Kubernetes集群管理与部署实践
发布时间: 2024-03-09 05:59:51 阅读量: 46 订阅数: 22 

Kubernetes 实践指南
# 1. Kubernetes简介与架构概述
## 1.1 Kubernetes概述
Kubernetes是一个开源的容器编排引擎,可以实现自动化部署、扩展和管理容器化的应用程序。本节将介绍Kubernetes的基本概念和特点,以及其在容器化领域的重要作用。
## 1.2 Kubernetes架构解析
Kubernetes的架构包括Master节点和Worker节点,它们通过各种组件协同工作,实现容器集群的高效管理与调度。我们将深入探讨这些组件的功能和作用。
## 1.3 Kubernetes核心概念解释
在使用Kubernetes之前,需要了解一些核心概念,如Pod、Service、Ingress等。本节将针对这些概念进行详细解释,并介绍它们在Kubernetes中的应用场景。
# 2. 搭建Kubernetes集群
### 2.1 硬件与软件准备
在搭建Kubernetes集群之前,确保你已经准备好了以下硬件和软件:
- **硬件要求**:
- Master节点:至少2核CPU、4GB内存、50GB存储空间
- Worker节点:至少2核CPU、2GB内存、20GB存储空间
- **软件要求**:
- 操作系统:推荐Ubuntu 18.04或CentOS 7.6
- Docker:最新稳定版
- kubeadm、kubelet和kubectl:同Kubernetes版本一致
- Kubernetes集群网络插件:如Flannel、Calico等
### 2.2 安装和配置Master节点
1. **安装Docker**:
```bash
$ sudo apt-get update
$ sudo apt-get install -y docker.io
$ sudo systemctl enable docker
$ sudo systemctl start docker
```
2. **安装kubeadm、kubelet和kubectl**:
```bash
$ sudo apt-get update
$ sudo apt-get install -y apt-transport-https curl
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
$ sudo apt-get update
$ sudo apt-get install -y kubelet kubeadm kubectl
$ sudo apt-mark hold kubelet kubeadm kubectl
```
3. **初始化Master节点**:
```bash
$ sudo kubeadm init --pod-network-cidr=10.244.0.0/16
# 记录下输出中的kubeadm join命令,后续用于将Worker节点加入集群
```
4. **设置kubectl配置**:
```bash
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
```
### 2.3 安装和配置Worker节点
1. **安装Docker、kubeadm、kubelet和kubectl**(步骤同Master节点中的安装步骤)。
2. **加入集群**:
在Master节点初始化完成后,运行以下命令加入Worker节点:
```bash
$ sudo kubeadm join <Master节点IP>:<端口> --token <token> --discovery-token-ca-cert-hash <hash>
```
### 2.4 部署Kubernetes网络
1. **部署Flannel网络插件**:
```bash
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
```
2. **验证网络插件是否正常运行**:
```bash
$ kubectl get pods --all-namespaces
```
这样,你就成功搭建起了一个基本的Kubernetes集群。接下来,可以开始部署应用和进行集群管理。
# 3. Kubernetes集群管理
#### 3.1 Pod的管理与调度
在Kubernetes中,Pod是最小的部署单元,可以包含一个或多个容器。通过Pod的控制器(如Deployment、StatefulSet等)可以对Pod进行管理和调度。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mycontainer
image: myimage
ports:
- containerPort: 80
```
- **场景描述:** 上面的YAML示例定义了一个Pod,包含一个名为mycontainer的容器,使用名为myimage的镜像,并在容器内部暴露端口80。
- **代码总结:** 通过定义Pod的YAML文件,可以实现对容器的管理和调度。
- **结果说明:** 提交该YAML文件给Kubernetes集群后,Kubernetes会根据调度算法将Pod分配到合适的节点上运行。
#### 3.2 Service的管理与负载均衡
Service是Kubernetes集群中用于暴露应用程序的一种资源对象,负责将外部流量引导到对应的Pod上。
```yaml
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
selector:
app: myapp
ports:
- protocol: TCP
port: 80
targetPort: 9376
```
- **场景描述:** 上面的YAML示例定义了一个Service,将流量引导到具有标签app=myapp的Pod上,并将流量从端口80转发到Pod的9376端口。
- **代码总结:** 通过定义Service的YAML文件,可以实现对应用程序的负载均衡和服务发现。
- **结果说明:** 提交该YAML文件给Kubernetes集群后,外部客户端可以通过访问Service的ClusterIP来访问Pod。
#### 3.3 Ingress的配置与管理
Ingress是Kubernetes集群中用于公开HTTP和HTTPS服务的一种资源对象,通过Ingress Controller实现流量的路由和负载均衡。
```yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myingress
spec:
rules:
- host: mydomain.com
http:
paths:
- path: /
pathType: ImplementationSpecific
backend:
service:
name: myservice
port:
number: 80
```
- **场景描述:** 上面的YAML示例定义了一个Ingress资源,将mydomain.com的流量路由到名为myservice的Service上。
- **代码总结:** 通过定义Ingress资源,可以实现对外暴露HTTP和HTTPS服务,并实现流量的负载均衡。
- **结果说明:** 提交该YAML文件给Kubernetes集群后,Ingress Controller会根据规则配置将流量正确地路由到对应的Service上。
# 4. Kubernetes应用部署
### 4.1 使用Deployment部署应用
在Kubernetes中,使用Deployment可以方便地部署应用,并且能够实现应用的自动修复、扩展和滚动更新等功能。下面是一个简单的示例,演示如何使用Deployment部署一个Nginx应用:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.17.6
ports:
- containerPort: 80
```
上面的示例定义了一个名为nginx-deployment的Deployment,它会创建3个replica副本,使用Nginx的镜像,并且将容器的80端口暴露出来。你可以使用`kubectl apply -f nginx-deployment.yaml`来部署这个Deployment。
### 4.2 使用StatefulSet部署有状态应用
与Deployment不同,StatefulSet适用于部署有状态的应用,如数据库。下面是一个示例,演示如何使用StatefulSet部署一个具有稳定网络标识符的MySQL数据库:
```yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: mysql
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
```
上面的示例定义了一个名为mysql的StatefulSet,它会创建3个带有稳定网络标识符的MySQL实例,并且使用持久化存储来保存数据。你可以使用`kubectl apply -f mysql-statefulset.yaml`来部署这个StatefulSet。
### 4.3 使用DaemonSet部署系统守护进程
DaemonSet用于在集群的每个节点上运行一个副本,通常用于部署一些系统级的守护进程。下面是一个示例,演示如何使用DaemonSet部署一个NodeExporter守护进程,用于收集节点的监控指标:
```yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
containers:
- name: node-exporter
image: prom/node-exporter:v0.18.1
ports:
- containerPort: 9100
```
上面的示例定义了一个名为node-exporter的DaemonSet,它会在集群的每个节点上运行一个NodeExporter容器,用于暴露节点的监控指标。你可以使用`kubectl apply -f node-exporter-daemonset.yaml`来部署这个DaemonSet。
### 4.4 使用Job和CronJob管理任务和定时任务
除了部署长期运行的应用外,Kubernetes还支持管理短期任务和定时任务。Job用于管理一次性任务,而CronJob用于管理周期性任务。下面是一个示例,演示如何使用Job和CronJob来执行任务和定时任务:
```yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: pi-biweekly
spec:
schedule: "*/2 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: OnFailure
```
上面的示例首先定义了一个名为pi的Job,用于计算π的值;然后定义了一个名为pi-biweekly的CronJob,用于每两分钟执行一次计算π的任务。你可以使用`kubectl apply -f pi-job.yaml`和`kubectl apply -f pi-cronjob.yaml`来管理这些任务和定时任务。
以上就是使用Kubernetes部署应用的一些常用方式,通过这些方式,你可以灵活地管理不同类型的应用,并且充分利用Kubernetes提供的自动化功能。
# 5. Kubernetes集群监控与日志
在本章中,我们将讨论如何实现对Kubernetes集群的监控和日志管理,以确保集群的稳定性和高可用性。
### 5.1 部署Heapster和InfluxDB进行集群监控
#### 场景描述:
在Kubernetes集群中,我们希望实时监控集群各项指标,如CPU、内存和网络使用情况。为此,我们将部署Heapster和InfluxDB来收集和存储这些指标数据。
#### 代码示例:
```yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
spec:
replicas: 1
template:
metadata:
labels:
app: heapster
spec:
containers:
- name: heapster
image: k8s.gcr.io/heapster-amd64:v1.5.4
command:
- /heapster
- --source=kubernetes:https://kubernetes.default
```
```yaml
apiVersion: v1
kind: Service
metadata:
name: heapster
spec:
selector:
app: heapster
ports:
- port: 80
targetPort: 8082
```
### 5.2 使用Prometheus进行应用监控
#### 场景描述:
除了集群级别的监控外,我们还需要实现针对应用程序的监控。Prometheus是一个流行的开源监控解决方案,我们将使用Prometheus来监控应用程序的性能和健康状态。
#### 代码示例:
```yaml
apiVersion: v1
kind: ServiceMonitor
metadata:
name: example-app-monitor
labels:
release: prometheus
app: example-app
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
path: /metrics
```
### 5.3 集成EFK进行日志收集和分析
#### 场景描述:
日志对于排查问题和追踪应用程序状态至关重要。我们将使用Elasticsearch、Fluentd和Kibana(EFK)堆栈来收集、存储和分析Kubernetes集群中的日志数据。
#### 代码示例:
```yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluent.conf: |
<source>
@type forward
port 24224
</source>
<match **>
@type elasticsearch
host elasticsearch.logging
port 9200
logstash_format true
</match>
```
在本章中,我们介绍了如何利用Heapster和InfluxDB进行集群监控、使用Prometheus进行应用监控,以及集成EFK进行日志收集和分析。这些工具和技术将帮助您更好地管理和维护Kubernetes集群。
# 6. Kubernetes集群高可用与安全
## 6.1 实现Master节点的高可用
在Kubernetes集群中,Master节点的高可用性非常重要。我们可以通过使用多个Master节点来实现高可用架构,其中一个节点为主节点,其他节点为备用节点。在主节点发生故障时,备用节点可以接管服务,确保集群的正常运行。
### 实现方法
1. 配置多个Master节点
2. 使用负载均衡器进行流量分发
3. 定期进行故障转移测试
```bash
# 示例代码
# 配置负载均衡器
kubectl create -f load-balancer.yaml
```
### 结果说明
通过上述配置,我们可以确保Kubernetes集群在Master节点发生故障时仍然可以正常运行,保障业务的稳定性。
## 6.2 集群安全和RBAC配置
Kubernetes集群的安全性至关重要,RBAC(基于角色的访问控制)可以帮助我们限制用户和服务账户对集群资源的访问权限,从而保护集群不受未授权的访问和操作。
### 实现方法
1. 创建角色和角色绑定
2. 将角色绑定到用户或服务账户
3. 进行权限验证测试
```yaml
# 示例代码
# 配置角色和角色绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
# 绑定角色到用户
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
```
### 结果说明
通过RBAC配置,我们可以限制用户和服务账户对集群资源的访问权限,提高集群的安全性。
## 6.3 使用TLS加密保护集群通信
为了确保集群通信的安全性,我们可以使用TLS加密技术对集群的所有通信进行加密保护,防止信息被窃取和篡改。
### 实现方法
1. 生成TLS证书和私钥
2. 配置Kubernetes组件使用TLS
3. 验证加密通信的有效性
```bash
# 示例代码
# 生成TLS证书和私钥
openssl genrsa -out ca.key 2048
openssl req -x509 -new -nodes -key ca.key -subj "/CN=kubernetes" -days 10000 -out ca.crt
```
### 结果说明
通过TLS加密保护集群通信,我们可以避免敏感信息在传输过程中被窃取和篡改,增强集群的安全性。
## 6.4 优化集群性能与稳定性
除了确保集群的安全性外,我们还需要对集群进行性能优化,以提升集群的稳定性和响应速度。这包括调整资源配额、优化调度策略、定期监测和调整集群资源利用率等方面。
### 实现方法
1. 设置资源配额和限制
2. 调整调度器配置
3. 使用监控工具进行资源利用率分析
```yaml
# 示例代码
# 设置Pod资源配额
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "10"
requests.cpu: "4"
requests.memory: 5Gi
limits.cpu: "8"
limits.memory: 10Gi
```
### 结果说明
通过优化集群性能和稳定性,我们可以提升集群的资源利用率,降低故障发生的概率,确保业务的稳定运行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【DEH调节逻辑图解】:掌握基础知识,精通应用

# 摘要
本文系统地介绍了DEH(Digital Electro-Hydraulic)调节系统的理论基础与实践应用。首先解释了DEH系统的工作原理,阐述了其组成和基本流程。接着,文章深入分析了DEH调节中的关键参数,包括压力、温度设定点,流量控制和功率调节,以及PID(比例、积分、微分)控制的解析。此外,本文还探讨了DEH调节系统与其他系统的协同
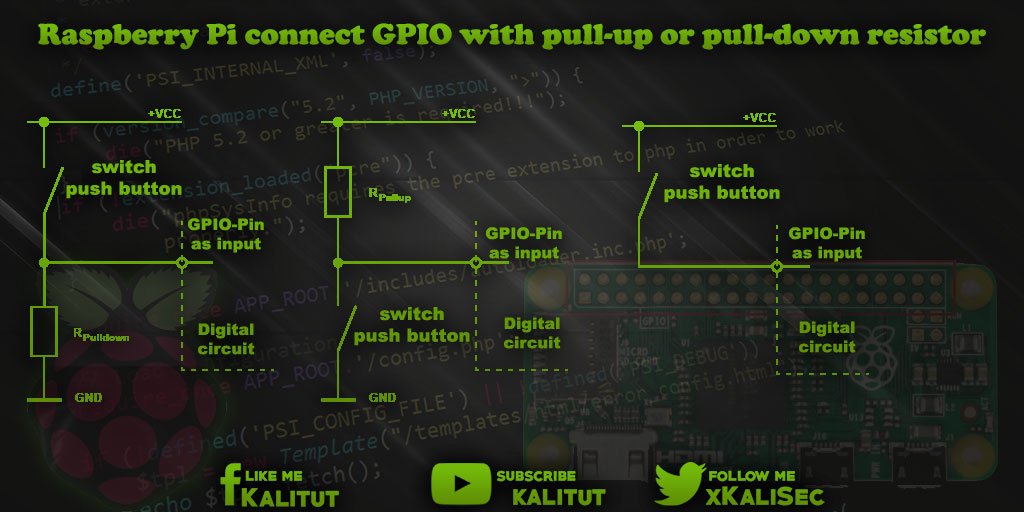
【AT32F435手册深度解读】:揭秘隐藏性能参数与应用技巧
# 摘要
本文全面介绍了AT32F435微控制器,从其概述开始,深入分析了硬件架构和内存存储配置,探讨了高性能的ARM Cortex-M4内核特性及其性能参数。详细讨论了编程与开发环境,强调了IDE配置、调试技巧以及编程接口的优化。文章进一步探索了AT32F435的高级功能,包括电源管理、安全特性、实时时钟等,并分析了在工业自动化控制、消费电子产品和无线通信应用中的
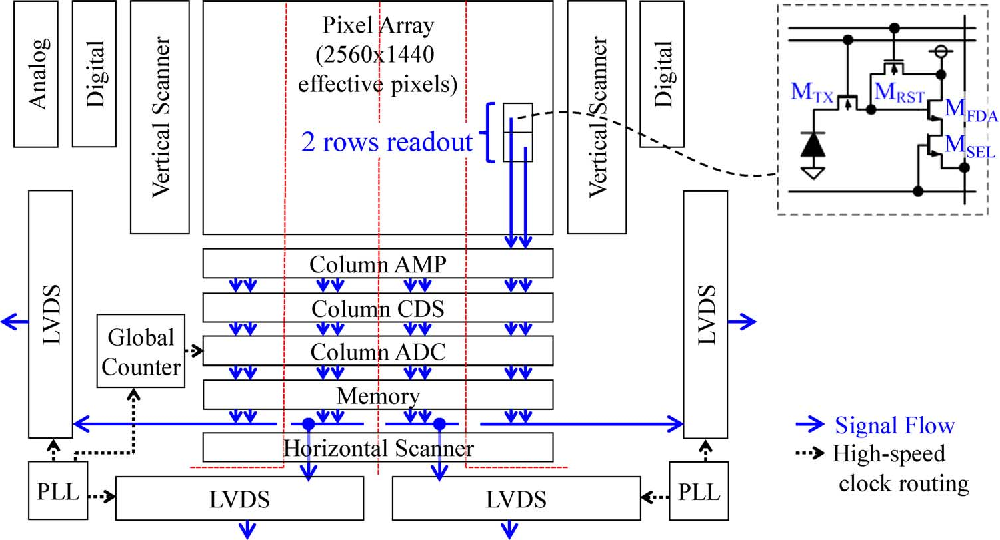
【sCMOS相机驱动电路全攻略】:20年经验大师带你破解设计与故障处理的神秘面纱
# 摘要
本论文全面介绍了sCMOS相机驱动电路的设计原理、实践与高级应用,并对故障处理技巧和未来发展趋势进行了深入探讨。首先概述了sCMOS相机驱动电路的基本概念及其重要性,接着从理论基础入手,详尽分析了sCMOS相机的工作原理、关键参数和信号完整性。在设计实践章节中,讨论了电路设计前期准备、布局布线以及调试测试的
【自动售货机界面设计】:交互逻辑实现的秘诀

# 摘要
自动售货机界面设计是提升用户体验、增强交互效率及实现技术革新的关键要素。本文详细探讨了自动售货机界面设计的理论基础,如用户体验的重要性、界面设计的交互原则及布局视觉层次。接着,文章深入分析了界面交互逻辑,包括导航、交易流程和错误处理的设计。在实践层面,本文阐述了用户研究、原型设计、用户测试以及迭代优化的过程。技术实现部分则讨论了界面开发工具、功能模块编码和测试方法。最后
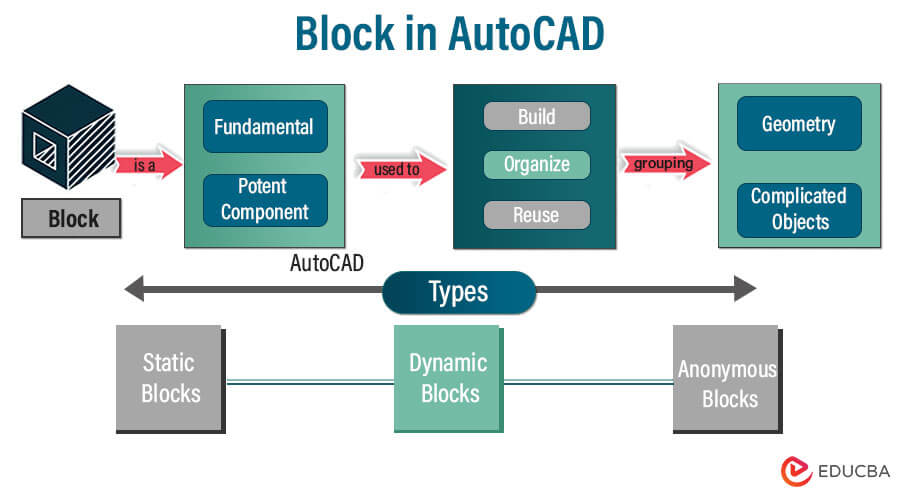
【CAD2002块操作全攻略】
# 摘要
CAD块操作是提高CAD绘图效率和标准化的关键技术。本文旨在介绍CAD块操作的基本知识,包括块的创建、编辑、命名及属性管理。进一步探讨高级技巧,如动态块的创建和使用,以及块与外部数据库的交互。文章还涵盖了块操作在实际应用中的案例分析,例如工程图纸中的块应用,协作设计中块操作的应用,以及自动化工具的开发。最后,本文针对块操作中可能遇到的常见问题,提出相应的诊断方法和性能优化策略,并通过案例
【MATLAB内存布局精通】:数组方向性对性能影响的深入剖析

# 摘要
本文综合探讨了MATLAB中数组方向性对性能的影响,并提出了相应的性能优化策略。首先,从理论层面分析了数组方向性的重要性以及其如何影响缓存效率,并构建了相应的数学模型。其次,本文深入到MATLAB的实践操作,探讨了方向性在性能优化中的具体应用,并通过案例研究展示了方向性优化的实际效果。文章还详细阐述了优化算法的设计原则,研究了MATLAB内置函数及自定义函
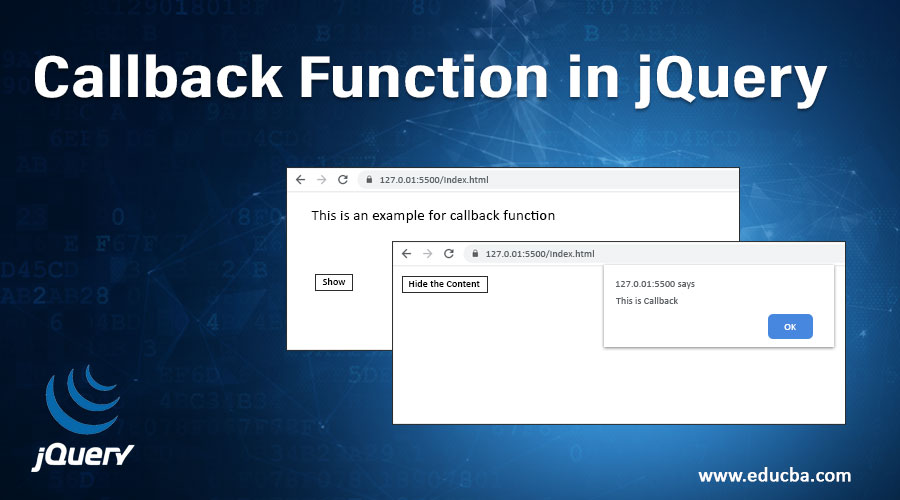
C语言回调函数:使用技巧与实现细节详解
# 摘要
回调函数是软件开发中广泛应用的一种编程技术,它允许在程序执行的某个点调用一个预先定义的函数,从而实现模块化和事件驱动的程序设计。本文详细探讨了回调函数的基本概念和在C语言中使用函数指针实现回调的技巧。通过分析典型的使用场景,如事件处理和算法设计模式,本文提供了如何在C语言中高效且安全地使用回调函数的深入指导。此外,文中还介绍了性能优化和安全注意事项,包括减少开销、防止内存泄漏、回调注入攻
【监控大师】:掌握西门子SINUMERIK测量循环,实现生产过程全面监控
# 摘要
本文全面探讨了SINUMERIK测量循环的理论基础、实践应用以及监控大师系统在其中所扮演的角色。首先介绍了测量循环的基本概念、分类、特点和参数设置,其次解析了监控大师系统的架构和功能模块,并说明了如何利用该系统实现对生产过程的全面监控。文章重点通过实际案例分析,展示了测量循环在生产中的应用,并探讨了监控大师在实时监控和故障预测中的作用,以及如何通过这些技术提升生产效率和质量。最后,文章讨论了系统优化的策略,面临的挑战和未来发展趋势,并分享了成功的案例研究与经验。
# 关键字
SINUMERIK测量循环;系统架构;实时监控;生产效率;故障预测;案例研究
参考资源链接:[西门子SIN
Word 2016 Endnotes加载项:提升工作流的十个技巧

# 摘要
本文系统地介绍了Word 2016中Endnotes加载项的使用方法和技巧,阐述了Endnotes的基本概念、作用以及其在提升文档质量和优化工作流中的重要性。文章详细描述了Endnotes加载项的安装、配置和个性化设置,同时提供了管理尾注的策略和与文献管理软件整合的方法。此外,文章还探讨了在Word中快速插入和编辑Endnotes的技巧,分享了提高文档一致性和工作效率的高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )