HDFS监控与告警:实时保护系统健康的技巧
发布时间: 2024-10-28 20:52:34 阅读量: 28 订阅数: 32 

java+sql server项目之科帮网计算机配件报价系统源代码.zip
# 1. HDFS监控与告警基础
在分布式文件系统的世界中,Hadoop分布式文件系统(HDFS)作为大数据生态系统的核心组件之一,它的稳定性和性能直接影响着整个数据处理流程。本章将为您揭开HDFS监控与告警的基础面纱,从概念到实现,让读者建立起监控与告警的初步认识。
## HDFS监控的重要性
监控是维护HDFS稳定运行的关键手段,它允许管理员实时了解文件系统的状态,包括节点健康、资源使用情况和数据完整性。通过监控系统,我们可以及时发现并响应性能瓶颈或故障,防止数据丢失或系统宕机。
## 告警的必要性
告警系统则是在监控的基础上,为管理员提供了一个反应机制。当监控指标超出预设阈值时,告警会通知管理员采取行动。一个有效的告警系统应能准确及时地传递关键信息,同时避免不重要的信息泛滥造成“告警疲劳”。
## 监控与告警的基本实施步骤
1. **确定监控指标**:选择对HDFS系统稳定性影响最大的指标,如NameNode和DataNode的状态、磁盘容量和I/O性能等。
2. **配置监控工具**:安装并配置适合HDFS的监控工具,如Ambari, Ganglia,或Zabbix等。
3. **设置告警阈值**:根据历史数据和系统容量,合理设定告警阈值。
4. **告警通知方式**:配置告警通知通道,如邮件、短信、企业内部即时通讯工具等。
5. **测试与优化**:定期检查监控告警系统的有效性,并根据实际运行情况优化设置。
通过以上步骤,可以为HDFS建立起一套基础的监控和告警机制,为后续的深入分析和优化打下坚实的基础。
# 2. HDFS监控技术深入解析
在深入了解 Hadoop 分布式文件系统 (HDFS) 的监控技术之前,我们需要建立一个对 HDFS 基本运作模式的理解。HDFS 是由 NameNode 和 DataNode 组成的分布式系统。NameNode 负责管理文件系统的命名空间以及客户端对文件的访问。DataNode 则负责存储实际的数据,并在需要的时候将数据提供给客户端。一个有效的监控系统能够实时收集和分析 NameNode 和 DataNode 的状态,磁盘的使用情况以及 I/O 的性能,以此来保证 HDFS 的高可用性和稳定性。
## 2.1 HDFS的核心监控指标
### 2.1.1 NameNode和DataNode状态监控
在HDFS系统中,NameNode是管理整个文件系统的“大脑”,因此,保持NameNode的健康状态是至关重要的。监控 NameNode,我们通常关注以下指标:
- **NameNode堆内存使用情况:** 高内存使用可能表明需要更多的资源或者内存泄漏问题。
- **活跃/备用状态:** 保证系统至少有一个处于激活状态的 NameNode。
- **连接的 DataNode 数量:** 检查是否有过多的 DataNode 失联,这可能预示着网络问题或者硬件故障。
对于 DataNode 的监控指标,我们可以考虑以下内容:
- **DataNode 启动时间:** 这能够帮助我们了解系统重启的效率。
- **磁盘剩余空间:** 保证存储空间的充足,避免因为磁盘满导致的服务不可用。
- **读写操作次数:** 监控性能指标,过多的 I/O 操作可能导致性能瓶颈。
下面是一个使用Java Management Extensions (JMX) 来监控 NameNode 堆内存使用的代码示例。
```java
import javax.management.MBeanServerConnection;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
***.MalformedURLException;
public class NameNodeMonitoring {
public static void main(String[] args) {
try {
// 创建 JMX 连接
JMXServiceURL url = new JMXServiceURL("service:jmx:rmi:///jndi/rmi://<NAME_NODE_HOST>:<PORT>/jmxrmi");
JMXConnector jmxc = JMXConnectorFactory.connect(url);
MBeanServerConnection mbsc = jmxc.getMBeanServerConnection();
// 获取 NameNode 内存使用情况
long heapMemoryUsage = (Long) mbsc.getAttribute(
mbsc.queryMBeans(new ObjectName("Hadoop:service=NameNode,name=NameNodeInfo"), null).iterator().next(),
"HeapMemoryUsage"
);
System.out.println("NameNode Heap Memory Usage: " + heapMemoryUsage + " bytes");
// 关闭 JMX 连接
jmxc.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
在这个代码块中,我们首先建立了连接到 NameNode 的 JMX 连接,然后查询了 NameNode 信息的 MBean 来获取堆内存使用情况。这是实时监控的一个简单例子,实际监控系统会更加复杂,需要集成告警和历史数据分析等功能。
### 2.1.2 磁盘容量和I/O监控
磁盘容量的监控对于预防存储空间不足引起的故障至关重要,磁盘 I/O 监控则能够帮助我们及时发现性能瓶颈。
- **磁盘容量利用率:** 保证数据分布在足够的存储空间上,避免空间不足影响服务。
- **读写带宽:** 检测磁盘的读写性能,优化数据块的存储位置以提高效率。
要实现这些监控指标,可以使用如下命令行工具:
```bash
hdfs dfsadmin -report
```
该命令可以提供 NameNode 和 DataNode 的相关信息,其中就包含了磁盘利用率和 I/O 指标。要监控的更细致,我们还需要定期执行如 `iostat`、`df` 等Linux命令来检查磁盘使用情况和 I/O 性能。
## 2.2 实时监控数据的收集方法
### 2.2.1 使用JMX收集监控数据
通过JMX收集监控数据是一种非常流行的方式,因为它可以很便捷地获取Java应用程序的运行时信息,包括内存使用、线程使用、垃圾回收情况、GC情况等。对于Hadoop系统来说,可以通过JMX来获取HDFS的实时状态。
JMX提供了一种从HDFS组件(NameNode,DataNode)获取操作和性能指标的机制。这些指标对于实时监控和故障诊断至关重要。我们可以编写程序通过JMX连接到HDFS的各个组件,并定期拉取监控数据。
```java
import java
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《HDFS终极指南》是一份全面的专栏,深入探讨了分布式存储系统的关键方面。它涵盖了HDFS的文件结构、数据块、NameNode和DataNode的内部机制,以及高效的文件定位策略。此外,专栏还提供了优化数据读写、管理小文件、确保数据可靠性、加强安全保护和提高性能的实用建议。通过深入了解HDFS的联邦、快照、故障恢复、数据流动、与MapReduce的协同作用、版本控制、数据完整性、网络架构、文件生命周期、数据一致性和可用性,以及读写操作和监控技术,该专栏为读者提供了全面理解和优化HDFS部署所需的知识和见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MySQL数据库性能提升秘籍】:揭秘视图与索引的最佳实践策略
# 摘要
本文系统地探讨了MySQL数据库性能优化的各个方面,从索引的基础知识和优化技术,到视图的使用和性能影响,再到综合应用实践和性能监控工具的介绍。文中不仅阐述了索引和视图的基本概念、创建与管理方法,还深入分析了它们对数据库性能的正负面影响。通过真实案例的分析,本文展示了复杂查询、数据仓库及大数据环境下的性能优化策略。同时,文章展望了性能优化的未来趋势,包括
揭秘Android启动流程:UBOOT在开机logo显示中的核心作用与深度定制指南
# 摘要
本文旨在全面介绍Android系统的启动流程,重点探讨UBOOT在嵌入式系统中的架构、功能及其与Android系统启动的关系。文章从UBOOT的起源与发展开始,详细分析其在启动引导过程中承担的任务,以及与硬件设备的交互方式。接着,本文深入阐述了UBOOT与Kernel的加载过程,以及UBOOT在显示开机logo和提升Android启动性能方面的
【掌握材料属性:有限元分析的基石】:入门到精通的7个技巧
# 摘要
有限元分析是工程学中用于模拟物理现象的重要数值技术。本文旨在为读者提供有限元分析的基础知识,并深入探讨材料属性理论及其对分析结果的影响。文章首先介绍了材料力学性质的基础知识,随后转向非线性材料行为的详细分析,并阐述了敏感性分析和参数优化的重要性。在有限元软件的实际应用方面,本文讨论了材料属性的设置、数值模拟技巧以及非线性问题的处理。通过具体的工程结构和复合材料分析实例,文章展示了有限元分析在不同应用
中断处理专家课:如何让处理器智能响应外部事件

# 摘要
中断处理是计算机系统中关键的操作之一,它涉及到处理器对突发事件的快速响应和管理。本文首先介绍了中断处理的基本概念及其重要性,随后深
CMW100 WLAN故障快速诊断手册:立即解决网络难题
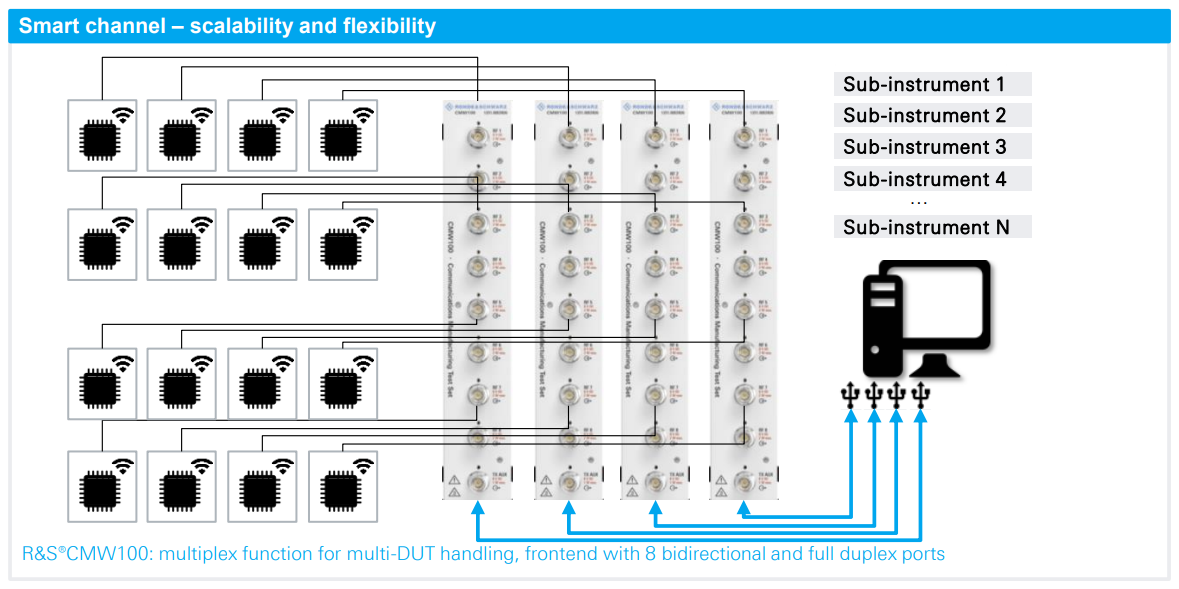
# 摘要
随着无线局域网(WLAN)技术的广泛应用,网络故障诊断成为确保网络稳定性和性能的关键环节。本文深入探讨了WLAN故障诊断的基础知识,网络故障的理论,以及使用CMW100这一先进的诊断工具进行故障排除的具体案例。通过理解不同类型的WLAN故障,如信号强度问题、接入限制和网络配置错误,并应用故障诊断的基本原则和工具,本文提供了对网络故障分析和解决过程的全面视角。文章详细介绍了CMW100的功能、特点及在实战中如何应对无线信号覆盖问题、客户端接入问题和网络安全漏
【Vue.js与AntDesign】:创建动态表格界面的最佳实践

# 摘要
随着前端技术的快速发展,Vue.js与AntDesign已成为构建用户界面的流行工具。本文旨在为开发者提供从基础到高级应用的全面指导。首先,本文概述了Vue.js的核心概念,如响应式原理、组件系统和生命周期,以及其数据绑定和事件处理机制。随后,探讨了AntDesign组件库的使用,包括UI组件的定制、表单和表格组件的实践。在此基础上,文章深入分析了动态表格
【PCIe 5.0交换与路由技术】:高速数据传输基石的构建秘籍
# 摘要
本文深入探讨了PCIe技术的发展历程,特别关注了PCIe 5.0技术的演进与关键性能指标。文章详细介绍了PCIe交换架构的基础组成,包括树状结构原理、路由机制以及交换器与路由策略的实现细节。通过分析PCIe交换与路由在服务器应用中的实践案例,本文展示了其在数据中心架构和高可用性系统中的具体应用,并讨论了故障诊断与性能调优的方法。最后,本文对PCIe 6.0的技术趋势进行了展望,并探讨了PCIe交换与路由技术的未来创新发展。
# 关键字
PCIe技术;性能指标;交换架构;路由机制;服务器应用;故障诊断
参考资源链接:[PCI Express Base Specification R
【16位加法器测试技巧】:高效测试向量的生成方法
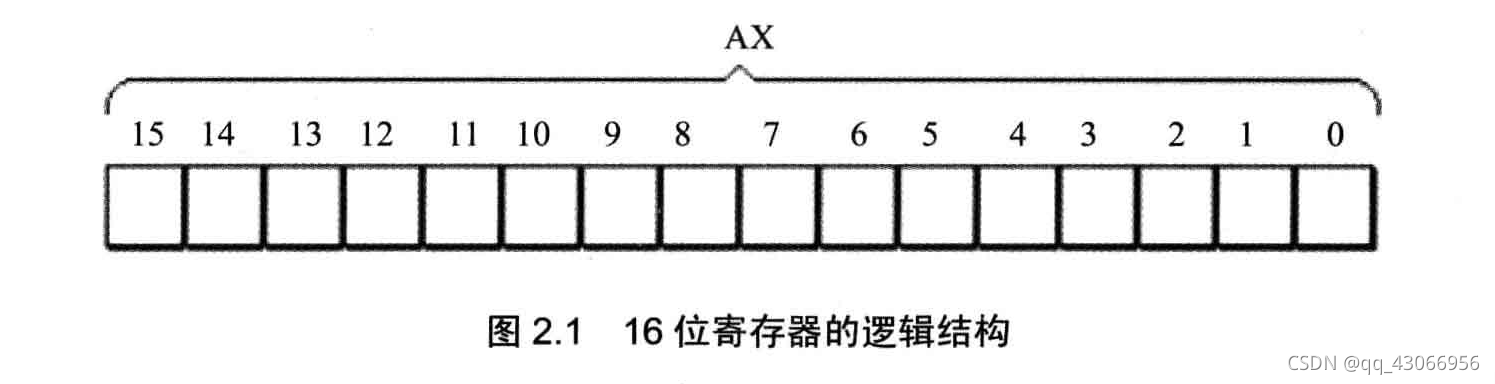
# 摘要
本文探讨了16位加法器的基本原理与设计,并深入分析了测试向量的理论基础及其在数字电路测试中的重要性。文章详细介绍了测试向量生成的不同方法,包括随机
三菱FX3U PLC在智能制造中的角色:工业4.0的驱动者

# 摘要
随着工业4.0和智能制造的兴起,三菱FX3U PLC作为自动化领域的关键组件,在生产自动化、数据采集与监控、系统集成中扮演着越来越重要的角色。本文首先概述智能制造
【PCIe IP核心建造术】:在FPGA上打造高性能PCIe接口
# 摘要
PCIe技术作为高带宽、低延迟的计算机总线技术,在现代计算机架构中扮演着关键角色。本文从PCIe技术的基本概念出发,详细介绍了FPGA平台与PCIe IP核心的集成,包括FPGA的选择、PCIe IP核心的架构与优化。随后,文章探讨了PCI
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )