12-Python入门基础必备-正则表达式入门与常用操作
发布时间: 2024-02-27 03:24:40 阅读量: 37 订阅数: 37 
# 1. Python入门基础概述
Python是一种高级通用编程语言,被广泛应用于各种领域,包括Web开发、数据科学、人工智能等。本章将介绍Python的基础知识,帮助初学者快速入门。
## 1.1 Python编程语言简介
Python由Guido van Rossum于1989年创造,以简洁、可读性强而闻名。它支持面向对象、函数式编程等多种范式,适合不同编程风格的开发者。
## 1.2 安装Python环境与IDE
在开始Python编程之前,需要安装Python解释器。推荐使用官方提供的Python发行版,如Anaconda、Miniconda等。同时,选择一个集成开发环境(IDE)如PyCharm、VS Code等,提高开发效率。
## 1.3 Python基础语法与数据类型
Python具有简洁优雅的语法,使用缩进来表示代码块结构,而不是像其他语言那样使用大括号。常见数据类型包括整数、浮点数、字符串、列表、字典等。学习掌握这些基础知识是学习Python编程的第一步。
通过掌握以上内容,读者将建立起对Python编程的基础理解,为深入学习和应用Python打下扎实基础。
# 2. 正则表达式基础概念
正则表达式(Regular Expression)是一种用来描述字符串特征的方法,它可以帮助我们快速地在文本中匹配、搜索或替换特定的字符串模式。在本章中,我们将深入了解正则表达式的基础知识和基本概念。
### 2.1 什么是正则表达式
正则表达式是一种由晦涩难懂的符号组成的字符串,可以用来描述字符的统一模式。它是对字符串操作的一种逻辑公式,就像一个公式一样,用来规定字符串应该具有怎样的特征。
### 2.2 正则表达式的基本语法
正则表达式的基本语法包括普通字符和特殊字符。普通字符包括大小写字母、数字和一些特殊符号,而特殊字符则具有特殊的匹配含义,如`\d`匹配数字,`\w`匹配字母数字或下划线等。
### 2.3 正则表达式的匹配规则
正则表达式可以通过匹配规则来实现对字符串的匹配操作,比如使用`.`匹配任意字符,`^`匹配字符串的开头,`$`匹配字符串的结尾,`[]`匹配指定范围内的字符等。
在下一章中,我们将学习在Python中如何使用正则表达式进行匹配、搜索和替换操作,希望通过本章的介绍,您已经对正则表达式有了初步的认识。
# 3. 在Python中使用正则表达式
在Python中,我们可以通过re模块来使用正则表达式。下面我们将介绍re模块的基本用法,包括使用re.match()进行匹配、使用re.search()进行搜索、使用re.findall()进行全局匹配、以及使用re.sub()进行替换操作。
#### 3.1 re模块简介
re模块是Python中用于处理正则表达式的标准库,它提供了一系列函数来操作字符串。我们可以使用re.compile()函数将正则表达式编译成Pattern对象,然后使用Pattern对象的方法进行匹配操作。
#### 3.2 使用re.match()进行匹配
re.match()函数尝试从字符串的起始位置匹配一个模式,如果匹配成功,则返回一个匹配对象,否则返回None。以下是一个简单的示例:
```python
import re
pattern = 'foo'
string = 'foobar'
match_result = re.match(pattern, string)
if match_result:
print("Match found:", match_result.group())
else:
print("No match")
```
在这个示例中,pattern为'foo',string为'foobar',re.match()尝试从字符串起始位置匹配'foo',因为匹配成功,所以会打印出"Match found: foo"。
#### 3.3 使用re.search()进行搜索
re.search()函数扫描整个字符串,返回第一个成功匹配的结果。如果没有找到匹配的,则返回None。以下是一个示例:
```python
pattern = 'bar'
search_result = re.search(pattern, string)
if search_result:
print("Match found:", search_result.group())
else:
print("No match")
```
在这个示例中,pattern为'bar',re.search()在string中找到了匹配的'bar',所以会打印出"Match found: bar"。
#### 3.4 使用re.findall()进行全局匹配
re.findall()函数可以以列表的形式返回字符串中所有匹配的子串。以下是一个示例:
```python
text = "The rain in Spain falls mainly in the plain"
pattern = 'ai'
findall_result = re.findall(pattern, text)
print(findall_result)
```
运行该示例,会输出['ai', 'ai', 'ai', 'ai'],因为在text中找到了所有匹配的'ai'子串。
#### 3.5 使用re.sub()进行替换操作
re.sub()函数用于替换字符串中的匹配项。以下是一个示例:
```python
text = "The rain in Spain falls mainly in the plain"
pattern = 'ain'
replacement = 'ow'
sub_result = re.sub(pattern, replacement, text)
print(sub_result)
```
运行该示例,会输出"The row in Spow falls mowly in the plow",因为将text中所有匹配的'ain'替换为'ow'。
在第三章节中,我们学习了在Python中使用正则表达式的基本方法,包括re模块的简介以及使用re.match()、re.search()、re.findall()和re.sub()的具体示例操作。接下来,我们将进入第四章节,介绍常用的正则表达式操作。
# 4. 常用的正则表达式操作
正则表达式在日常工作中经常用于匹配和处理特定模式的文本,下面将介绍一些常用的正则表达式操作,帮助读者更好地理解和运用正则表达式。
#### 4.1 匹配数字、字母和特殊字符
在实际工作中,常常需要匹配文本中的数字、字母和特殊字符,以便进行相应的处理。下面是一些常用的正则表达式操作示例:
- 匹配数字:`\d+` 可以匹配一个或多个数字;
- 匹配字母:`\w+` 可以匹配一个或多个字母,包括大小写字母和下划线;
- 匹配特殊字符:`[\W]+` 可以匹配一个或多个特殊字符。
```python
import re
# 匹配数字例子
text = "今天的温度是26摄氏度,明天预计30摄氏度。"
pattern = r'\d+'
result = re.findall(pattern, text)
print("匹配数字结果:", result)
# 匹配字母例子
text = "Hello, 你好, world!"
pattern = r'\w+'
result = re.findall(pattern, text)
print("匹配字母结果:", result)
# 匹配特殊字符例子
text = "今天的#天气$很%好!"
pattern = r'[\W]+'
result = re.findall(pattern, text)
print("匹配特殊字符结果:", result)
```
**代码说明:**
- 通过 `re.findall()` 方法可以找到匹配的所有结果。
- 在上述示例中,分别展示了匹配数字、字母和特殊字符的操作,读者可以根据实际需求进行相应的调整和使用。
**结果说明:**
- 分别输出了匹配数字、字母和特殊字符的结果,以便用户理解和使用相应的正则表达式操作。
#### 4.2 匹配邮箱地址、URL等常见模式
在实际工作中,经常需要匹配和处理常见的模式,比如邮箱地址、URL等。下面是一些常用的正则表达式操作示例:
- 匹配邮箱地址:`[\w\.-]+@[\w\.-]+` 可以匹配常见的邮箱地址;
- 匹配URL:`https?://[\w/.\-]+` 可以匹配常见的URL地址。
```python
import re
# 匹配邮箱地址例子
text = "我的邮箱地址是abc@example.com,欢迎联系。"
pattern = r'[\w\.-]+@[\w\.-]+'
result = re.findall(pattern, text)
print("匹配邮箱地址结果:", result)
# 匹配URL例子
text = "详情请访问我的个人网站:http://www.example.com 或 https://blog.example.com"
pattern = r'https?://[\w/.\-]+'
result = re.findall(pattern, text)
print("匹配URL结果:", result)
```
**代码说明:**
- 通过使用不同的正则表达式模式,可以匹配到常见的邮箱地址和URL。
- 在上述示例中,展示了匹配邮箱地址和URL的操作,读者可以根据实际需求进行相应的调整和使用。
**结果说明:**
- 分别输出了匹配邮箱地址和URL的结果,以便用户理解和使用相应的正则表达式操作。
以上是常用的正则表达式操作示例,希望可以帮助读者更好地掌握正则表达式的使用方法。
# 5. 正则表达式的高级应用
在本章中,我们将深入探讨正则表达式的高级应用,包括贪婪匹配、预定义字符集、捕获组以及前后向匹配等技巧。
### 5.1 贪婪匹配与非贪婪匹配
在正则表达式中,默认情况下是贪婪匹配,即尽可能多地匹配满足条件的字符。例如,在匹配HTML标签时,可以使用`.*`实现贪婪匹配。为了转换为非贪婪匹配,可以在`*`后面加上`?`,即`.*?`表示非贪婪匹配。
```python
import re
text = "<html><title>Title</title></html>"
# 贪婪匹配
print(re.match('<.*>', text).group()) # 输出:<html><title>Title</title></html>
# 非贪婪匹配
print(re.match('<.*?>', text).group()) # 输出:<html>
```
**代码总结:** 贪婪匹配尽可能匹配更多字符,而非贪婪匹配则匹配更少字符。
**结果说明:** 在上述代码中,我们展示了贪婪匹配和非贪婪匹配的区别,以匹配HTML标签为例。
### 5.2 使用预定义字符集简化匹配
在正则表达式中,预定义字符集可以简化匹配特定类型的字符,例如`\d`匹配数字,`\w`匹配字母数字下划线,`\s`匹配空白字符等。
```python
import re
text = "The meeting is at 9:00 am."
# 匹配数字
print(re.search('\d+:\d+', text).group()) # 输出:9:00
# 匹配字母数字下划线
print(re.findall('\w+', text)) # 输出:['The', 'meeting', 'is', 'at', '9', '00', 'am']
```
**代码总结:** 使用预定义字符集可以简化匹配,提高代码可读性和效率。
**结果说明:** 在以上代码中,我们展示了如何使用预定义字符集匹配数字和字母数字下划线。
### 5.3 捕获组与非捕获组
捕获组是用括号括起来的正则表达式,可以对匹配的结果进行分组提取。非捕获组使用`(?:)`语法,可以进行分组但不捕获结果。
```python
import re
text = "apple price: $2, banana price: $1"
# 捕获组提取水果价格
pattern = re.compile(r'(\w+) price: \$(\d)')
match = pattern.findall(text)
for item in match:
print(item) # 输出:('apple', '2') 和 ('banana', '1')
# 非捕获组示例
print(re.findall(r'\w+(?: price: \$\d)', text)) # 输出:['apple price: $2', 'banana price: $1']
```
**代码总结:** 捕获组可以对匹配内容进行分组提取,而非捕获组进行分组但不捕获结果。
**结果说明:** 以上代码展示了捕获组和非捕获组的用法,以提取水果价格为例。
### 5.4 使用前后向匹配
在正则表达式中,可以使用`(?=...)`实现正向肯定预查,`(?!...)`实现负向否定预查,`(?<=...)`实现正向肯定回顾,`(?<!...)`实现负向否定回顾。
```python
import re
text = "match these words: bat, mat, cat, hat, rat"
# 正向肯定预查示例
print(re.findall(r'\w+(?=at)', text)) # 输出:['b', 'm', 'c', 'h', 'r']
# 正向否定预查示例
print(re.findall(r'\w+(?!at)', text)) # 输出:['match', 'these', 'words', 'r']
# 正向肯定回顾示例
print(re.findall(r'(?<=b)\w+', text)) # 输出:['at']
# 负向否定回顾示例
print(re.findall(r'(?<!h)\w+', text)) # 输出:['mat', 'cat', 'at', 'rat']
```
**代码总结:** 使用前后向匹配可以更精确地定位匹配内容,进行高级匹配。
**结果说明:** 在上述代码中,我们展示了正向肯定预查、正向否定预查、正向肯定回顾、负向否定回顾的应用场景。
# 6. 实战案例与总结
在本章节中,我们将通过实际案例来展示如何在Python中使用正则表达式进行有效的信息提取和用户输入验证。通过这些实战案例,我们将加深对正则表达式的理解,并总结其重要性和应用场景。
### 6.1 实战案例:提取文本中的有效信息
在这个案例中,我们将展示如何使用正则表达式从文本中提取有效信息。假设我们有一个包含电话号码的文本,我们想要提取出所有的电话号码。
```python
import re
text = "John: 123-456-7890, Jane: 987-654-3210"
phone_numbers = re.findall(r'\d{3}-\d{3}-\d{4}', text)
print("提取到的电话号码为:", phone_numbers)
```
**代码解释:**
- 使用`re.findall()`函数结合正则表达式`\d{3}-\d{3}-\d{4}`来从文本中提取电话号码,该正则表达式匹配形如xxx-xxx-xxxx的电话号码格式。
- 最终输出提取到的电话号码列表。
**结果说明:**
- 运行以上代码后,将输出提取到的电话号码列表:`['123-456-7890', '987-654-3210']`。
### 6.2 实战案例:验证用户输入的合法性
在这个案例中,我们将展示如何使用正则表达式验证用户输入的合法性。假设我们要求用户输入一个邮箱地址,并验证其格式是否合法。
```python
import re
email = input("请输入您的邮箱地址:")
if re.match(r'^\w+@[a-zA-Z_]+?\.[a-zA-Z]{2,3}$', email):
print("邮箱地址合法!")
else:
print("邮箱地址格式不正确,请重新输入!")
```
**代码解释:**
- 使用`re.match()`函数结合正则表达式来验证用户输入的邮箱地址格式是否合法。
- 正则表达式`^\w+@[a-zA-Z_]+?\.[a-zA-Z]{2,3}$`用于匹配常见的邮箱地址格式。
- 如果用户输入的邮箱地址符合格式,则输出“邮箱地址合法!”;否则输出“邮箱地址格式不正确,请重新输入!”。
**结果说明:**
- 当用户输入正确的邮箱地址格式时,将输出“邮箱地址合法!”;如果格式不正确,则会提示用户重新输入。
### 6.3 总结正则表达式的重要性与应用场景
通过上面两个实战案例的演示,我们可以看到正则表达式在信息提取和输入验证等方面的强大应用。正则表达式可以帮助我们快速准确地匹配特定模式的文本,提高处理数据的效率和精确度。
在实际开发中,掌握正则表达式的基础知识和常见操作是非常重要的。它不仅可以用于处理文本数据,还可以应用于网络爬虫、数据清洗、日志分析等各种场景中。
### 6.4 学习资源推荐与进阶建议
- **学习资源推荐:**
- 《正则表达式必知必会》- 作者:Ben Forta
- [Python官方文档 - re模块](https://docs.python.org/3/library/re.html)
- **进阶建议:**
- 深入学习正则表达式的高级应用,如预测符号、零宽断言等特性。
- 练习更多实际案例,加深对正则表达式的理解与应用。
希望通过本章内容的学习,您对正则表达式的实陵应用有了更深入的认识与理解,同时也能够在实际开发中灵活运用正则表达式解决问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
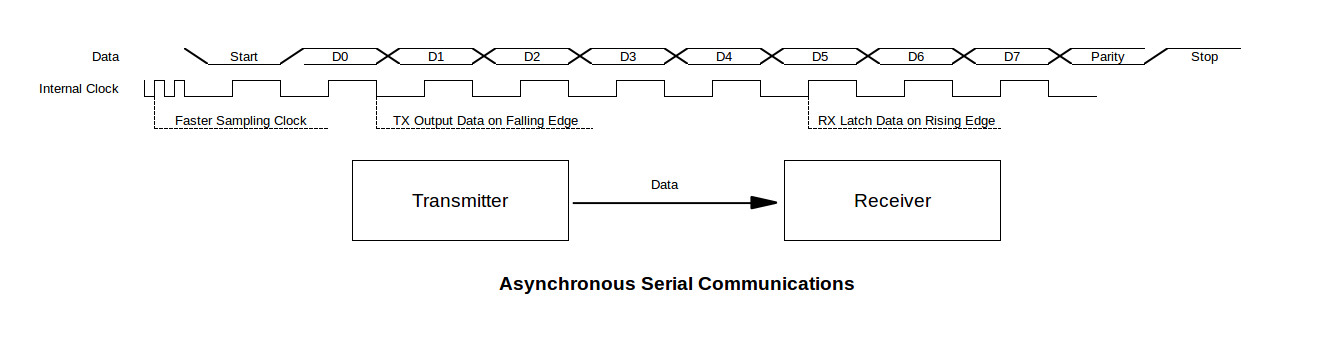
S32K SPI开发者必读:7大优化技巧与故障排除全攻略
# 摘要
本文深入探讨了S32K微控制器的串行外设接口(SPI)技术,涵盖了从基础知识到高级应用的各个方面。首先介绍了SPI的基础架构和通信机制,包括其工作原理、硬件配置以及软件编程要点。接着,文章详细讨论了SPI的优化技巧,涵盖了代码层面和硬件性能提升的策略,并给出了故障排除及稳定性的提升方法。实战章节着重于故障排除,包括调试工具的使用和性能瓶颈的解决。应用实例和扩展部分分析了SPI在
图解数值计算:快速掌握速度提量图的5个核心构成要素
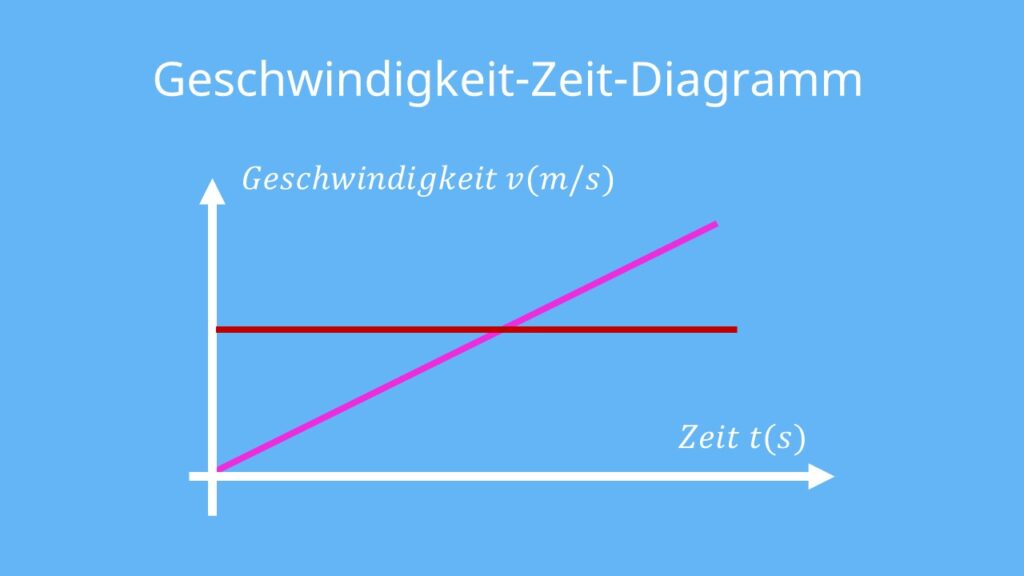
# 摘要
本文全面探讨了速度提量图的理论基础、核心构成要素以及在多个领域的应用实例。通过分析数值计算中的误差来源和减小方法,以及不同数值计算方法的特点,本文揭示了实现高精度和稳定性数值计算的关键。同时,文章深入讨论了时间复杂度和空间复杂度的优化技巧,并展示了数据可视化技术在速度提量图中的作用。文中还举例说明了速度提量图在
动态规划:购物问题的终极解决方案及代码实战

# 摘要
动态规划是解决优化问题的一种强大技术,尤其在购物问题中应用广泛。本文首先介绍动态规划的基本原理和概念,随后深入分析购物问题的动态规划理论,
【随机过程精讲】:工程师版习题解析与实践指南
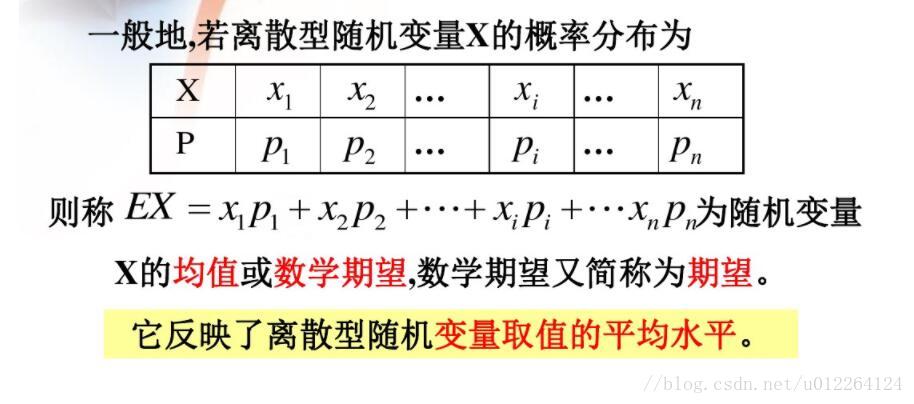
# 摘要
随机过程是概率论的一个重要分支,被广泛应用于各种工程和科学领域中。本文全面介绍了随机过程的基本概念、分类、概率分析、关键理论、模拟实现以及实践应用指南。从随机变量的基本统计特性讲起,深入探讨了各类随机过程的分类和特性,包括马尔可夫过程和泊松过程。文章重点分析了随机过程的概率极限定理、谱分析和最优估计方法,详细解释了如何通过计算机模拟和仿真软件来实现随机过程的模拟。最后,本文通过工程问题中随机过程的实际应用案例,以
【QSPr高级应用案例】:揭示工具在高通校准中的关键效果
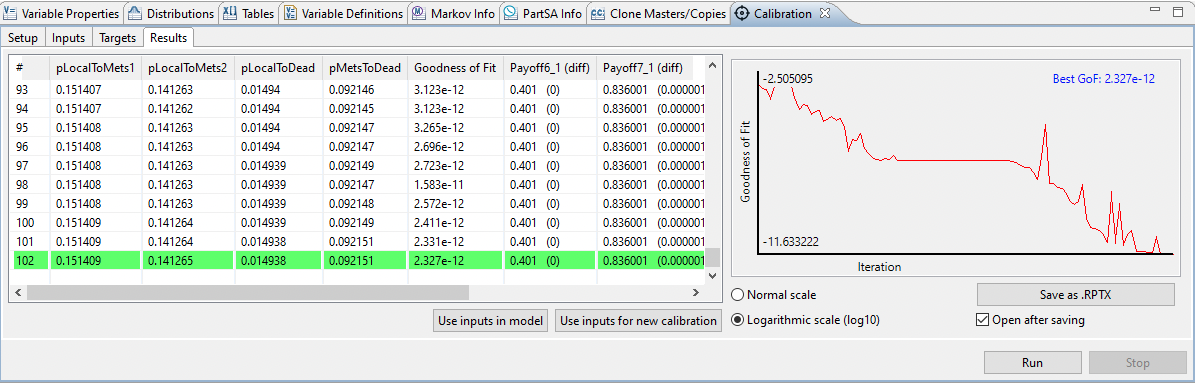
# 摘要
本论文旨在介绍QSPr工具及其在高通校准中的基础和应用。首先,文章概述了QSPr工具的基本功能和理论框架,探讨了高通校准的重要性及其相关标准和流程。随后,文章深入分析了QSPr工具的核心算法原理和数据处理能力,并提供了实践操作的详细步骤,包括数据准备、环境搭建、校准执行以及结果分析和优化。此外,通过具体案例分析展示了QSPr工具在不同设备校准中的定制
Tosmana配置精讲:一步步优化你的网络映射设置

# 摘要
Tosmana作为一种先进的网络映射工具,为网络管理员提供了一套完整的解决方案,以可视化的方式理解网络的结构和流量模式。本文从基础入门开始,详细阐述了网络映射的理论基础,包括网络映射的定义、作用以及Tosmana的工作原理。通过对关键网络映射技术的分析,如设备发现、流量监控,本文旨在指导读者完成Tosmana网络映射的实战演练,并深入探讨其高级应用,包括自动化、安全威胁检测和插件应用。最
【Proteus与ESP32】:新手到专家的库添加全面攻略

# 摘要
本文详细介绍Proteus仿真软件和ESP32微控制器的基础知识、配置、使用和高级实践。首先,对Proteus及ESP32进行了基础介绍,随后重点介绍了在Proteus环境下搭建仿真环境的步骤,包括软件安装、ESP32库文件的获取、安装与管理。第三章讨论了ESP32在Proteus中的配置和使用,包括模块添加、仿真
【自动控制系统设计】:经典措施与现代方法的融合之道
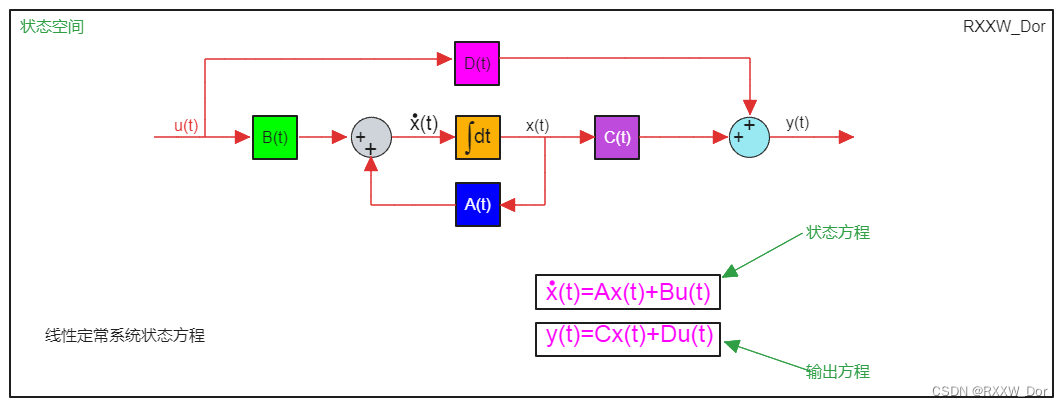
# 摘要
自动控制系统是工业、航空、机器人等多个领域的核心支撑技术。本文首先概述了自动控制系统的基本概念、分类及其应用,并详细探讨了经典控制理论基础,包括开环和闭环控制系统的原理及稳定性分析方法。接着,介绍了现代控制系统的实现技术,如数字控制系统的原理、控制算法的现代实现以及高级控制策略。进一步,本文通过设计实践,阐述了控制系统设计流程、仿真测试以及实际应用案例。此外,分析了自动控制系统设计的当前挑战和未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )