Ubuntu系统监控与日志分析:实时掌握系统状态的实用技巧
发布时间: 2024-12-12 09:10:07 阅读量: 9 订阅数: 12 

UbuntuLinux操作系统实用教程-PPT.zip
# 1. Ubuntu系统监控概述
在现代信息技术领域,系统的稳定运行直接关系到业务的连续性和数据的安全性。Ubuntu系统,作为最流行的Linux发行版之一,其监控的重要性不言而喻。监控不仅能帮助系统管理员及时发现并解决问题,还能通过性能分析优化系统资源配置,保证服务的高可用性。
## 1.1 为什么进行系统监控
在面对复杂的网络环境和多变的业务需求时,监控系统可以确保IT基础设施的稳定运行。系统监控可以实时获取系统状态信息,及时发现资源瓶颈和潜在的故障,从而在问题扩大之前进行干预,减少系统停机时间,保证用户的良好体验。
## 1.2 Ubuntu系统监控的基本概念
监控Ubuntu系统通常涉及多个层面,包括硬件资源的监控(CPU、内存、磁盘、网络等)、系统服务状态、进程性能以及安全性。这些监控任务可以手动执行,也可以借助于各种自动化工具来实现,比如Nagios、Zabbix、Prometheus等。
## 1.3 监控工具的选择与应用
根据不同的监控需求和环境,系统管理员需要选择合适的监控工具。对于Ubuntu系统而言,开源工具因其灵活性和可扩展性受到了广泛欢迎。工具的选择和应用应当基于系统架构、监控目标和团队的技术能力等多方面因素进行考虑。
通过本章的介绍,您将对Ubuntu系统监控的必要性有一个初步的认识,并对监控的基本概念有清晰的理解。接下来,我们将深入探讨系统性能监控的理论与实践,以及如何利用各种工具对系统进行高效监控。
# 2. 系统性能监控理论与实践
## 2.1 系统性能监控基础
### CPU和内存监控
在系统性能监控中,CPU和内存的监控是基础环节,它们是保证系统稳定运行的关键资源。为了有效地监控CPU和内存,我们需要理解它们的工作原理和监控指标。
CPU监控指标通常包括:CPU使用率、上下文切换次数、中断次数、系统等待时间等。通过观察这些指标,我们可以判断CPU资源是否过度消耗,是否存在性能瓶颈。比如,`top`命令可以实时显示CPU的使用情况:
```bash
top
```
输出示例:
```
top - 13:33:09 up 1:15, 1 user, load average: 0.45, 0.32, 0.34
Tasks: 211 total, 1 running, 210 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16265244 total, 9311208 free, 2139140 used, 4814896 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 13933924 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2535 root 20 0 616304 16948 9400 S 1.0 0.1 0:05.10 Xorg
```
内存监控则关注内存的使用量、缓存和缓冲区的大小、以及交换空间(swap)的使用情况。`free -m`命令可以显示内存和交换空间的使用情况:
```bash
free -m
```
输出示例:
```
total used free shared buff/cache available
Mem: 15915 13906 996 464 9992 13258
Swap: 2047 0 2047
```
通过观察`free`命令的输出,我们可以看出系统内存的使用趋势,特别是在高负载情况下,交换空间的使用是否显著上升,这可能是内存不足的一个信号。
### 磁盘I/O和网络监控
磁盘I/O和网络的监控同样重要,它们影响到数据的读写速度和网络传输效率,对于系统的整体性能有着直接的影响。
磁盘I/O监控包括读写速率、IOPS(每秒读写次数)、队列长度等。`iostat`是一个常用的命令行工具,可以监控磁盘的读写性能:
```bash
iostat -x 1
```
输出示例:
```
avg-cpu: %user %nice %system %iowait %steal %idle
4.42 0.00 2.67 1.44 0.00 91.47
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 2.40 0.80 13.80 15.20 264.80 38.53 0.33 22.32 7.00 23.31 1.43 2.04
```
而网络监控则关注数据包发送和接收的数量、错误率、流量等。`netstat`可以用来显示网络连接、路由表等信息:
```bash
netstat -i
```
输出示例:
```
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
lo 65536 0 0 0 0 0 0 0 0 LRU
eth0 1500 258577 0 0 0 290223 0 0 0 BMRU
```
对网络接口的监控能够及时发现网络问题,如高丢包率(RX-DRP、TX-DRP)和超时重传(RX-OVR、TX-OVR),这些都可能预示着网络性能问题或配置错误。
## 2.2 高级性能分析工具
### top和htop工具的使用
`top`和`htop`是两个强大的系统监控工具,它们提供实时的系统运行状态,包括进程的资源使用情况。`top`是较为传统的监控工具,而`htop`则是`top`的增强版,提供更友好的用户界面和更丰富的功能。
使用`top`命令,我们可以看到按CPU和内存使用排序的进程列表,这对于快速发现资源占用高的进程非常有用。然而,`top`的输出信息较多,初次使用可能需要一段时间来适应。
`htop`提供了一个彩色的、动态更新的进程列表,并且支持交互式操作,比如可以直接结束进程或者调整进程的优先级。这些功能使`htop`成为性能分析和故障排查的有力工具。
在`htop`中,可以通过按`F2`进入设置菜单,调整一些显示选项,比如设置哪些列显示,设置更新的频率等。使用`F10`退出`htop`。
### vmstat和iostat的进阶应用
`vmstat`(虚拟内存统计)和`iostat`是两个专注于系统性能监控的命令行工具,它们提供关于系统内存、进程、CPU、I/O等状态的详细报告。
`vmstat`命令可以显示关于系统内存使用情况的简短总结,包括:虚拟内存、内核线程、磁盘、系统进程、I/O块设备和CPU活动的统计信息。例如:
```bash
vmstat 1
```
输出示例:
```
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 899148 48904 364764 0 0 4 4 35 85 1 1 98 0 0
0 0 0 899148 48904 364764 0 0 0 0 25 66 0 0 100 0 0
```
`iostat`提供磁盘I/O以及CPU使用率的详细报告。在监控中,我们可以利用`iostat`来检测I/O瓶颈,或者监控特定设备的性能。例如:
```bash
iostat -x /dev/sda 1
```
输出示例:
```
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 2.40 0.80 13.80 15.20 264.80 38.53 0.33 22.32 7.00 23.31 1.43 2.04
```
`iostat`对于存储管理员来说是一个非常有用的工具,它能帮助他们监控整个磁盘I/O的使用情况,找出瓶颈所在。
## 2.3 性能监控的数据分析
### 识别性能瓶颈
性能瓶颈是影响系统运行效率的那些缓慢或过载的组件。要识别性能瓶颈,我们需要了解每个组件的性能指标,并通过监控这些指标来判断是否存在瓶颈。
一般来说,CPU瓶颈会表现为CPU使用率长时间接近100%。对于内存,可以通过查看`free`命令输出来确定是否需要添加更多内存或优化内存使用。磁盘I/O瓶颈则可以通过`iostat`观察到大量的读写操作(r/s和w/s)、高I/O等待时间(await)和高

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Ubuntu 使用心得与技巧》专栏汇集了全面的 Ubuntu 指南,涵盖了从优化系统性能到个性化桌面环境的各个方面。专栏内容包括:
* 优化策略:7 个步骤提升系统性能
* 软件管理:解决依赖性问题
* 故障诊断:3 步定位并解决问题
* 桌面环境定制:打造个性化工作空间
* 备份与恢复:保障数据安全
* 内核定制:按需优化系统内核
* 启动项优化:提升系统启动速度
本专栏旨在帮助 Ubuntu 用户充分利用其系统的强大功能,提高效率并解决常见问题。无论是新手还是经验丰富的用户,都能从中找到有价值的信息和实用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VC709开发板原理图进阶】:深度剖析FPGA核心组件与性能优化(专家视角)

# 摘要
本论文首先对VC709开发板进行了全面概述,并详细解析了其核心组件。接着,深入探讨了FPGA的基础理论及其架构,包括关键技术和设计工具链。文章进一步分析了VC709开发板核心组件,着重于FPGA芯片特性、高速接口技术、热管理和电源设计。此外,本文提出了针对VC709性能优化
IP5306 I2C同步通信:打造高效稳定的通信机制

# 摘要
本文系统地阐述了I2C同步通信的基础原理及其在现代嵌入式系统中的应用。首先,我们介绍了IP5306芯片的功能和其在同步通信中的关键作用,随后详细分析了实现高效稳定I2C通信机制的关键技术,包括通信协议解析、同步通信的优化策略以及IP5306与I2C的集成实践。文章接着深入探讨了IP5306 I2C通信的软件实现,涵盖软件架
Oracle数据库新手指南:DBF数据导入前的准备工作
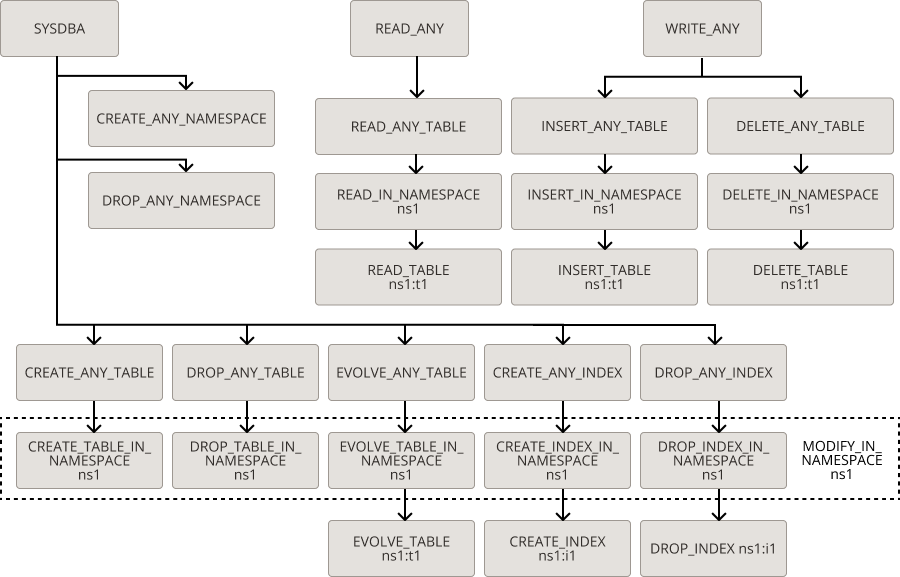
# 摘要
本文旨在详细介绍Oracle数据库的基础知识,并深入解析DBF数据格式及其结构,包括文件发展历程、基本结构、数据类型和字段定义,以及索引和记录机制。同时,本文指导读者进行环境搭建和配置,包括Oracle数据库软件安装、网络设置、用户账户和权限管理。此外,本文还探讨了数据导入工具的选择与使用方法,介绍了SQL
FSIM对比分析:图像相似度算法的终极对决
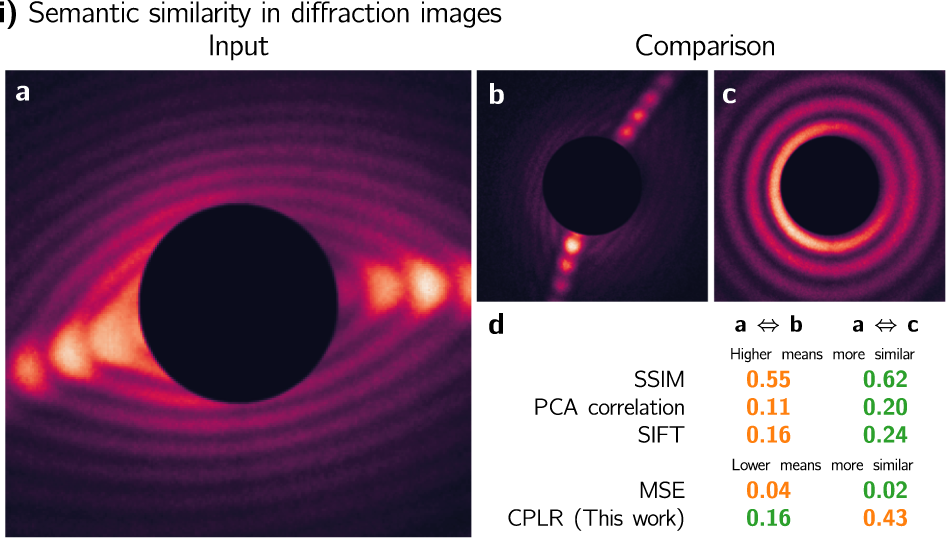
# 摘要
本文首先概述了图像相似度算法的发展历程,重点介绍了FSIM算法的理论基础及其核心原理,包括相位一致性模型和FSIM的计算方法。文章进一步阐述了FSIM算法的实践操作,包括实现步骤和性能测试,并探讨了针对特定应用场景的优化技巧。在第四章中,作者对比分析了FSIM与
应用场景全透视:4除4加减交替法在实验报告中的深度分析
# 摘要
本文综合介绍了4除4加减交替法的理论和实践应用。首先,文章概述了该方法的基础理论和数学原理,包括加减法的基本概念及其性质,以及4除4加减交替法的数学模型和理论依据。接着,文章详细阐述了该方法在实验环境中的应用,包括环境设置、操作步骤和结果分析。本文还探讨了撰写实验报告的技巧,包括报告的结构布局、数据展示和结论撰写。最后,通过案例分析展示了该方法在不同领域的应用,并对实验报告的评价标准与质量提升建议进行了讨论。本文旨在
电子设备冲击测试必读:IEC 60068-2-31标准的实战准备指南
# 摘要
IEC 60068-2-31标准为冲击测试提供了详细的指导和要求,涵盖了测试的理论基础、准备策划、实施操作、标准解读与应用、以及提升测试质量的策略。本文通过对冲击测试科学原理的探讨,分类和方法的分析,以及测试设备和工具的选择,明确了测试的执行流程。同时,强调了在测试前进行详尽策划的重要性,包括样品准备、测试计划的制定以及测试人员的培训。在实际操作中,本
【神经网络】:高级深度学习技术提高煤炭价格预测精度

# 摘要
随着深度学习技术的飞速发展,该技术已成为预测煤炭价格等复杂时间序列数据的重要工具。本文首先介绍了深度学习与煤炭价格预测的基本概念和理论基础,包括神经网络、损失函数、优化器和正则化技术。随后,文章详细探讨了深度学习技术在煤炭价格预测中的具体应用,如数据预处理、模型构建与训练、评估和调优策略。进一步,本文深入分析了高级深度学习技术,包括卷积神经网络(CNN)、循环神经网络(RNN)和长
电子元器件寿命预测:JESD22-A104D温度循环测试的权威解读
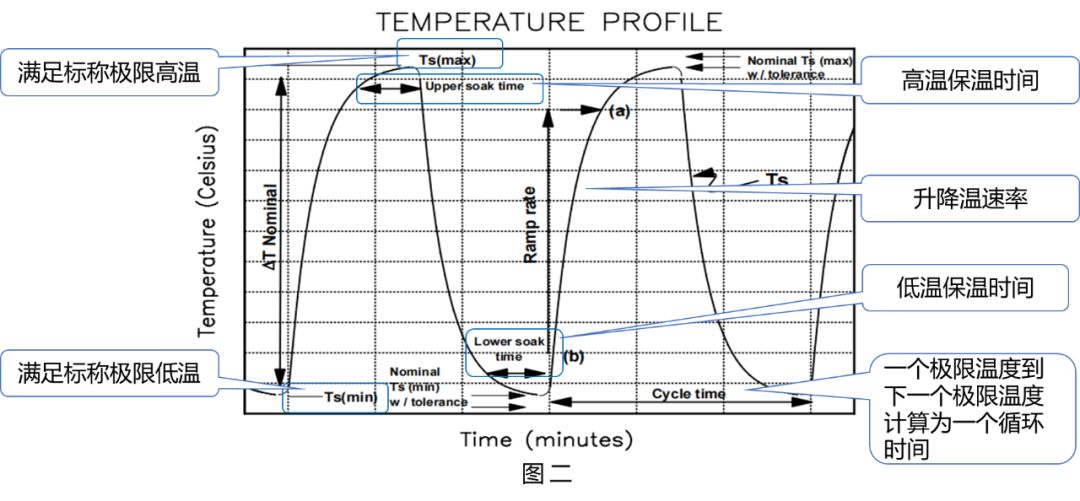
# 摘要
电子元器件在各种电子设备中扮演着至关重要的角色,其寿命预测对于保证产品质量和可靠性至关重要。本文首先概述了电子元器件寿命预测的基本概念,随后详细探讨了JESD22-A104D标准及其测试原理,特别是温度循环测试的理论基础和实际操作方法。文章还介绍了其他加速老化测试方法和寿命预测模型的优化,以及机器学习技术在预测中的应用。通过实际案例分析,本文深入讨论了预测模型的建立与验证。最后,文章展望了未来技术创新、行
【数据库连接池详解】:高效配置Oracle 11gR2客户端,32位与64位策略对比
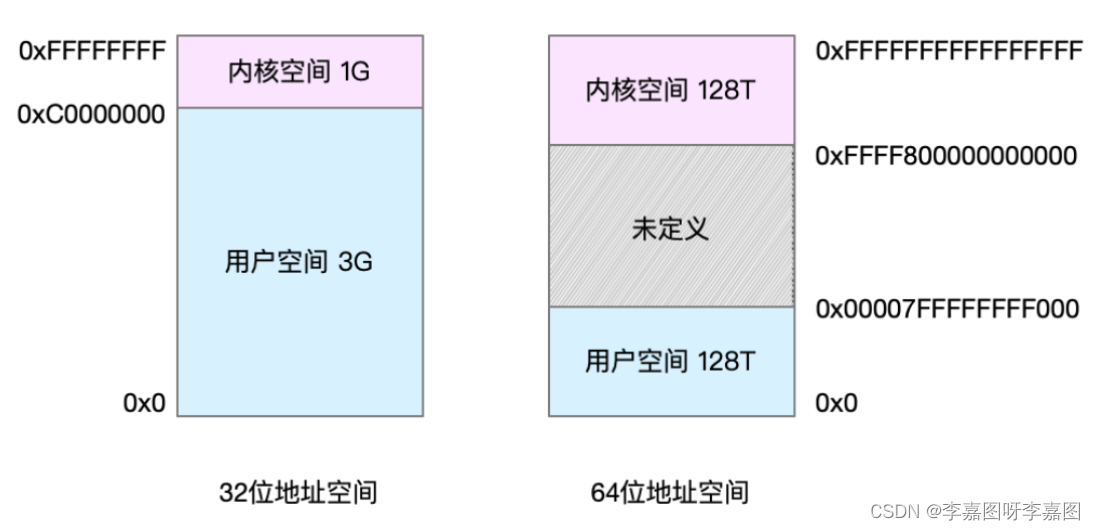
# 摘要
本文对Oracle 11gR2数据库连接池的概念、技术原理、高效配置、不同位数客户端策略对比,以及实践应用案例进行了系统的阐述。首先介绍了连接池的基本概念和Oracle 11gR2连接池的技术原理,包括其架构、工作机制、会话管理、关键技术如连接复用、负载均衡策略和失效处理机制。然后,文章转向如何高效配置Oracle 11gR2连接池,涵盖环境准备、安装步骤、参数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )