【Python字符串搜索案例分析】:从简单到复杂的递进学习
发布时间: 2024-09-20 00:03:45 阅读量: 34 订阅数: 46 

# 1. 字符串搜索基础概念与方法
在信息技术的海洋中,字符串搜索是一个极为重要的基础操作。无论是在数据分析、文本处理还是在复杂的软件开发过程中,我们总需要找到特定的字符序列。理解字符串搜索的基础概念和方法,是掌握更高级搜索技术的基石。
## 1.1 字符串搜索的基础
字符串搜索,通常指的是在一个文本字符串中寻找是否存在一个特定的子串,并获取其位置的过程。这个基础操作是许多字符串处理和文本分析算法的核心。搜索可以是从文本的开头开始,也可以是任意位置,甚至可以是不区分大小写的搜索。
## 1.2 搜索方法的分类
从技术角度,字符串搜索方法大致可以分为两类:
- **基本搜索方法**:如顺序搜索(线性搜索),它简单但效率较低,适合短字符串或简单场景。
- **高效搜索方法**:如KMP算法(Knuth-Morris-Pratt)、Boyer-Moore算法等,它们通过预处理信息来提高搜索速度,适合长文本和重复搜索的场景。
在后续章节中,我们将详细介绍Python中的字符串搜索技术,包括基本操作和正则表达式的强大功能。让我们开始探索字符串搜索的奥秘。
# 2. Python中的基本字符串搜索技术
### 2.1 Python字符串基础操作
#### 2.1.1 字符串的定义和访问方式
在Python中,字符串是一种序列类型,可以包含多个字符。它被定义为以单引号(' ')或双引号(" ")包裹的字符序列。此外,可以通过多行字符串的方式定义包含多行文本的字符串,即使用三个连续的单引号(''')或双引号("""")。
字符串可以使用索引进行访问,索引值从0开始,代表字符串中的第一个字符。例如,字符串`s = "Hello World"`中的`'H'`可以通过`s[0]`访问,而`'d'`可以通过`s[10]`访问。Python还支持负索引,`s[-1]`可以访问最后一个字符`'d'`。
```python
# 定义字符串
example_str = "Hello World"
# 正向索引访问
print("正向索引访问示例:")
print(example_str[0]) # 输出: H
print(example_str[10]) # 输出: d
# 负向索引访问
print("\n负向索引访问示例:")
print(example_str[-1]) # 输出: d
print(example_str[-11]) # 输出: H
```
#### 2.1.2 字符串的基本搜索功能:index(), find(), and count()
在处理字符串时,经常会需要查找子串的位置或者计算子串出现的次数。Python提供了`index()`, `find()`, 和`count()`方法来实现这些功能。
- `index(sub[, start[, end]])`方法会在字符串中搜索子串`sub`,并返回子串首次出现的索引位置。如果在指定范围内找不到子串,则会抛出一个`ValueError`异常。
- `find(sub[, start[, end]])`方法与`index()`类似,但是如果找不到子串,则返回`-1`。
- `count(sub[, start[, end]])`方法会计算子串`sub`在字符串中出现的次数。
```python
# 定义字符串和子串
text = "Hello World, this is a simple example."
substring = "is"
# index()方法
try:
print("index()方法示例:")
print(text.index(substring)) # 输出: 10
except ValueError:
print("Sub-string not found")
# find()方法
print("\nfind()方法示例:")
print(text.find(substring)) # 输出: 10
# count()方法
print("\ncount()方法示例:")
print(text.count(substring)) # 输出: 3
```
### 2.2 正则表达式入门
#### 2.2.1 正则表达式的定义和语法基础
正则表达式是一种强大的文本处理工具,它允许用户定义匹配特定字符组合的模式。正则表达式模式被编译为一系列的字节码,然后执行匹配过程。Python通过内置的`re`模块提供对正则表达式的支持。
正则表达式的语法基础包括元字符、特殊字符、字符类、量词等。例如:
- `.` 匹配除换行符以外的任意字符。
- `^` 匹配字符串的开始位置。
- `$` 匹配字符串的结束位置。
- `*` 匹配0次或多次前面的子表达式。
- `+` 匹配1次或多次前面的子表达式。
- `{n}` 精确匹配n次前面的子表达式。
- `[a-z]` 匹配任何小写字母。
- `\d` 匹配任何数字,等价于[0-9]。
- `\s` 匹配任何空白字符,包括空格、制表符、换行符等。
```python
# 导入re模块
import re
# 定义字符串
text = "Hello World!"
# 使用正则表达式匹配
match = re.search(r"Hello", text) # r表示原始字符串,避免转义字符的干扰
# 输出匹配结果
if match:
print("正则表达式匹配结果:")
print(match.group()) # 输出: Hello
```
#### 2.2.2 Python中使用re模块进行基本的正则表达式搜索
Python的`re`模块提供了正则表达式的基本功能。它包括许多函数,如`search()`, `match()`, `findall()`, `finditer()`, 和`compile()`等。下面介绍`search()`, `match()`, 和`findall()`方法。
- `re.search(pattern, string, flags=0)`:在字符串中搜索第一个与模式匹配的子串,并返回相应的匹配对象。
- `re.match(pattern, string, flags=0)`:从字符串的开始位置检查模式是否匹配。
- `re.findall(pattern, string, flags=0)`:返回一个列表,包含字符串中所有匹配正则表达式模式的子串。
```python
import re
text = "Hello World, this is an example!"
# search()方法
match_obj = re.search(r"example!", text)
if match_obj:
print("search()方法找到匹配的字符串:")
print(match_obj.group()) # 输出: example!
# match()方法
match_obj = re.match(r"Hello", text)
if match_obj:
print("\nmatch()方法找到匹配的字符串:")
print(match_obj.group()) # 输出: Hello
# findall()方法
matches = re.findall(r"\b[a-z]+\b", text)
print("\nfindall()方法找到所有匹配的单词:")
print(matches) # 输出: ['hello', 'world', 'this', 'is', 'an', 'example']
```
在接下来的章节中,我们将深入探讨高级的正则表达式模式匹配技巧,以及字符串搜索的优化技巧。
# 3. Python字符串搜索进阶应用
在IT领域,数据的快速准确检索是日常工作的重要组成部分。在上一章节中,我们学习了Python字符串搜索的基本方法,包括基本操作和正则表达式的入门知识。在这一章节中,我们将深入了解字符串搜索在实际应用中的进阶使用方式,这将包括更高级的正则表达式模式匹配,以及提升搜索效率的各种优化技术。这不仅会加深我们对Python字符串处理的理解,同时也会提高我们开发相关应用程序时的性能和效率。
## 3.1 高级正则表达式模式匹配
在前一章节中,我们介绍了正则表达式的基础知识和如何在Python中使用re模块进行基本的搜索。现在,我们将深入探讨一些更高级的模式匹配技术,这些技术可以让搜索功能更加强大和灵活。
### 3.1.1 特殊字符和模式的使用
在正则表达式中,有特定的字符和字符组合,它们具有特殊的意义。比如,点号(`.`)可以匹配任何单个字符(除了换行符),问号(`?`)表示前面的字符是可选的,星号(`*`)表示前面的字符可以出现零次或多次等等。这些特殊的模式使得正则表达式具有极高的表达力。
#### 例子
假设我们需要匹配一个邮箱地址

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Python字符串搜索的方方面面,从基础方法到高级技巧。您将掌握find()方法的全面用法,了解其与index()方法的异同,并探索正则表达式的复杂匹配艺术。此外,您还将学习在处理大数据时高效使用find()功能的策略,以及避免常见错误的实用技巧。通过阅读本专栏,您将成为Python字符串搜索方面的专家,能够轻松解决各种字符串处理任务。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言shiny数据管道优化法】:高效数据流管理的核心策略
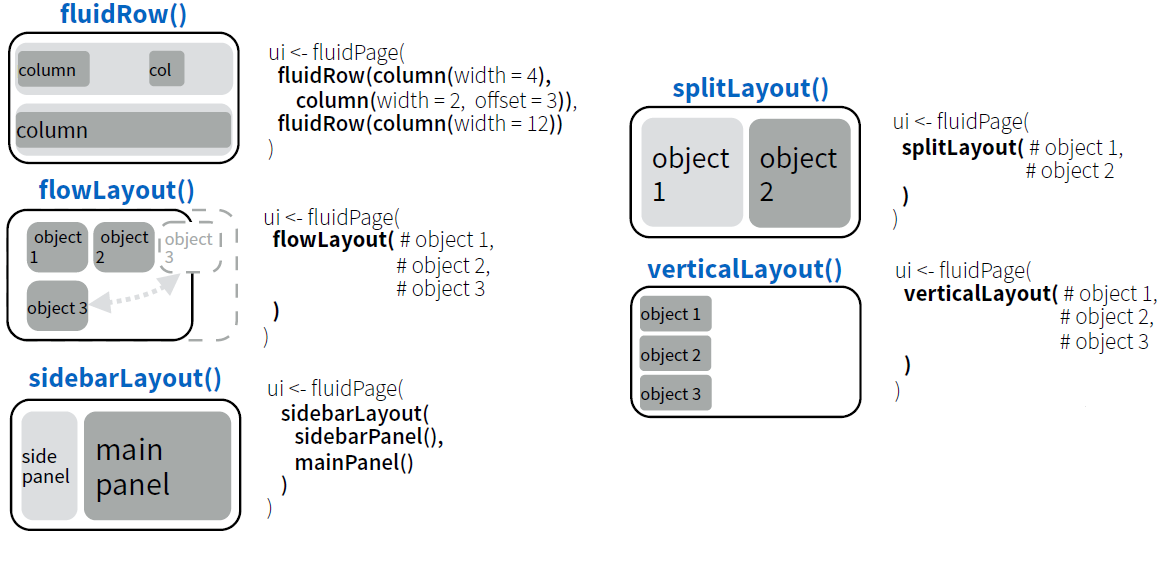
# 1. R语言Shiny应用与数据管道简介
## 1.1 R语言与Shiny的结合
R语言以其强大的统计分析能力而在数据科学领域广受欢迎。Shiny,作为一种基于R语言的Web应用框架,使得数据分析师和数据科学家能够通过简单的代码,快速构建交互式的Web应用。Shiny应用的两大核心是UI界面和服务器端脚本,UI负责用户界面设计,而服务器端脚本则处
【R语言数据包使用】:shinythemes包的深度使用与定制技巧

# 1. shinythemes包概述
`shinythemes` 包是R语言Shiny Web应用框架的一个扩展,提供了一组预设计的HTML/CSS主题,旨在使用户能够轻松地改变他们Shiny应用的外观。这一章节将简单介绍`shinythemes`包的基本概念和背景。
在数据科
【knitr包测试与验证】:如何编写测试用例,保证R包的稳定性与可靠性

# 1. knitr包与R语言测试基础
在数据科学和统计分析的世界中,R语言凭借其强大的数据处理和可视化能力,占据了不可替代的地位。knitr包作为R语言生态系统中一款重要的文档生成工具,它允许用户将R代码与LaTeX、Markdown等格式无缝结合,从而快速生成包含代码执行结果的报告。然而,随着R语言项目的复杂性增加,确保代码质量的任务也随之变得尤为重要。在本章中,我们将探讨knitr包的基础知识,并引入R语
【rgl数据包案例分析】:探索其在经济数据分析中的应用潜力

# 1. rgl数据包基础知识
在经济学研究领域,数据分析扮演着越来越重要的角色,尤其是在深入挖掘经济活动的复杂性方面。**rgl数据包**为处理经济数据提供了一系列工具和方法
贝叶斯统计入门:learnbayes包在R语言中的基础与实践

# 1. 贝叶斯统计的基本概念和原理
## 1.1 统计学的两大流派
统计学作为数据分析的核心方法之一,主要分为频率学派(Frequentist)和贝叶斯学派(Bayesian)。频率学派依赖于大量数据下的事件频率,而贝叶斯学派则侧重于使用概率来表达不确定性的程度。前者是基于假设检验和置信区间的经典方法,后者则是通过概率更新来进行推理。
## 1.2
【R语言数据包的错误处理】:编写健壮代码,R语言数据包运行时错误应对策略

# 1. R语言数据包的基本概念与环境搭建
## 1.1 R语言数据包简介
R语言是一种广泛应用于统计分析和图形表示的编程语言,其数据包是包含了数据集、函数和其他代码的软件包,用于扩展R的基本功能。理解数据包的基本概念,能够帮助我们更高效地进行数据分析和处理
【R语言shinydashboard机器学习集成】:预测分析与数据探索的终极指南
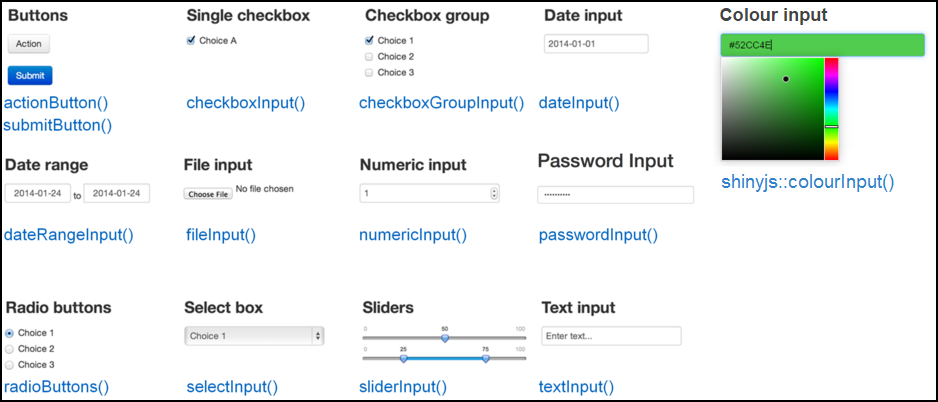
# 1. R语言shinydashboard简介与安装
## 1.1 R语言Shinydashboard简介
Shinydashboard是R语言的一个强大的包,用于构建交互式的Web应用。它简化了复杂数据的可视化过程,允许用户通过拖放和点击来探索数据。Shinydashboard的核心优势在于它能够将R的分析能力与Web应用的互动性结合在一起,使得数据分析结果能够以一种直观、动态的方式呈现给终端用户。
## 1.2 安
R语言高级用户:misc3d包在复杂数据分析中的15个实用案例

# 1. R语言与复杂数据分析
R语言,作为一门在统计学界和数据科学领域广受欢迎的编程语言,它为复杂数据分析提供了一套强大的工具集。本章将介绍R语言在处理复杂数据分析任务时的核心优势和常用方法。我们将探讨R语言提供的丰富统计函数库、数据处理能力以及如何运用这些工具进行高效的数据分析。
R语言的数据分析过程通常涉及数据的清洗、变
R语言空间数据分析:sf和raster包的地理空间分析宝典
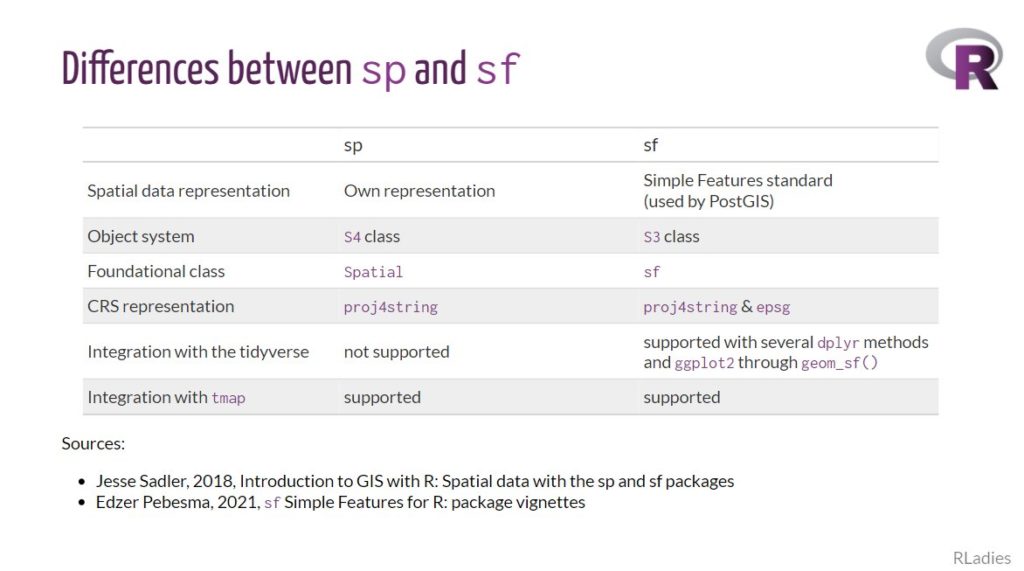
# 1. R语言空间数据分析基础
## 简介
R语言作为数据分析领域广受欢迎的编程语言,提供了丰富的空间数据处理和分析包。在空间数据分析领域,R语言提供了一套强大的工具集,使得地理信息系统(GIS)的复杂分析变得简洁高效。本章节将概述空间数据分析在R语言中的应用,并为读者提供后续章节学习所需的基础知识。
## 空间数据的
【R语言多变量分析】:三维散点图在变量关系探索中的应用

# 1. R语言多变量分析基础
在数据分析领域,多变量分析扮演着至关重要的角色。它不仅涉及到数据的整理和分析,还包含了从数据中发现深层次关系和模式的能力。R语言作为一种广泛用于统计分析和图形表示的编程语言,其在多变量分析领域中展现出了强大的功能和灵活性。
## 1.1 多变量数据分析的重要性
多变量数据分析能够帮助研究者们同时对多个相关变量进行分析,以理解它们之间的关系。这种分析方法在自然科学、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )