转置矩阵在机器学习中的应用:从理论到实践,揭秘5个关键场景
发布时间: 2024-07-12 18:27:01 阅读量: 116 订阅数: 78 

果壳处理器研究小组(Topic基于RISCV64果核处理器的卷积神经网络加速器研究)详细文档+全部资料+优秀项目+源码.zip

# 1. 转置矩阵的理论基础**
转置矩阵是一个将矩阵行和列互换得到的矩阵。对于一个m×n矩阵A,其转置矩阵AT为一个n×m矩阵,其中AT的第i行第j列元素等于A的第j行第i列元素。
转置矩阵具有以下性质:
- (AB)T = BTAT
- (AT)T = A
- (A+B)T = AT+BT
- (kA)T = kAT,其中k为标量
# 2.1 矩阵运算的优化
### 2.1.1 转置矩阵在矩阵乘法中的应用
在机器学习中,矩阵乘法是常见的操作,用于计算模型权重、特征转换和预测结果。转置矩阵可以优化矩阵乘法的计算效率。
考虑两个矩阵 A 和 B,其中 A 的维度为 m x n,B 的维度为 n x p。常规的矩阵乘法计算复杂度为 O(mnp)。
通过转置矩阵 B,使其维度变为 p x n,可以将矩阵乘法优化为 A * B^T。此时,计算复杂度变为 O(mn + np),当 m 和 n 远大于 p 时,优化效果显著。
**代码块:**
```python
import numpy as np
# 原矩阵 A 和 B
A = np.array([[1, 2, 3], [4, 5, 6]])
B = np.array([[7, 8], [9, 10], [11, 12]])
# 转置矩阵 B
B_T = np.transpose(B)
# 矩阵乘法
C = A @ B_T
print(C)
```
**逻辑分析:**
* `np.transpose(B)`:转置矩阵 B,将维度从 n x p 变为 p x n。
* `A @ B_T`:执行矩阵乘法,优化后的计算复杂度为 O(mn + np)。
### 2.1.2 转置矩阵在特征工程中的应用
特征工程是机器学习中至关重要的步骤,用于提取和转换原始数据中的有用特征。转置矩阵可以简化特征工程中的某些操作。
例如,在 one-hot 编码中,将类别特征转换为二进制向量。常规方法需要逐行转换,计算复杂度为 O(mn),其中 m 为样本数,n 为类别数。
通过转置原始数据,使其维度变为 n x m,再进行 one-hot 编码,计算复杂度优化为 O(nm)。
**代码块:**
```python
import pandas as pd
# 原始数据
data = pd.DataFrame({
'category': ['A', 'B', 'C', 'A', 'B'],
'value': [1, 2, 3, 4, 5]
})
# 转置数据
data_T = data.T
# one-hot 编码
data_onehot = pd.get_dummies(data_T)
print(data_onehot)
```
**逻辑分析:**
* `data.T`:转置原始数据,将维度从 m x n 变为 n x m。
* `pd.get_dummies(data_T)`:执行 one-hot 编码,优化后的计算复杂度为 O(nm)。
# 3. 转置矩阵在机器学习中的实践案例
### 3.1 自然语言处理
#### 3.1.1 转置矩阵在文本分类中的应用
在文本分类任务中,转置矩阵可用于将文本数据转换为适合分类模型处理的格式。具体而言,转置矩阵可以将文本数据中的词语按行排列,按列排列则为文档。通过这种转换,每个文档都可以表示为一个词语向量,其中每个元素代表该词语在文档中出现的频率。
```python
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# 文本数据
texts = ["This is a sample text.", "This is another sample text."]
# 创建词语向量化器
vectorizer = CountVectorizer()
# 将文本数据转换为词语向量
X = vectorizer.fit_transform(texts)
# 获取词语向量
word_vectors = X.toarray()
# 转置词语向量
transposed_word_vectors = word_vectors.T
# 打印转置后的词语向量
print(transposed_word_vectors)
```
**代码逻辑分析:**
* 使用 `CountVectorizer` 将文本数据转换为词语向量。
* 将词语向量转换为 NumPy 数组。
* 使用 `T` 属性转置词语向量。
* 打印转置后的词语向量。
#### 3.1.2 转置矩阵在文本挖掘中的应用
在文本挖掘任务中,转置矩阵可用于发现文本数据中的模式和关系。例如,通过转置文本数据,我们可以识别频繁出现的词语对或词语组。
```python
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
# 文本数据
texts = ["This is a sample text.", "This is another sample text."]
# 创建 TF-IDF 向量化器
vectorizer = TfidfVectorizer()
# 将文本数据转换为 TF-IDF 向量
X = vectorizer.fit_transform(texts)
# 获取 TF-IDF 向量
tfidf_vectors = X.toarray()
# 转置 TF-IDF 向量
transposed_tfidf_vectors = tfidf_vectors.T
# 打印转置后的 TF-IDF 向量
print(transposed_tfidf_vectors)
```
**代码逻辑分析:**
* 使用 `TfidfVectorizer` 将文本数据转换为 TF-IDF 向量。
* 将 TF-IDF 向量转换为 NumPy 数组。
* 使用 `T` 属性转置 TF-IDF 向量。
* 打印转置后的 TF-IDF 向量。
### 3.2 图像处理
#### 3.2.1 转置矩阵在图像增强中的应用
在图像增强任务中,转置矩阵可用于对图像进行旋转、翻转等操作。通过转置图像,我们可以改变图像的维度,从而实现图像的增强。
```python
import numpy as np
import cv2
# 读取图像
image = cv2.imread("image.jpg")
# 转置图像
transposed_image = np.transpose(image)
# 显示转置后的图像
cv2.imshow("Transposed Image", transposed_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**代码逻辑分析:**
* 使用 `cv2.imread()` 读取图像。
* 使用 `np.transpose()` 转置图像。
* 使用 `cv2.imshow()` 显示转置后的图像。
* 使用 `cv2.waitKey(0)` 等待用户输入。
* 使用 `cv2.destroyAllWindows()` 关闭所有窗口。
#### 3.2.2 转置矩阵在图像分割中的应用
在图像分割任务中,转置矩阵可用于将图像分割成不同的区域。通过转置图像,我们可以改变图像的维度,从而更容易地识别图像中的不同区域。
```python
import numpy as np
import cv2
# 读取图像
image = cv2.imread("image.jpg")
# 转置图像
transposed_image = np.transpose(image)
# 使用 K-Means 聚类分割图像
kmeans = cv2.kmeans(transposed_image.reshape(-1, 3), 3)
# 将图像分割成不同区域
segmented_image = kmeans[1].reshape(image.shape)
# 显示分割后的图像
cv2.imshow("Segmented Image", segmented_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**代码逻辑分析:**
* 使用 `cv2.imread()` 读取图像。
* 使用 `np.transpose()` 转置图像。
* 将转置后的图像转换为一维数组。
* 使用 `cv2.kmeans()` 对图像进行 K-Means 聚类。
* 将聚类结果转换为二维数组。
* 使用 `cv2.imshow()` 显示分割后的图像。
* 使用 `cv2.waitKey(0)` 等待用户输入。
* 使用 `cv2.destroyAllWindows()` 关闭所有窗口。
# 4.1 深度学习
### 4.1.1 转置矩阵在卷积神经网络中的应用
在卷积神经网络(CNN)中,转置矩阵被用于执行反卷积操作,也称为转置卷积。转置卷积是一种将特征图上采样的操作,可以增加特征图的分辨率。
**代码块:**
```python
import tensorflow as tf
# 定义输入特征图
input_features = tf.constant([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 定义转置卷积核
transpose_kernel = tf.constant([[0.5, 0.5], [0.5, 0.5]])
# 执行转置卷积操作
output_features = tf.nn.conv2d_transpose(input_features, transpose_kernel, strides=[1, 1, 1, 1], padding='SAME')
# 打印输出特征图
print(output_features)
```
**逻辑分析:**
* `input_features`是输入的特征图,形状为`[3, 3, 1]`, 其中`3`表示特征图的高度和宽度,`1`表示通道数。
* `transpose_kernel`是转置卷积核,形状为`[2, 2, 1, 1]`, 其中`2`表示卷积核的高度和宽度,`1`表示输入通道数和输出通道数。
* `strides`参数指定卷积操作的步长,这里设置为`[1, 1, 1, 1]`, 表示在每个维度上步长为1。
* `padding`参数指定卷积操作的填充方式,这里设置为`'SAME'`, 表示输出特征图的大小与输入特征图相同。
* `output_features`是转置卷积操作的输出,形状为`[3, 3, 1]`, 分辨率与输入特征图相同。
### 4.1.2 转置矩阵在循环神经网络中的应用
在循环神经网络(RNN)中,转置矩阵被用于计算梯度,以便在反向传播过程中更新模型参数。
**代码块:**
```python
import tensorflow as tf
# 定义循环神经网络单元
rnn_cell = tf.nn.rnn_cell.BasicRNNCell(num_units=10)
# 定义输入序列
input_sequence = tf.constant([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 定义输出序列
output_sequence, _ = tf.nn.dynamic_rnn(rnn_cell, input_sequence, dtype=tf.float32)
# 计算梯度
gradients = tf.gradients(output_sequence, input_sequence)
# 打印梯度
print(gradients)
```
**逻辑分析:**
* `rnn_cell`是循环神经网络单元,`num_units`参数指定隐藏状态的维度。
* `input_sequence`是输入序列,形状为`[3, 3]`, 其中`3`表示序列的长度,`3`表示每个时间步的输入维度。
* `output_sequence`是循环神经网络的输出序列,形状为`[3, 10]`, 其中`3`表示序列的长度,`10`表示每个时间步的输出维度。
* `gradients`是输出序列相对于输入序列的梯度,形状为`[3, 3]`, 其中`3`表示序列的长度,`3`表示每个时间步的梯度维度。
* 在反向传播过程中,转置矩阵被用于计算梯度,以便更新模型参数。
# 5.1 并行计算
### 5.1.1 转置矩阵在分布式计算中的应用
在分布式计算中,转置矩阵可用于优化数据并行化处理。通过将矩阵转置,可以将数据块分配到不同的计算节点上进行并行计算,从而提高计算效率。
**代码块:**
```python
import numpy as np
from dask.distributed import Client
# 创建一个分布式客户端
client = Client()
# 创建一个大矩阵
matrix = np.random.rand(10000, 10000)
# 转置矩阵
transposed_matrix = client.submit(np.transpose, matrix)
# 并行计算矩阵乘法
result = client.submit(np.matmul, transposed_matrix, matrix)
# 获取计算结果
result.result()
```
**逻辑分析:**
* 使用 `dask.distributed` 库创建分布式客户端。
* 创建一个大矩阵 `matrix`。
* 使用 `client.submit` 将矩阵转置任务提交到分布式客户端。
* 使用 `client.submit` 将矩阵乘法任务提交到分布式客户端。
* 使用 `result.result()` 获取计算结果。
**参数说明:**
* `matrix`: 待转置的矩阵。
* `transposed_matrix`: 转置后的矩阵。
* `result`: 矩阵乘法计算结果。
### 5.1.2 转置矩阵在 GPU 加速中的应用
在 GPU 加速中,转置矩阵可用于优化数据布局,以提高 GPU 内核的性能。通过将矩阵转置,可以将数据组织成更适合 GPU 内核并行计算的形式。
**代码块:**
```python
import numpy as np
import cupy as cp
# 创建一个大矩阵
matrix = np.random.rand(10000, 10000)
# 将矩阵复制到 GPU
gpu_matrix = cp.asarray(matrix)
# 转置矩阵
transposed_gpu_matrix = cp.transpose(gpu_matrix)
# 使用 GPU 内核计算矩阵乘法
result = cp.matmul(transposed_gpu_matrix, gpu_matrix)
# 将结果复制回 CPU
result = result.get()
```
**逻辑分析:**
* 使用 `cupy` 库将矩阵复制到 GPU。
* 使用 `cp.transpose` 转置 GPU 矩阵。
* 使用 GPU 内核计算矩阵乘法。
* 将结果复制回 CPU。
**参数说明:**
* `matrix`: 待转置的矩阵。
* `gpu_matrix`: GPU 上的矩阵。
* `transposed_gpu_matrix`: GPU 上转置后的矩阵。
* `result`: 矩阵乘法计算结果。
# 6. 转置矩阵在机器学习中的未来展望**
**6.1 新兴技术**
**6.1.1 转置矩阵在量子机器学习中的应用**
量子机器学习是机器学习的一个新兴领域,它利用量子力学原理来解决传统机器学习方法难以解决的问题。转置矩阵在量子机器学习中具有重要的作用,因为它可以用于:
- **量子态的表示:**转置矩阵可以用来表示量子态,这对于量子算法的开发和实现至关重要。
- **量子门的优化:**转置矩阵可以用来优化量子门的性能,从而提高量子算法的效率。
- **量子纠缠的分析:**转置矩阵可以用来分析量子纠缠,这对于理解量子机器学习的复杂性至关重要。
**6.1.2 转置矩阵在边缘计算中的应用**
边缘计算是一种分布式计算范式,它将计算任务移至靠近数据源的设备上。转置矩阵在边缘计算中具有重要的作用,因为它可以用于:
- **数据预处理:**转置矩阵可以用来对边缘设备上的数据进行预处理,从而减少数据传输的开销。
- **模型压缩:**转置矩阵可以用来压缩机器学习模型,从而使其能够在边缘设备上部署。
- **推理加速:**转置矩阵可以用来加速边缘设备上的推理过程,从而提高实时响应能力。
**6.2 应用领域拓展**
**6.2.1 转置矩阵在医疗保健中的应用**
转置矩阵在医疗保健领域具有广泛的应用,包括:
- **医疗图像分析:**转置矩阵可以用来分析医疗图像,如 X 射线和 MRI 扫描,以检测疾病和异常情况。
- **药物发现:**转置矩阵可以用来模拟药物与蛋白质的相互作用,从而加速药物发现过程。
- **个性化医疗:**转置矩阵可以用来分析患者数据,以制定个性化的治疗计划。
**6.2.2 转置矩阵在金融科技中的应用**
转置矩阵在金融科技领域具有重要的应用,包括:
- **风险管理:**转置矩阵可以用来分析金融数据,以识别和管理风险。
- **欺诈检测:**转置矩阵可以用来检测金融欺诈,如信用卡欺诈和洗钱。
- **投资组合优化:**转置矩阵可以用来优化投资组合,以最大化收益和最小化风险。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“转置”专栏深入探讨了转置矩阵在各个领域的广泛应用。通过一系列文章,专栏揭示了转置矩阵在机器学习、图像处理、数据分析、数值计算、计算机图形学、量子计算、密码学、金融建模、统计学、运筹学、控制理论、信号处理、电气工程、材料科学和生物信息学中的关键作用。专栏提供了对转置矩阵数学原理的深入理解,并展示了其在优化性能、挖掘隐藏模式、加速计算、简化分析和解决复杂问题的实际应用。通过揭示转置矩阵在不同学科中的广泛影响,该专栏旨在帮助读者掌握这一强大的数学工具,并充分利用其在解决实际问题中的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
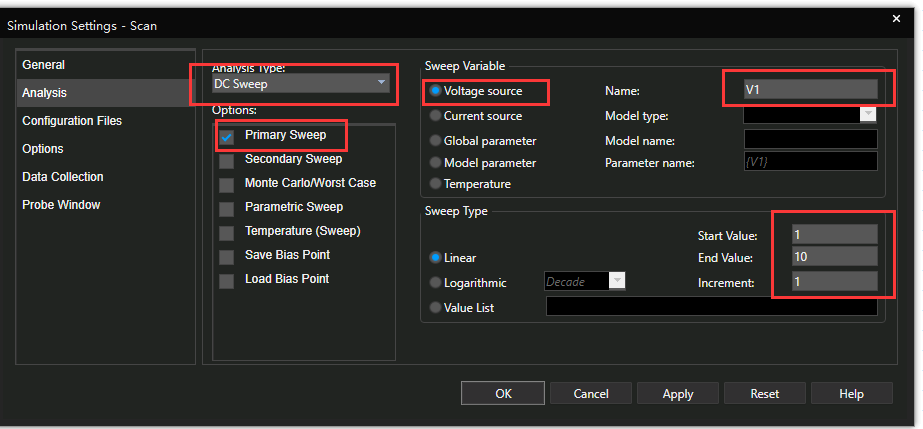
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )