Ubuntu系统故障排查速成课:全面掌握从崩溃到安全的诊断艺术
发布时间: 2024-12-11 23:28:53 阅读量: 7 订阅数: 11 

精通Ubuntu系统服务管理:从入门到精通

# 1. Ubuntu系统故障排查概述
在信息时代,Linux系统尤其是Ubuntu以其开源性、稳定性和安全性,在服务器和桌面市场中占据了一席之地。然而,面对复杂的系统环境和不断更新的技术,系统故障在所难免。本章节将概述Ubuntu系统故障排查的基本流程和常用方法,为读者提供一种系统化的故障处理思路。
Ubuntu系统故障排查不仅仅是技术操作,更是对系统原理的深入理解和对问题根源的精确诊断。在开始实际的故障诊断之前,理解系统的工作原理、掌握故障排查的基本原则和方法是至关重要的。通过对系统架构和启动流程的分析,我们可以发现许多问题的征兆,例如配置错误或服务故障。
此外,本章还将介绍一些实用的故障诊断工具,包括但不限于日志分析工具、性能监控工具以及一些专门的故障排查命令。使用这些工具,我们可以更快速地定位问题所在,并采取相应的解决方案。在本章的最后,我们将通过几个典型的故障排查案例,来展示故障排查的实际操作过程,为后续章节中更深层次的故障分析打下基础。
# 2. 故障诊断前的理论准备
### 2.1 理解系统的工作原理
#### 2.1.1 Ubuntu系统架构简介
Ubuntu 系统是基于 Linux 内核的开源操作系统,它包括了庞大的软件集合。Ubuntu 系统架构由多个层次组成,其核心是 Linux 内核,负责管理系统资源,如 CPU、内存以及各种硬件设备。内核之上是系统库和运行时环境,这包括了像 glibc 这样的核心库和如 Python、Java 等语言的运行时环境。接着是应用框架层,例如 GNOME 或 KDE,这些框架提供了构建用户界面的标准工具集。最上层是应用软件层,这是用户直接交互的层,包括办公套件、浏览器、媒体播放器等。
系统架构的理解是故障排查的基础,因为不同层次的故障表现形式和解决方法都不尽相同。例如,内核级别的问题往往与硬件直接相关,而应用软件层次的问题则可能是软件本身的错误或配置不当所致。
#### 2.1.2 系统启动流程分析
Ubuntu 的启动流程包括了从计算机加电到系统完全启动完成的一系列步骤,这些步骤大致可以分为五个阶段:
1. BIOS 加电自检(POST):计算机硬件的自我检测。
2. 引导加载(Bootloader):GRUB(GRand Unified Bootloader)加载内核。
3. 内核初始化:内核开始初始化硬件设备,并且挂载根文件系统。
4. initrd 过渡:使用初始内存磁盘(initrd)加载必要的驱动程序。
5. 系统服务启动:执行系统初始化脚本,启动各种系统服务。
每个阶段都有可能出现故障,所以理解这一流程对于有效诊断问题至关重要。例如,如果在第二阶段 GRUB 阶段出现问题,可能是因为 GRUB 配置文件损坏或错误配置导致无法正确加载内核。如果问题出现在第五阶段,则可能是服务脚本配置错误或者依赖关系缺失。
### 2.2 故障排查的基本原则和方法
#### 2.2.1 故障排查的五大原则
故障排查是一个系统化的过程,为了高效准确地找出问题所在,我们应遵循以下五大原则:
1. **最小化测试环境**:在尽可能小的环境中重复问题,这有助于缩小问题范围。
2. **逐步测试**:分步骤进行测试,逐步排除系统中可能的故障点。
3. **记录故障现象**:详细记录故障的表现、发生时间和持续时间等信息,有利于快速定位问题。
4. **控制变量法**:改变单个变量,观察系统的变化,以确定问题所在。
5. **验证解决方案**:在实施解决方案后,必须再次测试以验证问题是否已经解决。
#### 2.2.2 常用的故障诊断工具和技术
在排查故障时,下面这些工具和技术是非常实用的:
- **dmesg**:用于查看内核的环形缓冲区信息,这对于诊断系统启动时的问题非常有用。
- **journalctl**:用于查询和显示系统日志文件内容。
- **/var/log/**:系统日志文件存放目录,针对不同服务和应用有不同的日志文件。
- **strace**:用于跟踪程序运行时的系统调用和接收到的信号,常用于定位应用程序故障。
- **netstat** 和 **ss**:用于查看网络连接、路由表、接口状态等信息,这对于网络相关问题非常有帮助。
- **tcpdump** 和 **wireshark**:用于捕获和分析网络流量,是网络故障排查中不可或缺的工具。
通过运用这些工具,可以收集到系统运行过程中的关键信息,帮助快速定位故障。例如,使用 `dmesg` 可以发现与硬件相关的错误信息,而 `journalctl` 可以提供系统服务的日志详情,从而对服务状态进行诊断。
故障排查是一个需要耐心和细致的工作,只有透彻理解了系统的工作原理和掌握了有效的排查方法,才能在面对复杂问题时做出快速而准确的反应。在本章节中,我们通过介绍 Ubuntu 系统架构和启动流程,以及故障排查的原则和工具,为读者奠定了理论基础,接下来我们将进入具体的故障排查实践。
# 3. 启动过程中的故障排查
启动过程中的故障排查对于确保系统的稳定性至关重要。在这一部分,我们将深入探讨在启动阶段遇到的问题,并提供有效的诊断和修复策略。
## 3.1 启动阶段的故障诊断
### 3.1.1 GRUB引导加载器问题解决
GRUB是Linux系统的默认引导加载器,它负责引导操作系统。当GRUB出现问题时,系统将无法正确引导,因此了解如何诊断和修复GRUB故障至关重要。
1. **问题识别**:首先,需要识别问题是否与GRUB有关。如果系统启动时出现"GRUB loading"后系统无响应或无法进入菜单,这可能是GRUB问题的一个信号。
2. **启动恢复盘**:使用Ubuntu启动恢复盘或live CD启动系统,以便可以访问一个已经安装好的系统环境。
3. **挂载根文件系统**:将出现问题的系统根分区挂载到一个安全的位置。例如:
```bash
sudo mount /dev/sda1 /mnt
```
4. **修复GRUB安装**:然后,可以通过chroot命令进入系统,并运行grub-install和update-grub命令修复GRUB。例如:
```bash
sudo grub-install /dev/sda
sudo update-grub
```
5. **检查配置文件**:GRUB的配置文件位于`/boot/grub/grub.cfg`,但不应该直接编辑它。需要修改的配置应该放在`/etc/default/grub`中,然后再次运行update-grub生成新的grub.cfg。
6. **重新启动**:完成以上步骤后,退出chroot环境并重启系统。
### 3.1.2 内核故障排除技巧
内核是操作系统的核心部分,负责管理计算机硬件资源和提供程序运行所需的服务。当内核出现故障时,系统可能无法启动。
1. **启动参数**:在GRUB菜单中,可以尝试添加特定的启动参数来绕过问题,例如使用`acpi=off`或`nomodeset`来解决硬件兼容性问题。
2. **内核恢复模式**:如果系统能够进入内核恢复模式,这可以提供一个命令行环境来进一步诊断问题。在该模式下,可以检查系统日志或尝试修复文件系统。
3. **备选内核**:如果当前使用的内核版本出现问题,可以尝试引导到较旧的内核版本。GRUB菜单通常会列出可用的内核版本,选择一个备选内核进行启动。
4. **重新编译内核**:如果问题与特定的内核功能相关,可以尝试重新编译内核,排除可能引起问题的模块。
5. **系统日志分析**:检查`/var/log/dmesg`日志文件,它包含了内核启动时的信息。错误信息可能会提供故障的线索。
## 3.2 系统服务与运行级别
系统服务和运行级别的概念是启动故障排查中不可忽视的部分。以下是关于系统服务管理原理和运行级别调整的相关内容。
### 3.2.1 系统服务管理原理
系统服务是指在Linux系统启动时自动启动的程序,它们为用户提供各种服务。
1. **服务管理工具**:大多数Linux发行版都使用Systemd作为其初始化系统。使用`systemctl`命令可以管理服务。例如,列出所有服务状态:
```bash
systemctl list-units --type=service
```
2. **服务启动类型**:Systemd允许设置服务的启动类型(开机自动启动、手动启动、禁用等)。例如:
```bash
systemctl enable <service_name> # 开机自动启动
systemctl disable <service_name> # 禁用开机自动启动
```
3. **服务状态**:检查特定服务的状态和配置可以使用:
```bash
systemctl status <service_name>
systemctl show <service_name>
```
### 3.2.2 运行级别调整与故障应对
运行级别定义了系统启动时的不同环境,它们允许系统管理员针对不同的使用场景启动特定的服务组合。
1. **运行级别简介**:传统的SysV init脚本使用0-6的数字来代表不同的运行级别,而Systemd则使用目标(target)来代替运行级别。
2. **查看当前目标**:要查看当前系统正在运行的目标,可以使用:
```bash
systemctl list-units --type=target
```
3. **切换目标**:要切换到不同的运行级别,可以使用`systemctl isolate <target_name>`命令。例如,切换到紧急模式:
```bash
systemctl isolate emergency.target
```
4. **故障排查**:如果系统无法正常启动到特定的运行级别,可能需要检查相关的服务是否正确配置并处于启用状态。
通过以上内容,我们了解了Ubuntu启动阶段故障排查的基本方法。这些步骤不仅涵盖了从引导加载器到内核以及服务和运行级别的基础问题,还提供了操作指南和故障处理策略。这些知识将帮助IT从业者有效地诊断和解决启动过程中的各种故障。
# 4. ```
# 第四章:运行中的系统故障排查
随着Ubuntu系统安装完成并成功启动,IT专业人员往往需要面对系统运行时出现的各种问题。此类问题可能导致服务中断、性能下降,甚至数据丢失,因此,及时、准确地诊断并修复运行中的系统故障显得至关重要。本章将深入探讨内存和进程管理、文件系统和磁盘问题的故障排查方法。
## 4.1 内存和进程管理
内存和进程管理是保证系统稳定运行的关键。内存泄漏和进程异常终止是较为常见的问题,它们不仅影响系统的运行效率,还可能导致系统崩溃。
### 4.1.1 内存泄漏的检测与解决
内存泄漏是指程序在分配内存后,未能在不再需要时释放,从而导致内存资源的不断消耗。长时间运行后,内存泄漏可能会导致系统可用内存量持续减少,直至耗尽。
#### 诊断工具:Valgrind
使用Valgrind是检测内存泄漏的常用方法。Valgrind是一个开源的内存调试工具集,可以用来检测C、C++以及其他语言编写的程序中的内存问题。
```bash
valgrind --leak-check=full --show-leak-kinds=all ./your_program
```
上述命令中,`--leak-check=full` 参数告诉Valgrind提供完整的内存泄漏信息,`--show-leak-kinds=all` 参数则要求显示所有类型的内存泄漏。执行完毕后,Valgrind会输出详细的内存泄漏报告。
#### 修复内存泄漏
修复内存泄漏通常需要对程序代码进行审查和修改。程序员需要检查哪些分配的内存没有被正确释放,并在适当的时候添加释放内存的代码。以下是一段示例代码,展示了如何在C语言中正确分配和释放内存:
```c
int main() {
int *array = malloc(sizeof(int) * 10); // 分配内存
// ... 使用内存的代码
free(array); // 释放内存
return 0;
}
```
### 4.1.2 进程异常终止的分析与修复
进程异常终止可能是由于程序中存在错误,如除零错误、无效指针引用等。这些错误通常会导致程序立即退出,甚至系统出现段错误(segmentation fault)。
#### 使用`coredump`分析
当进程异常终止时,系统可以生成一个`core`文件,其中包含了进程终止时的内存映像和其他调试信息。通过分析`core`文件,开发者可以了解导致进程终止的具体原因。
```bash
ulimit -c unlimited # 允许生成core文件
```
执行上述命令后,当进程异常终止时,系统将会生成`core`文件。使用`gdb`等调试工具可以对`core`文件进行分析:
```bash
gdb /path/to/your_program /path/to/core_file
```
在`gdb`的交互式环境中,可以使用`bt`(backtrace)命令查看调用栈信息,找到导致进程崩溃的确切位置。
#### 修复进程异常终止
修复进程异常终止的问题通常需要程序员对相关代码进行调试和修改。修复手段包括处理潜在的错误、增加异常处理代码,以及优化算法以避免可能导致崩溃的操作。
## 4.2 文件系统和磁盘问题
文件系统是操作系统中负责管理和存储文件的部分,它对数据的完整性至关重要。磁盘问题包括文件系统损坏、磁盘性能下降或物理故障等。
### 4.2.1 文件系统的检查与修复
文件系统错误可能是由意外断电、硬件故障或软件缺陷引起的。定期检查和修复文件系统是确保数据完整性的必要步骤。
#### 使用`fsck`工具
`fsck`(File System Consistency Check)是一个用于检查和修复Linux文件系统的工具。在系统启动时或单用户模式下,可以通过`fsck`对文件系统进行全面检查。
```bash
sudo fsck /dev/sda1
```
上述命令将对`/dev/sda1`分区执行检查。如果检测到错误,`fsck`将提示用户选择是否修复。
#### 文件系统修复过程
当`fsck`报告有错误时,它通常可以修复大部分问题。但是,对于一些复杂的文件系统错误,可能需要更为谨慎的处理,例如使用日志文件系统(如ext3/ext4)的特定恢复功能或备份文件系统元数据。
### 4.2.2 磁盘错误检测与处理方法
磁盘错误可能是由于硬盘驱动器老化、读写次数过多或物理损害导致。及时发现并处理磁盘错误可以减少数据丢失的风险。
#### 磁盘性能监控工具
使用`smartmontools`可以对硬盘进行监控和自我检测。`smartmontools`包中的`satactl`和`smartctl`工具可以帮助用户获取硬盘的详细状态信息。
```bash
sudo smartctl -a /dev/sda
```
执行此命令可以得到`/dev/sda`磁盘的全面检测结果,包括磁盘的健康状态、读写错误次数等。
#### 物理磁盘故障处理
如果检测到磁盘存在物理故障,应立即备份数据并更换磁盘。对于RAID阵列,应根据RAID级别和磁盘配置采取适当的重建或替换策略。
## 4.3 故障排除流程图
为了更直观地理解故障排查流程,以下是使用mermaid格式的流程图:
```mermaid
graph TD
A[开始] --> B{是否可以启动}
B -->|是| C[运行中的系统]
B -->|否| D[启动过程中的故障]
C --> E[内存和进程管理]
C --> F[文件系统和磁盘问题]
D --> G[GRUB引导加载器问题]
D --> H[内核故障排除]
E --> I{是否存在内存泄漏}
E --> J{是否存在进程异常}
F --> K{文件系统是否损坏}
F --> L{磁盘是否有错误}
G --> M[GRUB修复流程]
H --> N[内核模块加载与配置]
I --> O[使用Valgrind检测]
J --> P[分析core文件]
K --> Q[使用fsck修复]
L --> R[磁盘自我检测]
M --> S[重新启动系统]
N --> S
O --> T[修改代码修复]
P --> T
Q --> U[文件系统完整性验证]
R --> V[磁盘更换或修复]
S --> W[系统恢复正常]
T --> W
U --> W
V --> W
W --> X[结束]
```
这个流程图详细描述了从系统启动失败到运行中系统各种故障的排查与处理步骤,包括内存泄漏、进程异常、文件系统损坏、磁盘错误等常见问题的解决方案。
# 5. 网络故障的诊断与修复
## 5.1 网络配置与问题定位
### 5.1.1 网络配置文件解析
在Ubuntu系统中,网络配置的控制通常涉及到多个文件,如`/etc/network/interfaces`、`/etc/netplan/`以及动态管理的配置文件,比如`/run/systemd/network/`。掌握这些配置文件的结构和内容对于诊断和修复网络问题至关重要。
以`/etc/network/interfaces`为例,这个文件定义了系统的网络接口配置。一个典型的配置如下所示:
```
auto eth0
iface eth0 inet static
address 192.168.1.10
netmask 255.255.255.0
gateway 192.168.1.1
dns-nameservers 8.8.8.8 8.8.4.4
```
在这个例子中,`auto eth0` 表示在系统启动时自动启动`eth0`接口。`iface eth0 inet static`定义了使用静态IP地址。`address`、`netmask`、`gateway`和`dns-nameservers`分别指定了静态IP地址、子网掩码、默认网关和DNS服务器。
**代码块示例**:
```bash
cat /etc/network/interfaces
```
这个简单的命令可以帮助你获取并审查`/etc/network/interfaces`文件的内容,以便进一步诊断网络配置问题。
### 5.1.2 网络故障诊断流程
网络故障诊断流程可以分为几个关键步骤,首先是使用`ping`命令检查基本的网络连通性:
```bash
ping -c 4 google.com
```
如果`ping`命令失败,则可能需要检查本地网络配置。接下来,可以使用`ip`命令来查看和调试IP地址配置:
```bash
ip addr show
```
查看路由表信息,可以使用:
```bash
ip route
```
若需要检查当前的DNS解析是否正常,可以使用`dig`或`nslookup`命令:
```bash
dig google.com
```
或者
```bash
nslookup google.com
```
如果以上命令都正常,但仍然无法访问网络,可能是防火墙或安全设置导致的问题。这时,就需要检查`iptables`规则或使用`ufw`等工具来查看和管理防火墙配置。
**故障排查逻辑分析**:
1. **检查网络连接**:先确认物理连接是否正确,无线连接是否已开启,并尝试重新连接网络。
2. **检查IP配置**:确认IP地址是否在正确的子网中,并且与路由器的设置保持一致。
3. **检查默认网关和DNS**:确保默认网关和DNS设置正确,这些是网络通信的关键要素。
4. **路由表检查**:确认系统路由表配置正确,确保数据包能够被正确地转发。
5. **防火墙和安全设置**:确保网络流量未被防火墙或安全软件阻挡。
## 5.2 安全性故障排查
### 5.2.1 防火墙和安全更新检查
在检查网络安全性问题时,防火墙规则是一个重要的检查点。Ubuntu中常用`ufw`(Uncomplicated Firewall)作为前端工具来管理`iptables`规则。检查防火墙状态:
```bash
sudo ufw status
```
如果防火墙处于启用状态,可以使用以下命令列出所有规则:
```bash
sudo ufw show raw
```
另一个关键点是系统和软件的安全更新。Ubuntu系统通过`apt`包管理器进行更新。更新可能涉及系统的安全补丁,因此定期检查和应用这些更新是确保系统安全的重要措施。
```bash
sudo apt update
sudo apt upgrade
```
**参数和逻辑说明**:
- `ufw status`命令用来查看当前防火墙的状态。
- `ufw show raw`命令用于显示原始`iptables`规则,这有助于理解`ufw`的内部运作方式。
- `apt update`命令更新包索引,而`apt upgrade`命令升级所有可升级的包。
### 5.2.2 常见安全漏洞的诊断与修复
Ubuntu系统中的安全漏洞可能来自多种来源,包括但不限于:未更新的软件包、弱密码策略、未加密的数据传输以及未配置的网络安全设置。诊断这些漏洞通常需要一个综合性的检查过程。
**代码块示例**:
```bash
sudo apt upgrade -y
```
这个命令会自动接受所有更新,是修复已知安全漏洞的简便方法。
接下来,我们需要检查系统的安全设置,例如密码策略。密码策略可以通过`pam-auth-update`工具来配置,这有助于强化密码的安全性。
```bash
sudo pam-auth-update
```
为了保护数据传输的安全性,可以使用`ssh`的密钥认证代替密码认证。生成密钥对的命令如下:
```bash
ssh-keygen -t rsa -b 4096
```
然后,将生成的公钥添加到需要访问的远程服务器。
**故障排查逻辑分析**:
1. **检查和更新软件包**:定期运行`apt update`和`apt upgrade`确保系统和应用都是最新版本。
2. **检查防火墙规则**:使用`ufw status`和相关命令确认防火墙规则设置是否正确。
3. **强化密码策略**:使用`pam-auth-update`加强密码安全设置。
4. **使用密钥认证**:生成并配置SSH密钥,以增强远程访问的安全性。
通过以上章节内容,我们从基础的网络配置文件解析到网络故障的诊断流程,再到安全性问题的排查和修复,层层深入地探讨了Ubuntu系统网络故障的诊断与修复方法。每一个步骤都紧密相连,旨在为IT专业人员提供一个完整的问题诊断到解决的流程图。
# 6. 故障预防与性能优化
## 6.1 系统监控与日志分析
系统监控和日志分析是预防故障和提升系统性能的关键环节。对系统的持续监控可以及时发现异常指标,而日志文件记录了系统和应用程序运行的所有详细信息,是进行故障分析的重要资源。
### 6.1.1 关键性能指标的监控方法
在Linux系统中,有多种工具可以用来监控系统的关键性能指标。以下是一些常用的工具和它们的基本使用方法:
- **top**: 实时显示系统进程和资源使用情况。
```bash
top
```
该命令启动一个交互式程序,按CPU使用率对进程进行排序。
- **htop**: top的增强版本,带有更直观的界面和额外的功能。
```bash
htop
```
- **vmstat**: 报告关于内核线程、虚拟内存、磁盘IO、系统进程、CPU活动等的信息。
```bash
vmstat 1
```
上述命令会每秒刷新一次报告。
- **iostat**: 提供CPU利用率和设备IO统计信息。
```bash
iostat -x
```
监控这些指标能够帮助你了解系统资源的使用状况,并及时做出调整。
### 6.1.2 日志文件的分析技巧
分析日志文件是故障排查的重要步骤。通过日志文件,我们可以了解系统在特定时间的行为和发生的错误。以下是一些关键的系统日志文件和分析方法:
- **/var/log/syslog**: 记录系统日志信息。
- **/var/log/auth.log**: 记录认证相关事件。
- **/var/log/kern.log**: 内核日志信息。
使用`grep`来搜索特定错误信息,可以使用如下命令:
```bash
grep "error" /var/log/syslog
```
此外,`journalctl`是另一个用于查询systemd日志系统的工具。例如:
```bash
journalctl -u ssh.service
```
这个命令显示SSH服务的日志条目。
对于日志分析,也可以使用图形界面工具如`gnome-system-monitor`和`KSysGuard`进行更直观的监控和日志查看。这些工具提供了资源使用情况的图形化视图,以及实时查看和过滤日志的能力。
## 6.2 系统备份与灾难恢复计划
系统备份与灾难恢复计划对于最小化数据丢失和系统故障的影响至关重要。一个良好的备份策略和恢复计划可以确保在出现故障时能够迅速恢复正常操作。
### 6.2.1 备份策略的制定与实施
制定备份策略应考虑以下因素:
- **备份频率**: 备份应该频繁到足以防止数据丢失,但又要考虑到存储成本和备份时间。
- **备份类型**: 包括完全备份、增量备份和差异备份。
- **备份方法**: 使用命令行工具如`rsync`、`tar`、`dd`,或者使用图形化备份工具如`Déjà Dup`。
例如,使用`rsync`进行目录同步,可以包括如下命令:
```bash
rsync -avz /path/to/source/ /path/to/destination/
```
这个命令会同步源目录到目标目录,并包括压缩和详细输出。
### 6.2.2 灾难恢复的步骤与实践
灾难恢复计划包括以下关键步骤:
1. **创建备份**: 确保定期创建并验证备份。
2. **测试恢复流程**: 定期进行恢复测试以验证灾难恢复计划的有效性。
3. **文档化**: 详细记录恢复步骤和备份位置。
4. **灾难恢复团队**: 建立一个团队并定期培训以应对灾难情况。
例如,进行系统恢复的步骤可能包括从备份介质启动系统,并使用命令行工具恢复数据:
```bash
mount /dev/sdb1 /mnt/backup/
rsync -avz /mnt/backup/ /path/to/destination/
```
这些命令首先挂载备份设备,然后将数据从备份中恢复到目标路径。
通过将这些步骤纳入常规操作流程,可以确保在系统发生故障时,有一个明确的计划可以遵循,从而快速有效地进行恢复。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Ubuntu系统故障排除与修复》专栏深入探讨了Ubuntu系统中常见的故障问题及其解决方案。专栏涵盖了广泛的主题,包括:
* **文件系统损坏急救手册:**指导用户恢复损坏的文件系统,确保数据完整性。
* **软件包故障处理攻略:**提供解决安装和升级问题的全面方法。
* **内核问题深度诊断:**系统化地诊断和解决内核错误。
* **硬件兼容性问题解决方案:**帮助用户识别和解决硬件兼容性问题。
* **系统升级后故障速解:**提供应对升级后常见问题的策略。
该专栏旨在为Ubuntu用户提供全面的故障排除指南,帮助他们快速解决系统问题,恢复系统正常运行。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【停车场管理新策略:E7+平台高级数据分析】
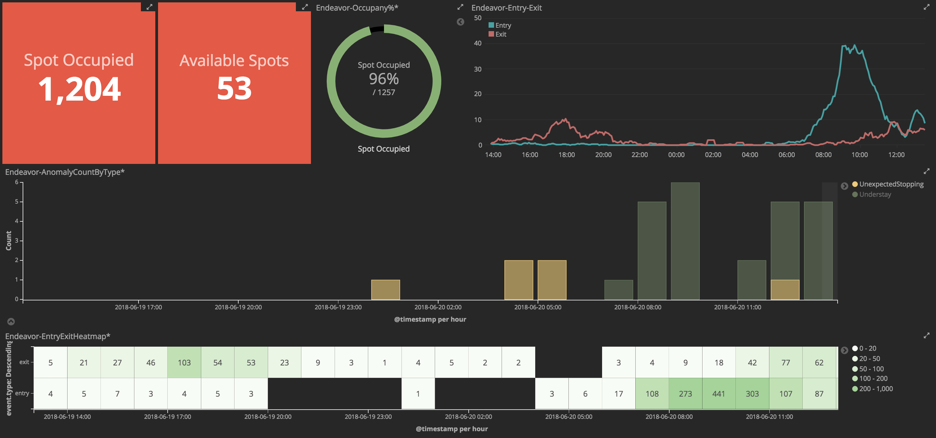
# 摘要
E7+平台是一个集数据收集、整合和分析于一体的智能停车场管理系统。本文首先对E7+平台进行介绍,然后详细讨论了停车场数据的收集与整合方法,包括传感器数据采集技术和现场数据规范化处理。在数据分析理论基础章节,本文阐述了统计分析、时间序列分析、聚类分析及预测模型等高级数据分析技术。E7+平台数据分析实践部分重点分析了实时数据处理及历史数据分析报告的生成。此外,本文还探讨了高级分析技术在交通流
【固件升级必经之路】:从零开始的光猫固件更新教程

# 摘要
固件升级是光猫设备持续稳定运行的重要环节,本文对固件升级的概念、重要性、风险及更新前的准备、下载备份、更新过程和升级后的测试优化进行了系统解析。详细阐述了光猫的工作原理、固件的作用及其更新的重要性,以及在升级过程中应如何确保兼容性、准备必要的工具和资料。同时,本文还提供了光猫固件下载、验证和备份的详细步骤,强调了更新过程中的安全措施,以及更新后应如何进行测试和优化配置以提高光猫的性能和稳定性。
【功能深度解析】:麒麟v10 Openssh新特性应用与案例研究

# 摘要
本文详细介绍了麒麟v10操作系统集成的OpenSSH的新特性、配置、部署以及实践应用案例。文章首先概述了麒麟v10与OpenSSH的基础信息,随后深入探讨了其核心新特性的三个主要方面:安全性增强、性能提升和用户体验改进。具体包括增加的加密算法支持、客户端认证方式更新、传输速度优化和多路复用机制等。接着,文中描述了如何进行安全配置、高级配置选项以及部署策略,确保系
QT多线程编程:并发与数据共享,解决之道详解

# 摘要
本文全面探讨了基于QT框架的多线程编程技术,从基础概念到高级应用,涵盖线程创建、通信、同步,以及数据共享与并发控制等多个方面。文章首先介绍了QT多线程编程的基本概念和基础架构,重点讨论了线程间的通信和同步机制,如信号与槽、互斥锁和条件变量。随后深入分析了数据共享问题及其解决方案,包括线程局部存储和原子操作。在
【Green Hills系统性能提升宝典】:高级技巧助你飞速提高系统性能
# 摘要
系统性能优化是确保软件高效、稳定运行的关键。本文首先概述了性能优化的重要性,并详细介绍了性能评估与监控的方法,包括对CPU、内存和磁盘I/O性能的监控指标以及相关监控工具的使用。接着,文章深入探讨了系统级性能优化策略,涉及内核调整、应用程序优化和系统资源管理。针对内存管理,本文分析了内存泄漏检测、缓存优化以及内存压缩技术。最后,文章研究了网络与
MTK-ATA与USB互操作性深入分析:确保设备兼容性的黄金策略
# 摘要
本文深入探讨了MTK-ATA与USB技术的互操作性,重点分析了两者在不同设备中的应用、兼容性问题、协同工作原理及优化调试策略。通过阐述MTK-ATA技术原理、功能及优化方法,并对比USB技术的基本原理和分类,本文揭示了两者结合时可能遇到的兼容性问题及其解决方案。同时,通过多个实际应用案例的分析,本文展示
零基础学习PCtoLCD2002:图形用户界面设计与LCD显示技术速成

# 摘要
随着图形用户界面(GUI)和显示技术的发展,PCtoLCD2002作为一种流行的接口工具,已经成为连接计算机与LCD显示设备的重要桥梁。本文首先介绍了图形用户界面设计的基本原则和LCD显示技术的基础知识,然后详细阐述了PCtoLCD200
【TIB文件编辑终极教程】:一学就会的步骤教你轻松打开TIB文件

# 摘要
TIB文件格式作为特定类型的镜像文件,在数据备份和系统恢复领域具有重要的应用价值。本文从TIB文件的概述和基础知识开始,深入分析了其基本结构、创建流程和应用场景,同时与其他常见的镜像文件格式进行了对比。文章进一步探讨了如何打开和编辑TIB文件,并详细介绍了编辑工具的选择、安装和使用方法。本文还对TIB文件内容的深入挖掘提供了实践指导,包括数据块结构的解析
单级放大器稳定性分析:9个最佳实践,确保设备性能持久稳定

# 摘要
单级放大器稳定性对于电子系统性能至关重要。本文从理论基础出发,深入探讨了单级放大器的工作原理、稳定性条件及其理论标准,同时分析了稳定性分析的不同方法。为了确保设计的稳定性,本文提供了关于元件选择、电路补偿技术及预防振荡措施的最佳实践。此外,文章还详细介绍了稳定性仿真与测试流程、测试设备的使用、测试结果的分析方法以及仿真与测试结果的对比研究。通过对成功与失败案例的分析,总结了实际应用中稳定性解决方案的实施经验与教训。最后,展望了未来放
信号传输的秘密武器:【FFT在通信系统中的角色】的深入探讨

# 摘要
快速傅里叶变换(FFT)是一种高效的离散傅里叶变换算法,广泛应用于数字信号处理领域,特别是在频谱分析、滤波处理、压缩编码以及通信系统信号处理方面。本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )