【MySQL JSON数据处理秘籍】:10个核心函数,高效应对复杂数据
发布时间: 2024-08-04 09:07:43 阅读量: 45 订阅数: 20 

# 1. MySQL JSON数据处理概述**
JSON(JavaScript Object Notation)是一种流行的数据格式,用于在各种应用程序中存储和交换数据。MySQL 8.0 及更高版本提供了对 JSON 数据的原生支持,使您可以轻松地存储、查询和操作 JSON 数据。
JSON 数据在 MySQL 中表示为字符串,您可以使用 JSON 函数来处理这些数据。这些函数允许您创建、解析、提取和修改 JSON 数据。通过利用 JSON 函数,您可以有效地管理和利用 JSON 数据,从而增强您的应用程序的功能。
# 2. 核心JSON函数
### 2.1 JSON_ARRAY() 函数
**功能:** 创建一个JSON数组。
**语法:**
```sql
JSON_ARRAY(value1, value2, ..., valueN)
```
**参数:**
* `value1, value2, ..., valueN`:要添加到数组中的值,可以是任何数据类型。
**返回值:**
一个JSON数组,包含指定的值。
**逻辑分析:**
`JSON_ARRAY()` 函数将指定的值组合成一个JSON数组。数组中的值可以是任何数据类型,包括字符串、数字、布尔值和嵌套的JSON对象。
**示例:**
```sql
SELECT JSON_ARRAY(1, 2, 3, 4, 5);
-- 输出:
[1, 2, 3, 4, 5]
```
### 2.2 JSON_OBJECT() 函数
**功能:** 创建一个JSON对象。
**语法:**
```sql
JSON_OBJECT(key1, value1, key2, value2, ..., keyN, valueN)
```
**参数:**
* `key1, key2, ..., keyN`:JSON对象的键,必须是字符串。
* `value1, value2, ..., valueN`:JSON对象的相应值,可以是任何数据类型。
**返回值:**
一个JSON对象,包含指定的键值对。
**逻辑分析:**
`JSON_OBJECT()` 函数将指定的键值对组合成一个JSON对象。键必须是字符串,而值可以是任何数据类型。
**示例:**
```sql
SELECT JSON_OBJECT('name', 'John', 'age', 30, 'city', 'New York');
-- 输出:
{"name": "John", "age": 30, "city": "New York"}
```
### 2.3 JSON_SET() 函数
**功能:** 在现有JSON对象中设置或更新一个值。
**语法:**
```sql
JSON_SET(json_document, path, value)
```
**参数:**
* `json_document`:要更新的JSON对象。
* `path`:要设置或更新的值的路径,使用点分隔符(`.`)表示。
* `value`:要设置或更新的值,可以是任何数据类型。
**返回值:**
一个新的JSON对象,其中指定路径的值已被设置或更新。
**逻辑分析:**
`JSON_SET()` 函数允许在现有JSON对象中设置或更新一个值。`path` 参数指定要设置或更新的值的路径。如果路径不存在,则会创建它。
**示例:**
```sql
SELECT JSON_SET(
JSON_OBJECT('name', 'John', 'age', 30),
'$.address',
JSON_OBJECT('street', 'Main Street', 'city', 'New York')
);
-- 输出:
{"name": "John", "age": 30, "address": {"street": "Main Street", "city": "New York"}}
```
### 2.4 JSON_EXTRACT() 函数
**功能:** 从JSON对象中提取一个值。
**语法:**
```sql
JSON_EXTRACT(json_document, path)
```
**参数:**
* `json_document`:要提取值的JSON对象。
* `path`:要提取的值的路径,使用点分隔符(`.`)表示。
**返回值:**
指定路径的值,可以是任何数据类型。
**逻辑分析:**
`JSON_EXTRACT()` 函数从JSON对象中提取一个值。`path` 参数指定要提取的值的路径。如果路径不存在,则返回 `NULL`。
**示例:**
```sql
SELECT JSON_EXTRACT(
JSON_OBJECT('name', 'John', 'age', 30),
'$.age'
);
-- 输出:
30
```
### 2.5 JSON_SEARCH() 函数
**功能:** 在JSON对象中搜索一个值。
**语法:**
```sql
JSON_SEARCH(json_document, one_or_all, path, value)
```
**参数:**
* `json_document`:要搜索的JSON对象。
* `one_or_all`:指定是返回第一个匹配的值(`ONE`)还是所有匹配的值(`ALL`)。
* `path`:要搜索的值的路径,使用点分隔符(`.`)表示。
* `value`:要搜索的值。
**返回值:**
一个JSON数组,包含所有匹配的值。如果未找到匹配项,则返回 `NULL`。
**逻辑分析:**
`JSON_SEARCH()` 函数在JSON对象中搜索一个值。`path` 参数指定要搜索的值的路径。`one_or_all` 参数指定是返回第一个匹配的值还是所有匹配的值。
**示例:**
```sql
SELECT JSON_SEARCH(
JSON_ARRAY(
JSON_OBJECT('name', 'John', 'age', 30),
JSON_OBJECT('name', 'Mary', 'age', 25)
),
'ALL',
'$.age',
30
);
-- 输出:
[{"name": "John", "age": 30}]
```
# 3. JSON数据操作实践
### 3.1 JSON数据的插入和更新
**插入JSON数据**
```sql
INSERT INTO table_name (column_name) VALUES (JSON_OBJECT('key1', 'value1', 'key2', 'value2'));
```
**参数说明:**
* `table_name`: 要插入JSON数据的表名
* `column_name`: 要插入JSON数据的列名
* `JSON_OBJECT()`: 创建JSON对象的函数,参数为键值对
**代码逻辑:**
该语句使用`JSON_OBJECT()`函数创建一个JSON对象,并将其插入到指定列中。
**更新JSON数据**
```sql
UPDATE table_name SET column_name = JSON_SET(column_name, '$.key1', 'new_value1') WHERE condition;
```
**参数说明:**
* `table_name`: 要更新JSON数据的表名
* `column_name`: 要更新JSON数据的列名
* `JSON_SET()`: 更新JSON对象中指定键的值的函数,参数为JSON对象、键路径和新值
* `condition`: 更新条件
**代码逻辑:**
该语句使用`JSON_SET()`函数更新JSON对象中指定键的值,并根据指定条件进行更新。
### 3.2 JSON数据的查询和提取
**查询JSON数据**
```sql
SELECT JSON_EXTRACT(column_name, '$.key1') FROM table_name;
```
**参数说明:**
* `table_name`: 要查询JSON数据的表名
* `column_name`: 要查询JSON数据的列名
* `JSON_EXTRACT()`: 从JSON对象中提取指定键的值的函数,参数为JSON对象和键路径
**代码逻辑:**
该语句使用`JSON_EXTRACT()`函数从JSON对象中提取指定键的值。
**提取JSON数组**
```sql
SELECT JSON_ARRAY_ELEMENTS(column_name) FROM table_name;
```
**参数说明:**
* `table_name`: 要提取JSON数组的表名
* `column_name`: 要提取JSON数组的列名
* `JSON_ARRAY_ELEMENTS()`: 将JSON数组中的每个元素提取为单独的行
**代码逻辑:**
该语句使用`JSON_ARRAY_ELEMENTS()`函数将JSON数组中的每个元素提取为单独的行。
### 3.3 JSON数据的修改和删除
**修改JSON数据**
```sql
UPDATE table_name SET column_name = JSON_REPLACE(column_name, '$.key1', 'new_value1') WHERE condition;
```
**参数说明:**
* `table_name`: 要修改JSON数据的表名
* `column_name`: 要修改JSON数据的列名
* `JSON_REPLACE()`: 替换JSON对象中指定键的值的函数,参数为JSON对象、键路径和新值
* `condition`: 修改条件
**代码逻辑:**
该语句使用`JSON_REPLACE()`函数替换JSON对象中指定键的值,并根据指定条件进行修改。
**删除JSON数据**
```sql
UPDATE table_name SET column_name = JSON_REMOVE(column_name, '$.key1') WHERE condition;
```
**参数说明:**
* `table_name`: 要删除JSON数据的表名
* `column_name`: 要删除JSON数据的列名
* `JSON_REMOVE()`: 从JSON对象中删除指定键的函数,参数为JSON对象和键路径
* `condition`: 删除条件
**代码逻辑:**
该语句使用`JSON_REMOVE()`函数从JSON对象中删除指定键,并根据指定条件进行删除。
# 4. 高级JSON函数**
**4.1 JSON_TABLE() 函数**
JSON_TABLE() 函数将 JSON 文档转换为关系型表,允许您查询和操作 JSON 数据中的嵌套结构。
**语法:**
```
JSON_TABLE(json_doc, '$."path_to_json_array" COLUMNS (column_name data_type, ...))
```
**参数:**
* **json_doc:**要转换的 JSON 文档。
* **$."path_to_json_array":**JSON 文档中要转换的 JSON 数组的路径。
* **column_name:**要创建的关系型表的列名。
* **data_type:**要创建的关系型表的列的数据类型。
**示例:**
```
SELECT * FROM JSON_TABLE(
'{"employees": [
{"id": 1, "name": "John", "salary": 1000},
{"id": 2, "name": "Jane", "salary": 2000}
]}',
'$."employees" COLUMNS (id INT, name VARCHAR(255), salary INT)
);
```
**结果:**
| id | name | salary |
|---|---|---|
| 1 | John | 1000 |
| 2 | Jane | 2000 |
**4.2 JSON_QUERY() 函数**
JSON_QUERY() 函数用于从 JSON 文档中提取特定值或子文档。
**语法:**
```
JSON_QUERY(json_doc, '$.path_to_value')
```
**参数:**
* **json_doc:**要查询的 JSON 文档。
* **$.path_to_value:**要提取的值或子文档的路径。
**示例:**
```
SELECT JSON_QUERY(
'{"employees": [
{"id": 1, "name": "John", "salary": 1000},
{"id": 2, "name": "Jane", "salary": 2000}
]}',
'$.employees[1].name'
);
```
**结果:**
```
John
```
**4.3 JSON_UNQUOTE() 函数**
JSON_UNQUOTE() 函数从 JSON 字符串中删除引号。
**语法:**
```
JSON_UNQUOTE(json_string)
```
**参数:**
* **json_string:**要删除引号的 JSON 字符串。
**示例:**
```
SELECT JSON_UNQUOTE('"John"');
```
**结果:**
```
John
```
**4.4 JSON_TYPE() 函数**
JSON_TYPE() 函数返回 JSON 值的数据类型。
**语法:**
```
JSON_TYPE(json_value)
```
**参数:**
* **json_value:**要检查数据类型的 JSON 值。
**示例:**
```
SELECT JSON_TYPE('{"id": 1, "name": "John", "salary": 1000}');
```
**结果:**
```
OBJECT
```
# 5.1 JSON数据索引优化
### 索引类型选择
对于JSON数据,MySQL提供了两种索引类型:
- **普通索引 (BTREE)**:适用于对JSON文档进行范围查询或相等性查询。
- **全文索引 (FTS)**:适用于对JSON文档进行文本搜索。
### 索引创建策略
创建索引时,应考虑以下策略:
- **选择性较高的字段**:索引字段应具有较高的选择性,即唯一值较多。
- **查询模式**:根据常见的查询模式创建索引。例如,如果经常对JSON文档中的特定属性进行查询,则可以创建该属性的索引。
- **索引覆盖**:创建索引时,应考虑是否可以覆盖常见的查询,避免回表查询。
### 索引使用示例
以下示例创建了一个普通索引,用于对JSON文档中的 `name` 属性进行相等性查询:
```sql
CREATE INDEX idx_name ON table_name(JSON_EXTRACT(json_column, '$.name'));
```
以下示例创建了一个全文索引,用于对JSON文档中的 `description` 属性进行文本搜索:
```sql
CREATE FULLTEXT INDEX idx_description ON table_name(JSON_EXTRACT(json_column, '$.description'));
```
### 索引维护
索引需要定期维护,以确保其有效性。可以使用以下命令重建索引:
```sql
ALTER TABLE table_name REBUILD INDEX idx_name;
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入解析 MySQL 中 JSON 数据的处理、查询、索引、存储、完整性、备份、恢复、分析和可视化等各个方面。通过 10 个核心函数,掌握高效应对复杂 JSON 数据的秘诀;从基础到高级,全面了解 MySQL JSON 查询的技巧;揭秘 JSON 索引失效的原因并提供 5 个解决方案,提升查询性能;深入解析 JSON 数据存储结构,优化存储性能;提供保障 JSON 数据准确性、避免数据灾难的完整性指南;讲解 JSON 数据备份与恢复的全攻略,保障数据安全;实战演示 JSON 数据的统计、聚合等分析方法,洞察数据价值;分享 JSON 数据可视化的秘诀,将数据转化为直观图表,轻松理解;解析 JSON 数据锁机制,深入理解并避免死锁问题。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
模型验证的艺术:使用R语言SolveLP包进行模型评估
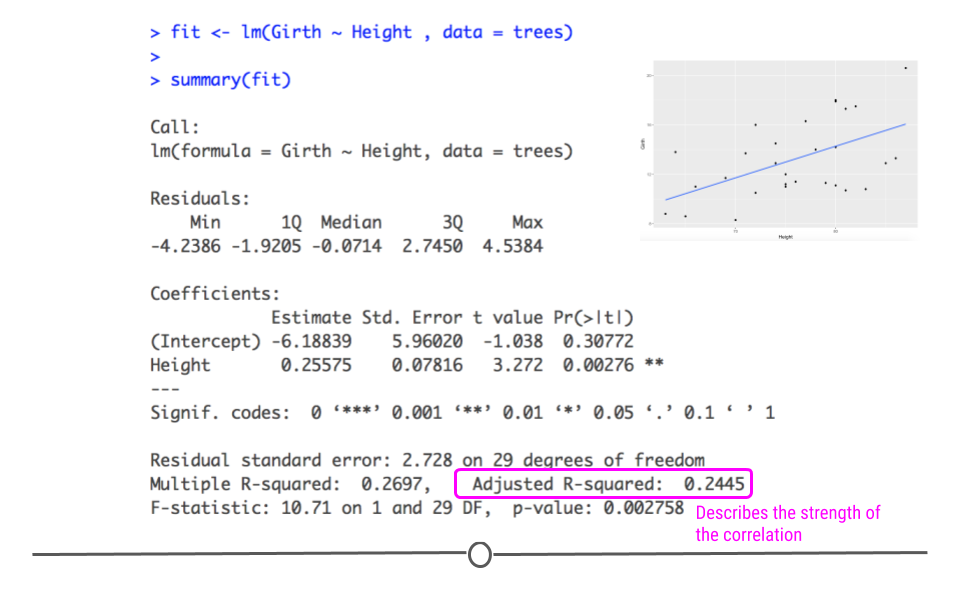
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
R语言数据包安全使用指南:规避潜在风险的策略
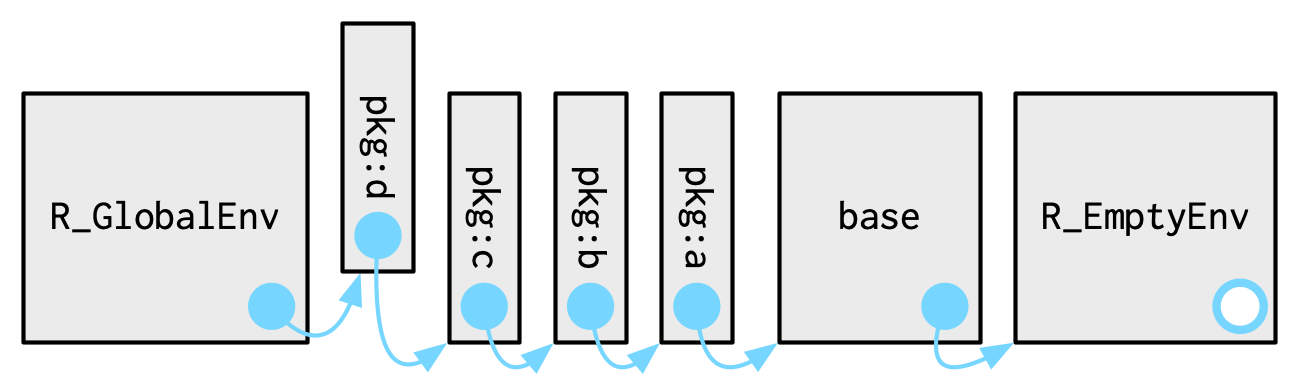
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
R语言数据包多语言集成指南:与其他编程语言的数据交互(语言桥)

# 1. R语言数据包的基本概念与集成需求
## R语言数据包简介
R语言作为统计分析领域的佼佼者,其数据包(也称作包或库)是其强大功能的核心所在。每个数据包包含特定的函数集合、数据集、编译代码等,专门用于解决特定问题。在进行数据分析工作之前,了解如何选择合适的数据包,并集成到R的
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
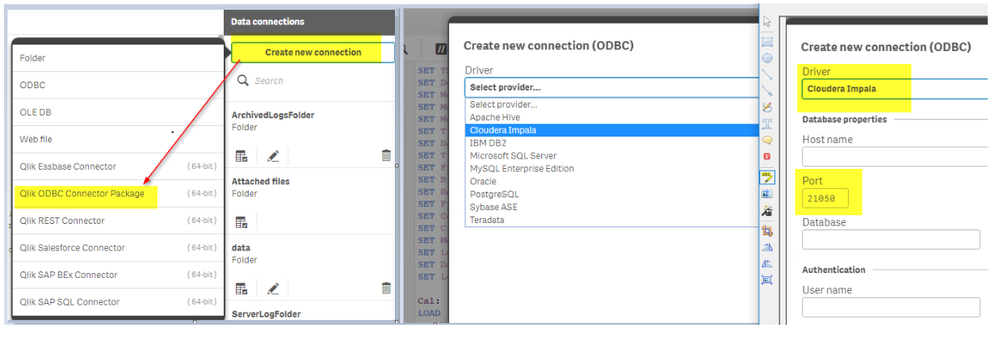
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
R语言数据包性能监控:实时跟踪使用情况的高效方法
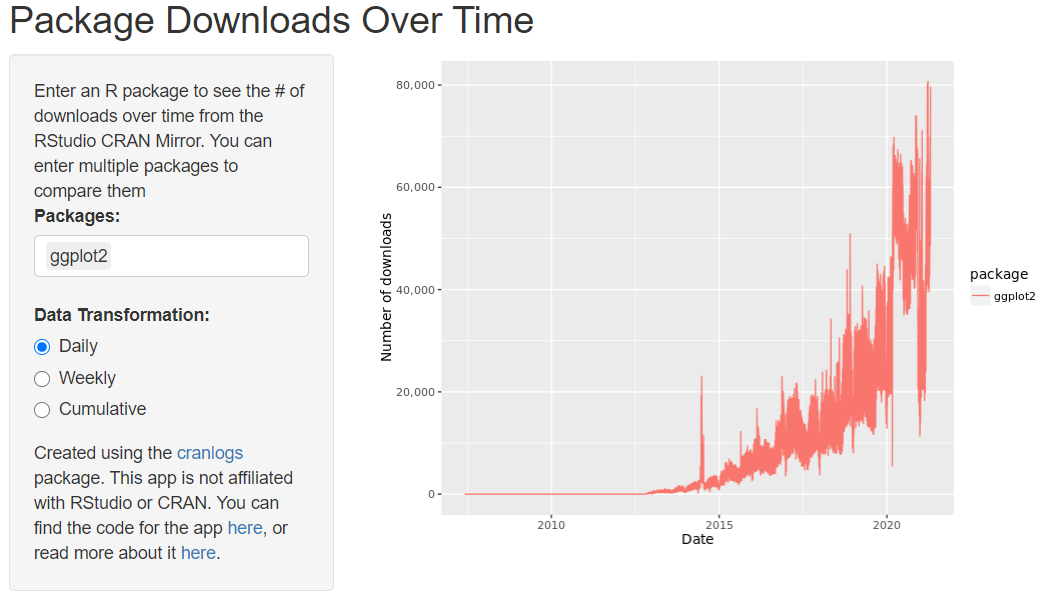
# 1. R语言数据包性能监控概述
在当今数据驱动的时代,对R语言数据包的性能进行监控已经变得越来越重要。本章节旨在为读者提供一个关于R语言性能监控的概述,为后续章节的深入讨论打下基础。
## 1.1 数据包监控的必要性
随着数据科学和统计分析在商业决策中的作用日益增强,R语言作为一款强大的统计分析工具,其性能监控成为确保数据处理效率和准确性的重要环节。性能监控能够帮助我们识别潜在的瓶颈,及时优化数据包的使用效率,提
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
【Tau包社交网络分析】:掌握R语言中的网络数据处理与可视化
# 1. Tau包社交网络分析基础
社交网络分析是研究个体间互动关系的科学领域,而Tau包作为R语言的一个扩展包,专门用于处理和分析网络数据。本章节将介绍Tau包的基本概念、功能和使用场景,为读者提供一个Tau包的入门级了解。
## 1.1 Tau包简介
Tau包提供了丰富的社交网络分析工具,包括网络的创建、分析、可视化等,特别适合用于研究各种复杂网络的结构和动态。它能够处理有向或无向网络,支持图形的导入和导出,使得研究者能够有效地展示和分析网络数据。
## 1.2 Tau与其他网络分析包的比较
Tau包与其他网络分析包(如igraph、network等)相比,具备一些独特的功能和优势。
模型结果可视化呈现:ggplot2与机器学习的结合
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
【R语言多条件绘图】:lattice包分面绘图与交互设计的完美融合
# 1. R语言与lattice包简介
R语言是一种用于统计分析、图形表示以及报告生成的编程语言和软件环境。它因具有强大的数据处理能力和丰富的图形表现手段而广受欢迎。在R语言中,lattice包是一个专门用于创建多变量条件图形的工具,其设计理念基于Trellis图形系统,为研究人员提供了一种探索性数据分析的强大手段。
## 1.1 R语言的特点
R语言的主要特点包括:
- 开源:R是开源软件,社区支持强大,不断有新功能和包加入。
- 数据处理:R语言拥有丰富的数据处理功能,包括数据清洗、转换、聚合等。
- 可扩展:通过包的形式,R语言可以轻易地扩展新的统计方法和图形功能。
## 1.
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )