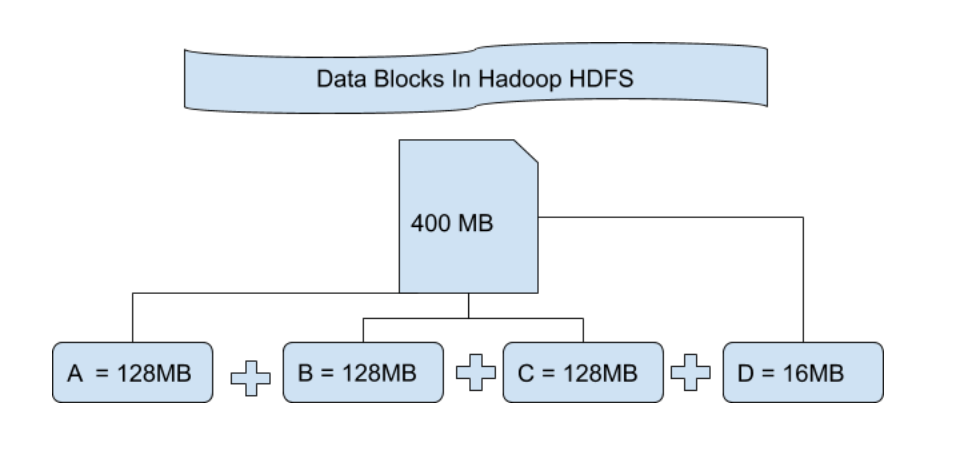
# 1. Hadoop资源管理概述
在大数据的生态系统中,Hadoop作为开源框架的核心,提供了高度可扩展的存储和处理能力。Hadoop的资源管理是保证大数据处理性能与效率的关键技术之一。本章旨在概述Hadoop的资源管理机制,为深入分析YARN架构及其核心组件打下基础。我们将从资源管理的角度探讨Hadoop的工作原理,涵盖资源的分配、调度、监控以及优化策略,为读者提供一个全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )