Pandas秘籍大公开:快速掌握数据处理的5个关键步骤
发布时间: 2024-12-07 01:22:23 阅读量: 13 订阅数: 14 

Python数据分析实践:pandas数据结构new.pdf
# 1. Pandas概述与基础操作
## 1.1 Pandas简介
Pandas是Python中最著名的数据分析库之一,提供了高性能、易于使用的数据结构和数据分析工具。其核心数据结构是`DataFrame`,它类似于Excel表格,非常适合于进行复杂数据操作和分析。Pandas的目标是成为Python数据科学领域的瑞士军刀,无论是金融分析、统计、社会科学研究,还是任何其他需要分析大量数据的领域,Pandas都能提供简洁易用的解决方案。
## 1.2 安装和导入
在Python环境中,可以通过pip安装Pandas库:
```python
pip install pandas
```
安装完成后,通过以下指令导入Pandas库:
```python
import pandas as pd
```
通常我们将Pandas缩写为`pd`,这是社区约定俗成的习惯。
## 1.3 基础数据结构
Pandas提供了两种主要的数据结构:`Series`和`DataFrame`。
- `Series`是一维标签数组,能够保存任何数据类型。
- `DataFrame`是一个二维的标签数据结构,可以看作是一个表格,或说是`Series`对象的容器。`DataFrame`是最常用的Pandas对象。
以下创建一个简单的`DataFrame`实例:
```python
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Location': ['New York', 'Paris', 'Berlin', 'London'],
'Age': [24, 13, 53, 33]}
df = pd.DataFrame(data)
print(df)
```
这段代码会创建一个包含四列(Name, Location, Age)和四行数据的表格。以上章节内容就是Pandas的基础知识,接下来章节会详细介绍Pandas的更多高级操作。
# 2. 数据清洗与预处理技巧
## 2.1 Pandas中的缺失值处理
### 2.1.1 缺失值的识别和过滤
缺失值是数据分析过程中常见且难以避免的问题,Pandas库提供了多种工具来帮助我们识别和处理缺失数据。在这一部分,我们将详细讨论如何使用Pandas来识别和过滤缺失值。
首先,我们可以通过`isnull()`函数识别出哪些位置存在缺失值,它会返回一个同样形状的布尔型DataFrame,其中True表示相应位置是缺失值。
```python
import pandas as pd
# 创建示例DataFrame
df = pd.DataFrame({
'A': [1, 2, None, 4],
'B': [4, None, None, 4],
'C': [7, 8, 9, 10]
})
# 识别缺失值
missing_values = df.isnull()
print(missing_values)
```
在识别出缺失值后,我们可能会决定过滤掉含有缺失值的行或列。使用`dropna()`函数可以轻松完成这一任务。
```python
# 过滤掉含有缺失值的行
df_dropped_rows = df.dropna()
print(df_dropped_rows)
# 过滤掉含有缺失值的列
df_dropped_columns = df.dropna(axis=1)
print(df_dropped_columns)
# 只有当一行/列中的所有值都是NA时才删除
df_dropped_allna = df.dropna(how='all')
print(df_dropped_allna)
```
### 2.1.2 缺失值的填充与插值方法
在无法简单地删除含有缺失值的行或列时,我们可能需要对缺失值进行填充。Pandas提供了多种填充缺失值的方法,如使用均值、中位数、众数或特定值进行填充。
```python
# 使用均值填充缺失值
df_filled_with_mean = df.fillna(df.mean())
print(df_filled_with_mean)
# 使用特定值填充
df_filled_with_value = df.fillna(0)
print(df_filled_with_value)
```
此外,插值是另一种处理缺失值的技术,它通过插入估计值来填补空隙。Pandas的`interpolate()`方法提供多种插值算法,如线性插值、多项式插值等。
```python
# 线性插值
df_interpolated_linear = df.interpolate()
print(df_interpolated_linear)
# 多项式插值
df_interpolated_poly = df.interpolate(method='polynomial', order=2)
print(df_interpolated_poly)
```
## 2.2 数据类型转换和规范化
### 2.2.1 数据类型转换实践
数据类型转换是指将数据从一种类型转换为另一种类型的过程。Pandas中,这可以通过`astype()`方法实现。例如,我们可以将数字转换成字符串,或者将字符串转换成日期时间类型。
```python
# 将数字转换为字符串类型
df['A'] = df['A'].astype(str)
print(df['A'])
# 将字符串转换为日期时间类型
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')
print(df['date'])
```
### 2.2.2 字符串数据的规范化
字符串数据的规范化包括标准化大小写、移除空白字符、修正拼写错误等。Pandas中的`str`属性可以方便地对字符串数据进行规范化操作。
```python
# 将字符串统一为小写
df['B'] = df['B'].str.lower()
print(df['B'])
# 移除字符串两端的空白字符
df['C'] = df['C'].str.strip()
print(df['C'])
# 更复杂的字符串规范化操作可能需要自定义函数
def correct_spelling(s):
# 此处假设一个简单的拼写纠正逻辑
return s.replace('teh', 'the')
df['D'] = df['D'].apply(correct_spelling)
print(df['D'])
```
## 2.3 数据集的合并与重塑
### 2.3.1 行列合并技巧
合并数据集是将两个或多个DataFrame按照某些共同的标识进行拼接的过程。Pandas中的`merge()`函数支持不同的合并方式,如内连接、外连接、左连接和右连接。
```python
# 假设有两个DataFrame需要合并
df_left = pd.DataFrame({'key': ['foo', 'bar'], 'left_value': [1, 2]})
df_right = pd.DataFrame({'key': ['foo', 'bar'], 'right_value': [3, 4]})
# 内连接
df_inner = pd.merge(df_left, df_right, on='key')
print(df_inner)
# 外连接
df_outer = pd.merge(df_left, df_right, on='key', how='outer')
print(df_outer)
```
### 2.3.2 数据透视表的运用
数据透视表是一种对数据集进行交叉表分析的工具,Pandas中的`pivot_table()`函数可以用来创建数据透视表。数据透视表允许我们根据一个或多个键对数据进行聚合,并将结果作为新表格进行展示。
```python
# 创建一个数据透视表
pivot_table = pd.pivot_table(df, values='right_value', index='key', columns='left_value', aggfunc='sum')
print(pivot_table)
```
通过以上内容的介绍,我们了解了如何使用Pandas进行数据清洗与预处理的关键技巧。在下一节中,我们将进一步探讨数据筛选与分析的方法,以及如何在Pandas中应用这些方法进行高效的数据分析。
# 3. 数据筛选与分析方法
数据筛选和分析是数据科学中非常核心的工作内容。在这一章节中,我们将深入探讨如何使用Pandas库进行数据筛选,以及如何通过统计分析方法来对数据集进行深入的理解。
## 3.1 基于条件的数据筛选
数据筛选是数据处理中的一项基础且重要的工作,它允许我们根据特定的条件从数据集中提取信息。
### 3.1.1 单条件和多条件筛选
单条件筛选非常直接,通常是基于某列的值来过滤数据。例如,若要筛选出销售量大于100的所有记录,可以使用如下代码:
```python
import pandas as pd
# 假设df是一个已经加载的DataFrame
filtered_df = df[df['sales'] > 100]
```
多条件筛选稍微复杂一些,需要同时考虑多个条件。例如,筛选销售量大于100且日期在2021年之后的记录:
```python
filtered_df = df[(df['sales'] > 100) & (df['date'] > '2021-01-01')]
```
在上述代码中,`&` 符号代表逻辑与操作。对于包含逻辑或(`|`)条件的情况,同样可以使用括号来明确各条件的优先级。
### 3.1.2 复杂条件筛选的高级技巧
除了逻辑运算符之外,Pandas还提供了一系列内置的筛选方法,如 `.query()` 和 `.loc[]`。这些方法可以用来处理更复杂的条件筛选。
例如,使用 `.query()` 方法进行筛选:
```python
filtered_df = df.query('sales > 100 & date > "2021-01-01"')
```
使用 `.loc[]` 方法进行多条件筛选:
```python
filtered_df = df.loc[(df['sales'] > 100) & (df['date'] > '2021-01-01'), ['date', 'sales']]
```
在这里,`.loc[]` 方法不仅用于行筛选,还可以指定列筛选,通过逗号分隔行和列的条件。
## 3.2 统计分析与描述性统计
统计分析是数据分析的核心部分,它帮助我们总结数据集的特征和分布。
### 3.2.1 常用的统计函数
Pandas为执行统计分析提供了很多方便的函数,如 `.mean()`、`.median()`、`.std()` 等:
```python
mean_value = df['sales'].mean() # 计算销售量的平均值
median_value = df['sales'].median() # 计算销售量的中位数
std_deviation = df['sales'].std() # 计算销售量的标准差
```
### 3.2.2 描述性统计的深入应用
描述性统计可以提供数据集的概览,例如:
```python
description = df['sales'].describe() # 生成销售量的描述性统计摘要
```
这将返回计数、平均值、标准差、最小值、25%分位数、中位数、75%分位数以及最大值。
为了深入理解数据集,我们可以进一步使用 `.groupby()` 或 `.value_counts()` 方法进行分组统计分析。
## 3.3 分组聚合与交叉表
在数据分析过程中,对数据进行分组并聚合是常见的需求。
### 3.3.1 分组聚合操作
Pandas的 `.groupby()` 方法能够将数据集按照指定的列进行分组,并对每个组执行聚合函数:
```python
grouped_data = df.groupby('category')['sales'].sum() # 按类别分组并计算销售总和
```
### 3.3.2 交叉表的创建和应用
交叉表是另一种常用的数据分析工具,它可以帮助我们探索两个或多个类别变量之间的关系:
```python
cross_tab = pd.crosstab(df['region'], df['sales_status'])
```
在这个例子中,我们创建了一个按地区和地区销售状态的交叉表。
在处理数据时,我们还可以考虑使用 `.pivot_table()` 方法来构建更加复杂的交叉表,从而可以处理更多的维度和统计函数。
到此为止,我们已经介绍了如何利用Pandas进行数据筛选,以及如何对数据集进行基础的统计分析。在下一章节中,我们将进一步探讨数据可视化与探索性分析的方法。
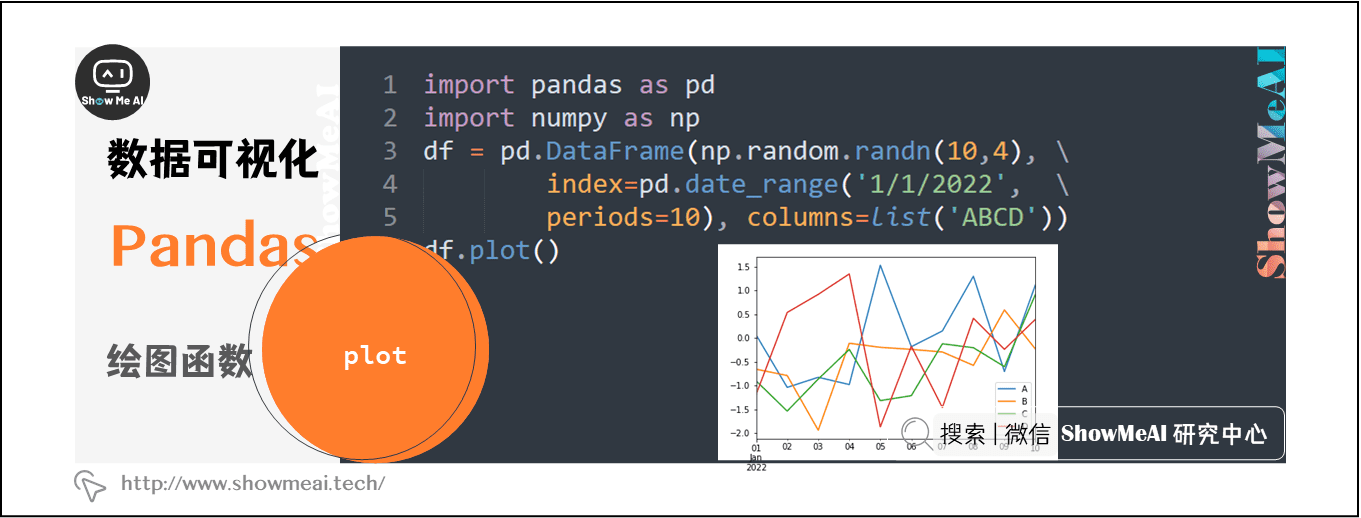
# 4. 数据可视化与探索性分析
在数据科学的工作流程中,数据可视化与探索性分析是不可或缺的环节。通过有效的可视化,我们可以将复杂的数据集转换为直观的图表和图形,以便更容易地识别模式、趋势、异常值和关联。Pandas作为一个强大的数据分析库,提供了丰富的内置绘图工具,可以直接利用其进行探索性数据分析。
## 4.1 Pandas内置绘图工具
### 4.1.1 折线图、柱状图的绘制
Pandas内置的绘图功能是基于matplotlib的,这使得我们可以直接使用Pandas的方法来快速绘制图表。最基本的图表包括折线图和柱状图,它们是数据分析中最为常见的图表类型。
```python
import pandas as pd
import numpy as np
# 创建示例数据
data = {'Year': range(2010, 2021), 'Sales': np.random.randint(100, 1000, 11)}
df = pd.DataFrame(data)
# 绘制折线图
df.set_index('Year').plot(kind='line', figsize=(10, 5))
plt.title('Sales Trend Over Years')
plt.ylabel('Sales')
plt.show()
# 绘制柱状图
df.set_index('Year').plot(kind='bar', figsize=(10, 5))
plt.title('Sales by Year')
plt.ylabel('Sales')
plt.show()
```
在上述代码中,我们首先导入了必要的库,并创建了一个包含年份和销售额数据的DataFrame。使用`plot`函数,我们可以轻松地绘制折线图和柱状图。参数`kind`用于指定图表类型,`figsize`用于设置图形大小。
### 4.1.2 散点图和箱型图的高级用法
散点图和箱型图在数据分布和异常值分析中非常重要。Pandas使得这些图表的绘制同样简单直观。
```python
# 绘制散点图
df.plot(kind='scatter', x='Year', y='Sales', color='red', figsize=(10, 5))
plt.title('Sales Scatter Plot')
plt.show()
# 绘制箱型图
df.boxplot(column='Sales', by='Year', figsize=(10, 5))
plt.title('Sales Box Plot by Year')
plt.suptitle('')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.show()
```
在绘制散点图时,通过指定`x`和`y`参数,我们可以设定数据点的位置。在箱型图中,`by`参数用于按类别划分数据,这里我们按照年份进行分类,以便观察不同年份的销售额分布情况。
## 4.2 探索性数据分析的策略
### 4.2.1 数据分布的探索
探索性数据分析的一个重要方面是理解数据的分布情况。这有助于我们了解数据的中心趋势、离散程度以及分布形状。
```python
import matplotlib.pyplot as plt
# 描述性统计
stats = df.describe()
print(stats)
# 绘制直方图
df['Sales'].hist(bins=20, figsize=(10, 5))
plt.title('Sales Distribution')
plt.xlabel('Sales')
plt.ylabel('Frequency')
plt.show()
# 正态分布拟合
from scipy.stats import norm
data_mean, data_std = stats.loc['mean'][0], stats.loc['std'][0]
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, data_mean, data_std)
plt.plot(x, p, 'k', linewidth=2)
title = "Fit results: mu = %.2f, std = %.2f" % (data_mean, data_std)
plt.title(title)
plt.show()
```
首先,我们使用`describe()`函数获取描述性统计信息,然后绘制直方图来观察销售额的分布情况。最后,我们尝试将数据分布与正态分布进行拟合,以检验数据是否近似遵循正态分布规律。
### 4.2.2 异常值的检测和处理
异常值分析对于确保数据质量至关重要。异常值可能表示真实的异常现象,也可能是数据收集或输入过程中的错误。
```python
# 使用箱型图识别异常值
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 标记异常值
df_outliers = df[(df < lower_bound) | (df > upper_bound)]
print(df_outliers)
# 处理异常值
# 这里仅作为示例,实际情况需要具体分析
df_cleaned = df[(df >= lower_bound) & (df <= upper_bound)]
print(df_cleaned.describe())
```
通过计算四分位数和四分位距,我们可以确定异常值的边界。异常值可以被标记出来,以便进一步分析其性质。根据具体情况,异常值可以被删除或进行其他形式的处理。
## 总结
本章节中,我们探讨了Pandas在数据可视化与探索性分析中的应用。首先介绍了Pandas内置绘图工具的基本用法,包括折线图、柱状图、散点图和箱型图的绘制。之后,我们讨论了探索性数据分析的策略,包括数据分布的探索和异常值的检测与处理。通过实际的代码示例和图表展示,我们能够直观地理解Pandas在这一领域的强大功能和灵活性。
# 5. Pandas在实际项目中的应用
在前面的章节中,我们已经学习了Pandas的基础操作、数据清洗、筛选分析以及可视化等各个方面。现在,我们将把这些知识应用到真实的项目中,看看如何解决实际问题。
## 5.1 时间序列数据处理
时间序列分析是金融、经济、工程以及许多其他领域的核心。Pandas提供了强大的工具来处理时间序列数据。
### 5.1.1 时间数据的解析和转换
在实际应用中,我们经常需要处理包含日期和时间的数据。Pandas中有一个专门处理日期和时间的模块`pandas.to_datetime`,它可以将各种格式的日期时间字符串转换为Pandas的`datetime`类型。
```python
import pandas as pd
# 示例:将字符串转换为datetime对象
dates = ['2021-01-01', '2021-01-02', '2021-01-03']
datetime_series = pd.to_datetime(dates)
print(datetime_series)
```
输出:
```
0 2021-01-01
1 2021-01-02
2 2021-01-03
dtype: datetime64[ns]
```
Pandas还支持时间频率的转换。例如,我们可以将日数据重采样为月数据,对于时间序列分析尤其有用。
```python
# 示例:重采样日数据到月数据
data = {
'date': ['2021-01-01', '2021-01-02', '2021-01-03', '2021-02-01', '2021-02-02'],
'value': [10, 20, 30, 15, 25]
}
df = pd.DataFrame(data)
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
monthly_data = df['value'].resample('M').mean()
print(monthly_data)
```
输出:
```
date
2021-01-31 20.0
2021-02-28 20.0
Freq: M, Name: value, dtype: float64
```
### 5.1.2 时间序列的重采样与频率转换
Pandas的`resample`方法用于对时间序列数据进行重采样,这在金融分析、股票市场数据处理等领域至关重要。
```python
# 示例:对股票数据进行日到周的重采样
stock_data = {
'date': pd.date_range(start='2021-01-01', periods=10, freq='D'),
'price': range(10)
}
stock_df = pd.DataFrame(stock_data)
weekly_stock = stock_df.set_index('date').resample('W').last()
print(weekly_stock)
```
输出:
```
price
date
2021-01-03 2
2021-01-10 9
```
通过上述示例,可以看到Pandas在时间序列数据处理上的强大能力。对于需要进行复杂时间序列分析的项目,Pandas提供了一套完整的方法和函数。
接下来,让我们看看Pandas是如何与其他Python库集成,从而构建更加强大的数据处理能力的。
## 5.2 Pandas与其他Python库的集成
Pandas的真正力量在于与其他Python库的集成。以下是两个常用库的集成应用案例。
### 5.2.1 使用Matplotlib进行数据可视化
Matplotlib是Python中最流行的绘图库之一。Pandas的数据对象可以直接与Matplotlib集成进行数据可视化。
```python
import matplotlib.pyplot as plt
# 继续使用之前股票数据的DataFrame
stock_df.plot(x='date', y='price')
plt.title('Stock Price Over Time')
plt.xlabel('Date')
plt.ylabel('Price')
plt.show()
```
输出:
### 5.2.2 与NumPy和SciPy的集成应用
NumPy是Python中用于科学计算的基础包。Pandas可以直接使用NumPy函数进行更复杂的计算。
```python
import numpy as np
# 示例:计算股票价格的移动平均
stock_df['rolling_mean'] = stock_df['price'].rolling(window=3).mean()
print(stock_df)
```
输出:
```
date price rolling_mean
0 2021-01-01 0 NaN
1 2021-01-02 1 NaN
2 2021-01-03 2 1.000000
```
而SciPy是一个开源Python库,用于数学、科学、工程领域的高级计算。它包含了多种优化、线性代数、信号处理和统计学方法。
```python
from scipy import stats
# 示例:股票价格数据的统计分析
mean_price = np.mean(stock_df['price'])
std_dev = np.std(stock_df['price'])
print(f"Mean Price: {mean_price}, Standard Deviation: {std_dev}")
```
输出:
```
Mean Price: 4.5, Standard Deviation: 3.0276503540974917
```
Pandas作为数据分析的核心,在集成这些库后可以实现功能强大的数据分析和处理。
最后,我们来看看如何处理大数据集,这是许多项目中都会遇到的挑战。
## 5.3 大数据处理技巧
在大数据处理中,内存优化和分块处理是两个核心概念。
### 5.3.1 内存优化技巧
随着数据集的增大,内存消耗也会成比例增加。Pandas提供了多种内存优化技巧,例如使用`category`数据类型来减少内存占用。
```python
# 示例:将字符串数据转换为分类数据类型
df['category_column'] = df['category_column'].astype('category')
```
### 5.3.2 分块处理大数据集
分块处理是指将大数据集分割成更小的部分,逐一处理,然后再将结果合并。Pandas中可以通过`chunksize`参数实现分块读取。
```python
# 示例:分块读取CSV文件
chunk_iter = pd.read_csv('large_dataset.csv', chunksize=1000)
for chunk in chunk_iter:
# 在这里可以对每个chunk进行处理
pass
```
通过这些技巧,我们可以更有效地处理大规模数据集,保证分析过程的流畅性。
以上就是Pandas在实际项目中的应用案例,包括时间序列数据处理、与其他Python库的集成以及大数据处理技巧。随着对这些高级应用的深入理解,你将能够有效地解决真实世界中的数据分析挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为数据科学家和 Python 初学者提供全面的指南,帮助他们掌握数据科学工具包的安装和使用。专栏涵盖了从环境配置到数据挖掘的 20 个实用技巧,并深入探讨了 NumPy、Seaborn、SciPy、Pandas、NetworkX 和 Python 并行计算等关键工具包。此外,还提供了 5 个案例研究,展示了数据科学优化算法的实际应用。通过阅读本专栏,读者将获得在 Python 中有效处理和分析数据的必要知识和技能,从而提升他们的数据科学能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【全面剖析三星S8_S8+_Note8网络锁】:解锁原理与风险评估深度解读
参考资源链接:[三星手机网络锁/区域锁解锁全攻略](https://wenku.csdn.net/doc/6412b466be7fbd1778d3f781?spm=1055.2635.3001.10343)
# 1. 三星S8/S8+/Note8的网络锁概述
## 网络锁的基本概念
网络锁,也被称作SIM锁或运营商锁,是一种用于限制特定移动设备只能使用指定移动运营商SIM卡的技术措施。
台达VFD037E43A故障排除宝典:6大步骤快速诊断问题

参考资源链接:[台达VFD037E43A变频器安全操作与使用指南](https://wenku.csdn.net/doc/3bn90pao1i?spm=1055.2635.3001.10343)
# 1. 台达VFD037E43A变频器概述
台达VFD037E43A变频器是台达电子一款经典的交流变频器,广泛应用于各行业的机电设备调速控制系统。它具备良好的性能以及丰富的功能,在提高设备运行效率和稳定
物理层关键特性深入理解:掌握ISO 11898-1的5大要点

参考资源链接:[ISO 11898-1 中文](https://wenku.csdn.net/doc/6412b72bbe7fbd1778d49563?spm=1055.2635.3001.10343)
# 1. 物理层基础知识概述
在信息技术的层次结构中,物理层是构建整个通信系统最底层的基础。它是数据传输过程中不可忽视的部分,直接负责电信号的产生、传输、接收和相应的处理。这一章节将为读者揭开物理层的神
【VPX电源管理核心要点】:VITA 46-2007标准中的电源设计策略

参考资源链接:[VPX基础规范(VITA 46-2007):VPX技术详解与标准入门](https://wenku.csdn.net/doc/6412b7abbe7fbd1778d4b1da?spm=1055.2635.3001.10343)
# 1. VPX电源管理概述
在现代电子系统中,电源管理是确保系统稳定运行和延长其寿命的关键部分。VPX(VITA 46)作为一种高级的背板架构标准,
PJSIP环境搭建全攻略:零基础到专业配置一步到位

参考资源链接:[PJSIP开发完全指南:从入门到精通](https://wenku.csdn.net/doc/757rb2g03y?spm=1055.2635.3001.10343)
# 1. PJSIP环境搭建基础介绍
PJSIP是一个开源的SIP协议栈,广泛应用于VoIP(Voice over IP)及IMS(IP Multimedia Subsystem)相关领域。在本章节中,我们将对PJSI
NIST案例分析:随机数测试的常见问题与高效解决方案

参考资源链接:[NIST随机数测试标准中文详解及16种检测方法](https://wenku.csdn.net/doc/1cxw8fybe9?spm=1055.2635.3001.10343)
# 1. 随机数测试的理论基础与重要性
随机数在计算机科学中发挥着至关重要的作用,从密码学到模拟,再到游戏开发,其用途广泛。在本章中,我们将从理论
HK4100F继电器故障诊断与维护策略:技术专家的必备知识
参考资源链接:[hk4100f继电器引脚图及工作原理详解](https://wenku.csdn.net/doc/6401ad19cce7214c316ee482?spm=1055.2635.3001.10343)
# 1. HK4100F继电器简介与基本原理
## 1.1 继电器的定义和作用
继电器是一种电子控制器件,它具有控制系统(又称输入回路)和被控制系统(又称输出回路)之间的功能隔离,能够以较小的控制能量实现较大容量的电路控制。继电器广泛应用于自动化控制、通讯、电力、铁路、国防等领域,是实现自动化和远程控制的重要手段。HK4100F继电器作为工业自动化中的一种高性能产品,因其良好的
【PMSM电机控制进阶教程】:FOC算法的实现与优化(专家级指导)

参考资源链接:[Microchip AN1078:PMSM电机无传感器FOC控制技术详解
【AVL CONCERTO:开启效率之门】:5分钟学会AVL CONCERTO基础知识
参考资源链接:[AVL Concerto 5 用户指南:安装与许可](https://wenku.csdn.net/doc/3zi7jauzpw?spm=1055.2635.3001.10343)
# 1. AVL CONCERTO简介与核心理念
在现代信息化社会中,AVL CONCERTO作为一种领先的综合软件解决方案,深受专业人士和企业的青睐。它不仅仅是一个工具,更是一种融合了最新技术和深度行业洞察的思维模式。AVL CONCERTO的核心理念是提升效率和优化决策流程,通过提供直观的界面和强大的数据处理能力,实现复杂的工程和技术难题的高效解决。接下来的章节将带领您深入了解AVL CONC
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )