C#枚举内存管理:避免泄漏的5大策略
发布时间: 2024-10-19 17:19:20 阅读量: 8 订阅数: 19 
# 1. C#枚举类型基础
## C#枚举类型概念
C#中的枚举类型(enum)是一种值类型,允许开发者为一组命名的常量定义一个类型。这些常量在内部用整数值表示,每个枚举成员都对应一个整数。枚举类型使代码更易于阅读和维护,因为它提供了更具描述性的符号名称,而不是直接使用数字进行比较。
```csharp
public enum Color
{
Red,
Green,
Blue
}
```
## 枚举的声明与使用
声明枚举非常简单,只需使用enum关键字后跟枚举名称和枚举成员。在C#中,枚举成员默认从0开始递增,但也可以显式赋值。使用时,枚举类型可以提供类型安全,并且可以作为方法参数或者返回类型。
```csharp
Color myColor = Color.Green;
```
## 枚举与值类型的关联
枚举类型本身就是一种特殊的值类型。与整数不同,枚举类型提供了编译时的类型检查,可以减少错误。它们被存储在栈上,而不是堆上,这意味着它们的内存分配和释放更加高效,不会像引用类型那样受到垃圾回收延迟的影响。
```csharp
// 在方法中使用枚举
public void ChangeColor(Color newColor)
{
// ...
}
```
通过本章的学习,我们将建立对C#枚举类型的基本理解,为后续章节中涉及内存管理以及优化策略的学习打下坚实的基础。
# 2. 内存管理理论与实践
### 2.1 内存泄漏的原理
#### 2.1.1 内存泄漏定义和影响
内存泄漏指的是程序在分配内存后,未能在不再需要时释放这部分内存,导致随着时间推移可用内存逐渐减少。这种内存的持续消耗会直接影响程序的性能,甚至导致程序崩溃。内存泄漏的后果可能会从轻微的性能下降到严重的系统故障不等,尤其是在多用户、高并发的服务器端应用程序中。
在解释内存泄漏的定义时,我们可以使用一个简单的比喻:假设你有一个水池,每天都要打开龙头加水,而每次加水后都需要关闭龙头来停止水流。如果你忘记了关闭龙头,水就会持续不断地流入水池,最终导致水池溢出。在计算机内存管理中,内存泄漏就像那个忘记关闭的水龙头。
#### 2.1.2 内存泄漏的常见原因
内存泄漏通常由以下几种情况引起:
1. 非静态内部类持有外部类实例:在Java中,非静态内部类会隐式地持有外部类的引用,如果此类对象未被适当管理,可能导致外部类无法被回收。
2. 长生命周期对象持有短生命周期对象的引用:当一个长生命周期的对象持有一个短生命周期对象的引用时,短生命周期的对象无法被垃圾回收器回收,即使它已经不再被需要。
3. 静态集合(如静态集合)无限制增长:静态集合被多个对象共享,如果它的内容不断增长而没有相应的清理机制,那么这些对象也会导致内存泄漏。
4. 使用static变量持有大对象或集合:静态变量的生命周期是整个应用程序的生命周期,如果将其指向大对象或集合,会阻止这些对象的回收。
### *** 垃圾回收机制
#### 2.2.1 垃圾回收基础
垃圾回收(Garbage Collection,简称GC)是.NET运行时提供的自动内存管理机制,用来回收不再被引用的对象所占用的内存。这种机制极大地简化了开发人员对内存管理的负担。当一个对象不再有任何引用指向它时,它就成为了垃圾回收器的目标。
在.NET中,垃圾回收器运行时,会暂停所有托管代码的执行(Stop-The-World,简称STW)。然后,它会遍历所有托管对象,构造对象图,确定哪些对象是可达的(即应用程序仍在使用),哪些对象是不可达的(即垃圾)。不可达对象随后会被标记为垃圾,并被回收。
#### 2.2.2 垃圾回收的工作原理
垃圾回收器的运作基于几个核心概念,包括代(Generations)、压缩(Compaction)、和根(Roots)。在.NET中,对象被分配到不同的代中,这些代根据它们存活的时间进行划分。常见的有三代:第0代、第1代和第2代。
第0代用于新创建的对象。当第0代中的对象存活下来,它们就会被移动到第1代,然后是第2代。代的概念允许垃圾回收器更高效地工作,因为通常新对象的生命周期较短,而老对象则更有可能存活更长时间。
压缩是垃圾回收过程的一部分,它将存活的对象移动到堆的一端,从而减少内存碎片。这有助于提高应用程序的性能,因为它可以减少内存分配的开销。
根是垃圾回收器在构建对象图时会查找的引用,包括局部变量和静态变量等。如果一个对象可以通过根直接或间接地访问到,那么它就不是垃圾。
#### 2.2.3 如何与垃圾回收器交互
虽然.NET运行时提供了自动垃圾回收机制,但开发者仍然可以通过几种方式与之交互,以优化垃圾回收行为:
- 使用`GC.Collect`方法强制执行垃圾回收。但是,这个方法并不推荐使用,因为它会强制启动Stop-The-World暂停,这会直接影响应用程序的性能。
- 使用`GCCollectionMode`枚举指定垃圾回收的时机。
- 利用`WeakReference`类为特定对象创建弱引用。这允许垃圾回收器回收那些只被弱引用的对象。
### 2.3 C#中引用类型的生命周期
#### 2.3.1 变量的作用域和生命周期
在C#中,变量的生命周期是由其作用域决定的。变量的声明点定义了其作用域的开始,而作用域结束时,变量即被清除。引用类型变量通常存储在托管堆(Managed Heap)上,而值类型变量则根据其使用情况存储在栈或堆上。
当一个函数或代码块结束执行时,局部变量会离开作用域,其引用的内存会被垃圾回收器回收。然而,如果一个对象的引用被某个静态字段或者全局变量持有,那么它就不会被垃圾回收。
#### 2.3.2 引用计数与内存回收
尽管.NET运行时不使用引用计数(Reference Counting)作为垃圾回收的主机制,但在某些情况下,引用计数的概念仍然适用,例如在引用类型内部。引用计数是一个计数器,记录有多少引用指向一个对象。当计数器为零时,对象被回收。然而,引用计数不能解决循环引用的问题,因此.NET使用标记-清除算法来处理复杂的内存回收场景。
当垃圾回收器运行时,它会标记所有可达对象,然后清除未被标记的对象。这个过程会考虑整个对象图,从根开始,递归地检查每个可达的对象。
```csharp
// 示例代码
class Program
{
static void Main(string[] args)
{
MyClass obj = new MyClass();
obj = null; // 取消引用,让obj成为垃圾回收的目标
// GC.Collect(); // 强制进行垃圾回收,通常不推荐
}
}
class MyClass
{
// 类的字段和方法
}
```
在上述代码示例中,创建了`MyClass`的实例,并将其赋值给`obj`变量。当`obj`被设置为null时,该对象不再有活跃的引用指向它,从而成为垃圾回收的目标。尽管在实际应用中,我们通常不需要显式地进行垃圾回收,但理解这个过程对于编写高效的代码是很有帮助的。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 C# 枚举的方方面面,提供全面的指南和高级技巧。从枚举在 ORM 和数据库交互中的应用到性能优化、并发编程和模式匹配,该专栏涵盖了枚举在各种场景中的使用。此外,还探讨了枚举的智能转换、扩展、序列化和 UI 设计中的应用。该专栏还提供了枚举在资源管理、依赖注入、事件驱动架构和 LINQ 查询中的实用策略。通过深入分析异常处理、可读性和维护性,该专栏旨在帮助开发人员充分利用 C# 枚举,编写高效、可维护且可扩展的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【HDFS切片与性能】:MapReduce作业性能提升的关键技术
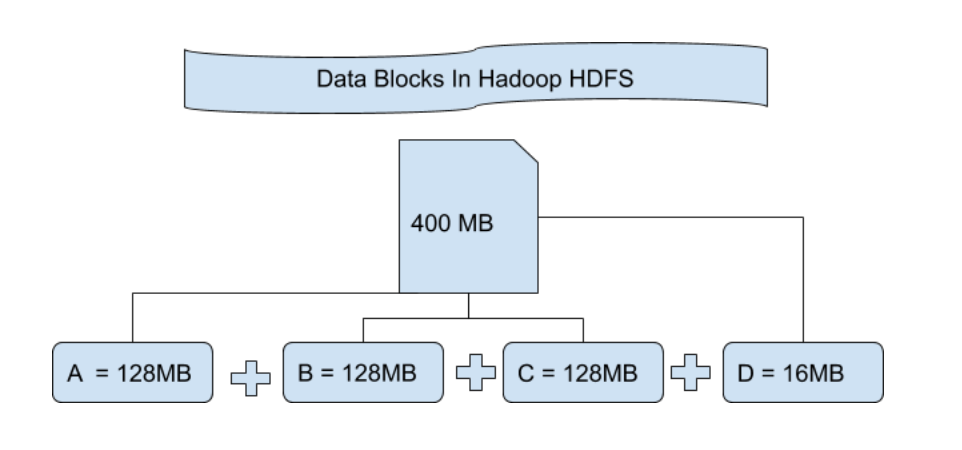
# 1. HDFS切片原理详解
Hadoop分布式文件系统(HDFS)是大数据存储的基础,其切片机制对于后续的MapReduce作业执行至关重要。本章将深入探讨HDFS切片的工作原理。
## 1.1 切片概念及其作用
在HDFS中,切片是指将一个大文件分割成多个小块(block)的过程。每个block通常为128MB大小,这使得Hadoop能够以并行化的方式处理存
HDFS监控与告警:实时保护系统健康的技巧
# 1. HDFS监控与告警基础
在分布式文件系统的世界中,Hadoop分布式文件系统(HDFS)作为大数据生态系统的核心组件之一,它的稳定性和性能直接影响着整个数据处理流程。本章将为您揭开HDFS监控与告警的基础面纱,从概念到实现,让读者建立起监控与告警的初步认识。
## HDFS监控的重要性
监控是维护HDFS稳定运行的关键手段,它允许管理员实时了解文件系统的状态,包括节点健康、资源使用情况和数据完整性。通过监控系
【HDFS HA集群的数据副本管理】:副本策略与数据一致性保障的最佳实践

# 1. HDFS高可用集群概述
Hadoop分布式文件系统(HDFS)作为大数据处理框架中的核心组件,其高可用集群的设计是确保大数据分析稳定性和可靠性的关键。本章将从HDFS的基本架构出发,探讨其在大数据应用场景中的重要作用,并分析高可用性(High Availability, HA)集群如何解决单点故障问题,提升整个系统的可用性和容错性。
HDFS高可用
HDFS块大小与数据复制因子:深入分析与调整技巧

# 1. HDFS块大小与数据复制因子概述
在大数据生态系统中,Hadoop分布式文件系统(HDFS)作为存储组件的核心,其块大小与数据复制因子的设计直接影响着整个系统的存储效率和数据可靠性。理解这两个参数的基本概念和它们之间的相互作用,对于优化Hadoop集群性能至关重要。
HDFS将文件划分为一系列块(block),这些块是文件系统的基本单位,负责管理数据的存储和读取。而数据复
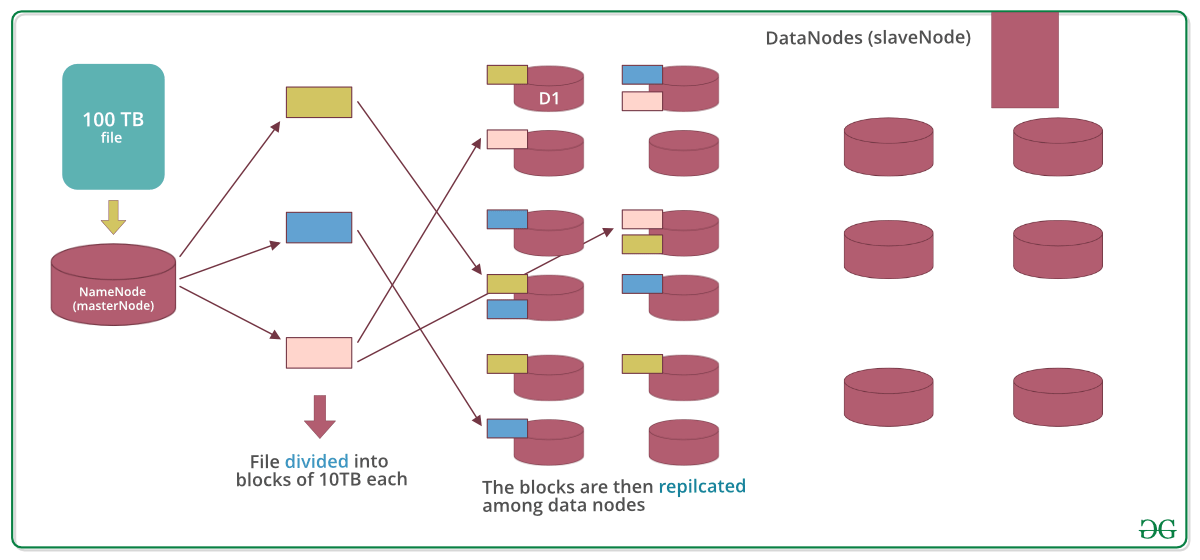
HDFS副本数与数据恢复时间:权衡数据可用性与恢复速度的策略指南
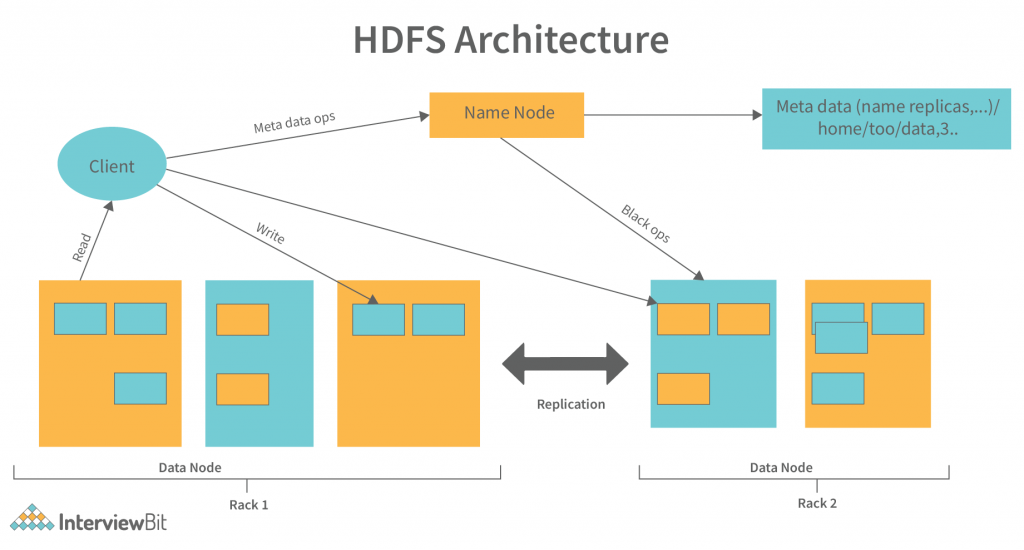
# 1. HDFS基础知识与数据副本机制
Hadoop分布式文件系统(HDFS)是Hadoop框架的核心组件之一,专为存储大量数据而设计。其高容错性主要通过数据副本机制实现。在本章中,我们将探索HDFS的基础知识和其数据副本机制。
## 1.1 HDFS的组成与架构
HDFS采用了主/从架构,由NameNode和DataNode组成。N
HDFS高可用性部署指南:Zookeeper配置与管理技巧详解
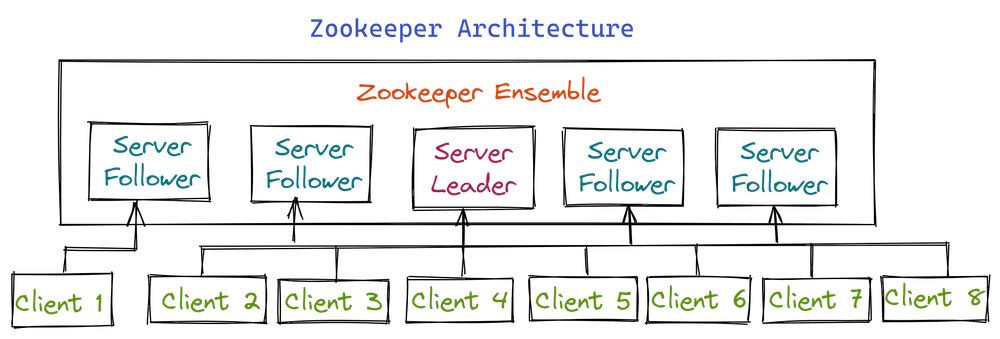
# 1. HDFS高可用性概述
在当今的大数据生态系统中,Hadoop分布式文件系统(HDFS)由于其强大的数据存储能力与容错机制,已成为众多企业数据存储的首选。然而,随着数据量的不断增长和对系统稳定性要求的提高,构建高可用的HDFS成为了保障业务连续性的关键。本章节将从HDFS高可用性的必要性、实现机制以及优势等维度,为读者提供一个全面的概述。
## HDFS高可用性的必要性
HDFS
【HDFS Block故障转移】:提升系统稳定性的关键步骤分析
# 1. HDFS基础架构和故障转移概念
## HDFS基础架构概述
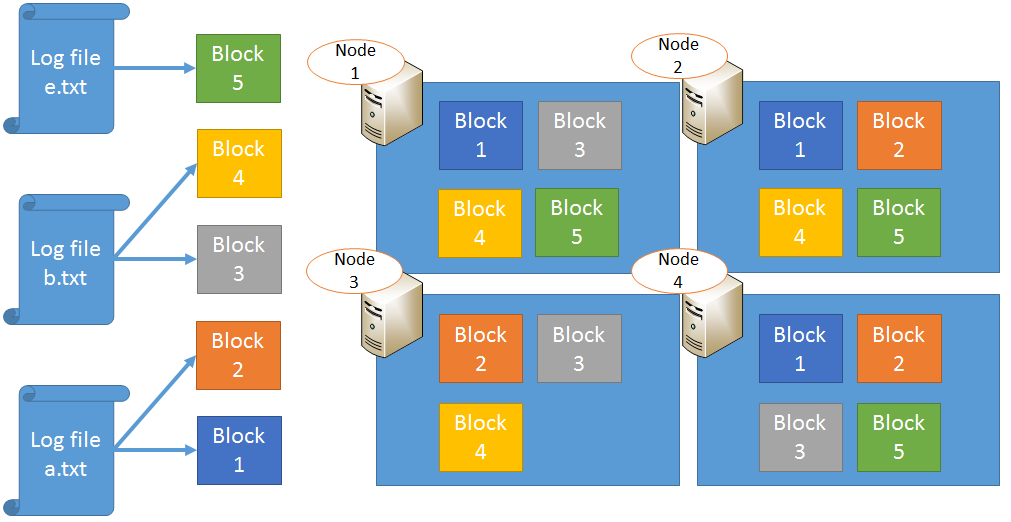
Hadoop分布式文件系统(HDFS)是Hadoop框架的核心组件之一,专为处理大数据而设计。其架构特点体现在高度容错性和可扩展性上。HDFS将大文件分割成固定大小的数据块(Block),默认大小为128MB,通过跨多台计算机分布式存储来保证数据的可靠性和处理速度。NameNode和DataNo
【HDFS的网络配置优化】:提升数据传输效率的网络设置策略
# 1. HDFS网络配置基础
## Hadoop分布式文件系统(HDFS)的网络配置是构建和维护高效能、高可用性数据存储解决方案的关键。良好的网络配置能够确保数据在节点间的高效传输,减少延迟,并增强系统的整体可靠性。在这一章节中,我们将介绍HDFS的基础网络概念,包括如何在不同的硬件和网络架构中配置HDFS,以及一些基本的网络参数,如RPC通信、心跳检测和数据传输等。
【场景化调整】:根据不同应用环境优化HDFS块大小策略

# 1. HDFS块大小的基本概念
在大数据处理领域,Hadoop分布式文件系统(HDFS)作为存储基础设施的核心组件,其块大小的概念是基础且至关重要的。HDFS通过将大文件分割成固定大小的数据块(block)进行分布式存储和处理,以优化系统的性能。块的大小不仅影响数据的存储效率,还会对系统的读写速
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )