马尔科夫决策过程(MDP)与强化学习的关系
发布时间: 2024-04-10 07:23:49 阅读量: 33 订阅数: 29 
# 1. 马尔科夫决策过程(MDP)简介
## 1.1 什么是马尔科夫决策过程(MDP)?
马尔科夫决策过程(MDP)是一种数学框架,用于描述具有马尔科夫性质的决策过程。在MDP中,决策是基于当前状态和可能的行动,目标是找到一个策略,使得长期收益最大化。MDP是强化学习中最基本的模型之一。
## 1.2 MDP 的基本元素和特征
在MDP中,有以下基本元素和特征:
- **状态空间(State Space)**:描述系统可能处于的所有状态的集合。
- **动作空间(Action Space)**:描述系统可采取的所有动作的集合。
- **奖励函数(Reward Function)**:在每个时刻系统执行动作时,环境返回的奖励信号。
- **转移概率(Transition Probability)**:描述在给定状态下执行某个动作后转移到下一个状态的概率。
- **马尔科夫性质(Markov Property)**:未来状态的转移仅与当前状态和当前动作有关,与过去无关。
下表展示了一个简单的MDP示例,其中包含3个状态(S1, S2, S3)和2个动作(A1, A2):
| 状态(State) | 动作(Action) | 转移概率(Transition Probability) | 奖励(Reward) |
|--------------|--------------|----------------------------------|-------------|
| S1 | A1 | S1 -> 0.7, S2 -> 0.3 | 5 |
| S1 | A2 | S2 -> 0.8, S3 -> 0.2 | 2 |
| S2 | A1 | S1 -> 0.4, S2 -> 0.6 | 3 |
| S2 | A2 | S2 -> 0.5, S3 -> 0.5 | 1 |
| S3 | A1 | S1 -> 0.6, S3 -> 0.4 | 4 |
| S3 | A2 | S1 -> 0.3, S2 -> 0.7 | 6 |
通过对MDP的基本元素和特征的了解,可以更好地理解马尔科夫决策过程在强化学习中的应用和意义。
# 2. 强化学习基础知识
### 2.1 强化学习概述
强化学习是一种机器学习范式,代理程序从环境中观察状态,根据选择执行动作,通过反馈学习奖励来调整其行为策略。在强化学习中,代理程序的目标是获得最大长期奖励。
#### 强化学习的基本特征
强化学习具有以下基本特征:
- 代理程序与环境进行交互
- 代理程序根据执行的动作获得即时奖励
- 代理程序通过奖励信号学习最优策略
### 2.2 强化学习与监督学习、无监督学习的区别
下表对比了强化学习、监督学习和无监督学习的区别:
| 特征 | 强化学习 | 监督学习 | 无监督学习 |
|--------------|------------------------------|-----------------------|-----------------------|
| 数据标签 | 无需标记 | 需要标记 | 无需标记 |
| 反馈 | 基于奖励信号 | 直接正确答案 | 无反馈 |
| 目标 | 最大化长期奖励 | 准确预测输出 | 数据特征学习 |
| 示例 | 游戏玩家 | 图像识别 | 聚类 |
| 应用场景 | 游戏、机器人控制 | 图像识别、语音识别 | 数据聚类、降维 |
```python
# 强化学习示例代码
import numpy as np
# 定义奖励函数
rewards = np.array([[0, 0, 0],
[0, 1, -1],
[0, 0, 0]])
# 定义初始策略
policy = np.array([[0, 1, 0],
[0, 1, 0],
[0, 1, 0]])
# 定义状态转移概率
transition = np.array([[[0.8, 0.1, 0.1],
[0, 1, 0],
[0.5, 0.5, 0]],
[[0, 0, 0],
[0, 1, 0],
[1, 0, 0]],
[[0, 1, 0],
[0, 1, 0],
[0.2, 0.4, 0.4]]])
# 执行强化学习
def reinforce_learning(rewards, policy, transition):
# 在这里实现强化学习算法
pass
# 调用强化学习函数
reinforce_learning(rewards, policy, transition)
```
```mermaid
graph TD;
A(观察环境状态) --> B(选择执行动作);
B --> C(获取奖励信号);
C --> D(调整行为策略);
D --> A;
```
# 3. MDP 在强化学习中的应用
马尔科夫决策过程(MDP)在强化学习中扮演着关键的角色,它定义了智能体与环境之间的交互方式,帮助智能体做出决策以最大化长期奖励。以下是MDP在强化学习中的具体应用:
1. **MDP 如何在强化学习中充当作用?**
- MDP 提供了一个框架,描述了智能体与环境之间的交互方式,包括状态、动作、奖励等元素。这使得智能体能够根据当前状态选择最佳动作,以获取最大长期奖励。
- 通过定义状态转移概率和奖励函数,MDP为强化学习算法提供了学习的环境,使智能体能够通过与环境的交互不断优化策略。
2. **强化学习中的奖励机制与MDP的关系**
在强化学习中,奖励是指智能体在某一状态执行某一动作后所获得的反馈。奖励机制直接与MDP的奖励函数相关联,该函数定义了智能体在不同状态下执行不同动作所获得的即时奖励。
| 状态 | 动作 | 下一状态 | 奖励 |
|---------|------|---------|------|
| S0 | A0 | S1 | 1 |
| S1 | A1 | S2 | 0 |
| S2 | A0 | S0 | -1 |
上表展示了一个简单的MDP示例,包括状态、动作、下一状态以及相应的奖励。
3. **应用代码示例**
```python
# 导入强化学习库
import gym
# 创建 CartPole 环境
env = gym.make('CartPole-v0')
# 初始化状态
state = env.reset()
# 开始强化学习循环
done = False
while not done:
# 选择动作
action = env.action_space.sample()
# 执行动作
next_state, reward, done, _ = env.step(action)
# 更新状态
state = next_state
```
4. **MDP与策略**
MDP中的策略定义了智能体如何在给定状态下选择动作。在强化学习中,目标是找到最优策略,使得智能体在与环境的交互过程中获得最大长期奖励。智能体可以通过值函数来评估不同策略的优劣,并选择价值最高的策略。
```mermaid
graph LR
Start --> DefineStatesAndActions
DefineStatesAndActions --> DefineRewards
DefineRewards --> DefineTransitionProbs
DefineTransitionProbs --> End
```
通过以上内容,我们可以看到MDP在强化学习中的重要性和具体应用,为智能体学习和决策提供了有效的框架和方法。
# 4. 值函数与策略
在马尔科夫决策过程(MDP)中,值函数和策略是两个重要的概念。值函数表示在某个状态下采取某个动作的长期回报,而策略则是指在每个状态下选择动作的规则。本章将深入探讨值函数和策略的定义、作用以及它们在MDP中的重要性。
### 4.1 值函数的定义与作用
值函数是对当前状态或状态动作对的价值进行评估的函数,主要有两种类型:状态值函数和动作值函数。
下表展示了状态值函数和动作值函数的定义和作用:
| 类型 | 定义 | 作用 |
|--------------|------------------------------------|------------------------------------------|
| 状态值函数 V(s) | 表示在状态 s 下的长期回报 | 帮助智能体判断不同状态的优劣,指导决策 |
| 动作值函数 Q(s, a) | 表示在状态 s 下采取动作 a 的长期回报 | 在给定状态下选择最优的动作,优化智能体的决策 |
### 4.2 策略的概念及在MDP中的重要性
策略是一个函数,它定义了智能体在每个状态下应该采取的动作。在MDP中,策略可以分为确定性策略和随机策略。
下面是一个用 Python 实现的简单示例代码,用于计算状态值函数 V(s) 的价值:
```python
# 简化的值迭代算法
def value_iteration(states, actions, rewards, transitions, gamma, theta):
V = {s: 0 for s in states} # 初始化状态值函数为0
while True:
delta = 0
for s in states:
v = V[s]
V[s] = max([sum([transitions[s][a][s1] * (rewards[s][a][s1] + gamma * V[s1]) for s1 in states])
for a in actions])
delta = max(delta, abs(v - V[s]))
if delta < theta:
break
return V
```
以上代码通过值迭代算法计算在给定状态下的状态值函数 V(s)。值迭代算法是强化学习中常用的算法之一,用于逐步更新状态值函数直到收敛。
下面是一个简单的流程图展示值迭代算法的流程:
```mermaid
graph LR
Start --> Initialize
Initialize -->|While True| Evaluate
Evaluate -->|Until convergence| Update
Update -->|Check convergence| Stop
```
通过值函数和策略的定义、作用和实际应用,我们可以更好地理解智能体在MDP中如何做出决策并获得最优策略。
# 5.1 蒙特卡洛方法
蒙特卡洛方法是一种基于统计学的计算方法,在强化学习中被广泛应用。本节将详细介绍蒙特卡洛方法的原理和在强化学习中的具体应用。
#### 蒙特卡洛方法原理:
蒙特卡洛方法通过随机抽样的方式来估计未知量的数值。在强化学习中,蒙特卡洛方法可以用来估计状态值函数或动作值函数,进而帮助智能体做出决策。
#### 蒙特卡洛方法步骤:
1. **采样阶段**:智能体与环境进行交互,收集样本轨迹数据。
2. **估计阶段**:根据样本数据计算状态值函数或动作值函数的估计值。
3. **更新阶段**:根据估计值更新决策策略。
#### 蒙特卡洛方法在强化学习中的应用:
蒙特卡洛方法可以用于解决强化学习中的预测问题和控制问题,例如用于评估策略的好坏、优化策略等。
#### 代码示例:
```python
import numpy as np
# 模拟样本数据
rewards = [1, 0, 1, 0, 1]
returns = []
gamma = 0.9
G = 0
# 计算回报值
for r in rewards[::-1]:
G = r + gamma * G
returns.insert(0, G)
print("Returns:", returns)
```
#### 结果说明:
以上代码展示了一个简单的蒙特卡洛方法示例,根据输入的奖励序列计算出每个时刻的回报值。蒙特卡洛方法通过累积回报值来估计状态值或动作值函数。
#### 总结:
蒙特卡洛方法是一种强大的强化学习方法,适用于许多场景下的值函数估计和策略优化问题。通过采样和估计得到的回报值,可以帮助智能体学习到更优的决策策略。
# 6. MDP 的延伸应用
马尔科夫决策过程(MDP)作为一种强大的模型,不仅在强化学习中有着重要作用,也在其他领域有着广泛的应用。本章将介绍MDP在机器人控制和自然语言处理领域的具体应用。
### 6.1 马尔科夫决策过程在机器人控制中的应用
在机器人控制领域,MDP被广泛应用于路径规划、动作决策等方面。通过MDP模型,机器人可以根据当前状态和环境动态调整策略,以实现更智能的行为。以下是一个简单的MDP在机器人控制中的应用流程图:
```mermaid
graph LR
A[开始] --> B(获取当前状态)
B --> C{是否达到终止状态}
C -- 是 --> D[结束]
C -- 否 --> E{选择动作}
E -- 确定动作 --> F[执行动作]
F --> G{观察奖励值}
G --> H{更新策略}
H --> B
```
### 6.2 MDP 在自然语言处理领域的应用
在自然语言处理领域,MDP可以用于对话系统、文本生成等任务中。通过建模环境状态和动作,MDP可以帮助系统根据用户输入动态生成合适的回复或文本内容。下表展示了一个简单的MDP在自然语言处理中的应用示例:
| 状态 | 动作 | 奖励 |
|-----------|---------------|--------|
| 用户提问 | 生成回复 | 高奖励 |
| 用户提问 | 生成随机内容 | 低奖励 |
通过以上示例,我们可以看到MDP在不同领域的应用,展示了其在解决实际问题中的灵活性和有效性。
# 7. 总结与展望
### 7.1 本文总结
在本文中,我们深入探讨了马尔科夫决策过程(MDP)与强化学习之间的关系,以及它们在现代机器学习中的重要性。通过介绍MDP的基本元素、强化学习的基础知识、MDP在强化学习中的应用、值函数与策略、强化学习算法、MDP的延伸应用等内容,帮助读者对这一领域有了更深入的理解。
本文从理论到实践,介绍了MDP在强化学习中的应用,包括如何建模问题、如何设计奖励机制等,同时展示了一些强化学习算法的具体应用场景。通过具体案例和代码实现,读者可以更直观地了解如何解决实际问题。
### 7.2 强化学习未来发展趋势
随着人工智能技术的飞速发展,强化学习在更多领域展现出巨大潜力。未来,我们可以期待以下发展趋势:
- **深度强化学习(Deep Reinforcement Learning):** 结合深度学习与强化学习,实现更复杂任务的解决。
- **多智能体强化学习(Multi-Agent Reinforcement Learning):** 研究多个智能体协同决策的问题,适用于博弈、交通控制等领域。
- **迁移强化学习(Transfer Reinforcement Learning):** 将在一个领域学到的知识迁移到另一个领域,提高算法的泛化能力。
- **自适应强化学习(Adaptive Reinforcement Learning):** 基于环境变化实时调整学习策略,提高算法的适应性。
以下是强化学习未来发展趋势的mermaid格式流程图:
```mermaid
graph TD;
A(深度强化学习) --> B(解决更复杂任务);
A --> C(结合深度学习与强化学习);
D(多智能体强化学习) --> E(多智能体协同决策);
D --> F(适用于博弈、交通控制);
G(迁移强化学习) --> H(知识迁移到新领域);
G --> I(提高算法泛化能力);
J(自适应强化学习) --> K(实时调整学习策略);
J --> L(提高适应性);
```
以上是对第七章的具体内容总结和强化学习未来发展的展望。随着技术的进步和应用场景的拓展,强化学习将在更多领域展现出其强大的能力和潜力。
0
0
相关推荐

专栏简介
本专栏深入探讨了强化学习,一种机器学习技术,使机器能够通过与环境互动并获得奖励来学习最佳行为。它涵盖了强化学习的基础概念,如马尔科夫决策过程和值函数。还介绍了各种强化学习算法,包括 Q-Learning、深度 Q 网络、策略梯度和蒙特卡洛树搜索。专栏还探讨了强化学习与神经网络的结合,以及在自动驾驶、金融和多智能体系统等领域的应用。此外,它还讨论了强化学习与机器学习之间的差异,以及在不确定性环境下和基于模型的强化学习的算法。通过对这些主题的全面概述,本专栏为读者提供了强化学习的深入理解,及其在现实世界中的广泛应用。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
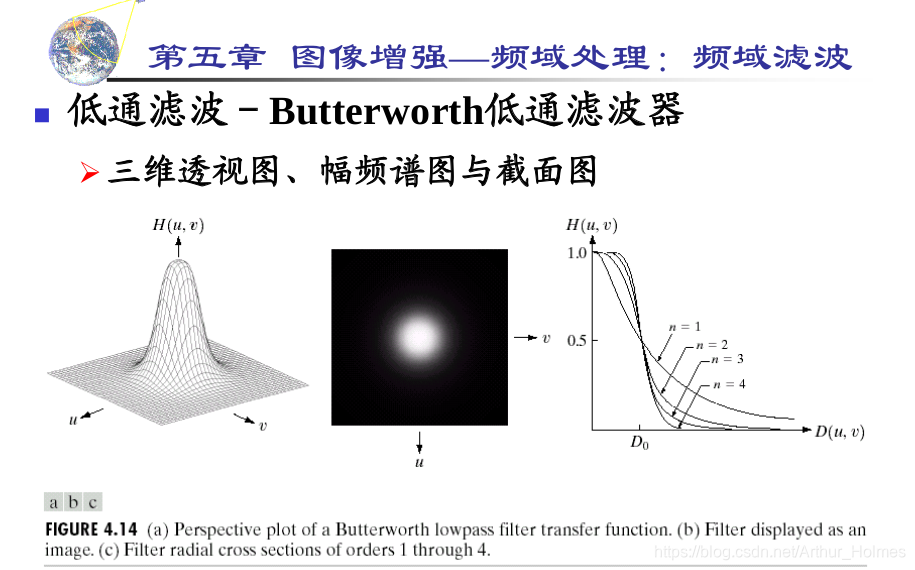
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
MATLAB散点图:使用散点图进行信号处理的5个步骤
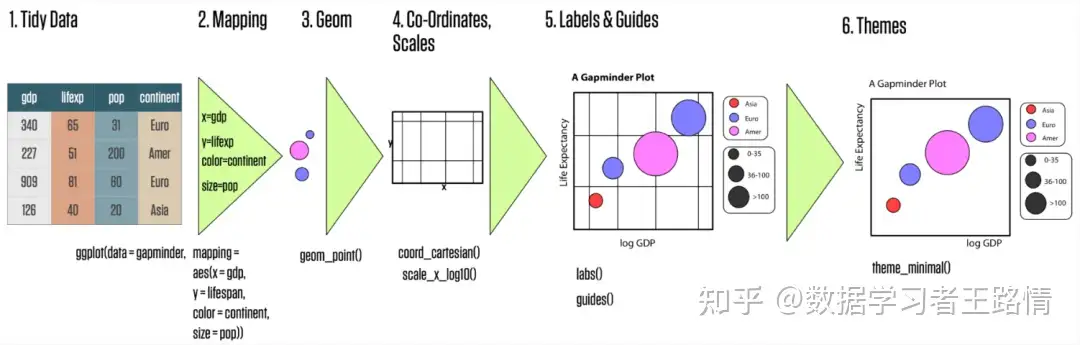
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
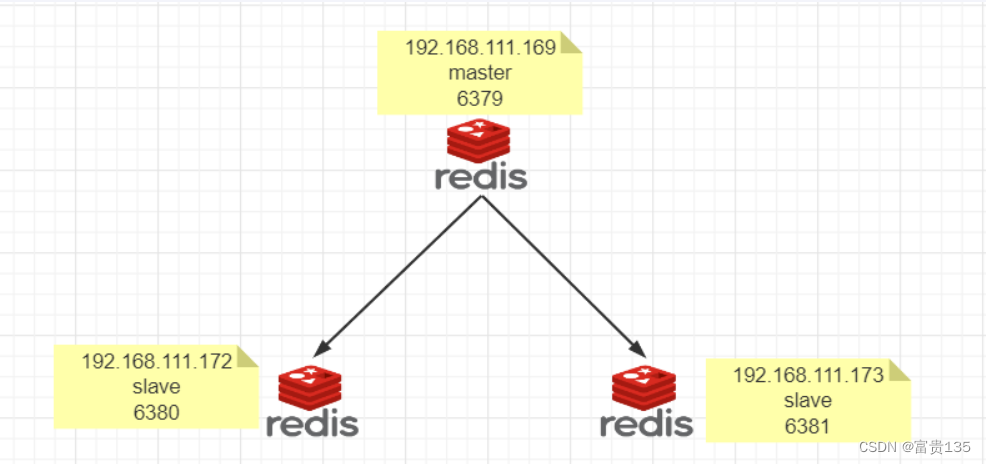
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )