Python数据科学优化算法应用:5个案例研究揭示算法的魔力
发布时间: 2024-12-07 02:29:38 阅读量: 20 订阅数: 14 

# 1. 数据科学中的优化算法概述
## 1.1 优化算法的重要性
在数据科学领域,优化算法扮演着至关重要的角色。它们是使模型能够从数据中学习并提高性能的基础。无论是在参数调优还是在训练过程中最小化误差,优化算法都是解决问题的核心。
## 1.2 优化问题的分类
优化问题可以是无约束的,也可以是有约束的。在机器学习中,我们通常遇到的是有约束问题,例如在参数空间中的限制,或者在特征选择上的限制。优化算法需要考虑到这些约束条件,以确保找到的解是可行的。
## 1.3 常见优化算法简介
优化算法种类繁多,包括但不限于梯度下降、牛顿法、拟牛顿法、遗传算法等。每种算法都有其适用场景和优缺点。例如,梯度下降是许多优化问题的基础,适用于可以明确计算梯度的场景。
优化算法是数据科学的基石,它们影响着从数据预处理到模型训练的每一个环节。在接下来的章节中,我们将深入探讨线性回归、聚类算法以及深度学习中的优化实践和案例分析。
# 2. 线性回归的优化实践
线性回归是最基础且广泛应用于数据科学中的预测建模技术。它试图找到变量间的线性关系,通过这种关系对未知变量进行预测。由于其简洁性和解释性,线性回归成为了机器学习初学者的首选算法,同时也是资深数据科学家用以建立基线模型的重要工具。
## 2.1 线性回归的基础理论
### 2.1.1 线性回归模型的数学原理
线性回归模型试图找到一个线性方程,使得该方程的预测值和实际观测值的差异最小化。假设有一个数据集,其中包含一个或多个自变量(解释变量)和一个因变量(响应变量),线性回归模型可以表示为:
\[y = \beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_nx_n + \epsilon\]
在这里,\(y\)是因变量,\(x_1, x_2, ..., x_n\)是自变量,\(\beta_0\)是截距,\(\beta_1, \beta_2, ..., \beta_n\)是对应于每个自变量的回归系数,而\(\epsilon\)是误差项。
### 2.1.2 损失函数的选择与优化目标
为了确定最佳的回归系数,我们需要定义一个损失函数,该函数量化了模型预测值与实际观测值之间的差异。最常见的损失函数是均方误差(MSE):
\[MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y_i})^2\]
在这里,\(y_i\)是实际值,\(\hat{y_i}\)是模型预测值,\(n\)是样本数量。优化目标就是最小化MSE,以便找到最佳的回归系数。
## 2.2 线性回归的Python实现
### 2.2.1 使用Scikit-learn进行线性回归
Python是一个极受欢迎的科学计算编程语言,其强大的库如Scikit-learn为实现线性回归提供了极大的便利。以下是一个使用Scikit-learn进行线性回归的示例代码。
```python
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
# 假设X为自变量数据集,y为目标变量数据集
X = ... # 使用实际数据替换
y = ... # 使用实际数据替换
# 拆分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型实例
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集数据
y_pred = model.predict(X_test)
# 计算模型在测试集上的均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"模型均方误差: {mse}")
```
### 2.2.2 模型评估与参数调优策略
评估线性回归模型的性能是至关重要的一步。常见的评估指标包括决定系数\(R^2\)、均方误差(MSE)、均方根误差(RMSE)等。参数调优则包括特征选择、模型正则化等策略。
```python
from sklearn.metrics import r2_score
# 计算决定系数
r2 = r2_score(y_test, y_pred)
print(f"模型决定系数: {r2}")
```
## 2.3 线性回归案例分析
### 2.3.1 实际数据集的处理流程
假设我们正在处理一个房地产价格预测的案例,我们的数据集包括房屋面积、卧室数量、建造年份等特征,目标是预测房屋的销售价格。以下是数据处理的步骤:
```python
import pandas as pd
# 加载数据集
data = pd.read_csv('housing_data.csv')
# 数据预处理:处理缺失值、异常值等
# ...
# 特征选择:选择对预测价格最相关的特征
# ...
# 特征工程:可能包括特征编码、标准化等
# ...
```
### 2.3.2 模型优化与结果解释
在模型优化过程中,我们可能会尝试多项式的特征以及正则化技术,如岭回归(Ridge Regression)和套索回归(Lasso Regression),以避免过拟合。同时,我们可以使用交叉验证等技术来评估模型的泛化能力。
```python
from sklearn.linear_model import Ridge, Lasso
from sklearn.model_selection import cross_val_score
# 尝试不同的正则化强度进行交叉验证
ridge = Ridge(alpha=1.0)
lasso = Lasso(alpha=0.1)
# 使用交叉验证评估模型
ridge_scores = cross_val_score(ridge, X, y, scoring='neg_mean_squared_error', cv=5)
lasso_scores = cross_val_score(lasso, X, y, scoring='neg_mean_squared_error', cv=5)
print(f"Ridge回归均方误差: {-np.mean(ridge_scores)}")
print(f"Lasso回归均方误差: {-np.mean(lasso_scores)}")
```
通过上述实践,我们可以对比不同模型的表现,挑选最优模型,并根据业务需求进行模型优化和解释。
# 3. 聚类算法的优化实践
聚类是一种无监督学习方法,通过将数据划分为不同的群体(或称为“簇”),以揭示数据中的隐藏结构。在本章中,我们将探讨聚类算法中的一个经典方法——K-means算法。我们会深入理解它的原理,并讨论在Python中如何实现它,以及如何通过案例分析来优化聚类结果。
## 3.1 K-means算法的理论基础
### 3.1.1 K-means聚类的原理及适用场景
K-means聚类算法是一种广泛使用的数据分割方

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为数据科学家和 Python 初学者提供全面的指南,帮助他们掌握数据科学工具包的安装和使用。专栏涵盖了从环境配置到数据挖掘的 20 个实用技巧,并深入探讨了 NumPy、Seaborn、SciPy、Pandas、NetworkX 和 Python 并行计算等关键工具包。此外,还提供了 5 个案例研究,展示了数据科学优化算法的实际应用。通过阅读本专栏,读者将获得在 Python 中有效处理和分析数据的必要知识和技能,从而提升他们的数据科学能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入解读NIST随机数测试标准:掌握随机性质量的关键与操作步骤

参考资源链接:[NIST随机数测试标准中文详解及16种检测方法](https://wenku.csdn.net/doc/1cxw8fybe9?spm=1055.2635.3001.10343)
# 1. 随机数生成器的重要性与应用
随机数生成
ATS2825实践指南:5个步骤教会你如何有效阅读技术数据手册

参考资源链接:[ATS2825:高集成蓝牙音频SoC解决方案](https://wenku.csdn.net/doc/6412b5cdbe7fbd1778d4471c?spm=1055.2635.3001.10343)
# 1. 理解技术数据手册的重要性
在技术行业,数据手册是连接工程师与产品之间的桥梁。技术数据手册详细记录了产品规格、性能参数及应用指南,是开发、维护
【图论与组合之美】:如何在复杂网络中运用组合数学(IT精英专属)
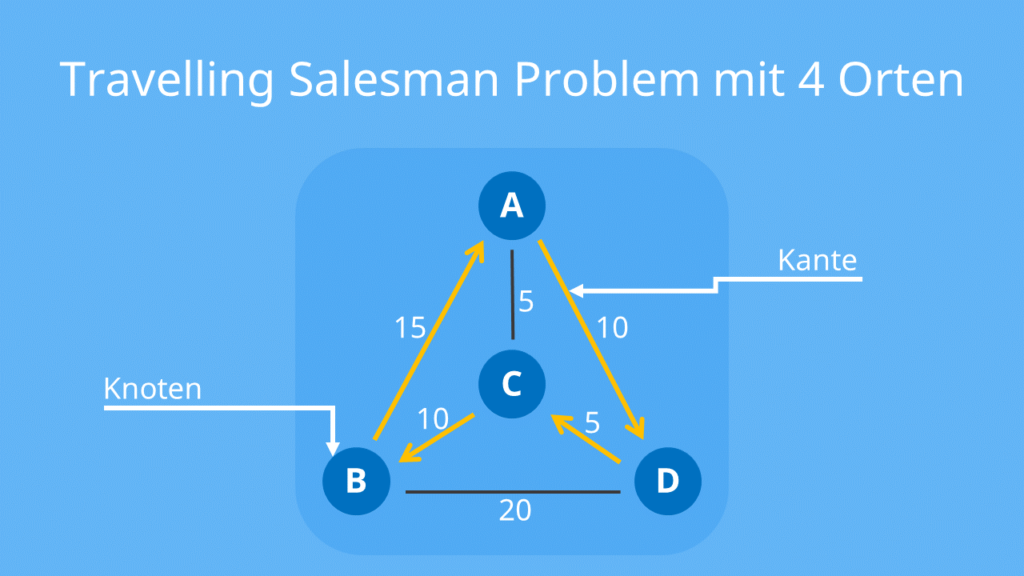
参考资源链接:[组合理论及其应用 李凡长 课后习题 答案](https://wenku.csdn.net/doc/646b0b685928463033e5bca7?spm=1055.2635.3001.10343)
# 1. 图论与组合数学基础
图论和组合数学是研究离散结构的数学分
立即掌握:HK4100F继电器驱动电路设计与优化技巧
参考资源链接:[hk4100f继电器引脚图及工作原理详解](https://wenku.csdn.net/doc/6401ad19cce7214c316ee482?spm=1055.2635.3001.10343)
# 1. HK4100F继电器驱动电路简介
继电器驱动电路是电子系统中重要的组件,负责控制继电器的动作,以实现电路的开关、转换、控制等功能。HK4100F是一种广泛应用于工业控制、家用电器、汽车电子等领域的高性能继电器。本文将首先对HK4100F继电器驱动电路进行简要介绍,阐述其基本功能和应用场景,为后续章节深入探讨其设计理论基础、电路设计实践、性能优化、自动化测试及创新应用奠定
【仿真分析新手上路】:电路设计仿真工具的必备技巧全攻略

参考资源链接:[大电容LDO中的Miller补偿:误区与深度解析](https://wenku.csdn.net/doc/1t74pjtw6m?spm=1055.2635.3001.10343)
# 1. 电路设计仿真工具概述
## 简介
在现代电子设计工程中,电路设计仿真工具扮演着至关重要的角色。它们不仅能够模拟实际电路在不同工作条件下的行为,而且能够帮助工程师在物理原型
【ISO 11898-1标准深度解析】:精通CAN通信协议的5大关键

参考资源链接:[ISO 11898-1 中文](https://wenku.csdn.net/doc/6412b72bbe7fbd1778d49563?spm=1055.2635.3001.10343)
# 1. CAN通信协议概述
## 1.1 CAN通信协议的诞生与应用领域
控制器局域网络(CAN)通信协议由德国Bosch公司于1980年代初期开发,最初用于汽车内部的微控制器和设备之间的通信
【高级故障排除】:Tc3卡壳卸载?专家级别的解决策略

参考资源链接:[TwinCAT 3软件卸载完全指南](https://wenku.csdn.net/doc/1qen88ydgt?spm=1055.2635.3001.10343)
# 1. Tc3卡故障排除概述
## 1.1 Tc3卡故障排除的重要性
在当今高度依赖技术的商业环境中,Tc3卡作为关键硬件组件,其稳定性和效率对整个系统的性能至关重要。当Tc3卡发生故障
【VPX硬件设计与实现秘籍】:遵循VITA 46-2007,打造高效嵌入式系统
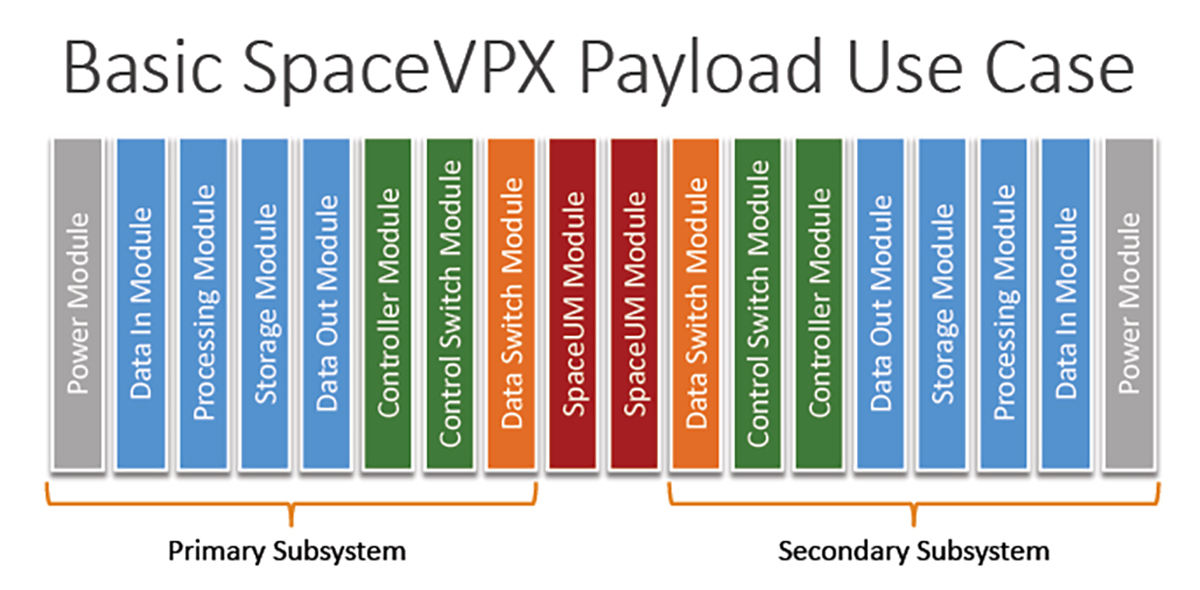
参考资源链接:[VPX基础规范(VITA 46-2007):VPX技术详解与标准入门](https://wenku.csdn.net/doc/6412b7abbe7fbd1778d4b1da?spm=1055.2635.3001.10343)
# 1. VPX技术标准概览
VPX,或VITA
PL_0编译器优化秘籍:技术细节与实践应用全面解读

参考资源链接:[PL/0编译程序研究与改进:深入理解编译原理和技术](https://wenku.csdn.net/doc/20is1b3xn1?spm=1055.2635.3001.10343)
# 1. PL_0编译器优化概述
## 1.1 什么是PL_0编译器优化
PL_0编译
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )