PL_SQL连接MySQL数据库数据类型映射:跨数据库数据类型转换,保障数据一致性
发布时间: 2024-07-24 22:32:01 阅读量: 28 订阅数: 33 

# 1. PL/SQL连接MySQL数据库概述
PL/SQL是一种面向过程的编程语言,用于增强Oracle数据库的处理能力。它允许开发人员创建存储过程、函数、触发器和其他数据库对象。随着MySQL数据库的普及,将PL/SQL与MySQL数据库连接的需求也日益增长。
通过使用PL/SQL与MySQL数据库连接,开发人员可以利用PL/SQL的强大功能来操作MySQL数据库。这包括执行查询、更新数据、创建和管理表等。此外,PL/SQL还可以用于编写复杂的业务逻辑,从而简化数据库应用程序的开发。
# 2. PL/SQL与MySQL数据类型映射原理
### 2.1 PL/SQL数据类型介绍
PL/SQL是一种高级编程语言,用于Oracle数据库开发。它支持多种数据类型,可以分为标量数据类型和集合数据类型。
#### 2.1.1 标量数据类型
标量数据类型表示单个值,包括:
- **数值类型:**NUMBER、INTEGER、FLOAT、REAL
- **字符类型:**CHAR、VARCHAR2、NCHAR、NVARCHAR2
- **日期和时间类型:**DATE、TIME、TIMESTAMP
- **布尔类型:**BOOLEAN
#### 2.1.2 集合数据类型
集合数据类型表示一组值,包括:
- **数组:**VARRAY、NESTED TABLE
- **记录:**RECORD
- **对象:**OBJECT
### 2.2 MySQL数据类型介绍
MySQL是一种开源关系型数据库管理系统。它也支持多种数据类型,可以分为数值类型、字符串类型和日期和时间类型。
#### 2.2.1 数值类型
数值类型用于存储数字值,包括:
- **整数类型:**TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT
- **浮点数类型:**FLOAT、DOUBLE、DECIMAL
#### 2.2.2 字符串类型
字符串类型用于存储文本数据,包括:
- **固定长度字符串:**CHAR
- **可变长度字符串:**VARCHAR
- **二进制字符串:**BINARY、VARBINARY
#### 2.2.3 日期和时间类型
日期和时间类型用于存储日期和时间值,包括:
- **日期类型:**DATE
- **时间类型:**TIME
- **日期和时间类型:**DATETIME、TIMESTAMP
# 3.1 基本数据类型映射
#### 3.1.1 整数类型映射
PL/SQL中的整数类型包括NUMBER、INTEGER、SMALLINT和TINYINT,而MySQL中的整数类型包括TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT等。在映射时,需要考虑数据范围和精度。
```sql
-- PL/SQL中的NUMBER类型
DECLARE num NUMBER(10, 2);
-- MySQL中的INT类型
CREATE TABLE t1 (id INT);
```
**参数说明:**
* `NUMBER(10, 2)`:表示精度为10位,小数点后2位
* `INT`:表示32位有符号整数
**逻辑分析:**
PL/SQL中的`NUMBER`类型可以映射到MySQL中的`INT`类型,因为两者都是有符号整数类型。`NUMBER`类型的精度和范围大于`INT`类型,因此在映射时不会出现精度损失。
#### 3.1.2 浮点数类型映射
PL/SQL中的浮点数类型包括FLOAT、DOUBLE和BINARY_FLOAT,而MySQL中的浮点数类型包括FLOAT、DOUBLE和DECIMAL。在映射时,需要考虑数据范围、精度和舍入方式。
```sql
-- PL/SQL中的FLOAT类型
DECLARE f FLOAT;
-- MySQL中的FLOAT类型
CREATE TABLE t2 (price FLOAT);
```
**参数说明:**
* `FLOAT`:表示单精度浮点数
* `FLOAT`:表示单精度浮点数
**逻辑分析:**
PL/SQL中的`FLOAT`

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PL/SQL 连接 MySQL 数据库的方方面面,提供了一系列实用的指南和解决方案,助力跨数据库访问。从连接机制的剖析到常见问题的解决,从连接池的原理和应用到数据类型映射和字符集处理,再到日期时间处理、XML 和 JSON 数据处理,以及性能监控和最佳实践,本专栏涵盖了跨数据库连接的各个方面。通过深入的分析和丰富的案例,本专栏为开发人员提供了全面且实用的知识,帮助他们构建高效、可靠且可扩展的跨数据库应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【大数据精细化管理】:掌握ReduceTask与分区数量的精准调优技巧

# 1. 大数据精细化管理概述
在当今的信息时代,企业与组织面临着数据量激增的挑战,这要求我们对大数据进行精细化管理。大数据精细化管理不仅关系到数据的存储、处理和分析的效率,还直接关联到数据价值的最大化。本章节将概述大数据精细化管理的概念、重要性及其在业务中的应用。
大数据精细化管理涵盖从数据
MapReduce与大数据:挑战PB级别数据的处理策略
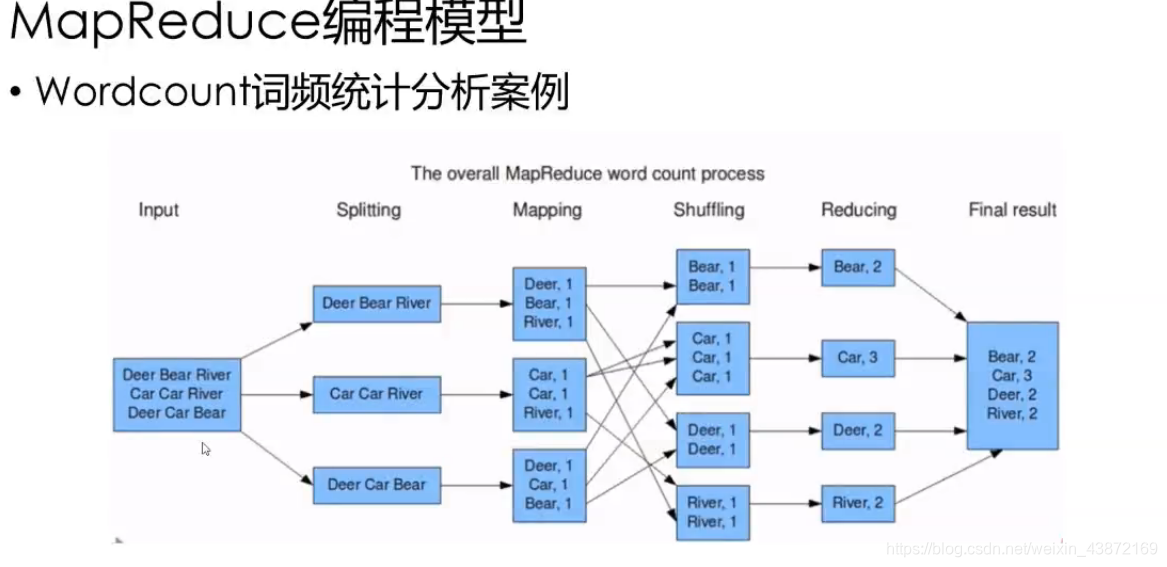
# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
MapReduce自定义分区:规避陷阱与错误的终极指导

# 1. MapReduce自定义分区的理论基础
MapReduce作为一种广泛应用于大数据处理的编程模型,其核心思想在于将计算任务拆分为Map(映射)和Reduce(归约)两个阶段。在MapReduce中,数据通过键值对(Key-Value Pair)的方式被处理,分区器(Partitioner)的角色是决定哪些键值对应该发送到哪一个Reducer。这种机制至关
【Flink流处理加速】:深入探讨分片大小调整的影响

# 1. Flink流处理概述
Flink流处理是当前大数据处理领域的一个关键技术和工具。作为Apache基金会的顶级项目,它在实时数据处理方面具有出色的
项目中的Map Join策略选择
# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner

# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
【MapReduce数据处理】:掌握Reduce阶段的缓存机制与内存管理技巧

# 1. MapReduce数据处理概述
MapReduce是一种编程模型,旨在简化大规模数据集的并行运算。其核心思想是将复杂的数据处理过程分解为两个阶段:Map(映射)阶段和Reduce(归约)阶段。Map阶段负责处理输入数据,生成键值对集合;Reduce阶段则对这些键值对进行合并处理。这一模型在处理大量数据时,通过分布式计算,极大地提
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )