深入剖析HDFS:数据块、NameNode和DataNode的内部机制
发布时间: 2024-10-28 19:43:34 阅读量: 71 订阅数: 34 

HDFS的概念-namenode和datanode.pdf
# 1. HDFS概述
## 1.1 HDFS的定义与功能
Hadoop分布式文件系统(HDFS)是Hadoop框架的核心组件之一,专为存储大量数据而设计,具有高容错性和良好的扩展性。作为一个高度容错的系统,HDFS能存储高达PB级别的数据,且适合运行在廉价的硬件上。
## 1.2 HDFS的设计哲学
HDFS的设计哲学是“硬件失效是常态”。这导致了系统在设计时就充分考虑了冗余存储和数据备份策略,以保证在遇到单点故障时,数据不会丢失。此外,HDFS的读写策略也非常适合大数据处理,如MapReduce框架。
## 1.3 HDFS与传统文件系统对比
与传统的文件系统相比,HDFS的主要区别在于它能够处理超大文件(GB至TB级别),并且提供了数据的容错能力。这些特性使得HDFS成为进行大数据分析和存储的首选文件系统。然而,它并非设计用于处理大量小文件,这在HDFS中可能会带来性能问题。
HDFS为大数据生态系统提供了坚实的基础,使得大规模数据集能够被存储和分析,这是目前云计算和数据密集型计算领域的关键技术之一。通过后续的章节我们将深入了解HDFS的内部机制、架构和优化方法。
# 2. ```
# 第二章:HDFS的数据块机制
## 2.1 数据块的概念与设计原理
### 2.1.1 数据块的定义和作用
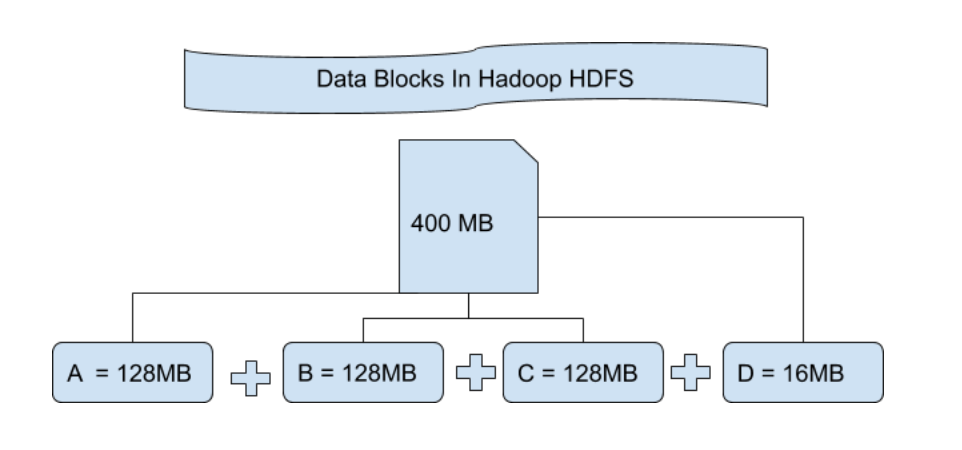
在Hadoop分布式文件系统(HDFS)中,数据不是以传统的文件形式存储,而是被划分为一系列的块(block),这些块再被分散存储到多个数据节点(DataNode)上。每个块默认大小是128MB(这个大小是可以调整的),但设计为在硬件配置较差的环境中运行时仍能维持良好的性能。
数据块设计的初衷是支持大规模数据集的存储,同时允许系统在不可靠的硬件上运行。它为HDFS提供了一种方式来处理大文件的存储,并且使得数据可以分布到多个物理存储设备上。
### 2.1.2 数据块大小的选择影响
选择合适的数据块大小对于HDFS的性能和资源使用效率至关重要。数据块过小会增加NameNode的内存消耗,因为NameNode需要为文件系统中每个块维护状态信息;另一方面,数据块太大则可能降低数据的读取效率,因为任何一个文件操作都需要加载整个数据块。
## 2.2 数据块的存储策略
### 2.2.1 副本放置策略
为了数据的高可用性和容错性,HDFS设计了多副本存储机制。默认情况下,每个数据块会有三个副本:一个位于写入节点,另外两个被随机放置到不同的节点上。这种策略保证了当某一节点失败时,数据仍然可通过其他节点访问。
副本放置策略也支持机架感知的特性,也就是说,HDFS会尽量将副本分散在不同的机架上,这样即便机架级别发生故障,也不会影响到所有数据副本的可用性。
### 2.2.2 数据块的读写过程
HDFS通过流式访问模型来实现高效的数据读写。在写入数据时,HDFS首先将数据以流的形式写入本地临时文件,然后在写入完成之后,再将数据块的副本分发到不同的DataNode上。这个过程是顺序的,有利于提高写入速度。
在读取数据时,客户端从NameNode获取块的位置信息,然后直接从包含数据块副本的DataNode读取数据。HDFS会尽量选择最近的数据节点进行数据读取,以减少网络传输的延迟。
## 2.3 数据块的容错机制
### 2.3.1 数据块的冗余存储
为了防止数据丢失,HDFS采用冗余存储机制。所有数据块都是以多个副本形式存在的。这种冗余机制保证了即使部分节点失败,数据仍然可以从其他副本中获取。
副本的数量可以根据实际需求调整,HDFS也支持数据的校验和,以此来确保数据在存储和传输过程中的完整性。
### 2.3.2 块健康状态的监控和维护
HDFS通过心跳机制和数据块报告来监控DataNode的健康状态。DataNode会定期向NameNode发送心跳信号以及包含数据块信息的报告。当发现某个副本数据损坏或者DataNode故障时,NameNode会安排数据的重新复制和平衡。
HDFS提供了一系列的命令和API来检查数据块的健康状态,例如使用`hdfs fsck`命令来检查文件系统的完整性,并修复可能出现的问题。
```bash
hdfs fsck /path/to/file -files -blocks -locations
```
上述命令可以用来检查指定路径下文件的健康状态,-files、-blocks和-locations参数分别显示文件列表、数据块列表以及数据块的位置。
以上为第二章详细内容的一部分,下一章节将继续深入探讨HDFS中NameNode的相关知识。
```
# 3. NameNode的架构与功能
## 3.1 NameNode的角色和职责
### 3.1.1 元数据管理
Hadoop分布式文件系统(HDFS)的核心组件之一是NameNode,它负责管理文件系统的命名空间和客户端对文件的访问。在HDFS中,所有的文件和目录都由NameNode以元数据的形式存储。这包括文件和目录的属性,如访问权限、修改时间、所有者信息以及文件到数据块的映射。一个关键点是NameNode不直接存储文件数据,而是管理数据块,这些数据块分散存储在集群中的DataNode上。
元数据的管理功能是NameNode最重要的职责。NameNode通过维护一个内存中的数据结构(通常是内存中的树形结构)来管理这些元数据。这个结构包含了所有的文件目录层次和每个文件的元数据信息。当客户端请求创建、删除、重命名或者读取一个文件时,它首先与NameNode通信,NameNode根据其元数据管理功能来处理这些请求。
### 3.1.2 文件系统命名空间的维护
NameNode负责维护整个文件系统的命名空间,使得HDFS能够支持非常大的文件和目录结构。命名空间的大小由配置参数`dfs.namenode.name.dir`定义,该参数指定了元数据存储的目录。
NameNode上的命名空间维护涉及以下关键任务:
- 命名空间的加载:在HDFS启动时,NameNode从磁盘加载命名空间。这个过程是通过读取编辑日志(edits log)和文件系统镜像(fsimage)完成的。
- 文件操作处理:文件的创建、删除、重命名以及修改属性等操作,都由NameNode进行处理并相应更新内存中的元数据结构。
- 快照管理:NameNode还负责命名空间的快照创建,快照可用于文件系统的备份和恢复。
NameNode通常运行在主节点上,对于保证高可用性和故障转移,有两个独立的NameNode:一个处于活跃状态,另一个处于待命状态。为了实现高可用性,还需要ZooKeeper、QuorumJournalManager等组件进行协调。
## 3.2 NameNode的高可用性设计
### 3.2.1 主备切换机制
高可用性(High Availability,简称HA)对于企业级Hadoop部署至关重要,因为单点故障(Single Point of Failure,简称SPOF)会极大增加宕机风险。在HDFS中实现高可用性设计的主要组件是ZooKeeper和QuorumJournalManager。
- **ZooKeeper集群**:ZooKeeper集群用于维护和同步整个分布式系统的状态信息,包括NameNode的健康状态。
- **QuorumJournalManager**:它管理共享的编辑日志,并确保在发生故障时,命名空间状态在两个NameNode之间是一致的。它是一个JournalNode集合,负责存储NameNode编辑日志,并保证多个NameNode间的数据一致性。
高可用性模式下的NameNode切换主要通过联邦和自动故障转移(failover)实现。当活跃的NameNode失效时,ZooKeeper会检测到,然后触发故障转移过程。待命的NameNode通过读取最新的编辑日志和元数据镜像进行同步,然后接管集群的控制权,成为新的活跃NameNode。
### 3.2.2 高可用性集群的搭建和配置
搭建高可用性HDFS集群涉及多个步骤,包括配置ZooKeeper集群、配置NameNode以及配置JournalNodes。以下是一个基本的配置步骤列表:
1. **配置ZooKeeper集群**:首先,需要设置ZooKeeper集群。至少需要三个ZooKeeper服务器,但为了提高性能和可靠性,一般会部署五个或更多的ZooKeeper实例。ZooKeeper集群的配置涉及到一系列的配置文件,如`zoo.cfg`。
2. **配置JournalNodes**:JournalNodes是运行在单独服务器上的守护进程,用来存储NameNode的编辑日志。每个JournalNode保存日志的一个副本,多个副本共同构成共享编辑日志的复制机制。它们之间的通信通过配置文件`journals.cfg`来管理。
3. **设置高可用性NameNode**:在NameNode的配置文件`hdfs-site.xml`中,需要设置与高可用性相关的参数,例如启用高可用性模式`dfs.ha.enabled`,指定活跃和待命NameNode的主机地址`dfs.namenode.rpc-address`,以及指定JournalNodes的列表`dfs.namenode.shared.edits.dir`。
4. **初始化元数据**:一旦配置完成,需要初始化NameNode的元数据,这通常通过格式化命令完成:`hdfs namenode -format`。
5. **启动集群**:最后,需要按照正确的顺序启动JournalNodes、两个NameNode和DataNode。
## 3.3 NameNode的性能优化
### 3.3.1 内存管理与优化
NameNode的性能是HDFS集群性能的关键因素之一。由于NameNode维护了整个文件系统的命名空间和客户端操作的元数据,它通常会成为系统的瓶颈。因此,优化NameNode的内存使用是提高HDFS性能的重要策略。
NameNode使用内存来缓存文件系统的命名空间和块映射信息,这样可以加速元数据操作。优化内存管理涉及以下几个方面:
- **堆内存大小调整**:通过调整JVM堆内存大小,可以改善性能。这通过`-Xmx`和`-Xms`参数来设置最大和初始堆内存大小。
- **使用高速缓存**:为了降低对磁盘的依赖,可以使用操作系统的pagecache来缓存文件系统元数据。
- **垃圾回收(GC)优化**:在生产环境中,应使用适合大型堆内存的垃圾回收器,例如G1 GC,它通过并发标记和清理周期来减少停顿时间。
### 3.3.2 垃圾回收机制的影响
垃圾回收(GC)是Java虚拟机(JVM)中一个自动释放不再使用的对象的过程。在NameNode中,由于大量元数据的管理,内存中的对象生命周期频繁变化,因此合理配置垃圾回收器,以避免长时间的停顿,对维持集群性能至关重要。
- **参数配置**:设置合适的GC参数是关键。对于NameNode这样的高性能应用场景,通常会配置G1 GC,并调整其参数以适应内存使用情况,例如`-XX:InitiatingHeapOccupancyPercent`参数,可以设定当堆内存使用率达到多少百分比时开始执行并发GC周期。
- **监控与调优**:持续监控GC行为并根据实际使用情况调优是非常重要的。GC日志提供了关于GC活动的详细信息,这些信息可以帮助识别潜在的性能问题并进行优化。
- **避免Full GC**:Full GC操作成本高昂,要尽量避免。在高负载的集群中,Full GC可能引起NameNode服务的长时间暂停,从而影响整个HDFS集群的性能。
在实践中,通常会根据具体的性能测试结果进行垃圾回收器的参数调整。例如,如果发现存在周期性的停顿问题,可以尝试通过调整新生代和老年代内存的比例,或者调整GC线程的优先级等方法来优化。
该章节内容详细介绍了NameNode作为HDFS核心组件的角色和职责,重点阐述了元数据管理机制和文件系统命名空间的维护,并讨论了高可用性设计的实现方式,包括主备切换机制和搭建HA集群的配置步骤。最后,分析了性能优化的策略,包括内存管理和垃圾回收机制的影响。通过这些介绍和分析,可以确保HDFS NameNode的高效和稳定运行,从而支撑大规模数据存储和计算需求。
# 4. DataNode的工作原理与优化
## 4.1 DataNode的基本职责
### 4.1.1 数据存储和恢复
DataNode是HDFS的基础数据存储节点,负责存储由NameNode分配的文件数据块。每个文件块在DataNode上都具有多个副本以实现容错和数据的高可用性。DataNode运行在普通的商用机器上,它们之间以及与NameNode之间的通信都基于TCP/IP协议。
具体到数据存储,当客户端写入数据至HDFS时,NameNode会根据策略选择合适的DataNode集群进行数据块的创建与存储。写入操作涉及将数据块复制到多个DataNode以确保数据的安全性。同时,DataNode会定期向NameNode发送块报告,汇报自己当前负责的数据块信息。
在数据恢复方面,DataNode扮演着关键角色。如果某个DataNode发生故障,那么NameNode会安排其他健康的DataNode副本进行数据块复制,以恢复数据的完整性。这些操作都是在NameNode的管理和调度下进行的。
```java
// 示例代码:DataNode启动时向NameNode注册
public void start() {
// ...
registerWithNN(); // 向NameNode注册DataNode
// ...
}
private void registerWithNN() {
// 使用RPC机制注册DataNode
// ...
}
```
上述代码展示了DataNode启动时如何通过RPC机制向NameNode注册自身,确保系统中节点的正常工作和数据块的管理。
### 4.1.2 块报告和心跳机制
心跳机制是DataNode与NameNode间维持健康状态的关键机制。DataNode周期性地向NameNode发送心跳信号,表明节点的运行状态正常。心跳包中一般会携带节点的信息,如存储容量、已用容量、读写性能等。
块报告是心跳信号的一部分,它详细说明了DataNode上存储了哪些数据块。如果NameNode在既定时间内没有收到DataNode的心跳信息,则会认为该DataNode失效,并触发数据块复制流程以保护数据不丢失。
心跳频率可以配置,以平衡系统开销与数据安全。HDFS的默认心跳间隔是3秒,而块报告的周期是6小时。
```properties
# 配置心跳间隔(dfs心跳间隔)
dfs心跳间隔 = 3000
# 配置块报告间隔(dfs块报告间隔)
dfs块报告间隔 = ***
```
## 4.2 DataNode的故障处理和恢复
### 4.2.1 故障检测与报告
DataNode故障检测通常依赖于NameNode的定时轮询。在接收到心跳信号后,NameNode会记录心跳时间戳,如果在预期时间内没有收到心跳,则视为DataNode节点故障。随后NameNode会启动故障节点数据块的复制流程。
故障检测不仅仅局限于节点宕机,还包括网络分区、硬件故障或数据损坏等。对于网络分区,DataNode会尝试重新连接到集群,如果无法恢复,故障报告机制会介入。
```xml
<!-- 故障节点数据块复制的配置 -->
<property>
<name>dfs.replication.min</name>
<value>1</value>
<description>副本数量的最小阈值</description>
</property>
```
上述配置指定了HDFS中数据块副本数量的最小阈值,当副本数量低于此值时,将触发数据块复制以修复故障。
### 4.2.2 数据块的重新复制
数据块的重新复制是HDFS容错性的一个重要组成部分。当DataNode发生故障导致数据副本数低于预设的最小阈值时,NameNode会安排其他健康节点进行数据块的复制。
这一过程首先涉及到选择合适的DataNode来保存新的副本,然后将数据从健康节点传输到目标节点。为了优化网络带宽的使用和节点负载平衡,HDFS会采用如流水复制(pipeline replication)等方式来提高数据传输效率。
```java
// 示例代码:故障数据块的复制过程
public void replicateDataBlock(String blockId, InetSocketAddress[] targets) {
// 创建一个复制流,用于向目标DataNode发送数据块
// ...
for (InetSocketAddress target : targets) {
// 建立到目标DataNode的连接
// ...
// 开始复制数据块到目标DataNode
// ...
}
}
```
代码展示了在DataNode发生故障时,如何进行数据块的复制。复制过程考虑到了数据块的完整性和目标节点的接收能力,确保了数据的一致性和可用性。
## 4.3 DataNode的性能调整
### 4.3.1 磁盘I/O优化
DataNode的性能与存储设备的I/O性能密切相关,因此优化磁盘I/O是提高DataNode性能的关键。磁盘I/O优化包括但不限于调整I/O调度策略、增加读写缓存、选择更快的磁盘技术等。
HDFS提供了几个参数用于优化磁盘I/O,例如`dfs.datanode.du.reserved`设置保留磁盘空间的百分比用于内部操作,`dfs.datanode.fsdatasetCache AGE`用于控制DataNode上的数据集缓存。
```xml
<!-- 配置DataNode磁盘空间保留比例 -->
<property>
<name>dfs.datanode.du.reserved</name>
<value>0.2</value>
<description>预留磁盘空间比例</description>
</property>
<!-- 配置数据集缓存的大小 -->
<property>
<name>dfs.datanode.fsdatasetCache AGE</name>
<value>10</value>
<description>缓存数据集数量</description>
</property>
```
上述配置项保证了磁盘空间不会被完全使用,从而为系统运行留有余地,同时也改善了读写性能。
### 4.3.2 网络带宽的调整和管理
网络带宽是数据块复制的瓶颈之一。在大规模的HDFS集群中,管理好网络带宽的使用可以提高整体系统的效率。HDFS提供了多种参数来调整和管理网络带宽,如限制单次复制操作使用的最大带宽。
```xml
<!-- 限制单个复制操作的最大带宽 -->
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value> <!-- 1MB/s -->
<description>每个DataNode的平衡带宽限制</description>
</property>
```
该配置项控制了DataNode进行数据块复制时的带宽使用上限,从而避免网络拥塞。
为了进一步优化网络带宽,HDFS集群管理员还可以根据网络的物理特性,对不同的DataNode进行分组管理,比如按照机架来分配数据块副本,这样可以最大化利用网络拓扑结构的优势。
| 机架 | DataNode |
|------|----------|
| RACK1| DN1, DN2, DN3 |
| RACK2| DN4, DN5, DN6 |
| ... | ... |
通过上述表格可以看出,管理员可以合理规划DataNode的物理分布,从而有效地管理和优化网络带宽的使用。
# 5. HDFS的实践应用与案例分析
## 5.1 HDFS的部署与集群扩展
### 5.1.1 Hadoop集群的搭建步骤
搭建Hadoop集群是开始使用HDFS之前的关键步骤,确保了后续数据处理和存储的基础。以下是详细的搭建流程:
1. **系统准备:** 确保集群中所有节点的操作系统一致,关闭防火墙和SELinux,配置好主机名和静态IP地址,编辑`/etc/hosts`文件以便节点间能够通过主机名相互识别。
2. **JDK安装:** Hadoop依赖Java环境,需要在所有节点上安装JDK并设置好环境变量。
3. **SSH免密登录:** 在主节点上配置SSH免密登录,以便能够无密码SSH到集群中的其他节点上执行命令。
4. **安装Hadoop:** 在所有节点上下载并解压Hadoop安装包,并配置好`$HADOOP_HOME`环境变量。
5. **配置Hadoop环境:** 修改Hadoop配置文件,包括`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`等,设置HDFS的副本数、数据块大小、YARN资源管理器地址等参数。
6. **格式化NameNode:** 在主节点上执行`hdfs namenode -format`命令格式化文件系统,这一步会清除之前的数据,因此要谨慎操作。
7. **启动集群:** 使用`start-dfs.sh`和`start-yarn.sh`脚本启动HDFS和YARN服务,可以通过`jps`命令检查各个守护进程是否正常启动。
8. **验证安装:** 通过运行一些基本的HDFS命令,如`hdfs dfs -ls /`来检查HDFS是否正常工作。
### 5.1.2 HDFS集群的扩展策略
随着数据量的增加,可能需要对HDFS集群进行扩展,以下是扩展集群的基本步骤:
1. **增加DataNode节点:** 新增机器,完成上面提到的安装和配置步骤。
2. **数据均衡:** 扩展之后,集群中的数据分布可能不均衡,需要使用`balancer`工具进行数据均衡操作,以保持各节点间的数据负载均衡。
3. **增加副本:** 如果需要改变HDFS的副本策略,可以通过修改`dfs.replication`参数实现,然后使用`hadoop fs -setrep -w`命令来调整已有文件的副本数。
4. **监控和调整:** 在扩展后,应该密切监控集群的性能,包括磁盘空间、CPU负载、网络I/O等,并根据需要调整相关配置。
5. **硬件升级:** 如果软件调整不能满足性能要求,可以考虑升级硬件,例如增加节点、提高CPU或内存配置。
## 5.2 HDFS在大数据处理中的应用
### 5.2.1 HDFS与MapReduce的整合
HDFS是MapReduce计算模型的自然存储选择,因为它能够提供高吞吐量的数据访问,并且具备容错机制。在Hadoop集群上部署MapReduce任务的典型流程包括:
1. **数据上传:** 将输入数据上传到HDFS中,MapReduce任务将从这里读取数据。
2. **编写MapReduce程序:** 根据业务需求编写Map和Reduce函数,并编译打包成JAR文件。
3. **提交任务:** 使用`hadoop jar`命令提交JAR包到集群上运行。例如:`hadoop jar MyMapReduceJob.jar MyMapReduceClass input output`。
4. **任务监控:** 在MapReduce任务运行过程中,可以使用`mapred job -status job_id`等命令来监控任务进度。
5. **结果查看:** 任务完成后,结果会存储在HDFS的指定输出目录中,可以使用`hdfs dfs -cat`或`hdfs dfs -get`命令查看或下载结果。
### 5.2.2 HDFS在流数据处理中的角色
HDFS也适用于存储流数据,它可以配合像Apache Storm、Apache Flume这样的流处理系统。HDFS在流数据处理中的角色通常包含:
1. **数据收集:** 使用Flume等工具实时地收集日志数据,并存储到HDFS中。
2. **数据存储:** 作为长期存储系统,HDFS保持流数据的多个版本。
3. **数据处理:** MapReduce或其他批处理工具可以周期性地处理存储在HDFS上的流数据。
4. **数据分发:** HDFS可以向下游系统(如数据仓库或搜索索引器)分发数据。
## 5.3 HDFS的监控与故障诊断
### 5.3.1 HDFS监控工具的使用
HDFS提供了多种监控工具和接口来检查集群的健康状况和性能指标:
1. **NameNode的Web界面:** 可以查看文件系统命名空间的状态和统计信息。
2. **Ganglia或Nagios:** 可以对Hadoop集群进行性能监控和报警设置。
3. **DFSAdmin命令:** 提供了丰富的命令行选项来获取集群的运行状态和执行管理任务,如`hdfs dfsadmin -report`可以提供数据节点报告。
4. **JMX(Java管理扩展):** 允许通过浏览器访问集群各个组件的性能数据。
### 5.3.2 常见故障案例分析与解决
HDFS在运行过程中可能会遇到各种问题,以下是几种常见的故障案例及其解决方案:
1. **节点故障:** 一个或多个DataNode或NameNode宕机。解决方案包括重启服务、故障转移、手动修复或替换硬件。
2. **网络分区:** 由于网络问题导致的集群分裂。需要检查网络配置,确保集群内部通信畅通无阻。
3. **数据不一致:** 可能由于数据节点的磁盘故障导致数据块损坏。可以使用`hdfs fsck`命令检查文件系统的健康状况,并通过复制好的副本修复损坏的数据块。
4. **性能瓶颈:** 磁盘I/O或网络带宽成为限制性能的因素。根据监控工具提供的数据调整相关配置,例如增加副本数以分散负载,或升级硬件以提升性能。
5. **资源竞争:** HDFS上的MapReduce任务可能因资源竞争导致性能下降。可以调整YARN的资源分配策略,如增加任务的内存和CPU配额。
通过这些工具和方法,IT专业人员可以有效地监控和维护HDFS集群,确保数据存储和处理的高可用性和性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《HDFS终极指南》是一份全面的专栏,深入探讨了分布式存储系统的关键方面。它涵盖了HDFS的文件结构、数据块、NameNode和DataNode的内部机制,以及高效的文件定位策略。此外,专栏还提供了优化数据读写、管理小文件、确保数据可靠性、加强安全保护和提高性能的实用建议。通过深入了解HDFS的联邦、快照、故障恢复、数据流动、与MapReduce的协同作用、版本控制、数据完整性、网络架构、文件生命周期、数据一致性和可用性,以及读写操作和监控技术,该专栏为读者提供了全面理解和优化HDFS部署所需的知识和见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
OWASP安全测试实战:5个真实案例教你如何快速定位与解决安全问题
# 摘要
本文系统地阐述了OWASP安全测试的基础知识,重点解析了OWASP前10项安全风险,并提供了防范这些风险的最佳实践。章节中详细介绍了注入攻击、身份验证和会话管理漏洞、安全配置错误等多种安全风险的原理、形成原因、影响及应对策略。同时,通过实战技巧章节,读者能够掌握安全测试流程、工具应用及自动化操作,并了解如何进行漏洞分析和制定修复策略。文中还包含对真实案例的分析,旨在通过实际事件来
【多线程编程最佳实践】:在JDK-17中高效使用并发工具
# 摘要
多线程编程是提升现代软件系统性能的关键技术之一,尤其是在JDK-17等新版本的Java开发工具包(JDK)中,提供
【智能温室控制系统】:DS18B20在农业应用中的革命性实践

# 摘要
本文详细介绍了智能温室控制系统的设计与实现,首先概述了该系统的组成与功能特点,随后深入探讨了DS18B20温度传感器的基础知识及其在农业中的应用潜力。接着,文章阐述了智能温室硬件搭建的过程,包括选择合适的主控制器、传感器的接口连接、供电管理以及布局策略。在软件开发方面,本文讨论了实时温度数据监控、编程环境选择、数据处理逻辑以及自动化控制算
【HPE Smart Storage故障速查手册】:遇到问题,30分钟内快速解决

# 摘要
本文提供了一个关于HPE Smart Storage系统的全面概览,介绍了存储系统工作原理、故障诊断的基础理论,并详细阐述了HPE Smart Storage的故障速查流程。通过故障案例分析,文章展示了在硬盘、控制器和网络方面常见问题的修复过程和解决策略。此外,本文还强调了
【数据安全守门员】:4个实用技巧确保wx-charts数据安全无漏洞
# 摘要
数据安全是信息系统的核心,随着技术的发展,保护数据免受未授权访问和滥用变得越来越具有挑战性。本文深入探讨了wx-charts这一数据可视化工具的基本安全特性,包括其架构、访问控制配置、数据加密技巧、监控与审核操作,以及如何实现高可用性和灾难恢复策略。文章详细分析了加密算法的选择、传输加密的实现、静态数据存储的安全性,并提供了实现日志记录、分析和审计的方法。通过案例研究,本文总结
【CMOS集成电路设计权威指南】:拉扎维习题深度解析,精通电路设计的10个秘密武器
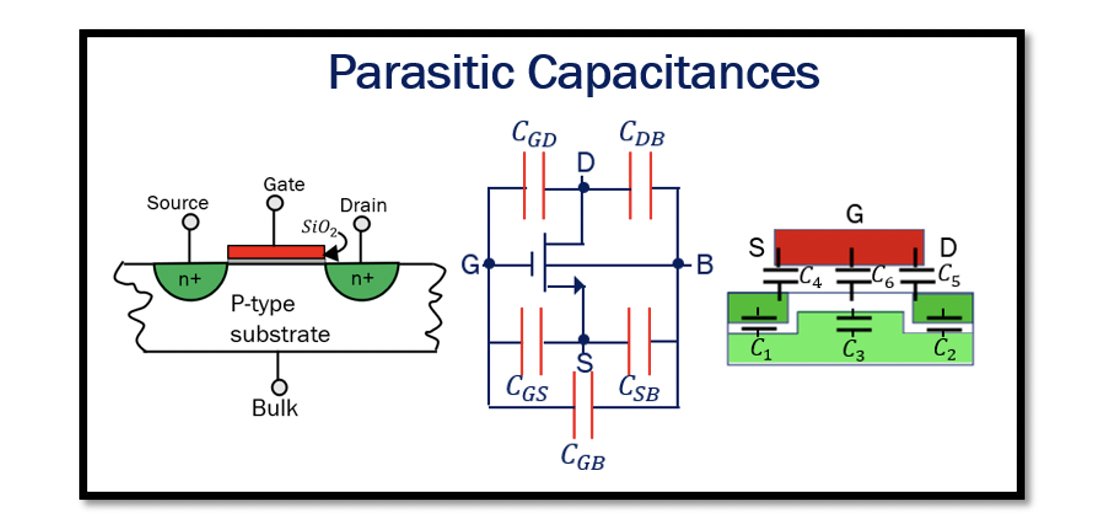
# 摘要
随着集成电路技术的发展,CMOS集成电路设计已成为电子工程领域的关键环节。本文首先概述了CMOS集成电路设计的基本原理与方法。接着,深入解析了拉扎维习题中的关键知识点,包括MOSFET的工作原理、CMOS反相器分析、电路模型构建、模拟与仿真等。随后,本文探讨了CMOS电路设计中的实战技巧,涉及参数优化、版图设计、信号完整性和电源管理等问题。在高级话题章节,分析
【Visual C++ 2010运行库新手必读】:只需三步完成安装与配置
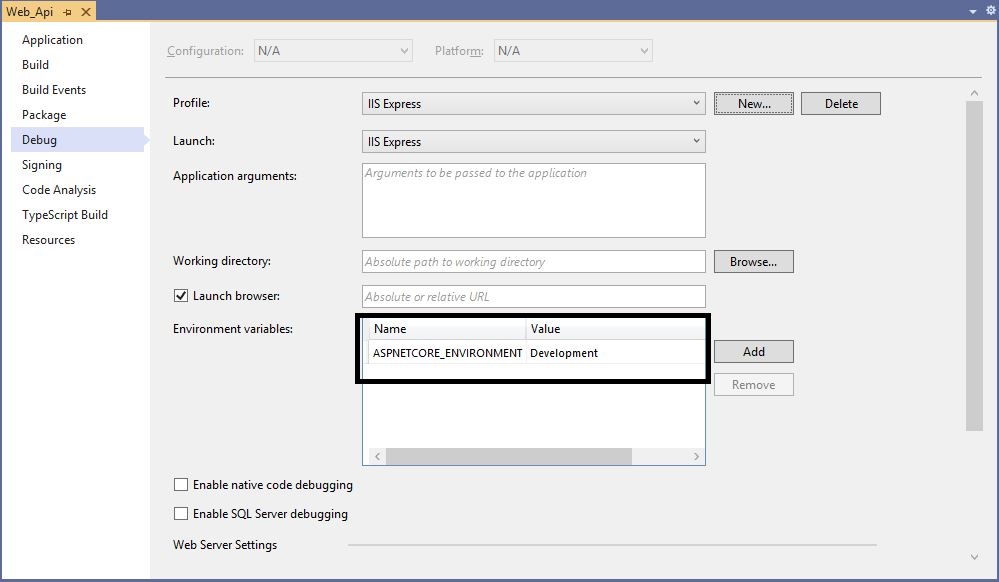
# 摘要
本文全面介绍了Visual C++ 2010运行库的相关知识,包括运行库概述、安装、配置及实践应用。首先,本文概述了Visual C++ 2010运行库的组成与功能,阐述了其在Visual C++开发中的核心作用。接着,详细介绍了安装运行库的步骤、系统兼容性要求以及环境配置的注意事项。在深入理解与高级应用章节,探讨了高级配置选项、非官方运行库的安装与维护,以及运行库
化学绘图效率提升大揭秘:ACD_ChemSketch高级技巧全解析
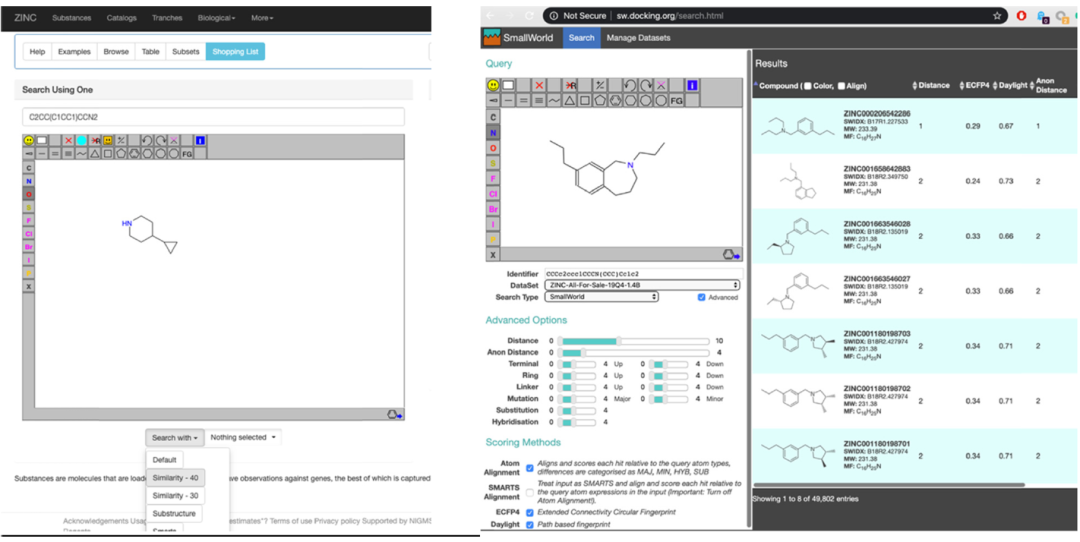
# 摘要
ACD_ChemSketch是一款专业的化学绘图软件,广泛应用于教学和科研领域。本文全面介绍了ACD_ChemSketch的基础操作、高级绘图技巧、自动化与定制化功能,以及在教学和科研中的具体应用。基础操作部分详细阐述了界面布局、工具栏以及文档管理,确保用户能够高效进行分子结构的绘制和管理。高级绘图技巧部分探讨了如何利用软件进行复杂化学结构的编辑,包括三维模型的创建和编辑。自动化与定制
晶体结构建模软件故障排除:一文掌握快速解决问题的秘密

# 摘要
晶体结构建模软件是材料科学和工程领域的重要工具,其稳定性和准确性直接影响研究结果。本文旨在提供对软件故障全面的理论认识,包括软件故障的分类、特征、根本原因以及心理学和认知理论。接着深入探讨了软件故障诊断技术,如日志分析、性能监控、代码审计等,并提出相应的修复策略和预防措施。通过分析实战案例,本文强化了理论与实践的结合。最后,展望了软件故障排除的未来,特别是在人工智能和持续学习框架下,提升故障排除的效率和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )