【硬件加速探索】:YOLOv8如何在GPU与FPGA上实现极致优化
发布时间: 2024-12-12 00:37:56 阅读量: 20 订阅数: 17 

硬件加速-基于GPU+FPGA加速LeNet5神经网络-附项目源码-优质项目实战.zip
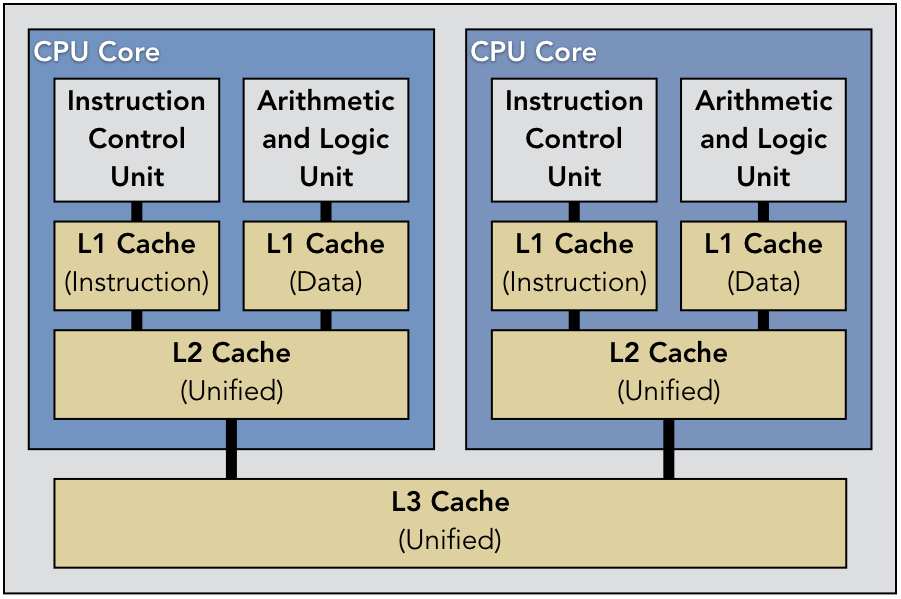
# 1. YOLOv8与硬件加速简介
YOLOv8作为YOLO(You Only Look Once)系列模型的最新版本,在计算机视觉领域中的实时对象检测任务上展现了前所未有的性能。随着深度学习技术的迅速发展和应用范围的不断扩大,对模型的计算效率提出了更高的要求。硬件加速,特别是利用GPU和FPGA等专用硬件的加速,为深度学习模型的快速执行提供了可能。
本章将从硬件加速的基本概念入手,概述YOLOv8的特点以及它如何与硬件加速技术相结合,进而提升计算性能和响应速度。我们将探讨硬件加速在深度学习中的应用背景,以及它在实现高性能计算中所扮演的关键角色。
## 1.1 YOLOv8简介
YOLOv8继承了YOLO系列模型一贯的快速准确特性,并且加入了更多创新的机制来优化检测精度和速度。与前代模型相比,YOLOv8在保持低延迟的同时,进一步提高了识别的精确度。
## 1.2 硬件加速的必要性
在处理复杂的图像识别任务时,传统的中央处理器(CPU)难以满足实时计算的需求。硬件加速技术,特别是GPU和FPGA的并行计算能力,为深度学习算法提供了强大的计算支持,从而大幅提升了模型的运行效率。
## 1.3 YOLOv8与硬件加速的结合
将YOLOv8模型部署于GPU和FPGA上,不仅可以利用这些硬件平台的并行计算特性,还可以通过定制优化来进一步提升检测速度和精度。接下来的章节将详细介绍硬件加速的理论基础以及YOLOv8在硬件加速方面的具体应用。
# 2. ```
# 第二章:GPU加速的理论基础
## 2.1 GPU加速技术概述
### 2.1.1 GPU架构与并行计算原理
GPU(图形处理单元)是专门针对大量并行计算任务设计的硬件设备。相较于CPU,GPU拥有成百上千的小核心,能够同时处理数以千计的计算任务。这种高度并行的计算能力使GPU非常适合处理图像和视频的处理、科学计算以及深度学习等应用场景。
为了实现高效的并行计算,GPU采用了SIMD(单指令多数据)和MIMD(多指令多数据)的混合设计。这些核心被组织成多个流处理器(Stream Processors)和计算单元(Compute Units),每个计算单元负责执行一个线程块内的多个线程。
GPU的内存结构是高度优化的,它包括了共享内存、常量内存、纹理内存等不同层次的存储器。这些存储器被设计用来减少数据传输的延迟,并在GPU内部实现快速的数据访问。
### 2.1.2 CUDA与OpenCL编程模型
CUDA(Compute Unified Device Architecture)是NVIDIA推出的一种并行计算平台和编程模型。它允许开发者使用C、C++以及Fortran等传统编程语言直接在NVIDIA的GPU上进行编程。CUDA的核心在于提供了一种方法,使得开发者能够轻松调用GPU的并行计算能力。
OpenCL(Open Computing Language)是另一种开放标准的编程框架,它由Khronos Group维护,支持多种处理器架构,包括CPU、GPU、DSP等。OpenCL的设计目标是实现跨平台的并行编程。
这两种模型都提供了丰富的API来管理内存、线程和设备资源,使得开发者能够将复杂的数据处理任务有效地映射到GPU上。
## 2.2 YOLOv8在GPU上的优化策略
### 2.2.1 卷积神经网络与GPU加速
卷积神经网络(CNN)由于其在图像识别领域的出色性能,已经成为深度学习中不可或缺的一部分。YOLOv8作为一种高效的目标检测模型,其底层架构大量依赖于卷积操作,这类操作高度适合GPU进行加速。
在GPU上实现CNN加速的关键在于,如何高效地将大量的卷积核运算并行化。为此,YOLOv8的网络设计中采用了特定的优化措施,比如使用深度可分离卷积来减少计算量和参数数量。
### 2.2.2 YOLOv8网络结构分析
YOLOv8的网络结构由多个卷积层、池化层和全连接层组成,这些层负责特征提取和目标分类。在GPU上实现YOLOv8时,网络的每一层都可以看作是一个计算密集型的任务,而这些任务可以被分配给GPU的多个核心。
GPU加速的优化策略之一是减少全局内存访问,提高共享内存的使用效率。这可以通过调整网络结构,使数据在不同层之间传输时,尽可能地在GPU内部的共享内存中完成,以避免昂贵的全局内存访问。
### 2.2.3 内存管理和数据传输优化
在GPU加速的应用中,内存管理和数据传输是影响性能的关键因素。YOLOv8在GPU上运行时,需要从主机内存传输大量数据到GPU内存,进行计算后再传回,这个过程中的延迟和带宽限制都可能成为性能瓶颈。
为了优化数据传输,通常会采取分批次加载数据、使用异步内存传输等技术。在YOLOv8中,还可以采用更高级的内存管理策略,例如使用零拷贝内存(Zero-Copy Memory)来进一步提升性能。
## 2.3 GPU加速实践案例分析
### 2.3.1 YOLOv8在NVIDIA GPU上的部署
在NVIDIA GPU上部署YOLOv8时,开发者可以利用NVIDIA的深度学习SDK,比如TensorRT。TensorRT是一个高性能的深度学习推理引擎,专为GPU设计,它能够对YOLOv8模型进行优化,实现更快的推理速度和更低的延迟。
部署步骤大致如下:
1. 使用TensorRT对YOLOv8模型进行转换和优化。
2. 在NVIDIA GPU上加载优化后的模型。
3. 将输入图像传递给模型并开始推理。
在部署过程中,开发者需要关注模型的精度损失和性能增益之间的平衡。
### 2.3.2 性能提升对比与分析
在对比不同GPU加速技术对YOLOv8性能的影响时,可以考虑以下几个方面:
- 推理速度(FPS):模型每秒能够处理的图像数量。
- 延迟:从数据输入到结果输出所需的时间。
- 资源占用:GPU的计算资源利用率,包括GPU核心和内存使用情况。
通过性能测试,可以得出不同的硬件配置和优化技术对YOLOv8性能的具体影响,为未来的部署提供参考。
```
### 表格:YOLOv8在GPU上性能参数比较
| GPU型号 | FPS | 平均延迟(ms) | GPU利用率 |
|---------|-----|----------------|-----------|
| GPU A | 30 | 33 | 90% |
| GPU B | 45 | 22 | 95% |
| GPU C | 55 | 18 | 85% |
### 代码块:使用TensorRT优化YOLOv8模型
```python
import tensorrt as trt
# 创建TensorRT的推理引擎
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
runtime = trt.Runtime(TRT_LOGGER)
engine = runtime.deserialize_cuda_engine(model_data)
# 使用引擎创建执行上下文
context = engine.create_execution_context()
```
在上述代码块中,首先导入了TensorRT模块,随后创建了一个运行时实例并使用模型数据对引擎进行了反序列化。最终,使用该引擎创建了一个执行上下文,之后就可以使用这个上下文进行推理。
### mermaid流程图:GPU加速数据传输流程
```mermaid
graph LR
A[开始] --> B[主机内存分配]
B --> C[将数据传输到GPU内存]
C --> D[在GPU上执行计算]
D --> E[将结果从GPU内存传输回主机内存]
E --> F[结束]
```
通过以上流程图可以清楚地看到,在GPU加速的数据传输中,数据是如何在主机内存和GPU内存之间进行传递的。这个过程中,优化内存管理显得尤为重要。
# 3. FPGA加速的理论基础
## 3.1 FPGA加速技术概述
### 3.1.1 FPGA架构与可编程性
可编程逻辑门阵列(FPGA)是一种半导体设备,它包含了数以万计的逻辑单元,通过编程配置,这些单元可以实现不同的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《YOLOv8的实时检测性能分析》专栏深入探究了YOLOv8目标检测算法的性能优化和实时检测能力。专栏涵盖了从入门到精通的性能优化全攻略,揭秘了YOLOv8与传统算法的性能对比。此外,还解析了YOLOv8模型压缩技巧、GPU和FPGA上的极致优化方法,以及多尺度检测、数据增强和损失函数调优等提高性能的策略。专栏还探讨了YOLOv8在分布式训练、端到端实时检测系统、多任务学习和自动驾驶中的创新应用。通过对NMS和Soft-NMS优化算法的深入比较,专栏提供了全面且深入的见解,帮助读者了解YOLOv8在实时检测领域的最新进展和优化技术。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SAP评估类型实战手册】:评估逻辑与业务匹配,一步到位

参考资源链接:[SAP物料评估与移动类型深度解析](https://wenku.csdn.net/doc/6487e1d8619bb054bf57ad44?spm=1055.2635.3001.10343)
# 1. SAP评估的理论基础
在现代企业资源规划(ERP)系统实施中,SAP评估是一个不可或缺的环节。本章将从理论的角度深入探讨SAP评估的
【数据可视化在MATLAB App Designer中的新境界】:打造交互式图表设计专家级技巧
参考资源链接:[MATLAB App Designer 全方位教程:GUI设计与硬件集成](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a38a?spm=1055.2
【Python量化策略秘籍】:有效避免过度拟合,提升策略稳健性

参考资源链接:[Python量化交易实战:从入门到精通](https://wenku.csdn.net/doc/7rp5f8e8
【毫米波信号模拟】:新手入门必备,一文看懂模拟基础与实践

参考资源链接:[TI mmWave Studio用户指南:安装与功能详解](https://wenku.csdn.net/doc/3moqmq4ho0?spm=1055.2635.3001.10343)
# 1. 毫米波信号模拟的基本概念
毫米波技术是现代通信系统中不可或缺的一部分,尤其是在无线通信和雷达系统中。毫米波信号模拟是利用计算机
MPS-MP2315芯片编程零基础教程:一步学会编程与技巧

参考资源链接:[MP2315高效能3A同步降压转换器技术规格](https://wenku.csdn.net/doc/87z1cfu6qv?spm=1055.2635.3001.10343)
# 1. MPS-MP2315芯片编程入门
## 1.1 初识MPS-MP2315
MPS-MP2315芯片是一款广泛
射频技术在V93000 Wave Scale RF中的应用实践:提升你的技术深度

参考资源链接:[Advantest V93000 Wave Scale RF 训练教程](https://wenku.csdn.net/doc/1u2r85x0y8?spm=1055.2635.3001.10343)
# 1. 射频技术基础与V93000 Wave Scale RF概述
射频技术是无线通信领域的核心技术之一,它涉及
【RoCEv2技术深度剖析】:揭秘数据中心网络性能提升的7大策略

参考资源链接:[InfiniBand Architecture 1.2.1: RoCEv2 IPRoutable Protocol Extension](https://wenku.csdn.net/doc/645f2
【dSPACE RTI 实战攻略】:新手快速入门与性能调优秘籍

参考资源链接:[DSpace RTI CAN Multi Message开发配置教程](https://wenku.csdn.net/doc/33wfcned3q?spm=1055.2635.3001.10343)
# 1. dSPACE RTI 基础知识概述
在
S32DS编译器内存管理优化指南:减少{90%

参考资源链接:[S32DS编译器官方指南:快速入门与项目设置](https://wenku.csdn.net/doc/6401abd2cce7214c316e9a18?spm=1055.2635.3001.10343)
# 1. S32DS编译器内存管理优化概述
内存管理在嵌入式系统开发中占据了极其重要的地位,尤其是在资源受限的系统中,如何高效地管理内存直接影响到系统的性能和稳定性。S32DS编译器作为针对NXP S32微
实验室安全隐患排查:BUPT试题解析与实战演练的终极指南
参考资源链接:[北邮实验室安全试题与答案解析](https://wenku.csdn.net/doc/12n6v787z3?spm=1055.2635.3001.10343)
# 1. 实验室安全隐患排查的重要性与原则
## 实验室安全隐患排查的重要性
在当今社会,实验室安全已成为全社会关注的焦点。实验室安全隐患排查的重要性不言而喻,它直接关系到实验人员的生命安全和身体健康。对于实验室管理者来说,确保实验室安全运行是其基本职责。忽视安全隐患排查将导致严重后果,包括环境污染、财产损失甚至人员伤亡。因此,必须强调实验室安全隐患排查的重要性,从源头上预防和控制安全事故的发生。
## 实验室安全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )