MySQL JSON数据存储秘诀:揭开高效处理半结构化数据的奥秘
发布时间: 2024-07-28 05:56:59 阅读量: 98 订阅数: 37 
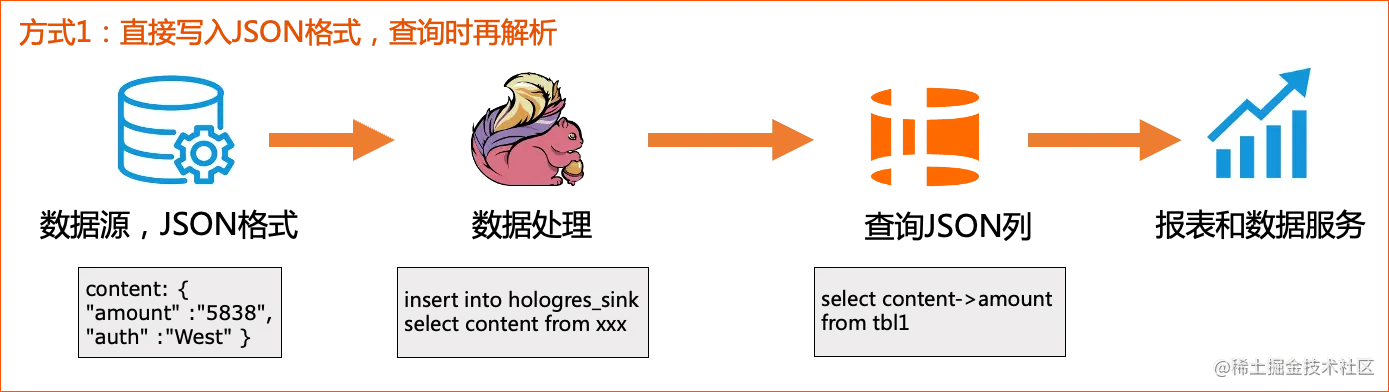
# 1. MySQL JSON 数据存储概述**
MySQL JSON 数据存储功能允许在 MySQL 数据库中存储和管理 JSON(JavaScript 对象表示法)数据。JSON 是一种轻量级、基于文本的数据格式,用于表示复杂的数据结构,例如对象、数组和嵌套数据。
MySQL JSON 数据存储提供了灵活性和可扩展性,使开发人员能够轻松存储和处理复杂数据,而无需创建复杂的表结构或使用外部数据存储。通过使用 JSON 数据类型,可以将 JSON 数据直接存储在 MySQL 表中,并使用标准 SQL 语句进行查询和操作。
# 2. JSON 数据建模与存储
### 2.1 JSON 数据结构与 MySQL 数据类型映射
JSON 数据结构是一种层次化的数据格式,它使用键值对来表示数据。MySQL 中没有专门的 JSON 数据类型,但可以通过以下方式将 JSON 数据映射到 MySQL 数据类型:
| JSON 数据类型 | MySQL 数据类型 |
|---|---|
| 对象 | JSON |
| 数组 | JSON |
| 字符串 | VARCHAR |
| 数值 | INT, FLOAT |
| 布尔值 | TINYINT(1) |
| 空值 | NULL |
### 2.2 JSON 数据的存储方式:文档和键值对
MySQL 中的 JSON 数据可以存储为文档或键值对。
**文档存储**
文档存储将整个 JSON 对象存储为一个不可分割的单元。这种存储方式适合存储复杂的数据结构,例如包含多个嵌套对象的 JSON 对象。
**键值对存储**
键值对存储将 JSON 对象中的每个键值对存储为单独的行。这种存储方式适合存储结构相对简单的 JSON 对象,例如包含少量键值对的 JSON 对象。
**存储方式选择**
存储方式的选择取决于 JSON 数据的结构和查询模式。如果需要查询整个 JSON 对象,则文档存储更合适。如果需要查询特定键值对,则键值对存储更合适。
#### 代码示例:文档存储
```sql
CREATE TABLE json_data (
id INT NOT NULL AUTO_INCREMENT,
json_object JSON NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO json_data (json_object) VALUES (
'{
"name": "John Doe",
"age": 30,
"address": {
"street": "123 Main Street",
"city": "Anytown",
"state": "CA",
"zip": "12345"
}
}'
);
```
#### 代码示例:键值对存储
```sql
CREATE TABLE json_data (
id INT NOT NULL AUTO_INCREMENT,
key VARCHAR(255) NOT NULL,
value JSON NOT NULL,
PRIMARY KEY (id)
);
INSERT INTO json_data (key, value) VALUES
('name', '"John Doe"'),
('age', '30'),
('address', '{
"street": "123 Main Street",
"city": "Anytown",
"state": "CA",
"zip": "12345"
}');
```
#### 逻辑分析:
文档存储示例中,`json_object` 列存储整个 JSON 对象,而键值对存储示例中,`key` 列存储键,`value` 列存储值。
# 3. JSON 数据查询与处理**
### 3.1 JSON 数据查询语法
MySQL 提供了多种语法来查询 JSON 数据,包括:
- **JSON_EXTRACT() 函数:**提取 JSON 文档中的特定值。
```sql
SELECT JSON_EXTRACT('{"name": "John Doe", "age": 30}', '$.name');
```
- **JSON_VALUE() 函数:**类似于 JSON_EXTRACT(),但可以指定一个路径表达式来提取嵌套值。
```sql
SELECT JSON_VALUE('{"address": {"street": "Main St", "city": "Anytown"}}', '$.address.street');
```
- **-> 操作符:**使用点号表示法访问 JSON 文档中的值。
```sql
SELECT `name`->'$.name' FROM `users`;
```
- **JSON_QUERY() 函数:**使用 XPath 表达式查询 JSON 文档。
```sql
SELECT JSON_QUERY('{"name": "John Doe", "age": 30}', '$.[?(@.age > 25)]');
```
### 3.2 JSON 数据处理函数
MySQL 还提供了各种函数来处理 JSON 数据,包括:
- **JSON_SET() 函数:**在 JSON 文档中设置或更新值。
```sql
UPDATE `users` SET `name` = JSON_SET(`name`, '$.first_name', 'Jane');
```
- **JSON_INSERT() 函数:**在 JSON 文档中插入值。
```sql
UPDATE `users` SET `name` = JSON_INSERT(`name`, '$.middle_name', 'Mary');
```
- **JSON_REMOVE() 函数:**从 JSON 文档中删除值。
```sql
UPDATE `users` SET `name` = JSON_REMOVE(`name`, '$.last_name');
```
- **JSON_MERGE() 函数:**合并两个 JSON 文档。
```sql
SELECT JSON_MERGE('{"name": "John Doe"}', '{"age": 30}');
```
### 3.3 JSON 数据的聚合与分组
MySQL 允许对 JSON 数据进行聚合和分组操作,包括:
- **JSON_AGG() 函数:**聚合 JSON 文档数组。
```sql
SELECT JSON_AGG(`name`) FROM `users`;
```
- **GROUP BY JSON_VALUE():**按 JSON 文档中的特定值进行分组。
```sql
SELECT JSON_VALUE(`name`, '$.first_name'), COUNT(*) FROM `users` GROUP BY JSON_VALUE(`name`, '$.first_name');
```
- **HAVING JSON_VALUE():**在分组结果上应用 JSON 值的过滤条件。
```sql
SELECT JSON_VALUE(`name`, '$.first_name'), COUNT(*) FROM `users` GROUP BY JSON_VALUE(`name`, '$.first_name') HAVING JSON_VALUE(`name`, '$.first_name') = 'John';
```
# 4. JSON 数据索引与优化
### 4.1 JSON 数据索引类型
MySQL 提供了多种索引类型来优化 JSON 数据的查询性能,包括:
- **普通索引:**创建在 JSON 列上的普通索引,可以加速对 JSON 文档中特定键或值的查询。
- **全文索引:**创建在 JSON 列上的全文索引,可以支持对 JSON 文档中文本内容的全文搜索。
- **空间索引:**创建在 JSON 列中包含地理空间数据的字段上,可以加速对地理空间数据的查询。
### 4.2 JSON 数据索引优化策略
为了优化 JSON 数据的索引性能,可以采用以下策略:
- **选择合适的索引类型:**根据查询需求选择最合适的索引类型,例如对特定键或值的查询使用普通索引,对文本内容的搜索使用全文索引。
- **创建复合索引:**创建复合索引可以同时覆盖多个查询条件,提高查询效率。
- **使用覆盖索引:**创建覆盖索引可以确保查询所需的所有数据都包含在索引中,避免回表查询。
- **避免索引冗余:**避免创建不必要的索引,因为每个索引都会增加更新数据的开销。
### 示例
考虑以下 JSON 数据表:
```sql
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
name JSON NOT NULL,
PRIMARY KEY (id)
);
```
如果需要经常查询 `name` 字段中的特定键,例如 `name.first_name`,则可以创建以下普通索引:
```sql
CREATE INDEX idx_name_first_name ON users (name.first_name);
```
如果需要对 `name` 字段中的文本内容进行全文搜索,则可以创建以下全文索引:
```sql
CREATE FULLTEXT INDEX idx_name_fulltext ON users (name);
```
### 代码块示例
以下代码块展示了如何使用普通索引优化 JSON 数据的查询性能:
```sql
-- 创建普通索引
CREATE INDEX idx_name_first_name ON users (name.first_name);
-- 使用普通索引查询
SELECT * FROM users WHERE name.first_name = 'John';
-- 逻辑分析
普通索引将加速对 `name.first_name` 字段的查询,因为索引中包含了该字段的值。这避免了对整个 JSON 文档进行扫描,从而提高了查询效率。
```
### 表格示例
下表总结了 JSON 数据索引类型的特点和适用场景:
| 索引类型 | 特点 | 适用场景 |
|---|---|---|
| 普通索引 | 适用于对特定键或值的查询 | 查询特定键或值,例如 `name.first_name` |
| 全文索引 | 适用于对文本内容的全文搜索 | 搜索 JSON 文档中的文本内容 |
| 空间索引 | 适用于对地理空间数据的查询 | 查询地理空间数据,例如 `location.latitude` |
### Mermaid 流程图示例
下图展示了 JSON 数据索引优化策略的流程:
```mermaid
graph LR
subgraph 选择合适的索引类型
A[普通索引] --> B[全文索引] --> C[空间索引]
end
subgraph 优化索引策略
D[创建复合索引] --> E[使用覆盖索引] --> F[避免索引冗余]
end
A --> D
B --> E
C --> F
```
# 5.1 半结构化数据的存储与管理
### JSON 的半结构化特性
JSON 是一种半结构化数据格式,它允许数据以树形结构存储,并且允许在同级元素之间存在不同的属性。这种灵活性使得 JSON 非常适合存储半结构化数据,即具有部分结构但又不完全符合严格模式的数据。
### MySQL 中存储半结构化数据
MySQL 中可以通过使用 JSON 数据类型来存储半结构化数据。JSON 数据类型允许将 JSON 文档直接存储在数据库中,而无需将其转换为关系模型。
### JSON 数据的查询与管理
存储在 MySQL 中的 JSON 数据可以通过 SQL 查询和更新语句进行查询和管理。可以使用 JSON 查询运算符(例如 `->` 和 `$`) 来提取和修改 JSON 文档中的特定元素。
### 示例:存储和查询半结构化数据
以下示例演示了如何使用 MySQL 存储和查询半结构化数据:
```sql
-- 创建一个表来存储半结构化数据
CREATE TABLE products (
id INT NOT NULL AUTO_INCREMENT,
product_data JSON NOT NULL,
PRIMARY KEY (id)
);
-- 插入一条半结构化数据记录
INSERT INTO products (product_data) VALUES (
'{
"name": "Product A",
"price": 10.00,
"tags": ["electronics", "gadgets"],
"specifications": {
"weight": "1kg",
"dimensions": "10x10x10cm"
}
}'
);
-- 查询半结构化数据记录
SELECT * FROM products WHERE product_data->>"name" = "Product A";
```
### 优点和缺点
使用 JSON 数据类型存储半结构化数据具有以下优点:
- **灵活性:**JSON 的半结构化特性使其能够存储各种类型的半结构化数据。
- **易于查询:**MySQL 提供了专门的 JSON 查询运算符,使查询和更新 JSON 数据变得容易。
- **性能:**MySQL 对 JSON 数据类型的支持经过优化,提供了良好的查询性能。
然而,使用 JSON 数据类型也有一些缺点:
- **模式限制:**JSON 数据类型没有强制模式,这可能会导致数据不一致和难以维护。
- **索引限制:**在 JSON 数据类型上创建索引可能很复杂,并且可能影响查询性能。
- **数据膨胀:**存储在 JSON 数据类型中的数据可能会比存储在关系模型中更冗余,从而导致数据膨胀。
# 6. MySQL JSON 数据存储高级技巧**
MySQL 提供了一系列高级技巧,可以进一步提升 JSON 数据存储和管理的效率和灵活性。
### 6.1 JSON 数据的存储过程和函数
存储过程和函数是预先编译的代码块,可以存储在数据库中并按需调用。它们可以用来封装复杂的数据操作,提高代码的可重用性和性能。
**创建存储过程:**
```sql
CREATE PROCEDURE get_json_data(IN json_column VARCHAR(255))
BEGIN
SELECT json_column->'$.name' AS name, json_column->'$.age' AS age FROM table_name;
END;
```
**调用存储过程:**
```sql
CALL get_json_data('{"name": "John Doe", "age": 30}');
```
**创建函数:**
```sql
CREATE FUNCTION get_json_value(json_column VARCHAR(255), path VARCHAR(255))
RETURNS VARCHAR(255)
BEGIN
RETURN JSON_VALUE(json_column, path);
END;
```
**调用函数:**
```sql
SELECT get_json_value('{"name": "John Doe", "age": 30}', '$.name');
```
### 6.2 JSON 数据的触发器和事件
触发器和事件是数据库中的特殊对象,可以在特定事件发生时自动执行代码。它们可以用来监视和响应 JSON 数据的更改,实现数据同步、验证或其他自定义操作。
**创建触发器:**
```sql
CREATE TRIGGER update_json_data
AFTER UPDATE ON table_name
FOR EACH ROW
BEGIN
UPDATE table_name SET json_column = JSON_SET(json_column, '$.age', NEW.age);
END;
```
**创建事件:**
```sql
CREATE EVENT update_json_data_daily
ON SCHEDULE EVERY 1 DAY
DO
UPDATE table_name SET json_column = JSON_SET(json_column, '$.last_updated', NOW());
END;
```
### 6.3 JSON 数据的备份与恢复
定期备份 JSON 数据至关重要,以防数据丢失或损坏。MySQL 提供了多种备份和恢复选项。
**使用 mysqldump:**
```sql
mysqldump -u username -p password database_name table_name > backup.sql
```
**使用 xtrabackup:**
```sql
xtrabackup --backup --target-dir=/path/to/backup
```
**恢复备份:**
```sql
mysql -u username -p password database_name < backup.sql
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了有关数据库中 JSON 数据处理的全面指南,涵盖 MySQL 和 MongoDB 等流行数据库。从存储和查询到索引、聚合分析、更新、备份和恢复,该专栏深入探讨了处理半结构化 JSON 数据的最佳实践。此外,还提供了性能调优和数据迁移方面的实用技巧,帮助您优化 JSON 数据处理效率并确保数据安全。无论您是数据库新手还是经验丰富的专业人士,本专栏都能为您提供宝贵的见解和可操作的建议,帮助您充分利用 JSON 数据的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
【实时系统空间效率】:确保即时响应的内存管理技巧

# 1. 实时系统的内存管理概念
在现代的计算技术中,实时系统凭借其对时间敏感性的要求和对确定性的追求,成为了不可或缺的一部分。实时系统在各个领域中发挥着巨大作用,比如航空航天、医疗设备、工业自动化等。实时系统要求事件的处理能够在确定的时间内完成,这就对系统的设计、实现和资源管理提出了独特的挑战,其中最为核心的是内存管理。
内存管理是操作系统的一个基本组成部
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
探索与利用平衡:强化学习在超参数优化中的应用
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
【算法竞赛中的复杂度控制】:在有限时间内求解的秘籍
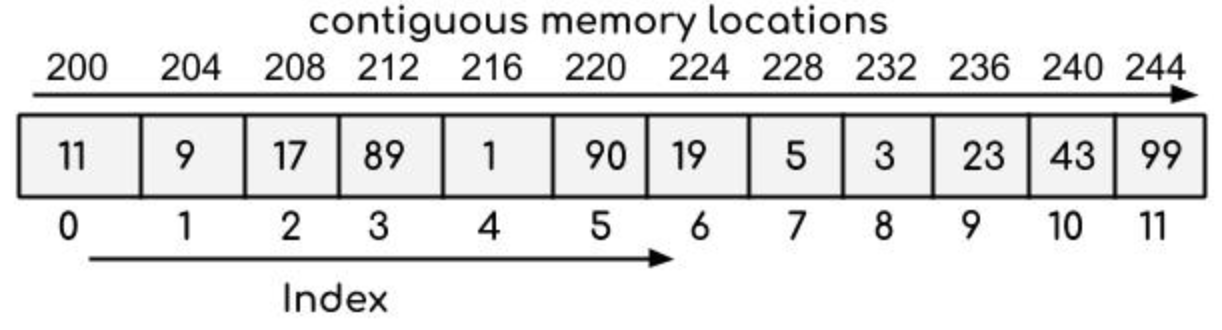
# 1. 算法竞赛中的时间与空间复杂度基础
## 1.1 理解算法的性能指标
在算法竞赛中,时间复杂度和空间复杂度是衡量算法性能的两个基本指标。时间复杂度描述了算法运行时间随输入规模增长的趋势,而空间复杂度则反映了算法执行过程中所需的存储空间大小。理解这两个概念对优化算法性能至关重要。
## 1.2 大O表示法的含义与应用
大O表示法是用于描述算法时间复杂度的一种方式。它关注的是算法运行时
如何避免在训练过程中过早停止

# 1. 避免过早停止问题的重要性
在机器学习和深度学习的训练过程中,过早停止(Early Stopping)是一个至关重要的实践。这一策略的核心在于避免模型在训
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
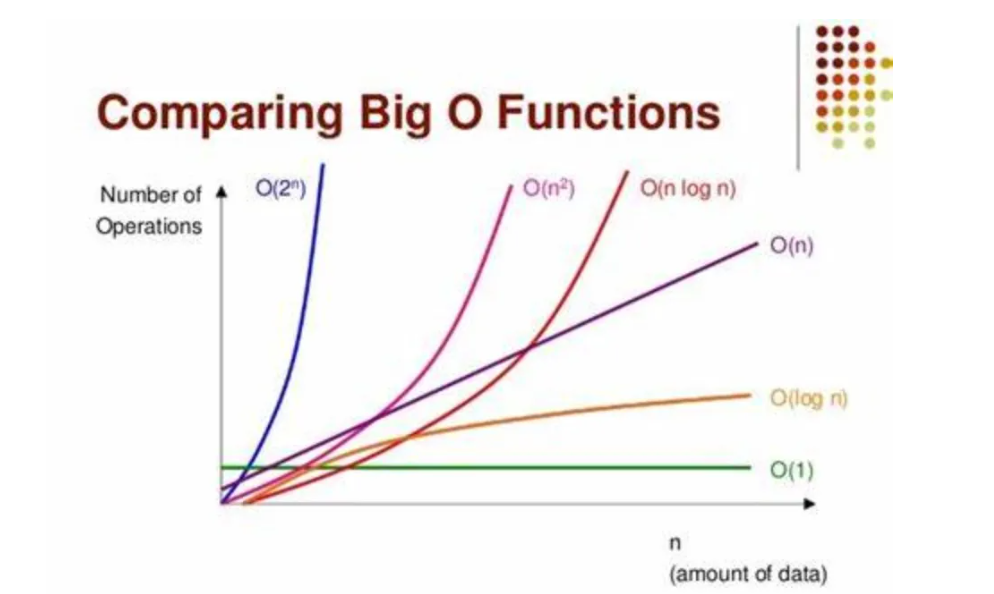
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )