MATLAB滤波器性能评估:5大指标,助你优化滤波器表现
发布时间: 2024-06-07 02:04:43 阅读量: 184 订阅数: 56 

滤波器的设计优化及Matlab实现
# 1. MATLAB滤波器性能评估概述**
MATLAB滤波器性能评估是评估滤波器在处理信号时表现的一种重要手段。它可以帮助我们了解滤波器的特性,并根据需要对其进行优化。滤波器性能评估通常涉及两个主要方面:频域指标和时域指标。
频域指标评估滤波器在频率域中的特性,包括幅度响应、相位响应和群时延。时域指标评估滤波器在时间域中的特性,包括脉冲响应、阶跃响应和稳定性。通过评估这些指标,我们可以全面了解滤波器的性能,并确定其是否满足特定应用的要求。
# 2.1 频域指标
频域指标用于评估滤波器在频率域的性能,包括幅度响应、相位响应和群时延。
### 2.1.1 幅度响应
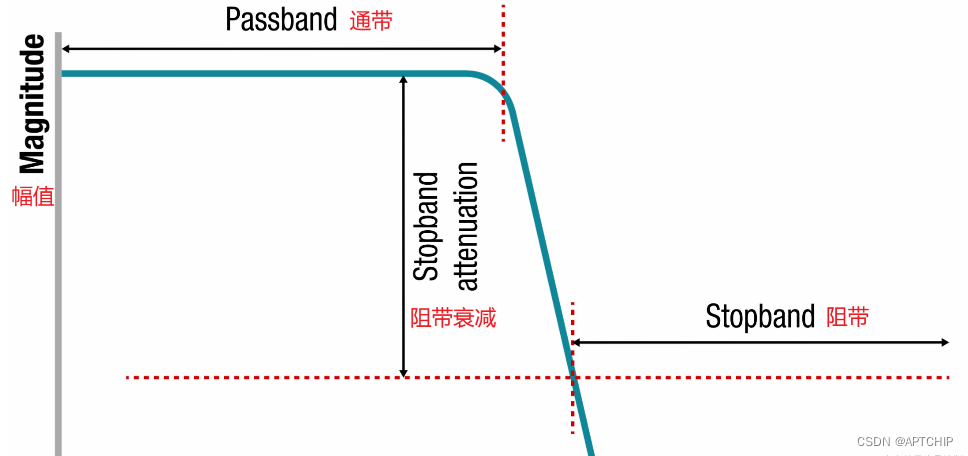
幅度响应表示滤波器在不同频率下的增益。理想的幅度响应在通带内保持平坦,而在阻带内衰减。
**代码块:**
```
% 生成频率响应数据
[H, f] = freqz(b, a, 512);
% 绘制幅度响应
figure;
semilogx(f, 20*log10(abs(H)));
grid on;
xlabel('Frequency (Hz)');
ylabel('Magnitude (dB)');
title('Amplitude Response');
```
**逻辑分析:**
* `freqz` 函数计算滤波器 `b` 和 `a` 的频率响应。
* `semilogx` 函数绘制半对数图,其中频率在 x 轴上,幅度以分贝为单位在 y 轴上。
* 网格线和标签用于增强可读性。
### 2.1.2 相位响应
相位响应表示滤波器在不同频率下的相移。理想的相位响应在通带内为线性,而在阻带内为非线性。
**代码块:**
```
% 绘制相位响应
figure;
semilogx(f, angle(H));
grid on;
xlabel('Frequency (Hz)');
ylabel('Phase (radians)');
title('Phase Response');
```
**逻辑分析:**
* `angle` 函数计算滤波器的相位响应。
* `semilogx` 函数绘制半对数图,其中频率在 x 轴上,相位以弧度为单位在 y 轴上。
* 网格线和标签用于增强可读性。
### 2.1.3 群时延
群时延表示信号通过滤波器所需的时间。理想的群时延在通带内保持恒定,而在阻带内增加。
**代码块:**
```
% 计算群时延
gd = grpdelay(b, a);
% 绘制群时延
figure;
plot(f, gd);
grid on;
xlabel('Frequency (Hz)');
ylabel('Group Delay (s
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MATLAB滤波器专栏是一份全面的指南,旨在帮助您掌握MATLAB滤波器的方方面面。从基础知识到高级应用,本专栏涵盖了滤波技术的所有关键方面,包括设计、实现、评估和应用。通过揭示10个必知秘诀、提供设计指南、展示实战宝典、介绍性能评估指标以及探索广泛的应用领域,本专栏将为您提供所需的知识和技能,以有效地使用MATLAB滤波器解决各种信号处理、图像处理、数据分析、控制系统、通信系统、生物医学信号处理、音频处理、视频处理、机器学习、深度学习、计算机视觉、自然语言处理、金融数据分析、科学计算和工程设计中的问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
霍尼韦尔SIS系统性能优化大揭秘:可靠性提升的关键步骤

# 摘要
霍尼韦尔安全仪表系统(SIS)作为保障工业过程安全的关键技术,其性能优化对于提高整体可靠性、可用性和可维护性至关重要。本文首先介绍了SIS系统的基础知识、关键组件
【Ansys电磁场分析】:掌握网格划分,提升仿真准确度的关键
# 摘要
本文详细探讨了Ansys软件中电磁场分析的网格划分技术,从理论基础到实践技巧,再到未来发展趋势。首先,文章概述了网格划分的概念、重要性以及对电磁场分析准确度的影响。接着,深入分析了不同类型的网格、网格质量指标以及自适应技术和网格无关性研究等实践技巧。通过案例分析,展示了网格划分在平面电磁波、复杂结构和高频电磁问题中的应用与优化策略。最后,讨论了网格划分与仿真准确度的关联,并对未来自动网
故障排查的艺术:H9000系统常见问题与解决方案大全

# 摘要
H9000系统作为本研究的对象,首先对其进行了全面的概述。随后,从理论基础出发,分析了系统故障的分类、特点、系统日志的分析以及故障诊断工具与技巧。本研究深入探讨了H9000系统在实际运行中遇到的常见问题,包括启动失败、性能问题及网络故障的排查实例,并详细阐述了这些问题的解决策略。在深入系统核心的故障处理方面,重点讨论
FSCapture90.7z跨平台集成秘籍:无缝协作的高效方案
# 摘要
本文旨在详细介绍FSCapture90.7z软件的功能、安装配置以及其跨平台集成策略。首先,文中对FSCapture90.7z的基本概念、系统要求和安装步骤进行了阐述,接着探讨了配置优化和文件管理的高级技巧。在此基础上,文章深入分析了FSCapture90.
【N-CMAPSS数据集深度解析】:实现大规模数据集高效存储与分析的策略
# 摘要
N-CMAPSS数据集作为一项重要资源,提供了深入了解复杂系统性能与故障预测的可能性。本文首先概述了N-CMAPSS数据集,接着详细探讨了大规模数据集的存储与分析方法,涵盖了存储技术、分析策略及深度学习应用。本文深入研究了数据集存储的基础、分布式存储系统、存储系统的性能优化、数据预处理、高效数据分析算法以及可视化工具的使用。通过案例分析,本文展示了N
【Spartan7_XC7S15硬件设计精讲】:精通关键组件与系统稳定性
# 摘要
本文对Xilinx Spartan7_XC7S15系列FPGA硬件进行了全面的分析与探讨。首先概述了硬件的基础架构、关键组件和设计基础,包括FPGA核心架构、输入/输出接口标准以及电源与散热设计。随后,本文深入探讨了系统稳定性优化的策略,强调了系统级时序分析、硬件故障诊断预防以及温度和环境因素对系统稳定性的影响。此外,通过案例分析,展示了S
MAX7000芯片时序分析:5个关键实践确保设计成功

# 摘要
本文系统地介绍了MAX7000芯片的基础知识、时序参数及其实现和优化。首先概述了MAX7000芯片的基本特性及其在时序基础方面的重要性。接着,深入探讨了时序参数的理论概念,如Setup时间和Hold时间,时钟周期与频率,并分析了静态和动态时序分析方法以及工艺角对时序参数
Acme财务状况深度分析:稳健增长背后的5大经济逻辑

# 摘要
本论文对Acme公司进行了全面的财务分析,涵盖了公司的概况、收入增长、盈利能力、资产与负债结构以及现金流和投资效率。通过对Acme主营业务的演变、市
机器人集成实战:SINUMERIK 840D SL自动化工作流程高效指南
# 摘要
本文旨在全面介绍SINUMERIK 840D SL自动化系统,从理论基础与系统架构出发,详述其硬件组件和软件架构,探讨自动化工作流程的理论以及在实际操作中的实现和集成。文中深入分析了SINUMERIK 840D SL的程序设计要点,包括NC程序的编写和调试、宏程序及循环功能的利用,以及机器人通信集成的机制。同时,通过集成实践与案例分析,展示自动化设备集成的过程和关键成功因素。此外,本文还提出了维护与故障诊断的策略,并对自动化技术的未来趋势与技术创新进行了展望。
# 关键字
SINUMERIK 840D SL;自动化系统;程序设计;设备集成;维护与故障诊断;技术革新
参考资源链接:
单片机与HT9200A交互:数据流与控制逻辑的精妙解析

# 摘要
本文旨在全面介绍单片机与HT9200A芯片之间的交互原理及实践应用。首先概述了单片机与HT9200A的基本概念和数据通信基础知识,随后深入解析了HT9200A的串行通信协议、接口电路设计以及关键引脚功能。第二部分详细探讨了HT9200A控制逻辑的实现,包括基本控制命令的发送与响应、复杂控制流程的构建,以及错误检测和异常处理机制。第三章将理论应用于实践,指导读者
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )