MongoDB数据库与Node.js的集成:数据存储和管理实战
发布时间: 2024-01-10 06:21:09 阅读量: 56 订阅数: 23 
# 1. 简介
## 介绍MongoDB和Node.js的基本概念和原理
MongoDB是一个开源的、面向文档的NoSQL数据库,它将数据存储在类似JSON的文档中,并且支持丰富的查询和索引功能。通过使用MongoDB,我们可以方便地存储、查询和管理大量的非结构化数据。
Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它非常适用于构建高性能、可扩展的网络应用程序。通过使用Node.js,我们可以快速搭建服务器端的应用程序,并与MongoDB进行数据交互。
在集成MongoDB和Node.js之前,我们需要先了解它们的基本概念和原理。MongoDB使用集合(Collection)来存储文档(Document),每个文档类似于关系数据库中的一行记录。Node.js则使用JavaScript语言来编写服务器端的代码,它支持异步非阻塞的I/O操作,可以高效地处理大量并发请求。
## 解释为什么选择MongoDB作为数据库
在选择数据库时,我们需要考虑多个因素,包括数据模型、性能、可扩展性和开发效率等。MongoDB作为一种NoSQL数据库,具有以下几个优势:
1. 灵活的数据模型:MongoDB的文档模型非常灵活,可以存储非结构化或半结构化的数据。这种灵活性使得我们可以快速地修改和扩展数据模型,而无需进行数据库迁移或模式更改。
2. 高性能和可扩展性:MongoDB 使用BSON(Binary JSON)格式存储数据,读写速度非常快。此外,MongoDB支持水平扩展,可以通过添加更多的服务器节点来提高性能和容量。
3. 强大的查询功能:MongoDB提供丰富的查询功能,包括复杂的条件查询、范围查询、全文搜索和地理位置查询等。同时,MongoDB还支持数据的聚合计算、数据分析和MapReduce等高级操作。
4. 易于使用和学习:对于熟悉JavaScript的开发者来说,学习和使用MongoDB非常容易。MongoDB的驱动程序和工具支持多种编程语言,包括JavaScript、Python、Java等,使得开发人员可以使用自己熟悉的语言与数据库进行交互。
综上所述,MongoDB的灵活性、性能和易用性使得它成为与Node.js集成的理想选择。在接下来的章节中,我们将学习如何在Node.js中使用MongoDB进行数据存储和管理。
# 2. 安装和配置MongoDB与Node.js
### 2.1 安装MongoDB数据库和Node.js开发环境
在开始使用MongoDB和Node.js集成之前,我们首先需要安装和配置它们的开发环境。下面是安装MongoDB和Node.js的步骤:
#### 2.1.1 安装MongoDB数据库
1. 访问MongoDB官方网站(https://www.mongodb.com/)下载对应操作系统的安装包。
2. 安装MongoDB,根据操作系统进行相应的安装步骤。
3. 配置MongoDB的环境变量PATH,以便在命令行中能够直接访问MongoDB的命令。
#### 2.1.2 安装Node.js
1. 访问Node.js官方网站(https://nodejs.org/)下载对应操作系统的安装包。
2. 安装Node.js,根据操作系统进行相应的安装步骤。
3. 验证Node.js安装是否成功,打开命令行,运行以下命令:
```shell
node -v
npm -v
```
如果正确显示Node.js和npm的版本号,则说明安装成功。
### 2.2 配置MongoDB和Node.js的连接
MongoDB和Node.js的连接需要使用到Node.js的驱动程序。在本文中,我们将使用Mongoose作为Node.js驱动程序来连接MongoDB数据库。下面是配置MongoDB和Node.js连接的步骤:
1. 在项目中安装Mongoose,执行以下命令:
```shell
npm install mongoose
```
2. 在Node.js代码中引入Mongoose模块,创建MongoDB连接。示例代码如下:
```javascript
const mongoose = require('mongoose');
// 创建MongoDB连接
mongoose.connect('mongodb://localhost/mydatabase', { useNewUrlParser: true, useUnifiedTopology: true });
// 获取MongoDB连接对象
const db = mongoose.connection;
// 连接成功回调
db.on('connected', () => {
console.log('MongoDB连接成功');
});
// 连接失败回调
db.on('error', (err) => {
console.error('MongoDB连接失败', err);
});
// 断开连接回调
db.on('disconnected', () => {
console.log('MongoDB连接断开');
});
```
上述代码中,我们首先引入了Mongoose模块,然后使用`mongoose.connect()`方法来创建MongoDB连接。其中,`mongodb://localhost/mydatabase`是MongoDB的连接字符串,`mydatabase`是要连接的数据库名称。在连接成功、失败或断开时,分别会触发对应的回调函数。
至此,我们已经完成了MongoDB和Node.js的安装和配置工作。下一章节将会介绍如何进行CRUD操作,即数据的创建、读取、更新和删除。
**总结**
本章介绍了安装和配置MongoDB和Node.js的开发环境的步骤。我们通过安装MongoDB数据库和Node.js,配置环境变量并验证安装结果。然后,我们使用Mongoose作为Node.js的驱动程序,创建了MongoDB的连接。在接下来的章节中,我们将使用这个连接进行数据操作。
# 3. 读取、更新和删除数据
在本章节中,我们将使用Node.js进行MongoDB的增删改查操作。首先我们需要确保已经安装和配置好了MongoDB和Node.js的环境,然后我们将演示如何在MongoDB中进行数据的创建、读取、更新和删除操作。
#### 3.1 使用Node.js进行数据的增删改查操作
首先,我们需要在Node.js中安装MongoDB的驱动程序,通常我们会使用 `mongodb` 包作为MongoDB的官方驱动。安装方法如下:
```javascript
// 在命令行中执行以下命令安装mongodb包
npm install mongodb
```
接下来,我们演示如何在Node.js中进行数据的增删改查操作:
```javascript
// 引入MongoDB的驱动程序
const MongoClient = require('mongodb').MongoClient;
// 数据库连接的URL
const url = 'mongodb://localhost:27017';
// 数据库名称
const dbName = 'myproject';
// 创建新数据
async function createData() {
const client = new MongoClient(url, { useUnifiedTopology: true });
try {
await client.connect();
const db = client.db(dbName);
const collection = db.collection('documents');
// 插入单个文档
const result = await collection.insertOne({ name: 'Alice', age: 30 });
console.log('Inserted document with _id:', result.insertedId);
} finally {
await client.close();
}
}
// 读取数据
async function readData() {
const client = new MongoClient(url, { useUnifiedTopology: true });
try {
await client.connect();
const db = client.db(dbName);
const collection = db.collection('documents');
// 查询所有文档
const cursor = collection.find({});
await cursor.forEach(console.log);
} finally {
await client.close();
}
}
// 更新数据
async function updateData() {
const client = new MongoClient(url, { useUnifiedTopology: true });
try {
await client.connect();
const db = client.db(dbName);
const collection = db.collection('documents');
// 更新匹配的第一个文档
const result = await collection.updateOne({ name: 'Alice' }, { $set: { age: 35 } });
console.log('Updated', result.modifiedCount, 'document');
} finally {
await client.close();
}
}
// 删除数据
async function deleteData() {
const client = new MongoClient(url, { useUnifiedTopology: true });
try {
await client.connect();
const db = client.db(dbName);
const collection = db.collection('documents');
// 删除匹配的第一个文档
const result = await collection.deleteOne({ name: 'Alice' });
console.log('Deleted', result.deletedCount, 'document');
} finally {
await client.close();
}
}
// 调用各个操作函数
createData();
readData();
updateData();
deleteData();
```
在上述代码示例中,我们通过使用 `mongodb` 包中的 `MongoClient` 类来连接MongoDB数据库,并分别演示了创建数据、读取数据、更新数据和删除数据的操作。
#### 3.2 演示如何在MongoDB中创建、读取、更新和删除数据
除了在Node.js中进行操作,我们也可以通过MongoDB的命令行或图形化界面工具来对数据进行增删改查操作。下面是一些常用的MongoDB shell命令示例:
- 创建数据:
```javascript
db.collectionName.insert({ key1: value1, key2: value2 })
```
- 读取数据:
```javascript
db.collectionName.find({ key: value })
```
- 更新数据:
```javascript
db.collectionName.update({ key: value }, { $set: { newKey: newValue } })
```
- 删除数据:
```javascript
db.collectionName.remove({ key: value })
```
通过上述示例,我们可以在MongoDB的命令行中进行简单的增删改查操作。
至此,我们已经演示了在Node.js中使用MongoDB进行数据的增删改查操作,并介绍了在MongoDB中使用命令行进行相同操作的方法。在下一节,我们将继续讨论关于数据模型设计和数据验证的内容。
# 4. 数据模型设计与数据验证
在使用MongoDB进行数据库开发时,良好的数据模型设计和数据验证是至关重要的。本章将介绍MongoDB数据模型设计的原则和技巧,并讲解如何使用Mongoose进行数据验证。
### 4.1 数据模型设计原则
在设计MongoDB数据库的数据模型时,需要考虑以下几个原则:
1. 优化查询性能:根据应用的需求和常见的查询操作,设计合适的数据结构和索引,以提高查询性能。
2. 避免重复数据:避免在一个集合中存储大量重复的数据,可以通过引用其他集合的方式来解决。
3. 嵌入与引用的选择:根据数据之间的关系和查询的频率,选择嵌入或引用其他文档。
4. 适当使用子文档:对于复杂的数据结构,可以使用子文档来组织数据,使数据更加清晰和易操作。
5. 可扩展性考虑:在设计数据模型时,要考虑到数据的增长和系统的扩展,以便后续的维护和升级。
6. 数据安全性:根据应用的安全需求,设计合适的权限控制和数据加密策略,保护数据的安全性。
### 4.2 使用Mongoose进行数据验证
Mongoose是一个优秀的MongoDB对象建模工具,它提供了强大的数据验证功能。下面我们将演示如何使用Mongoose进行数据验证。
首先,我们需要安装Mongoose模块:
```js
npm install mongoose
```
接下来,创建一个model模型并定义验证规则。例如,我们创建一个User模型,并设置username和password字段的验证规则:
```js
const mongoose = require('mongoose');
// 连接数据库
mongoose.connect('mongodb://localhost/test');
// 定义User模型
const UserSchema = new mongoose.Schema({
username: {
type: String,
required: true,
unique: true
},
password: {
type: String,
required: true,
minlength: 6
}
});
const User = mongoose.model('User', UserSchema);
```
以上代码中,我们使用`required: true`定义了username和password字段是必填字段,使用`unique: true`定义了username字段是唯一的。另外,使用`minlength: 6`定义了password字段的最小长度为6个字符。
接下来,我们可以使用User模型来创建新用户,并进行数据验证:
```js
const newUser = new User({
username: 'johndoe',
password: 'password'
});
newUser.save((err) => {
if (err) {
console.error(err.message);
} else {
console.log('User created successfully');
}
});
```
在以上代码中,我们创建了一个新用户,并使用`save`方法保存到数据库中。如果数据验证失败,Mongoose会返回一个错误对象`err`,我们可以从中获取错误信息并进行相应的处理。
另外,我们还可以通过调用`validate`方法手动进行数据验证:
```js
newUser.validate((err) => {
if (err) {
console.error(err.message);
} else {
console.log('Data is valid');
}
});
```
通过调用`validate`方法,Mongoose会检查数据是否符合模型定义的验证规则,并返回相应的错误信息。
综上所述,数据模型设计和数据验证是MongoDB开发中的重要环节。合理的数据模型设计能够提高查询性能和数据存储效率,而数据验证能够保证数据的完整性和安全性。使用Mongoose进行数据验证可以简化开发过程,提高代码的可维护性和可读性。
#### 代码总结
本节中,我们介绍了MongoDB数据模型设计的原则和技巧,以及如何使用Mongoose进行数据验证。通过良好的数据模型设计和数据验证,我们可以提高应用的性能和安全性。
#### 结果说明
在使用Mongoose进行数据验证时,如果数据不符合模型定义的验证规则,Mongoose会返回相应的错误信息。我们可以根据错误信息来调整数据或验证规则,以保证数据的完整性和合法性。如果数据验证通过,Mongoose会将数据保存到MongoDB数据库中。
# 5. 数据索引与查询优化
MongoDB中的索引是一种用于加快查询速度的数据结构。在本章中,我们将介绍MongoDB索引的概念和作用,并指导如何创建和优化索引以提高查询性能。
#### 5.1 索引的概念和作用
索引是数据库中用于快速查找数据的一种数据结构。它类似于一本书的目录,可以根据关键字快速定位到相关的数据。
MongoDB中的索引可以大大提高查询的性能,尤其是在处理大量数据时。它可以帮助MongoDB避免扫描整个集合来查找匹配的文档,而是直接根据索引的信息定位到符合条件的文档。
#### 5.2 创建索引
在MongoDB中,可以使用`createIndex()`方法来创建索引。该方法接收一个包含索引字段和排序方式的对象作为参数。
```javascript
// 创建一个名为name的升序索引
db.collection.createIndex({ name: 1 });
// 创建一个名为age的降序索引
db.collection.createIndex({ age: -1 });
```
#### 5.3 查询优化
除了创建索引,还可以通过其他方法来优化查询性能。
##### 5.3.1 查询条件优化
在查询数据时,尽量避免使用全局匹配符号(如`$regex`)以及复杂的查询条件(如多层嵌套的条件)。这样可以减少查询的复杂度,提高查询速度。
##### 5.3.2 使用`explain()`方法分析查询
MongoDB提供了`explain()`方法,可以用于分析查询的执行计划和性能。
```javascript
// 分析查询的执行计划
db.collection.find({ name: 'Tom' }).explain();
```
##### 5.3.3 数量限制和分页查询
在进行查询时,可以通过`limit()`方法限制返回的文档数量,以及使用`skip()`方法实现分页查询。
```javascript
// 返回前10条文档
db.collection.find().limit(10);
// 跳过前10条文档,返回后面的10条文档
db.collection.find().skip(10).limit(10);
```
#### 5.4 索引优化
为了进一步优化查询性能,可以对索引进行优化。
##### 5.4.1 索引字段选择
选择适合查询的索引字段是提高查询性能的关键。通常情况下,选择具有高选择性和频繁查询的字段作为索引字段。
##### 5.4.2 复合索引
复合索引是由多个字段组成的索引,可以提高查询的效率。
```javascript
// 创建一个由name和age字段组成的复合索引
db.collection.createIndex({ name: 1, age: 1 });
```
##### 5.4.3 索引覆盖
索引覆盖是指查询只需要读取索引而不需要访问实际的文档数据。如果索引覆盖能满足查询需求,可以大大提高查询性能。
#### 5.5 总结
本章介绍了MongoDB索引的概念和作用,并指导了如何创建和优化索引以提高查询性能。在设计数据模型时,需要根据查询需求选择合适的索引字段,并合理使用索引来优化查询。同时,还可以通过优化查询条件、使用`explain()`方法分析查询执行计划、限制返回文档数量和使用分页查询等方法来提高查询性能。索引的选择和优化是MongoDB与Node.js集成中的重要主题,值得开发人员深入学习和实践。
# 6. 高级主题和最佳实践
在本章中,我们将探讨一些与MongoDB数据库和Node.js集成相关的高级主题和最佳实践。这些主题包括数据分片、复制和故障恢复的方法,以及一些关于MongoDB与Node.js集成的注意事项。
### 6.1 数据分片
数据分片是将数据分割成多个分片(shard)存储在不同的机器上的过程。数据分片可以提高数据库的横向扩展性和性能。以下是在MongoDB中进行数据分片的一般步骤:
1. 安装和配置MongoDB分片集群。启动配置服务器和多个分片服务器。
2. 创建分片键。分片键决定了数据将如何在各个分片之间分布。选择一个合适的分片键对于数据均衡和性能至关重要。
3. 启用分片。使用`sh.enableSharding(dbName)`命令启用分片,其中`dbName`是要启用分片的数据库名称。
4. 选择一个集合进行分片。使用`sh.shardCollection("dbName.collectionName", { shardKey })`命令选择一个集合进行分片,其中`dbName.collectionName`是要分片的集合名称,`shardKey`是用作分片键的字段。
5. 监控和管理分片。使用`sh.status()`命令可以查看分片集群的状态,使用`sh.addShard()`命令可以添加新的分片。
### 6.2 数据复制
数据复制是将数据在多个副本集上进行同步的过程。数据复制提高了数据的可用性和可靠性,并且允许在主节点故障时自动切换到备用节点上。以下是在MongoDB中进行数据复制的一般步骤:
1. 配置复制集。启动多个MongoDB节点,并将其中一个节点配置为主节点,其他节点配置为从节点。
2. 初始化复制集。在主节点上运行`rs.initiate()`命令来初始化复制集。
3. 添加从节点。在主节点上运行`rs.add("hostname:port")`命令来添加从节点。
4. 监控复制集状态。使用`rs.status()`命令可以查看复制集的状态,包括主节点和从节点的连接状态和同步状态。
5. 处理主节点故障。当主节点故障时,从节点会发起选举以选择新的主节点。
### 6.3 故障恢复
故障恢复是在数据库遇到故障或错误时进行修复和恢复的过程。MongoDB提供了一些故障恢复的工具和机制,例如自动故障检测、故障转移和数据恢复。
1. 自动故障检测。MongoDB的分片和复制机制会自动检测故障节点,并尝试自动修复和恢复数据。
2. 故障转移。当主节点发生故障时,MongoDB的复制机制会自动切换到备用节点上,确保数据库的持续可用性。
3. 数据恢复。当数据库发生错误或数据损坏时,可以使用MongoDB的备份和还原工具来进行数据恢复。
### 6.4 最佳实践
在使用MongoDB与Node.js集成时,以下是一些最佳实践和注意事项:
1. 使用连接池来管理数据库连接,以提高性能和资源利用率。
2. 对于频繁读写的操作,使用批量操作和原子操作来减少数据库的开销和网络延迟。
3. 使用索引来加速查询操作。对于经常进行查询的字段,使用唯一索引或复合索引来提高查询性能。
4. 避免过度使用嵌套文档。对于复杂的数据结构,考虑使用引用(reference)来减少数据冗余和复杂性。
5. 定期进行性能优化和系统监控。使用适当的工具和技术来监控数据库的性能和运行状态,及时优化和调整系统配置。
总结:
本章中,我们讨论了一些与MongoDB数据库和Node.js集成相关的高级主题和最佳实践。我们介绍了数据分片、数据复制和故障恢复的方法,以及一些关于MongoDB与Node.js集成的注意事项。通过遵循这些最佳实践,我们可以提高系统的性能和可靠性,优化数据存储和管理的效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在帮助读者轻松搞定Node后台管理系统,通过一系列文章,覆盖了Node.js入门指南,使用Express框架创建RESTful API,以及MongoDB数据库与Node.js的集成,为读者提供了实战指南。专栏还包括用户认证与授权、前后端数据交互基础、使用WebSocket实现实时通信等内容,旨在保障后台管理系统的安全性和实时性。此外,专栏还介绍了文件上传与管理、日志管理与错误处理、分页与搜索、性能优化与缓存等方面的知识,以及使用Node.js构建微服务、异步编程、数据加密与安全传输、单元测试、任务调度与定时器管理等内容。通过专栏的学习,读者将能够构建高响应性的后台管理系统,实现实时监控与告警,以及自动化后台操作,同时能够处理邮件与通知,实现后台系统的消息推送。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB机械手仿真并行计算:加速复杂仿真的实用技巧
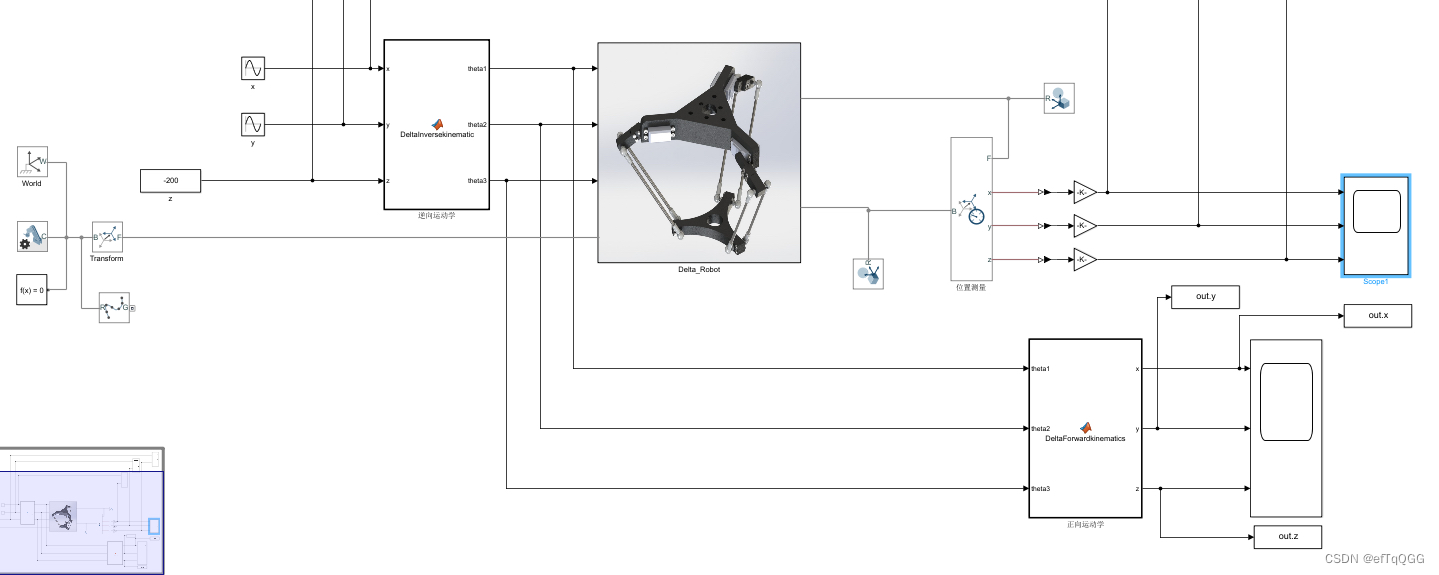
# 1. MATLAB机械手仿真基础
在这一章节中,我们将带领读者进入MATLAB机械手仿真的世界。为了使机械手仿真具有足够的实用性和可行性,我们将从基础开始,逐步深入到复杂的仿真技术中。
首先,我们将介绍机械手仿真的基本概念,包括仿真系统的构建、机械手的动力学模型以及如何使用MATLAB进行模型的参数化和控制。这将为后续章节中将要介绍的并行计算和仿真优化提供坚实的基础。
接下来,我
【Python分布式系统精讲】:理解CAP定理和一致性协议,让你在面试中无往不利

# 1. 分布式系统的基础概念
分布式系统是由多个独立的计算机组成,这些计算机通过网络连接在一起,并共同协作完成任务。在这样的系统中,不存在中心化的控制,而是由多个节点共同工作,每个节点可能运行不同的软件和硬件资源。分布式系统的设计目标通常包括可扩展性、容错性、弹性以及高性能。
分布式系统的难点之一是各个节点之间如何协调一致地工作。
【宠物管理系统权限管理】:基于角色的访问控制(RBAC)深度解析
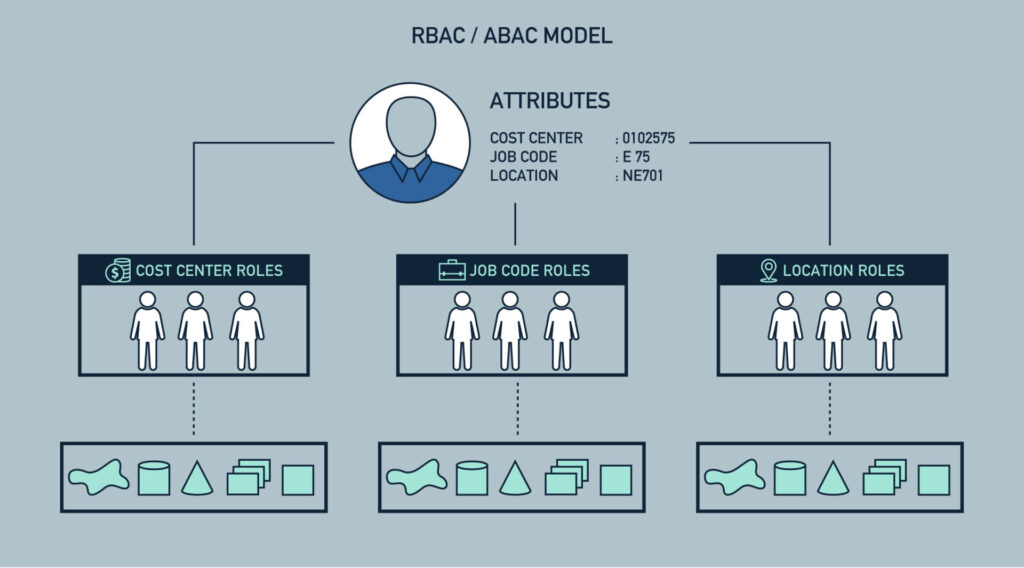
# 1. 基于角色的访问控制(RBAC)概述
在信息技术快速发展的今天,信息安全成为了企业和组织的核心关注点之一。在众多安全措施中,访问控制作为基础环节,保证了数据和系统资源的安全。基于角色的访问控制(Role-Based Access Control, RBAC)是一种广泛
【数据不平衡环境下的应用】:CNN-BiLSTM的策略与技巧

# 1. 数据不平衡问题概述
数据不平衡是数据科学和机器学习中一个常见的问题,尤其是在分类任务中。不平衡数据集意味着不同类别在数据集中所占比例相差悬殊,这导致模型在预测时倾向于多数类,从而忽略了少数类的特征,进而降低了模型的泛化能力。
## 1.1 数据不平衡的影响
当一个类别的样本数量远多于其他类别时,分类器可能会偏向于识别多数类,而对少数类的识别
【系统解耦与流量削峰技巧】:腾讯云Python SDK消息队列深度应用

# 1. 系统解耦与流量削峰的基本概念
## 1.1 系统解耦与流量削峰的必要性
在现代IT架构中,随着服务化和模块化的普及,系统间相互依赖关系越发复杂。系统解耦成为确保模块间低耦合、高内聚的关键技术。它不仅可以提升系统的可维护性,还可以增强系统的可用性和可扩展性。与
脉冲宽度调制(PWM)在负载调制放大器中的应用:实例与技巧

# 1. 脉冲宽度调制(PWM)基础与原理
脉冲宽度调制(PWM)是一种广泛应用于电子学和电力电子学的技术,它通过改变脉冲的宽度来调节负载上的平均电压或功率。PWM技术的核心在于脉冲信号的调制,这涉及到开关器件(如晶体管)的开启与关闭的时间比例,即占空比的调整。在占空比增加的情况下,负载上的平均电压或功率也会相
数据库备份与恢复:实验中的备份与还原操作详解

# 1. 数据库备份与恢复概述
在信息技术高速发展的今天,数据已成为企业最宝贵的资产之一。为了防止数据丢失或损坏,数据库备份与恢复显得尤为重要。备份是一个预防性过程,它创建了数据的一个或多个副本,以备在原始数据丢失或损坏时可以进行恢复。数据库恢复则是指在发生故障后,将备份的数据重新载入到数据库系统中的过程。本章将为读者提供一个关于
MATLAB模块库翻译性能优化:关键点与策略分析

# 1. MATLAB模块库性能优化概述
MATLAB作为强大的数学计算和仿真软件,广泛应用于工程计算、数据分析、算法开发等领域。然而,随着应用程序规模的不断增长,性能问题开始逐渐凸显。模块库的性能优化,不仅关乎代码的运行效率,也直接影响到用户的工作效率和软件的市场竞争力。本章旨在简要介绍MATLAB模块库性能优化的重要性,以及后续章节将深入探讨的优化方法和策略。
## 1.1 MATLAB模块库性能优化的重要性
随着应用需求的
【趋势分析】:MATLAB与艾伦方差在MEMS陀螺仪噪声分析中的最新应用
# 1. MEMS陀螺仪噪声分析基础
## 1.1 噪声的定义和类型
在本章节,我们将对MEMS陀螺仪噪声进行初步探索。噪声可以被理解为任何影响测量精确度的信号变化,它是MEMS设备性能评估的核心问题之一。MEMS陀螺仪中常见的噪声类型包括白噪声、闪烁噪声和量化噪声等。理解这些噪声的来源和特点,对于提高设备性能至关重要。
【集成学习方法】:用MATLAB提高地基沉降预测的准确性

# 1. 集成学习方法概述
集成学习是一种机器学习范式,它通过构建并结合多个学习器来完成学习任务,旨在获得比单一学习器更好的预测性能。集成学习的核心在于组合策略,包括模型的多样性以及预测结果的平均或投票机制。在集成学习中,每个单独的模型被称为基学习器,而组合后的模型称为集成模型。该
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )