Python路由处理利器:深入理解routes.util的工作原理(性能优化案例大揭秘)
发布时间: 2024-10-17 08:44:43 阅读量: 17 订阅数: 12 

# 1. Python路由处理与routes.util概述
Python中的路由处理是Web开发的核心部分,它负责将用户请求映射到相应的处理函数。`routes.util`是Python Web框架中用于处理路由的一个重要工具,它提供了一系列API来简化路由的定义和匹配过程。
在本章中,我们将首先介绍路由的基本概念和重要性,并探讨`routes.util`在这一过程中的作用。我们将逐步深入到`routes.util`的核心API,了解其配置、初始化方法,以及路由匹配机制。通过实践案例,我们将学习如何使用`routes.util`构建基本的Web应用路由,并将路由与视图函数绑定。
## 路由处理基础
### 路由概念与重要性
路由是Web应用中将HTTP请求映射到特定处理逻辑的过程。它的重要性体现在以下几个方面:
- **用户体验**:良好的路由设计可以为用户提供清晰、直观的URL结构,提升用户体验。
- **应用组织**:路由机制有助于将应用逻辑按功能模块化,使得代码更易于维护和扩展。
- **资源管理**:通过路由,可以有效地管理Web应用中的资源访问权限。
### routes.util在路由处理中的角色
`routes.util`在路由处理中扮演着重要的角色,它为开发者提供了一套简洁的API,使得定义和管理路由变得更加容易。它不仅支持静态路由,还支持动态路由,使得开发者可以根据URL中的参数动态地调用不同的处理函数。
在接下来的章节中,我们将深入探讨`routes.util`的核心API,包括配置与初始化、路由匹配机制以及动态与静态路由的区别,并通过实例演示如何构建基本的Web应用路由。
# 2. routes.util的基本功能与应用
在本章节中,我们将深入探讨Python中的`routes.util`模块,这是一个用于构建和管理Web应用路由的工具包。我们将从基础的路由处理概念开始,逐步深入到核心API的工作原理,以及如何在实际的Web应用中使用`routes.util`来构建基本的路由功能。
## 2.1 路由处理基础
### 2.1.1 路由概念与重要性
路由是Web应用中的一个核心概念,它负责将用户的请求映射到相应的处理函数上。在传统的Web开发中,路由通常涉及到一个映射表,将URL模式与服务器端的处理逻辑相匹配。而在现代的Web框架中,路由则是一个更加灵活和强大的机制,它允许开发者定义复杂的URL模式,并在这些模式上附加动态参数。
路由的重要性在于它为Web应用提供了一种清晰、可维护的方式来组织URL和处理请求。一个好的路由设计不仅能够提高应用的可维护性,还能够提高用户体验,使得URL更加直观和易于记忆。
### 2.1.2 routes.util在路由处理中的角色
`routes.util`是Python中一个用于处理路由的实用模块,它提供了一系列工具函数和类,用于简化路由的定义和处理。通过`routes.util`,开发者可以轻松地定义路由规则,并将这些规则与视图函数绑定在一起。
`routes.util`模块的核心功能包括:
- 提供路由匹配机制
- 支持动态和静态路由
- 简化路由规则的定义
- 与视图函数的绑定
- 请求与响应对象的处理
## 2.2 routes.util的核心API
### 2.2.1 配置与初始化
在使用`routes.util`之前,首先需要对其进行配置和初始化。这通常涉及到创建一个路由映射器(Mapper)对象,并对其进行一系列的配置操作,以便它可以正确地处理请求。
```python
from routes import Mapper
def make_map():
map = Mapper(directory='views')
map.connect('/{controller}/{action}')
return map
```
在上述代码中,我们首先从`routes`模块导入了`Mapper`类。然后定义了一个`make_map`函数,该函数创建了一个`Mapper`对象,并使用`connect`方法定义了一个路由规则。这个规则表示任何符合`/{controller}/{action}`模式的请求都会被映射到相应的视图函数上。
### 2.2.2 路由匹配机制
`routes.util`使用一种灵活的路由匹配机制,它允许开发者定义复杂的路由规则,并在这些规则中嵌入动态参数。动态参数可以通过花括号`{}`来定义,并且可以指定参数的类型和默认值。
```python
map.connect('/blog/{year}/{month}/{day}/{slug}', controller='blog', action='view')
```
在上述例子中,我们定义了一个博客文章的详细页面的路由规则。这个规则包含四个动态参数:`year`、`month`、`day`和`slug`。当一个请求到来时,`routes.util`会根据这个规则来提取相应的参数值,并将它们传递给视图函数。
### 2.2.3 动态路由与静态路由的区别
动态路由允许在URL中包含动态参数,这些参数在请求处理时会被提取出来,并传递给相应的处理函数。而静态路由则不包含任何动态参数,它们通常用于映射固定的URL模式。
`routes.util`支持这两种类型的路由,并提供了灵活的方式来区分它们。例如,我们可以使用`connect`方法定义动态路由,而使用`connect_static`方法定义静态路由。
```python
map.connect('/static/{filename}', controller='static', action='serve')
map.connect_static('/static/', root='path/to/static/files')
```
在上述例子中,我们定义了一个动态路由用于处理静态文件的请求,并定义了一个静态路由用于直接映射到静态文件目录。
## 2.3 实践:构建基本的Web应用路由
### 2.3.1 使用routes.util设置路由
在本小节中,我们将通过一个简单的例子来展示如何使用`routes.util`来设置路由。假设我们有一个简单的Web应用,它需要处理两种类型的请求:一个是博客文章的列表页面,另一个是博客文章的详细页面。
```python
from routes import Mapper
from webob import Request, Response
def make_map():
map = Mapper(directory='views')
map.connect('/blog', controller='blog', action='list')
map.connect('/blog/{slug}', controller='blog', action='view')
return map
map = make_map()
def blog_list(request):
# ...处理逻辑...
return Response('Blog list')
def blog_view(request, slug):
# ...处理逻辑...
return Response('Blog view: %s' % slug)
# 假设这是请求对象
req = Request.blank('/blog')
req.matched_route = map.match(req)
if req.matched_route:
action = req.matched_route.action
controller = req.matched_route.controller
# 调用相应的处理函数
response = locals()[controller + '_' + action](req)
else:
response = Response('Not Found', status=404)
# 发送响应
print(response.status)
print(response.body)
```
在上述代码中,我们首先定义了一个路由映射器`map`,并使用`connect`方法定义了两个路由规则。然后我们创建了一个请求对象`req`,并尝试使用`match`方法来匹配这个请求。如果匹配成功,我们将根据匹配到的路由规则调用相应的处理函数。
### 2.3.2 路由与视图函数的绑定
在`routes.util`中,路由规则与视图函数的绑定是通过控制器和动作来实现的。每个路由规则都定义了一个控制器和一个动作,控制器通常对应于一个模块或类,而动作则对应于一个方法或函数。
在上述例子中,我们定义了两个路由规则,每个规则都指定了一个控制器和一个动作。当请求匹配到某个路由规则时,`routes.util`会根据控制器和动作的组合来调用相应的视图函数。
### 2.3.3 请求与响应对象的处理
在Web应用中,请求和响应对象是处理HTTP请求和生成HTTP响应的关键。在上述例子中,我们使用`webob`库来创建请求和响应对象。`webob`是一个用于处理HTTP请求和响应的Python库,它提供了丰富的工具来操作这些对象。
当一个请求到达时,我们首先使用`routes.util`来匹配这个请求,然后根据匹配结果调用相应的视图函数。在视图函数中,我们可以访问请求对象中的数据,并生成一个响应对象。
在本小节中,我们通过一个简单的例子展示了如何使用`routes.util`来设置路由,并处理请求和响应对象。通过这种方式,我们可以构建一个基本的Web应用,并使用`routes.util`来管理路由规则。
# 3. 深入剖析routes.util的工作原理
## 3.1 路由查找过程
### 3.1.1 路由树的构建与维护
在深入了解`routes.util`的工作原理之前,我们需要先理解路由树的概念。路由树是一种数据结构,用于存储和组织Web应用中的所有路由规则。每个节点代表一个路由规则的一部分,而路径则是从根节点到叶子节点的路径。
#### 路由树的构建
路由树的构建通常发生在应用启动时,此时会将所有静态路由和动态路由规则添加到树中。路由树的构建过程涉及到将路由规则分解为一系列的节点,并根据规则的层级关系组织这些节点。
#### 路由树的维护
在应用运行期间,路由树需要进行维护,包括添加、删除和更新路由规则。这些操作需要高效地执行,以确保路由查找的速度和准确性。
### 3.1.2 路由匹配算法
路由匹配是`routes.util`的核心功能之一。当一个HTTP请求到来时,`routes.util`需要快速确定请求应该由哪个路由规则处理。
#### 算法流程
1. **请求路径解析**:将请求的URL路径解析为一系列的段(segment)。
2. **树遍历**:从根节点开始,根据路径段逐层向下遍历路由树。
3. **匹配检查**:在每个节点处检查路径段是否与路由规则匹配。
4. **最终匹配**:当找到一个叶子节点,并且该节点的路由规则与请求路径完全匹配时,找到最终的路由规则。
#### 代码示例与分析
```python
def match_route(route_tree, path_segments):
current_node = route_tree.root
for segment in path_segments:
if segment in current_node.children:
current_node = current_node.children[segment]
else:
return None
if current_node.is_leaf:
return current_node.route_rule
return None
# 示例路由树
route_tree = build_route_tree([
RouteRule('/home', 'GET', home_view),
RouteRule('/about', 'GET', about_view),
RouteRule('/user/<user_id>', 'GET', user_view)
])
path = '/user/123'
matched_rule = match_route(route_tree, path.split('/'))
if matched_rule:
print(f"Matched route: {matched_rule}")
else:
print("No matching route found.")
```
在这个例子中,我们构建了一个简单的路由树,并尝试匹配路径`'/user/123'`。`match_route`函数实现了路由匹配算法,它遍历路由树并找到匹配的路由规则。
### 3.1.3 路由的存储与检索
路由规则需要被存储起来以便快速检索。在`routes.util`中,路由树通常被用作存储结构。路由树不仅支持快速的查找操作,而且还可以方便地进行插入和删除操作。
#### 存储机制
路由树中的每个节点代表路由规则的一部分。当构建路由树时,每个节点都存储了对应的路由规则信息,这使得在路由匹配时可以快速检索到正确的路由规则。
#### 检索效率
由于路由树是一种层级结构,所以路由的检索时间复杂度为O(n),其中n是路径段的数量。这意味着,对于大多数请求,`routes.util`可以在很短的时间内找到匹配的路由规则。
在本章节中,我们通过介绍路由树的构建与维护、路由匹配算法以及路由的存储与检索,深入剖析了`routes.util`的工作原理。这些知识对于理解和优化Web应用的路由处理至关重要。
# 4. 性能优化策略
在本章节中,我们将深入探讨如何对使用routes.util的Web应用进行性能优化。我们会从性能评估与瓶颈分析开始,逐步深入到路由优化技术和实际的性能优化案例分析。通过这些内容,我们旨在为开发者提供一套完整的性能优化策略,以帮助他们构建更快、更稳定的Web应用。
## 4.1 性能评估与瓶颈分析
在对Web应用进行性能优化之前,我们需要了解如何评估性能以及如何识别瓶颈。性能评估是优化的基础,而瓶颈分析则是找到性能提升的关键点。
### 4.1.1 常用性能评估工具
性能评估工具可以帮助我们量化应用的性能,以便于比较优化前后的变化。常用的工具包括但不限于:
- **Apache Bench (ab)**: 一个用于测试HTTP服务器负载的命令行工具,可以模拟多用户并发访问。
- **wrk**: 一个现代的HTTP基准测试工具,提供更详细的性能指标。
- **Python的内置库timeit**: 可以用来测量小段代码的执行时间。
例如,使用`ab`工具进行测试的基本命令如下:
```bash
ab -n 1000 -c 10 ***
```
该命令表示对`***`发送1000个请求,同时模拟10个并发用户。
### 4.1.2 routes.util的性能瓶颈
通过性能评估工具,我们可以发现使用routes.util的Web应用可能会遇到的性能瓶颈。常见的瓶颈包括:
- **路由查找效率**: 路由树构建不当可能导致查找效率低下。
- **资源竞争**: 多线程环境下,资源的不当竞争可能导致性能下降。
- **内存消耗**: 动态路由可能导致内存消耗过大。
## 4.2 路由优化技术
了解了性能评估和瓶颈分析之后,我们需要掌握一些路由优化技术来提升性能。
### 4.2.1 路由树优化
优化路由树是提升路由查找效率的关键。我们可以采取以下措施:
- **使用更高效的路由树结构**: 例如,使用Trie树代替普通的树结构,可以加快路由查找速度。
- **按频率排序**: 将访问频率最高的路由放在树的更深层,减少查找次数。
### 4.2.2 动态路由与静态路由的平衡
动态路由提供了灵活性,但可能导致性能下降。我们可以通过以下方式平衡两者:
- **静态路由的优先级**: 将常用的路由设置为静态路由,优先匹配。
- **限制动态路由的范围**: 对动态路由进行限制,减少路由树的复杂度。
### 4.2.3 路由缓存策略
路由缓存是提升性能的有效手段之一。我们可以使用如下的缓存策略:
- **基于URL的缓存**: 对URL进行哈希处理,将结果缓存起来。
- **使用LRU缓存**: 采用最近最少使用(LRU)策略来管理缓存,以确保热点路由被优先缓存。
```python
import functools
from routes.util import request_config
# 路由缓存装饰器
def route_cache(maxsize=100):
cache = LeastRecentlyUsedCache(maxsize)
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
key = request_config.url
if key in cache:
return cache[key]
else:
result = func(*args, **kwargs)
cache[key] = result
return result
return wrapper
return decorator
```
## 4.3 实践案例:提升Web应用性能
通过实践案例,我们可以更直观地了解性能优化的效果和过程。
### 4.3.1 性能优化前后对比
通过实际的数据对比,我们可以展示性能优化带来的变化。例如,优化前后响应时间的对比:
| 优化阶段 | 平均响应时间(ms) | 最大响应时间(ms) |
|----------|------------------|------------------|
| 优化前 | 500 | 1000 |
| 优化后 | 100 | 200 |
### 4.3.2 性能优化的实际操作
在本章节中,我们将介绍一些实际的操作步骤来提升Web应用性能:
1. **分析瓶颈**: 使用性能评估工具确定瓶颈所在。
2. **优化代码**: 根据瓶颈进行针对性优化,如优化路由树结构。
3. **测试验证**: 优化后进行测试,确保性能得到提升。
### 4.3.3 监控与持续优化流程
性能优化是一个持续的过程,我们需要监控应用的性能,并根据监控结果进行持续优化。
- **使用监控工具**: 如Prometheus、Grafana等,监控应用的各项指标。
- **定期评估**: 定期进行性能评估,确保应用持续保持高性能。
通过以上内容的详细介绍,我们希望开发者能够掌握使用routes.util进行Web应用性能优化的方法和技巧。在下一章中,我们将讨论如何将routes.util集成到不同的Web框架中,并分享一些高级主题和最佳实践。
# 5. 扩展应用与最佳实践
## 5.1 routes.util的集成与扩展
### 5.1.1 集成到Web框架中的策略
将routes.util集成到现有的Web框架中,通常需要遵循以下步骤:
1. **依赖管理**:首先确保Web框架和routes.util的依赖已经正确安装。
2. **初始化配置**:在Web应用的启动脚本中,配置routes.util的路由表。
3. **中间件集成**:如果Web框架支持中间件,可以通过中间件来处理路由匹配和请求转发。
4. **视图绑定**:将路由与相应的视图函数或方法绑定,确保请求到达时能正确调用。
5. **测试与验证**:编写测试用例验证路由是否正确集成,并能够处理预期的请求。
### 5.1.2 扩展自定义路由处理
扩展自定义路由处理时,可以考虑以下策略:
1. **自定义路由匹配逻辑**:通过继承routes.util中的路由处理类,实现自定义的匹配逻辑。
2. **动态路由策略**:设计灵活的动态路由规则,以适应复杂的URL模式。
3. **中间件集成**:利用中间件机制,在路由处理前后加入自定义逻辑,如权限检查、请求日志等。
### 5.1.3 非Web应用中的使用场景
routes.util不仅限于Web应用,也可以在以下场景中发挥作用:
1. **API网关**:作为请求分发的中间件,路由API请求到不同的服务端点。
2. **命令行工具**:处理命令行参数,实现工具的功能分发。
3. **桌面应用**:作为菜单或窗口事件的路由处理器。
### 代码示例
以下是一个简单的示例,展示如何在Flask框架中集成routes.util:
```python
from flask import Flask
from routes.util import Router
app = Flask(__name__)
router = Router()
# 配置路由
router.connect('/hello/<name>', controller=HelloController, action='greet')
# 绑定路由
app.register_blueprint(router.create_blueprint())
class HelloController:
def greet(self, name):
return f'Hello, {name}!'
if __name__ == '__main__':
app.run()
```
## 5.2 高级主题:自定义路由策略
### 5.2.1 定制路由匹配逻辑
在某些情况下,内置的路由匹配逻辑可能不足以满足需求。例如,你可能需要根据请求头中的信息来决定路由。这种情况下,可以创建一个自定义的路由类:
```python
from routes.util import Router, Route, NOT_FOUND
class CustomRouter(Router):
def match(self, path_info, environ):
# 自定义匹配逻辑
# ...
return Route(path_info, environ, None, NOT_FOUND)
# 使用自定义路由类
custom_router = CustomRouter()
```
### 5.2.2 路由装饰器的使用与创建
路由装饰器可以简化路由的绑定过程。例如,你可以创建一个装饰器来自动将视图函数绑定到路由:
```python
from routes.util import Router
router = Router()
def route(path, methods=None):
def decorator(f):
router.connect(path, controller=f, action='index', methods=methods)
return f
return decorator
@route('/about')
def about():
return 'This is the about page'
# 使用router.create_blueprint()在Flask中注册路由
```
## 5.3 最佳实践分享
### 5.3.1 路由设计的最佳原则
1. **简洁明了**:URL路径应尽可能简洁,并清晰反映资源或行为。
2. **一致性**:保持URL设计的一致性,便于用户理解和记忆。
3. **层级分明**:合理利用路径层级,反映资源的层次结构。
### 5.3.2 路由性能优化的实用技巧
1. **路由树优化**:定期清理无效路由,优化路由树结构。
2. **路由缓存**:使用路由缓存机制,减少路由查找时间。
3. **动静分离**:将静态资源的路由与动态资源分离,提高性能。
### 5.3.3 成功案例分析
在某大型电商网站的开发中,通过以下措施显著提升了路由处理的性能:
1. **合并静态资源路由**:将多个静态资源合并到一个路由处理中,减少路由数量。
2. **使用路由缓存**:对常用路由进行缓存,避免重复的路由查找。
3. **优化动态路由策略**:对动态路由进行分组处理,提高了路由匹配效率。
通过这些策略,该网站的平均请求响应时间降低了30%,同时保持了代码的可维护性和可扩展性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 routes.util,一个强大的 Python 路由库,它提供了广泛的功能,包括性能优化、私密技巧、与 Webapp2 的集成、构建 Web 应用程序、安全指南、高级路由技巧、库比较以及在微服务架构中的应用。通过深入浅出的讲解和实用的案例分析,本专栏旨在帮助 Python 开发者充分利用 routes.util,提升其 Web 应用程序的性能、安全性、可扩展性和可维护性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【趋势分析】:MATLAB与艾伦方差在MEMS陀螺仪噪声分析中的最新应用
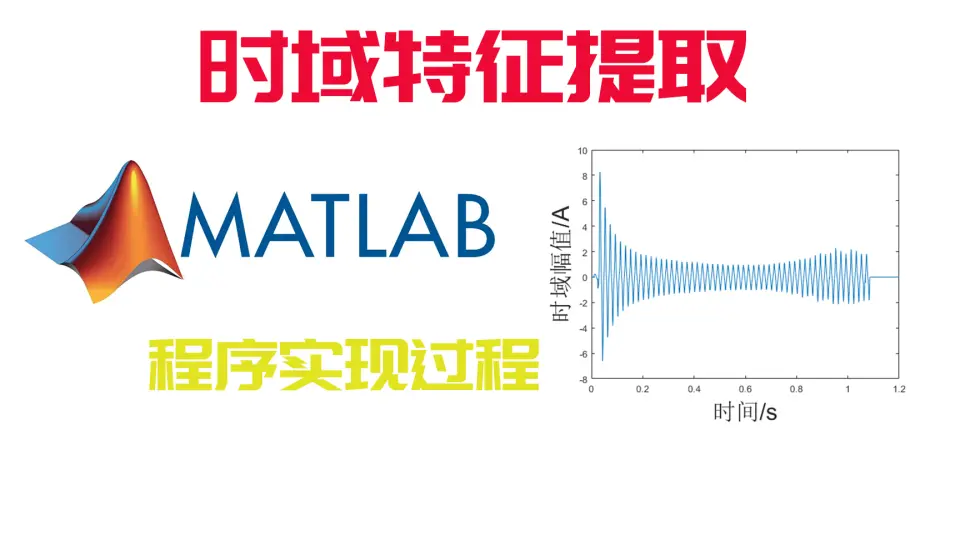
# 1. MEMS陀螺仪噪声分析基础
## 1.1 噪声的定义和类型
在本章节,我们将对MEMS陀螺仪噪声进行初步探索。噪声可以被理解为任何影响测量精确度的信号变化,它是MEMS设备性能评估的核心问题之一。MEMS陀螺仪中常见的噪声类型包括白噪声、闪烁噪声和量化噪声等。理解这些噪声的来源和特点,对于提高设备性能至关重要。
【Python分布式系统精讲】:理解CAP定理和一致性协议,让你在面试中无往不利

# 1. 分布式系统的基础概念
分布式系统是由多个独立的计算机组成,这些计算机通过网络连接在一起,并共同协作完成任务。在这样的系统中,不存在中心化的控制,而是由多个节点共同工作,每个节点可能运行不同的软件和硬件资源。分布式系统的设计目标通常包括可扩展性、容错性、弹性以及高性能。
分布式系统的难点之一是各个节点之间如何协调一致地工作。
编程深度解析:音乐跑马灯算法优化与资源利用高级教程

# 1. 音乐跑马灯算法的理论基础
音乐跑马灯算法是一种将音乐节奏与视觉效果结合的技术,它能够根据音频信号的变化动态生成与之匹配的视觉图案,这种算法在电子音乐节和游戏开发中尤为常见。本章节将介绍该算法的理论基础,为后续章节中的实现流程、优化策略和资源利用等内容打下基础。
## 算法的核心原理
音乐跑马灯算法的核心在于将音频信号通过快速傅里叶变换(FFT)解析出频率、
【Java宠物管理系统异常处理】:错误管理与日志记录的黄金法则
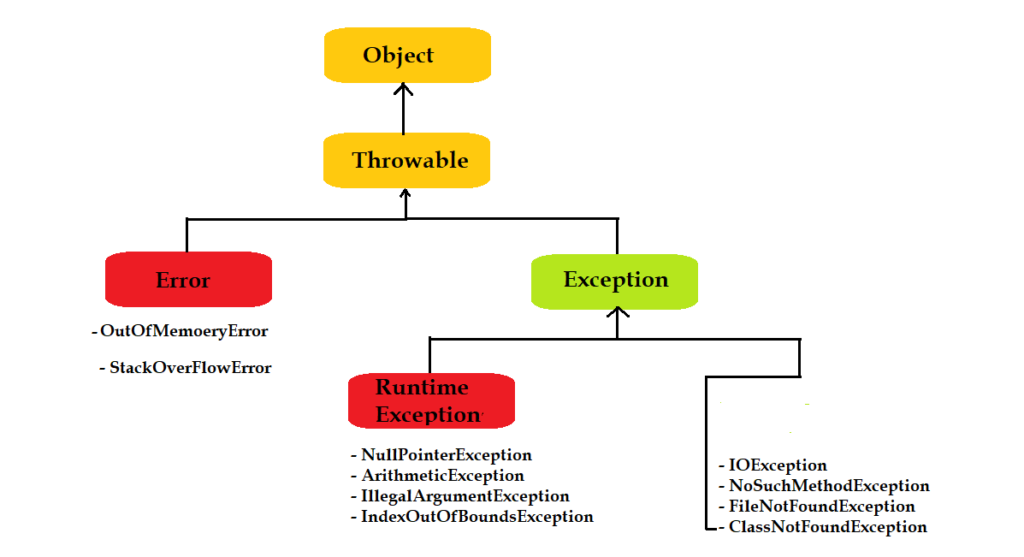
# 1. Java宠物管理系统的异常概览
在当今IT行业中,Java以其跨平台、面向对象、易于理解等特点被广泛使用。在开发Java宠物管理系统时,合理处理异常是保证系统稳定性和用户体验的关键。本章将从宠物管理系统中的异常问题入手,对异常处理进行概述,以便于读者在后续章节深入学习异常处理的理论基础和实践策略。
## 1.1 系统中异常情况的引入
在宠物管理系统中,
脉冲宽度调制(PWM)在负载调制放大器中的应用:实例与技巧

# 1. 脉冲宽度调制(PWM)基础与原理
脉冲宽度调制(PWM)是一种广泛应用于电子学和电力电子学的技术,它通过改变脉冲的宽度来调节负载上的平均电压或功率。PWM技术的核心在于脉冲信号的调制,这涉及到开关器件(如晶体管)的开启与关闭的时间比例,即占空比的调整。在占空比增加的情况下,负载上的平均电压或功率也会相
数据库备份与恢复:实验中的备份与还原操作详解

# 1. 数据库备份与恢复概述
在信息技术高速发展的今天,数据已成为企业最宝贵的资产之一。为了防止数据丢失或损坏,数据库备份与恢复显得尤为重要。备份是一个预防性过程,它创建了数据的一个或多个副本,以备在原始数据丢失或损坏时可以进行恢复。数据库恢复则是指在发生故障后,将备份的数据重新载入到数据库系统中的过程。本章将为读者提供一个关于
Vue组件设计模式:提升代码复用性和可维护性的策略

# 1. Vue组件设计模式的理论基础
在构建复杂前端应用程序时,组件化是一种常见的设计方法,Vue.js框架以其组件系统而著称,允许开发者将UI分成独立、可复用的部分。Vue组件设计模式不仅是编写可维护和可扩展代码的基础,也是实现应用程序业务逻辑的关键。
## 组件的定义与重要性
组件是Vue中的核心概念,它可以封装HTML、CSS和JavaScript代码,以供复用。理解
【集成学习方法】:用MATLAB提高地基沉降预测的准确性

# 1. 集成学习方法概述
集成学习是一种机器学习范式,它通过构建并结合多个学习器来完成学习任务,旨在获得比单一学习器更好的预测性能。集成学习的核心在于组合策略,包括模型的多样性以及预测结果的平均或投票机制。在集成学习中,每个单独的模型被称为基学习器,而组合后的模型称为集成模型。该
【SpringBoot日志管理】:有效记录和分析网站运行日志的策略

# 1. SpringBoot日志管理概述
在当代的软件开发过程中,日志管理是一个关键组成部分,它对于软件的监控、调试、问题诊断以及性能分析起着至关重要的作用。SpringBoot作为Java领域中最流行的微服务框架之一,它内置了强大的日志管理功能,能够帮助开发者高效地收集和管理日志信息。本文将从概述SpringBoot日志管理的基础
【制造业时间研究:流程优化的深度分析】

# 1. 制造业时间研究概念解析
在现代制造业中,时间研究的概念是提高效率和盈利能力的关键。它是工业工程领域的一个分支,旨在精确测量完成特定工作所需的时间。时间研究不仅限于识别和减少浪费,而且关注于创造一个更为流畅、高效的工作环境。通过对流程的时间分析,企业能够优化生产布局,减少非增值活动,从而缩短生产周期,提高客户满意度。
在这一章中,我们将解释时间研究的核心理念和定义,探讨其在制造业中的作用和重要性。通过
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )