Python爬虫技术:从入门到实战项目详解
发布时间: 2024-06-20 12:47:36 阅读量: 84 订阅数: 33 

# 1. Python爬虫基础**
Python爬虫是一种利用Python语言编写程序,从互联网上自动提取数据的技术。它广泛应用于数据采集、信息检索、网络监控等领域。
本章将介绍Python爬虫的基本概念、工作原理和常见技术。首先,我们将了解爬虫的组成部分,包括请求发送、响应处理和数据解析。其次,我们将学习如何使用Python标准库中的requests模块发送HTTP请求,并处理服务器返回的响应。最后,我们将介绍XPath和正则表达式,这两种用于从HTML和JSON数据中提取信息的强大工具。
# 2. Python爬虫实践技巧
### 2.1 请求库的使用和常见问题
#### 2.1.1 GET和POST请求
**GET请求**
GET请求用于从服务器获取数据,其语法如下:
```python
import requests
url = "https://example.com/api/v1/users"
response = requests.get(url)
```
**POST请求**
POST请求用于向服务器发送数据,其语法如下:
```python
import requests
url = "https://example.com/api/v1/users"
data = {"name": "John Doe", "email": "john.doe@example.com"}
response = requests.post(url, data=data)
```
**参数说明:**
* `url`: 要发送请求的URL。
* `data`: 要发送到服务器的数据(仅适用于POST请求)。
**常见问题:**
* **404错误:**表示服务器找不到请求的资源。
* **403错误:**表示服务器拒绝了请求。
* **500错误:**表示服务器在处理请求时遇到了内部错误。
#### 2.1.2 处理响应和解析数据
**处理响应**
`requests`库提供了一个`Response`对象来表示服务器的响应。该对象包含以下属性:
* `status_code`: 响应的状态代码(例如,200、404、500)。
* `headers`: 响应的HTTP头。
* `text`: 响应的文本内容。
* `json()`: 响应的JSON内容(如果响应是JSON格式)。
**解析数据**
根据响应的格式,可以使用以下方法解析数据:
* **文本数据:**使用`text`属性。
* **JSON数据:**使用`json()`方法。
* **XML数据:**使用第三方库(例如,`lxml`)。
**代码块:**
```python
import requests
url = "https://example.com/api/v1/users"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
for user in data:
print(f"User: {user['name']}, Email: {user['email']}")
```
**逻辑分析:**
该代码块演示了如何使用`requests`库发送GET请求,处理响应并解析JSON数据。如果响应的状态代码为200(表示成功),则将响应的JSON内容解析为一个Python字典,并遍历字典以打印每个用户的姓名和电子邮件。
### 2.2 XPath和正则表达式在爬虫中的应用
#### 2.2.1 XPath的基本语法和选择器
**XPath语法**
XPath是一种用于从XML文档中选择元素的语言。其基本语法如下:
```
/root/child1/child2/...
```
**选择器**
XPath提供了一系列选择器用于选择元素,包括:
* **标签选择器:**选择具有特定标签名的元素(例如,`//div`)。
* **属性选择器:**选择具有特定属性的元素(例如,`//div[@class="container"]`)。
* **文本选择器:**选择包含特定文本的元素(例如,`//p[contains(text(), "Hello")]`)。
#### 2.2.2 正则表达式的基本语法和匹配模式
**正则表达式语法**
正则表达式是一种用于匹配文本模式的语言。其基本语法如下:
```
pattern = r"regex"
```
**匹配模式**
正则表达式提供了一系列匹配模式,包括:
* **字符类:**匹配特定字符集(例如,`[a-z]`)。
* **量词:**指定字符重复的次数(例如,`.*`)。
* **分组:**将模式的一部分分组(例如,`(\w+)`)。
**代码块:**
```python
import re
html = "<div class='c
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到我们的专栏,在这里,我们将探索 Python 编程语言的奇妙世界。从浪漫的心形线代码到复杂的表锁问题,我们深入探讨了各种主题。
我们揭示了 Python 心形线代码背后的算法,并提供了优化指南,以提升效率和美感。我们分析了 MySQL 数据库中的表锁问题和索引失效案例,提供了全面的解决方案。此外,我们还分享了 MySQL 死锁问题的分析和解决方法,以及提升数据库性能的秘籍。
对于 Python 开发人员,我们提供了从数据结构和算法到面向对象编程设计模式的深入指南。我们涵盖了网络编程、机器学习、数据分析和可视化、Web 开发框架、爬虫技术、自动化测试、云计算和大数据处理等广泛主题。
无论您是 Python 新手还是经验丰富的专业人士,我们的专栏都旨在帮助您提升技能,解决问题并解锁 Python 的无限潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MySQL数据库性能提升秘籍】:揭秘视图与索引的最佳实践策略
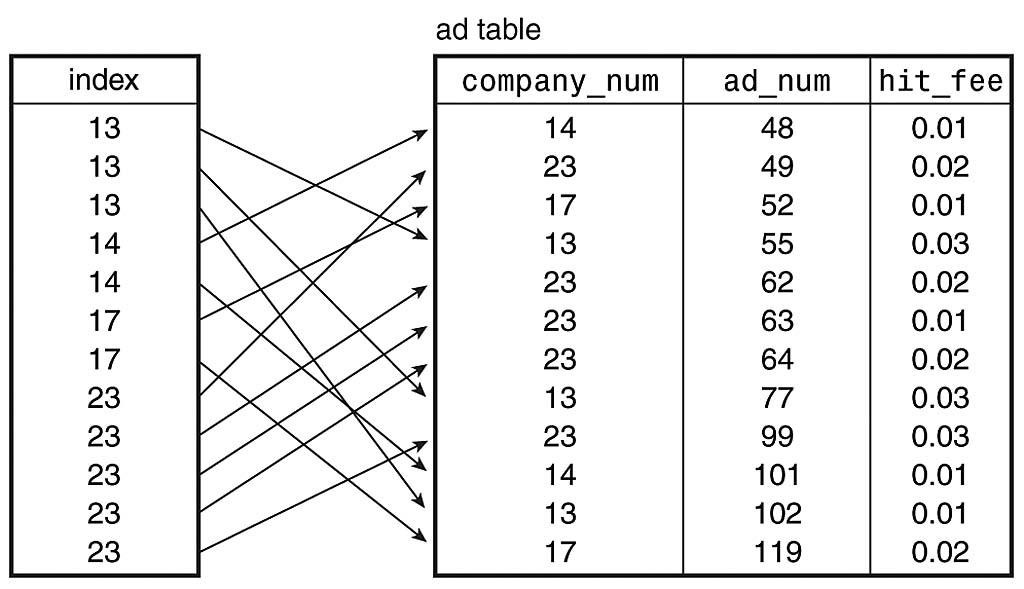
# 摘要
本文系统地探讨了MySQL数据库性能优化的各个方面,从索引的基础知识和优化技术,到视图的使用和性能影响,再到综合应用实践和性能监控工具的介绍。文中不仅阐述了索引和视图的基本概念、创建与管理方法,还深入分析了它们对数据库性能的正负面影响。通过真实案例的分析,本文展示了复杂查询、数据仓库及大数据环境下的性能优化策略。同时,文章展望了性能优化的未来趋势,包括
揭秘Android启动流程:UBOOT在开机logo显示中的核心作用与深度定制指南
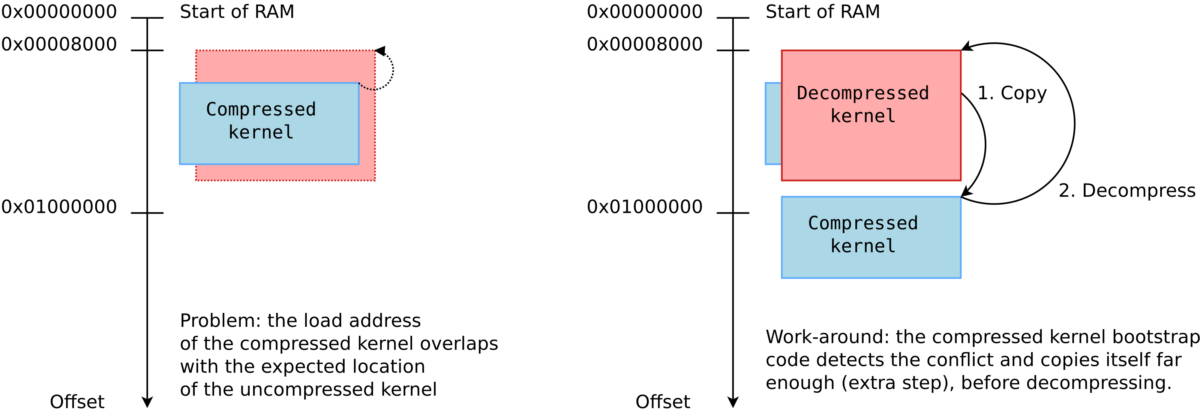
# 摘要
本文旨在全面介绍Android系统的启动流程,重点探讨UBOOT在嵌入式系统中的架构、功能及其与Android系统启动的关系。文章从UBOOT的起源与发展开始,详细分析其在启动引导过程中承担的任务,以及与硬件设备的交互方式。接着,本文深入阐述了UBOOT与Kernel的加载过程,以及UBOOT在显示开机logo和提升Android启动性能方面的
【掌握材料属性:有限元分析的基石】:入门到精通的7个技巧
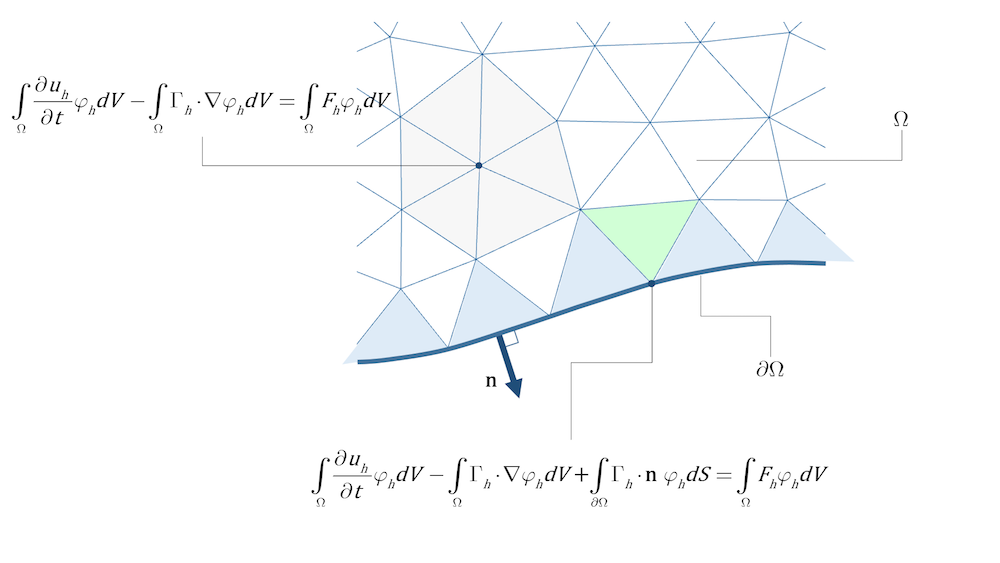
# 摘要
有限元分析是工程学中用于模拟物理现象的重要数值技术。本文旨在为读者提供有限元分析的基础知识,并深入探讨材料属性理论及其对分析结果的影响。文章首先介绍了材料力学性质的基础知识,随后转向非线性材料行为的详细分析,并阐述了敏感性分析和参数优化的重要性。在有限元软件的实际应用方面,本文讨论了材料属性的设置、数值模拟技巧以及非线性问题的处理。通过具体的工程结构和复合材料分析实例,文章展示了有限元分析在不同应用
中断处理专家课:如何让处理器智能响应外部事件

# 摘要
中断处理是计算机系统中关键的操作之一,它涉及到处理器对突发事件的快速响应和管理。本文首先介绍了中断处理的基本概念及其重要性,随后深
CMW100 WLAN故障快速诊断手册:立即解决网络难题
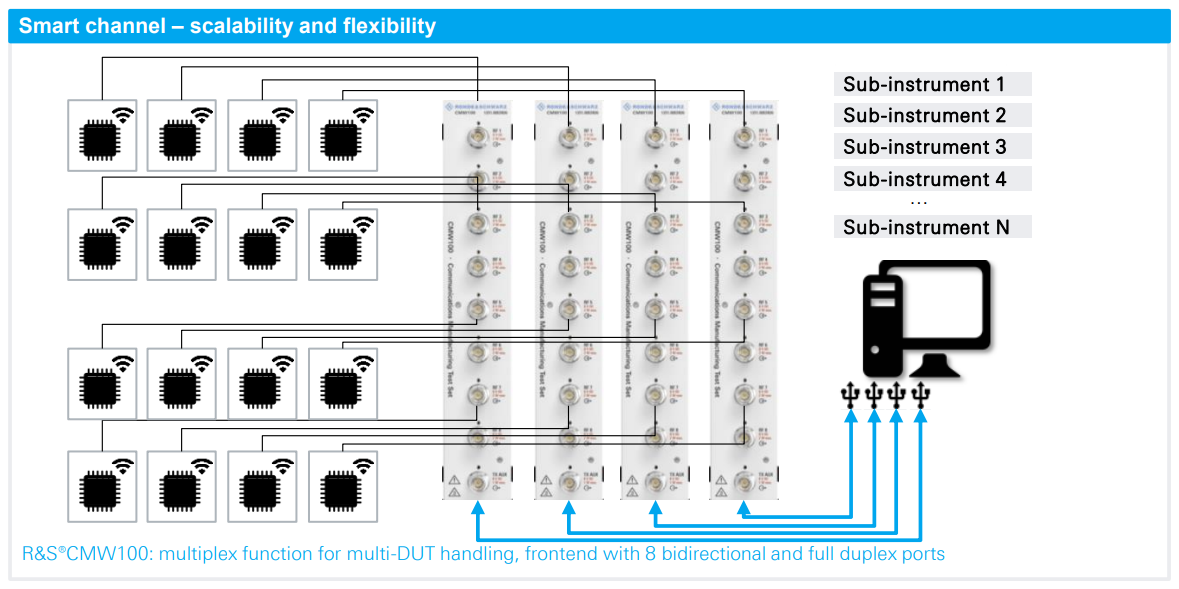
# 摘要
随着无线局域网(WLAN)技术的广泛应用,网络故障诊断成为确保网络稳定性和性能的关键环节。本文深入探讨了WLAN故障诊断的基础知识,网络故障的理论,以及使用CMW100这一先进的诊断工具进行故障排除的具体案例。通过理解不同类型的WLAN故障,如信号强度问题、接入限制和网络配置错误,并应用故障诊断的基本原则和工具,本文提供了对网络故障分析和解决过程的全面视角。文章详细介绍了CMW100的功能、特点及在实战中如何应对无线信号覆盖问题、客户端接入问题和网络安全漏
【Vue.js与AntDesign】:创建动态表格界面的最佳实践

# 摘要
随着前端技术的快速发展,Vue.js与AntDesign已成为构建用户界面的流行工具。本文旨在为开发者提供从基础到高级应用的全面指导。首先,本文概述了Vue.js的核心概念,如响应式原理、组件系统和生命周期,以及其数据绑定和事件处理机制。随后,探讨了AntDesign组件库的使用,包括UI组件的定制、表单和表格组件的实践。在此基础上,文章深入分析了动态表格
【PCIe 5.0交换与路由技术】:高速数据传输基石的构建秘籍
# 摘要
本文深入探讨了PCIe技术的发展历程,特别关注了PCIe 5.0技术的演进与关键性能指标。文章详细介绍了PCIe交换架构的基础组成,包括树状结构原理、路由机制以及交换器与路由策略的实现细节。通过分析PCIe交换与路由在服务器应用中的实践案例,本文展示了其在数据中心架构和高可用性系统中的具体应用,并讨论了故障诊断与性能调优的方法。最后,本文对PCIe 6.0的技术趋势进行了展望,并探讨了PCIe交换与路由技术的未来创新发展。
# 关键字
PCIe技术;性能指标;交换架构;路由机制;服务器应用;故障诊断
参考资源链接:[PCI Express Base Specification R
【16位加法器测试技巧】:高效测试向量的生成方法
# 摘要
本文探讨了16位加法器的基本原理与设计,并深入分析了测试向量的理论基础及其在数字电路测试中的重要性。文章详细介绍了测试向量生成的不同方法,包括随机
三菱FX3U PLC在智能制造中的角色:工业4.0的驱动者

# 摘要
随着工业4.0和智能制造的兴起,三菱FX3U PLC作为自动化领域的关键组件,在生产自动化、数据采集与监控、系统集成中扮演着越来越重要的角色。本文首先概述智能制造
【PCIe IP核心建造术】:在FPGA上打造高性能PCIe接口
# 摘要
PCIe技术作为高带宽、低延迟的计算机总线技术,在现代计算机架构中扮演着关键角色。本文从PCIe技术的基本概念出发,详细介绍了FPGA平台与PCIe IP核心的集成,包括FPGA的选择、PCIe IP核心的架构与优化。随后,文章探讨了PCI
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )