Go语言基础教程-性能优化与调试技巧
发布时间: 2023-12-20 10:14:21 阅读量: 42 订阅数: 35 

go语言教程
### 第一章:Go语言基础回顾
Go语言作为一种新兴的编程语言,具有简洁高效、并发性能好等特点,在近年来备受关注。本章将回顾Go语言的基础知识,包括变量和数据类型、流程控制、函数和方法等内容。让我们来深入了解Go语言的基础知识。
1.1 变量和数据类型
1.2 流程控制
1.3 函数和方法
## 第二章:性能优化基础
### 3. 第三章:代码调试与分析工具
在软件开发过程中,调试和性能分析是非常重要的环节。本章将介绍如何使用Go语言内置的调试工具和性能分析工具来提高代码质量和性能。
#### 3.1 基础调试技巧
在进行代码调试时,可以使用fmt包来输出变量的取值,以便确定程序的执行流程和变量取值是否符合预期。另外,可以使用Go语言标准库中的log包输出日志信息,帮助定位问题所在。
```go
package main
import "fmt"
func main() {
var a = 10
var b = 20
c := add(a, b)
fmt.Println("The result of adding a and b is:", c)
}
func add(x, y int) int {
return x + y
}
```
通过在代码中插入fmt.Println语句可以输出中间变量的取值,帮助分析代码执行过程中的问题。
#### 3.2 使用Go内置的调试工具
Go语言提供了内置的调试工具,例如`go run`、`go build`、`go test`等命令行工具。我们可以使用这些工具来运行、构建和测试代码,查看代码执行过程中的错误信息,帮助定位问题所在。
#### 3.3 性能分析工具的使用
除了调试工具,对于性能优化也非常重要。Go语言提供了丰富的性能分析工具,例如`go test`中的`-bench`参数可以用来进行性能基准测试,`pprof`工具可以用来进行更加详细的性能分析,帮助找出代码中的性能瓶颈。
```go
package main
import (
"testing"
)
func BenchmarkAdd(b *testing.B) {
a := 10
for i := 0; i < b.N; i++ {
add(a, a)
}
}
```
以上是一个性能基准测试的示例代码,通过使用`go test -bench`命令可以对`BenchmarkAdd`函数进行性能测试,并输出性能报告。
### 4. 第四章:并发编程的性能优化
并发编程在Go语言中是非常重要的,但是并发代码的性能优化也是一个挑战。本章将介绍如何优化并发编程的性能,包括Goroutine的调度与性能、Channel的性能优化,以及使用原子操作优化并发代码。
#### 4.1 Goroutine的调度与性能
在并发编程中,Goroutine的调度对性能有很大影响。合理控制Goroutine的数量、避免过多的上下文切换等都是提升性能的关键。
```go
package main
import (
"fmt"
"runtime"
"sync"
)
func main() {
numCPUs := runtime.NumCPU()
runtime.GOMAXPROCS(numCPUs) // 设置使用的CPU核心数
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
// 执行并发任务
fmt.Println("执行并发任务")
}()
}
wg.Wait()
}
```
**代码总结:**
- 通过`runtime.GOMAXPROCS(numCPUs)`可以设置使用的CPU核心数来优化Goroutine的调度性能。
- 使用`sync.WaitGroup`来等待所有Goroutine执行完成。
**结果说明:**
通过合理设置CPU核心数和使用`sync.WaitGroup`等待所有Goroutine执行完成,可以有效优化Goroutine的调度性能。
#### 4.2 Channel的性能优化
Channel是Go语言中并发编程的重要组件,合理使用Channel可以提高程序的并发性能。
```go
package main
import "fmt"
func main() {
ch := make(chan int, 100) // 设置有缓冲的Channel
go func() {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}()
for num := range ch {
// 处理从Channel中接收到的数据
fmt.Println("接收到数据:", num)
}
}
```
**代码总结:**
- 可以通过`make(chan int, 100)`设置有缓冲的Channel来减少因Channel阻塞导致的性能损失。
**结果说明:**
使用有缓冲的Channel可以减少因发送或接收数据而阻塞Goroutine的情况,从而提高并发性能。
#### 4.3 使用原子操作优化并发代码
在并发编程中,原子操作可以保证对共享变量的原子性操作,从而避免竞争条件,提高代码的性能。
```go
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var count int32
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
atomic.AddInt32(&count, 1)
wg.Done()
}()
}
wg.Wait()
fmt.Println("最终的count值:", count)
}
```
**代码总结:**
- 使用`sync/atomic`包中的原子操作函数,如`atomic.AddInt32`来对共享变量进行原子操作,避免竞争条件。
**结果说明:**
通过使用原子操作,可以避免竞争条件,保证对共享变量的原子性操作,提高并发代码的性能。
### 5. 第五章:网络编程与性能优化
网络编程在Go语言中扮演着至关重要的角色。在本章中,我们将探讨如何使用Go语言进行网络编程,并重点讨论如何优化网络性能,以提高程序的效率和稳定性。
#### 5.1 使用标准库进行网络编程
在本节中,我们将介绍如何使用Go语言标准库进行常见的网络编程,涵盖TCP、UDP等协议的基本操作和优化技巧。
```go
// 示例代码:使用标准库进行TCP网络编程
package main
import (
"fmt"
"net"
)
func main() {
// 服务端代码
go func() {
listener, err := net.Listen("tcp", ":8888")
if err != nil {
fmt.Println("Error listening:", err.Error())
return
}
defer listener.Close()
fmt.Println("Server is listening on :8888")
for {
conn, err := listener.Accept()
if err != nil {
fmt.Println("Error accepting: ", err.Error())
return
}
fmt.Printf("Accepted connection from %s\n", conn.RemoteAddr())
go handleRequest(conn)
}
}()
// 客户端代码
conn, err := net.Dial("tcp", "localhost:8888")
if err != nil {
fmt.Println("Error connecting:", err.Error())
return
}
defer conn.Close()
fmt.Println("Client connected to server!")
// 省略发送数据和接收数据的过程
}
func handleRequest(conn net.Conn) {
// 处理连接的具体业务逻辑
defer conn.Close()
// 省略具体业务逻辑的代码
}
```
#### 5.2 TCP/UDP性能优化技巧
在本节中,我们将深入探讨如何针对TCP和UDP协议进行性能优化,包括优化网络传输效率、处理大规模并发连接等方面的技巧。
```go
// 示例代码:TCP连接的性能优化
package main
import (
"net"
"time"
)
func main() {
addr := "localhost:8888"
conn, err := net.DialTimeout("tcp", addr, 3*time.Second)
if err != nil {
// 错误处理逻辑
return
}
defer conn.Close()
// 设置TCP连接参数
tcpConn, _ := conn.(*net.TCPConn)
tcpConn.SetNoDelay(true)
tcpConn.SetKeepAlive(true)
tcpConn.SetKeepAlivePeriod(30 * time.Second)
// 省略后续数据交互和业务逻辑
}
```
#### 5.3 HTTP性能优化与缓存策略
本节将重点讨论如何在Go语言中进行HTTP性能优化与缓存策略的制定,包括使用HTTP缓存头、CDN加速等技术手段。
```go
// 示例代码:HTTP服务器端性能优化与缓存策略
package main
import (
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// 设置缓存头
w.Header().Set("Cache-Control", "max-age=3600, public")
w.Header().Set("Etag", "some-unique-id")
// 省略后续业务逻辑
})
http.ListenAndServe(":8080", nil)
}
```
以上是第五章的内容,包括使用标准库进行网络编程、TCP/UDP性能优化技巧以及HTTP性能优化与缓存策略。这些内容将帮助你更好地理解如何在Go语言中进行网络编程并优化性能。
### 6. 第六章:实战案例分析
在这一章中,我们将深入分析实际项目中的性能问题,并结合优化案例进行讲解与实践经验分享。通过具体的案例分析,我们将带领读者了解性能问题的排查与解决思路,以及在实际项目中优化性能的方法和技巧。在每个案例分析中,我们将提供详细的代码示例、注释、代码总结以及结果说明,帮助读者更好地理解和应用性能优化相关的知识。
具体而言,我们将讨论以下内容:
#### 6.1 分析实际项目中的性能问题
我们将选取一个真实的项目案例,通过对项目性能问题的分析,探讨问题产生的原因、影响范围以及解决方案。通过具体案例的分析,读者可以更好地理解性能问题排查的方法与技巧。
#### 6.2 优化案例讲解与实践经验分享
在这一节中,我们将挑选一个性能优化的具体案例,通过详细的代码演示、优化过程讲解和实践经验分享,帮助读者掌握性能优化的实际操作技巧,从而在实际项目中应用这些技巧。
#### 6.3 性能问题排查与解决思路
最后,我们将总结一些通用的性能问题排查与解决思路,包括常见性能问题的排查方法、解决技巧以及在项目中预防性能问题的经验。
通过本章的学习,读者将能够全面了解性能优化的实际应用场景和方法,掌握排查与解决性能问题的技巧,从而在实际项目中提升代码的性能表现。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Go语言基础教程》专栏深入浅出地介绍了Go语言的基础知识和各种应用场景。从介绍与环境搭建开始,逐步深入探讨了变量与数据类型、流程控制与循环、数组与切片、结构体与方法、接口与多态等内容。同时,还涵盖了并发编程基础与进阶、错误处理与异常、文件操作与IO、网络编程基础与进阶等方面的知识,以及JSON与XML处理、正则表达式入门、性能优化与调试技巧、内存管理与垃圾回收、数据库操作与ORM、Web开发入门等实用技能。通过逐步深入的学习,读者可以系统掌握Go语言的基础知识并具备一定的应用能力,为进一步实现Go语言的高级应用打下坚实基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Android应用中的MAX30100集成完全手册:一步步带你上手
# 摘要
本文综合介绍了MAX30100传感器的搭建和应用,涵盖了从基础硬件环境的搭建到高级应用和性能优化的全过程。首先概述了MAX30100的工作原理及其主要特性,然后详细阐述了如何集成到Arduino或Raspberry Pi等开发板,并搭建相应的硬件环境。文章进一步介绍了软件环境的配置,包括Arduino IDE的安装、依赖库的集成和MAX30100库的使用。接着,通过编程实践展示了MAX30100的基本操作和高级功能的开发,包括心率和血氧饱和度测量以及与Android设备的数据传输。最后,文章探讨了MAX30100在Android应用中的界面设计、功能拓展和性能优化,并通过实际案例分析
【AI高手】:掌握这些技巧,A*算法解决8数码问题游刃有余
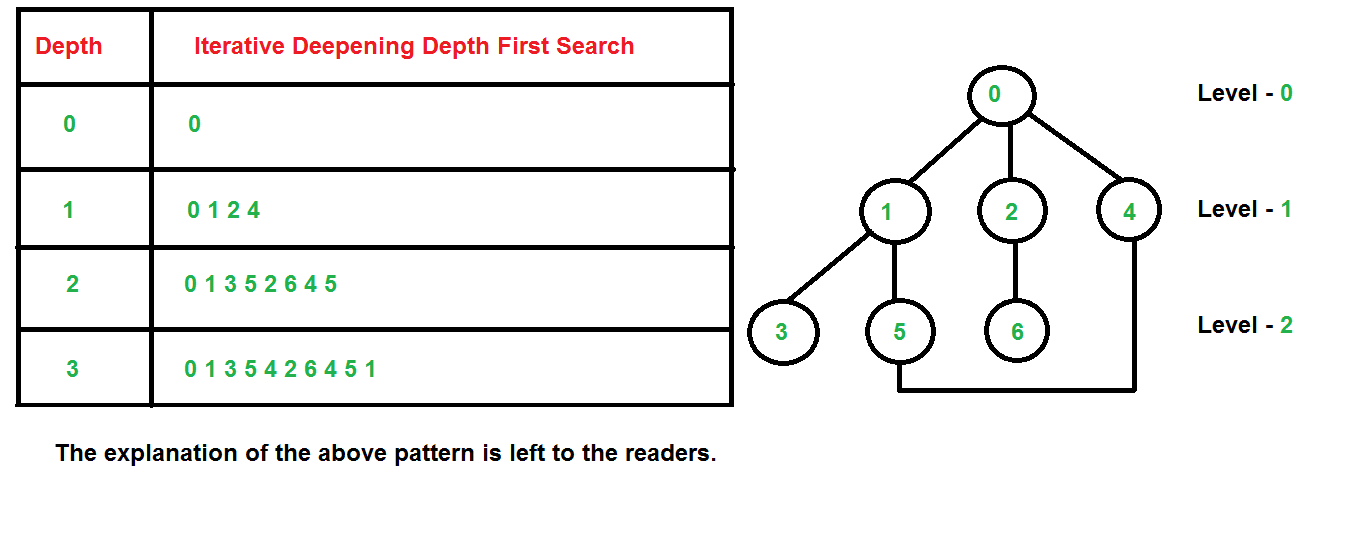
# 摘要
A*算法是计算机科学中广泛使用的一种启发式搜索算法,尤其在路径查找和问题求解领域表现出色。本文首先概述了A*算法的基本概念,随后深入探讨了其理论基础,包括搜索算法的分类和评价指标,启发式搜索的原理以及评估函数的设计。通过结合著名的8数码问题,文章详细介绍了A*算法的实际操作流程、编码前的准备、实现步骤以及优化策略。在应用实例部分,文章通过具体问题的实例化和算法的实现细节,提供了深入的案例分析和问题解决方法。最后,本文展望
【硬件软件接口艺术】:掌握提升系统协同效率的关键策略
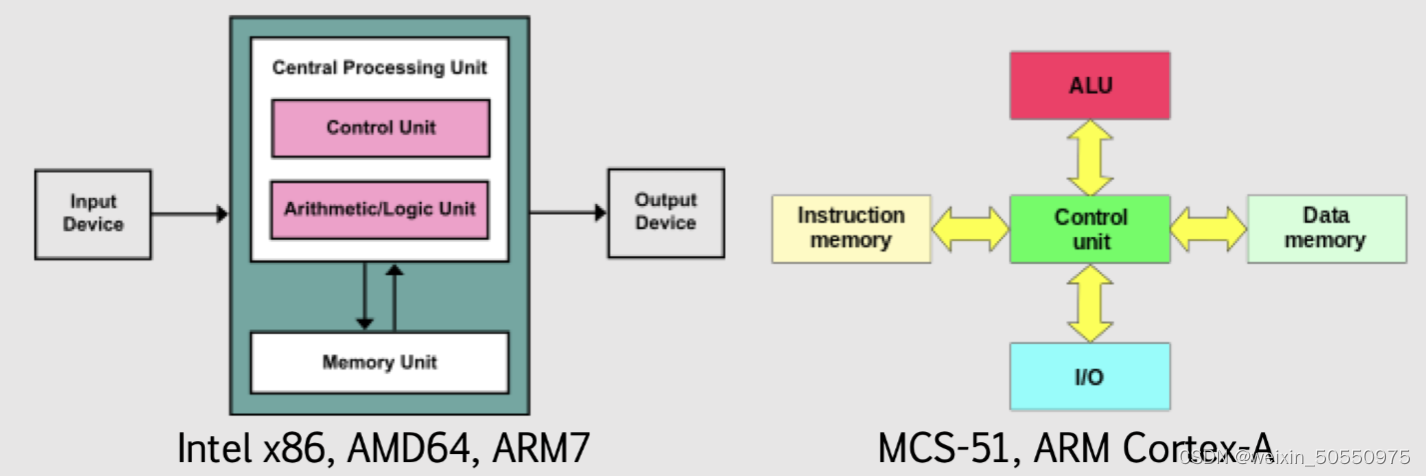
# 摘要
硬件与软件接口是现代计算系统的核心,它决定了系统各组件间的通信效率和协同工作能力。本文首先概述了硬件与软件接口的基本概念和通信机制,深入探讨了硬件通信接口标准的发展和主流技术的对比。接着,文章分析了软件接口的抽象层次,包括系统调用、API以及驱动程序的作用。此外,本文还详细介绍了同步与异步处理机制的原理和实践。在探讨提升系统协同效率的关键技术方面,文中阐述了缓存机制优化、多线程与并行处理,以及
PFC 5.0二次开发宝典:API接口使用与自定义扩展
# 摘要
本文深入探讨了PFC 5.0的技术细节、自定义扩展的指南以及二次开发的实践技巧。首先,概述了PFC 5.0的基础知识和标准API接口,接着详细分析了AP
【台达VFD-B变频器与PLC通信集成】:构建高效自动化系统的不二法门

# 摘要
本文综合介绍了台达VFD-B变频器与PLC通信的关键技术,涵盖了通信协议基础、变频器设置、PLC通信程序设计、实际应用调试以及高级功能集成等各个方面。通过深入探讨通信协议的基本理论,本文阐述了如何设置台达VFD-B变频器以实现与PLC的有效通信,并提出了多种调试技巧与参数优化策略,以解决实际应用中的常见问题。此外,本文
【ASM配置挑战全解析】:盈高经验分享与解决方案

# 摘要
自动存储管理(ASM)作为数据库管理员优化存储解决方案的核心技术,能够提供灵活性、扩展性和高可用性。本文深入介绍了ASM的架构、存储选项、配置要点、高级技术、实践操作以及自动化配置工具。通过探讨ASM的基础理论、常见配置问题、性能优化、故障排查以及与RAC环境的集成,本文旨在为数据库管理员提供全面的配置指导和操作建议。文章还分析了ASM在云环境中的应用前景、社区资源和
【自行车码表耐候性设计】:STM32硬件防护与环境适应性提升

# 摘要
本文详细探讨了自行车码表的设计原理、耐候性设计实践及软硬件防护机制。首先介绍自行车码表的基本工作原理和设计要求,随后深入分析STM32微控制器的硬件防护基础。接着,通过研究环境因素对自行车码表性能的影响,提出了相应的耐候性设计方案,并通过实验室测试和现场实验验证了设计的有效性。文章还着重讨论了软件防护机制,包括设计原则和实现方法,并探讨了软硬件协同防护
STM32的电源管理:打造高效节能系统设计秘籍
# 摘要
随着嵌入式系统在物联网和便携设备中的广泛应用,STM32微控制器的电源管理成为提高能效和延长电池寿命的关键技术。本文对STM32电源管理进行了全面的概述,从理论基础到实践技巧,再到高级应用的探讨。首先介绍了电源管理的基本需求和电源架构,接着深入分析了动态电压调节技术、电源模式和转换机制等管理策略,并探讨了低功耗模式的实现方法。进一步地,本文详细阐述了软件工具和编程技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )