19-Python入门基础必备-爬虫入门与Requests和BeautifulSoup库
发布时间: 2024-02-27 03:33:19 阅读量: 49 订阅数: 37 
# 1. Python入门基础概述
## 1.1 Python介绍与安装
Python是一种高级、解释型、面向对象的编程语言,由Guido van Rossum于1991年发明。它具有简单易学、代码可读性高等特点,被广泛用于Web开发、数据科学、人工智能等领域。
安装Python非常简单,只需到官方网站https://www.python.org/downloads/ 下载对应操作系统的安装包,按照提示一步步安装即可。
```python
# Python安装示例
# 下载安装包: https://www.python.org/downloads/
# 安装时记得勾选“Add Python to PATH”选项
print("Hello, Python!")
```
安装完成后,可以在命令行中输入`python`命令,进入Python交互式环境,验证是否安装成功。
## 1.2 Python基础语法与数据类型
Python语法简洁明了,使用缩进来表示代码块,推荐使用4个空格作为缩进。常见的数据类型包括整数、浮点数、字符串、列表、元组、字典等。
```python
# Python基础语法示例
# 定义变量并输出
message = "Hello, Python!"
print(message)
# 列表示例
fruits = ['apple', 'banana', 'cherry']
for fruit in fruits:
print(fruit)
```
## 1.3 Python函数与模块
Python通过函数和模块来组织代码。函数是一段可重复使用的代码块,而模块是包含Python代码的文件。
```python
# Python函数与模块示例
# 定义一个简单函数
def greet(name):
print("Hello, " + name + "!")
greet("Alice")
# 导入自定义模块并调用函数
import mymodule
mymodule.say_hi("Bob")
```
在这一章节中,我们简要介绍了Python的基础概述,包括Python的介绍与安装、基础语法与数据类型、函数与模块的概念和用法。接下来,我们将深入探讨网络爬虫的相关知识。
# 2. 网络爬虫概述
### 2.1 什么是网络爬虫
在这一节中,我们将介绍网络爬虫的定义和基本概念。网络爬虫(Web Crawler)是一种自动化提取网络信息的程序或脚本,也被称为网络蜘蛛(Web Spider)或网络机器人(Web Robot)。它们通过模拟人的浏览行为,自动地浏览网页、收集数据、整理信息,并将所需内容存储到本地或数据库中。
### 2.2 网络爬虫的应用领域
网络爬虫在各个领域都有着广泛的应用,包括但不限于:
- 搜索引擎:如Google、百度等搜索引擎利用网络爬虫对互联网进行信息搜集和索引,以提供用户更好的搜索体验。
- 数据挖掘:通过网络爬虫可以抓取海量数据并进行分析,从而发现数据间的关联和规律。
- 价格监控:电商网站可以利用网络爬虫来监视竞争对手的价格变化,以调整自己的销售策略。
- 舆情监控:政府、企业等可以通过网络爬虫来监测舆情动向,了解公众对于某一事件或产品的看法。
### 2.3 网络爬虫的道德与法律问题
虽然网络爬虫在各行各业都发挥着重要作用,但也存在一些道德和法律问题需要注意:
- 尊重网站所有者的隐私政策和使用条款,避免对网站造成过大负担。
- 遵守Robots协议,即robots.txt文件中所规定的爬取规则,不越权访问和爬取网页。
- 避免盗版和侵权问题,不要未经允许地抓取他人的内容。
网络爬虫作为一个强大的工具,需要在遵守法律和道德的前提下加以使用,以推动科技和社会的进步。
# 3. Requests库的基本用法
网络爬虫通常需要发送 HTTP 请求来获取网页数据,而 Python 的 Requests 库是一个简洁、优雅的发送 HTTP 请求的库。接下来我们将介绍 Requests 库的基本用法,包括库的简介与安装、发送 HTTP 请求以及处理响应数据的方法。
#### 3.1 Requests库简介与安装
在使用 Requests 库之前,首先需要安装该库。可以通过 pip 工具来进行安装:
```python
pip install requests
```
安装完成后,我们就可以开始使用 Requests 库来发送各种类型的 HTTP 请求了。
#### 3.2 使用Requests库发送HTTP请求
Requests 库提供了简洁而强大的 API,可以方便地发送各种类型的 HTTP 请求,比如 GET、POST 等。下面是一个使用 Requests 库发送 GET 请求的示例代码:
```python
import requests
# 发送一个简单的 GET 请求
response = requests.get('https://www.example.com')
# 打印响应内容
print(response.text)
```
#### 3.3 处理Requests库的响应数据
当请求发送完成后,我们通常需要处理服务器返回的响应数据。Requests 库提供了许多属性和方法来处理响应数据,比如获取 HTTP 状态码、响应头、以及解析响应内容等。下面是一个简单的示例代码:
```python
import requests
# 发送一个简单的 GET 请求
response = requests.get('https://www.example.com')
# 获取响应状态码
print('Status code:', response.status_code)
# 获取响应头
print('Headers:', response.headers)
# 获取并打印响应内容
print('Content:', response.text)
```
通过上述介绍,我们初步了解了如何使用 Requests 库发送 HTTP 请求以及处理响应数据。在接下来的章节中,我们将利用 Requests 库对网页进行获取,并结合 BeautifulSoup 库进行信息提取,完成一个简单的网页爬取示例。
# 4. BeautifulSoup库的基本用法
在本章中,我们将介绍如何使用BeautifulSoup库来解析HTML并从网页中提取信息。在网络爬虫开发中,BeautifulSoup是一个非常强大和常用的库,能够帮助我们轻松地处理HTML和XML文件,提取我们需要的信息。
**4.1 BeautifulSoup库简介与安装**
BeautifulSoup是一个Python库,它能够从HTML或XML文件中提取数据。它支持解析器如Python标准库中的html.parser、lxml解析器、html5lib等,可以根据需要选择最合适的解析器来解析网页。
要安装BeautifulSoup库,可以使用pip工具,在命令行中运行以下命令:
```bash
pip install beautifulsoup4
```
**4.2 使用BeautifulSoup解析HTML**
使用BeautifulSoup解析HTML非常简单,首先我们需要导入BeautifulSoup库,然后将需要解析的HTML内容传入BeautifulSoup类中即可。
下面是一个简单的示例代码,演示了如何使用BeautifulSoup解析HTML:
```python
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>这是一个示例HTML</title>
</head>
<body>
<h1>标题</h1>
<p class="content">示例内容段落1</p>
<p class="content">示例内容段落2</p>
</body>
</html>
# 使用html.parser解析器解析HTML文档
soup = BeautifulSoup(html_doc, 'html.parser')
# 输出HTML文档的title标签内容
print(soup.title)
# 输出HTML文档中所有的p标签
for p_tag in soup.find_all('p'):
print(p_tag.text)
```
**4.3 从网页中提取信息**
除了解析HTML外,BeautifulSoup还提供了丰富的方法来提取网页中我们需要的信息,比如查找特定标签、获取标签属性、搜索字符串等。通过结合Requests库获取到的网页内容和BeautifulSoup库,我们可以轻松地编写爬虫程序来爬取网页信息。
以上是BeautifulSoup库的基本用法介绍,希望可以帮助您更好地理解如何利用这个强大的库来处理网页数据。
# 5. 利用Requests和BeautifulSoup进行网页爬取
在这一章节中,我们将介绍如何结合使用Python中的Requests库和BeautifulSoup库进行网页爬取,帮助你更好地了解如何获取并处理网页信息。
#### 5.1 结合Requests和BeautifulSoup进行简单网页爬取
首先,我们需要使用Requests库发送HTTP请求获取网页内容,再利用BeautifulSoup库解析HTML,从而提取我们需要的信息。让我们看一个简单的示例:
```python
import requests
from bs4 import BeautifulSoup
# 发送HTTP GET请求
url = 'https://www.example.com'
response = requests.get(url)
# 判断请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 从网页中提取标题信息
title = soup.title.text
print(f"网页标题: {title}")
else:
print("网页请求失败")
```
这段代码中,我们首先使用Requests库发送GET请求获取网页内容,然后使用BeautifulSoup解析HTML,提取网页标题信息并打印输出。通过这种方法,我们可以轻松地获取网页中的相关信息。
#### 5.2 处理爬取到的数据
在网页爬取过程中,我们通常需要处理爬取到的数据,可能包括数据清洗、转换、存储等操作。下面是一个简单示例:
```python
# 假设我们要提取网页中所有链接
links = soup.find_all('a')
# 打印所有链接的文本和链接地址
for link in links:
print(f"链接文本: {link.text}, 链接地址: {link.get('href')}")
```
这段代码中,我们使用BeautifulSoup找到网页中所有的链接,并循环输出每个链接的文本和地址。这是处理爬取数据的简单示例,根据具体情况,你可能需要进行更复杂的数据处理操作。
#### 5.3 编写一个简单的爬虫程序
最后,我们可以将上述示例整合成一个简单的爬虫程序,实现对指定网页的信息提取:
```python
import requests
from bs4 import BeautifulSoup
def simple_web_spider(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.text
print(f"网页标题: {title}")
links = soup.find_all('a')
for link in links:
print(f"链接文本: {link.text}, 链接地址: {link.get('href')}")
else:
print("网页请求失败")
# 调用函数以爬取网页信息
simple_web_spider('https://www.example.com')
```
通过将上述步骤整合成一个函数,我们可以更加方便地编写和调用爬虫程序,实现对网页信息的获取和处理。
通过本节的学习,相信你已经掌握了如何利用Requests和BeautifulSoup库进行网页爬取,并能够实践编写简单的爬虫程序。接下来的章节将进一步探讨爬虫的进阶技巧和实践案例,帮助你更深入地了解和应用网络爬虫技术。
# 6. 进阶与实践
在网络爬虫领域中,随着技术的发展和应用的深入,我们需要更多的进阶与实践经验来应对各种挑战。本章将深入讨论一些进阶的话题,并结合实际案例分享经验和总结。让我们一起探讨以下内容:
#### 6.1 网站反爬虫对策
网站为了保护自身数据和资源,往往会采取一些反爬虫对策,限制爬虫程序的访问。常见的反爬手段包括设置访问频率限制、验证码识别、动态加载数据等。在面对这些反爬虫对策时,可以尝试使用代理IP、设置请求头、模拟登录等方法来提高爬虫的稳定性和效率。
```python
# 代码示例:使用代理IP访问网站
import requests
url = 'http://example.com'
proxy = {
'http': 'http://127.0.0.1:8888',
'https': 'https://127.0.0.1:8888'
}
response = requests.get(url, proxies=proxy)
print(response.text)
```
总结:在面对网站反爬虫对策时,可以通过设置代理IP等方式来规避限制,但需要注意尊重网站的合法权益,遵守网络道德准则。
#### 6.2 数据存储与持久化
在进行网页爬取后,我们通常需要将爬取到的数据进行存储和持久化,以供后续分析和应用。可以选择将数据存储到数据库中,如MySQL、MongoDB等,也可以将数据保存为文本文件或CSV文件等格式。
```python
# 代码示例:将爬取到的数据存储到MySQL数据库
import pymysql
# 连接MySQL数据库
db = pymysql.connect(host='localhost', user='root', password='password', database='testdb')
cursor = db.cursor()
# 创建数据表
cursor.execute("CREATE TABLE IF NOT EXISTS data (id INT AUTO_INCREMENT PRIMARY KEY, content TEXT)")
# 插入数据
data = "Some crawled data..."
cursor.execute("INSERT INTO data (content) VALUES (%s)", (data,))
db.commit()
# 关闭连接
cursor.close()
db.close()
```
总结:数据存储是网络爬虫过程中至关重要的一环,合理选择存储方式和数据结构,能够提高数据的管理和应用效率。
#### 6.3 实战案例分享与总结
通过实际案例的分享和总结,我们可以更好地理解网络爬虫的应用场景、技术挑战和解决方案。在实战中不断积累经验,才能更好地提升网络爬虫的技能和水平。
在这里,我们分享一个实战案例:利用Requests库和BeautifulSoup库爬取目标网站的新闻信息,并将数据存储到本地数据库中。这个案例结合了前面章节所学的知识,展现了网络爬虫实战的整个流程和技术要点。
通过不断地实践和总结,我们能够更好地掌握网络爬虫的技术核心,应对各种挑战和问题,实现更广泛的应用和价值。
希望本章内容能够帮助读者进一步深入网络爬虫领域,探索更多的可能性和机遇。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
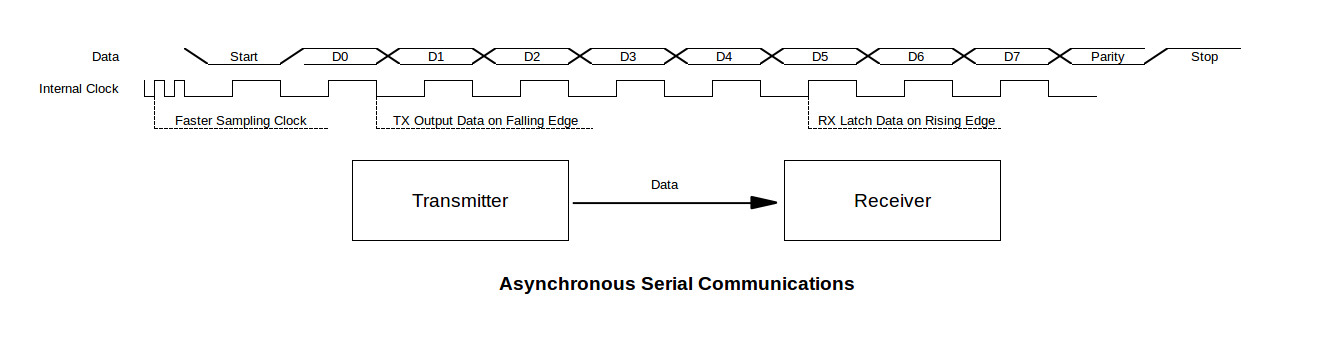
S32K SPI开发者必读:7大优化技巧与故障排除全攻略
# 摘要
本文深入探讨了S32K微控制器的串行外设接口(SPI)技术,涵盖了从基础知识到高级应用的各个方面。首先介绍了SPI的基础架构和通信机制,包括其工作原理、硬件配置以及软件编程要点。接着,文章详细讨论了SPI的优化技巧,涵盖了代码层面和硬件性能提升的策略,并给出了故障排除及稳定性的提升方法。实战章节着重于故障排除,包括调试工具的使用和性能瓶颈的解决。应用实例和扩展部分分析了SPI在
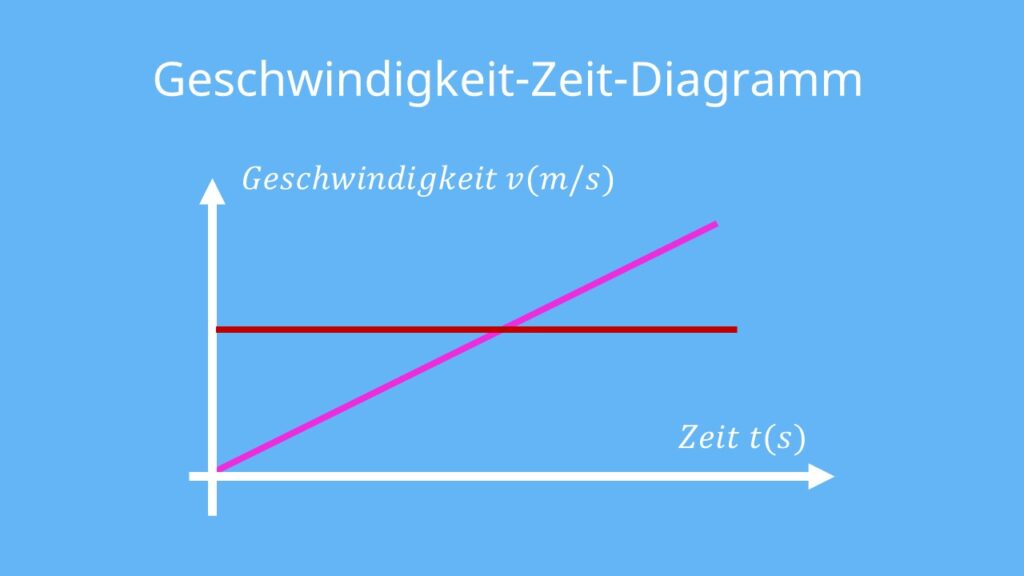
图解数值计算:快速掌握速度提量图的5个核心构成要素
# 摘要
本文全面探讨了速度提量图的理论基础、核心构成要素以及在多个领域的应用实例。通过分析数值计算中的误差来源和减小方法,以及不同数值计算方法的特点,本文揭示了实现高精度和稳定性数值计算的关键。同时,文章深入讨论了时间复杂度和空间复杂度的优化技巧,并展示了数据可视化技术在速度提量图中的作用。文中还举例说明了速度提量图在
动态规划:购物问题的终极解决方案及代码实战

# 摘要
动态规划是解决优化问题的一种强大技术,尤其在购物问题中应用广泛。本文首先介绍动态规划的基本原理和概念,随后深入分析购物问题的动态规划理论,
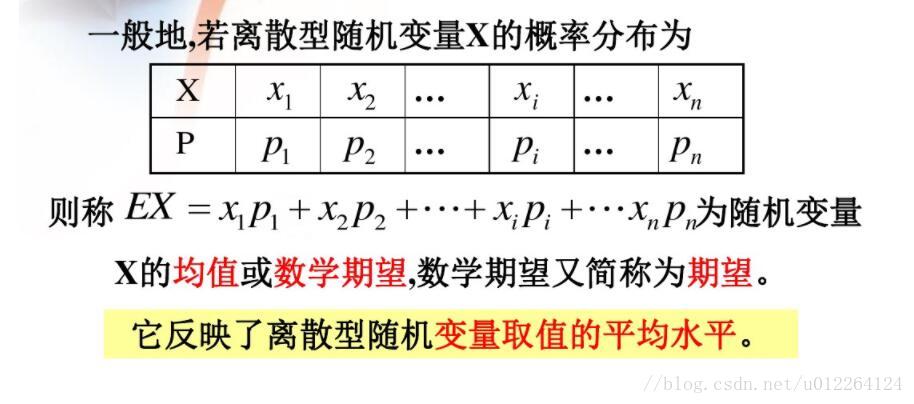
【随机过程精讲】:工程师版习题解析与实践指南
# 摘要
随机过程是概率论的一个重要分支,被广泛应用于各种工程和科学领域中。本文全面介绍了随机过程的基本概念、分类、概率分析、关键理论、模拟实现以及实践应用指南。从随机变量的基本统计特性讲起,深入探讨了各类随机过程的分类和特性,包括马尔可夫过程和泊松过程。文章重点分析了随机过程的概率极限定理、谱分析和最优估计方法,详细解释了如何通过计算机模拟和仿真软件来实现随机过程的模拟。最后,本文通过工程问题中随机过程的实际应用案例,以
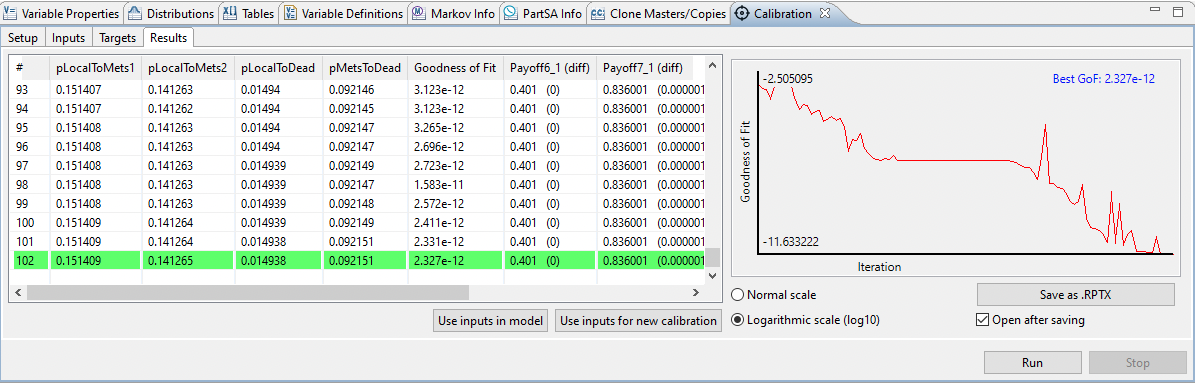
【QSPr高级应用案例】:揭示工具在高通校准中的关键效果
# 摘要
本论文旨在介绍QSPr工具及其在高通校准中的基础和应用。首先,文章概述了QSPr工具的基本功能和理论框架,探讨了高通校准的重要性及其相关标准和流程。随后,文章深入分析了QSPr工具的核心算法原理和数据处理能力,并提供了实践操作的详细步骤,包括数据准备、环境搭建、校准执行以及结果分析和优化。此外,通过具体案例分析展示了QSPr工具在不同设备校准中的定制
Tosmana配置精讲:一步步优化你的网络映射设置

# 摘要
Tosmana作为一种先进的网络映射工具,为网络管理员提供了一套完整的解决方案,以可视化的方式理解网络的结构和流量模式。本文从基础入门开始,详细阐述了网络映射的理论基础,包括网络映射的定义、作用以及Tosmana的工作原理。通过对关键网络映射技术的分析,如设备发现、流量监控,本文旨在指导读者完成Tosmana网络映射的实战演练,并深入探讨其高级应用,包括自动化、安全威胁检测和插件应用。最
【Proteus与ESP32】:新手到专家的库添加全面攻略

# 摘要
本文详细介绍Proteus仿真软件和ESP32微控制器的基础知识、配置、使用和高级实践。首先,对Proteus及ESP32进行了基础介绍,随后重点介绍了在Proteus环境下搭建仿真环境的步骤,包括软件安装、ESP32库文件的获取、安装与管理。第三章讨论了ESP32在Proteus中的配置和使用,包括模块添加、仿真
【自动控制系统设计】:经典措施与现代方法的融合之道
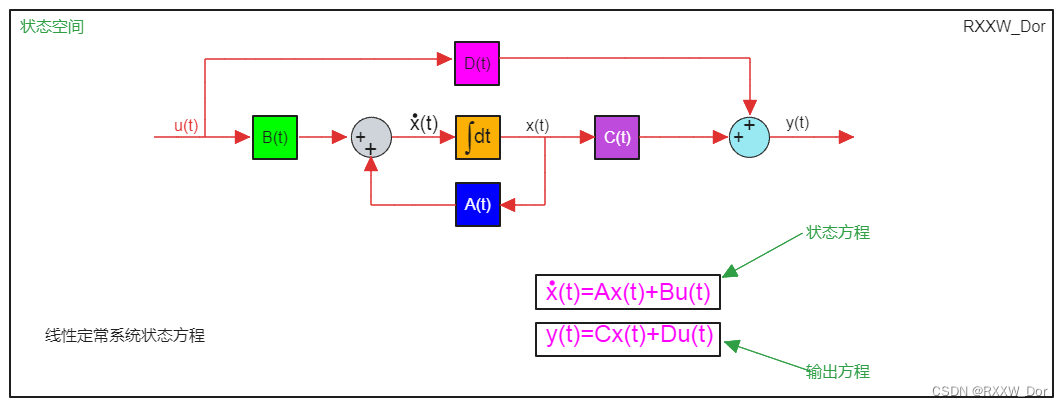
# 摘要
自动控制系统是工业、航空、机器人等多个领域的核心支撑技术。本文首先概述了自动控制系统的基本概念、分类及其应用,并详细探讨了经典控制理论基础,包括开环和闭环控制系统的原理及稳定性分析方法。接着,介绍了现代控制系统的实现技术,如数字控制系统的原理、控制算法的现代实现以及高级控制策略。进一步,本文通过设计实践,阐述了控制系统设计流程、仿真测试以及实际应用案例。此外,分析了自动控制系统设计的当前挑战和未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )