【YOLO数据集增强秘籍】:10个必知技巧,提升模型精度50%
发布时间: 2024-08-16 12:58:49 阅读量: 373 订阅数: 58 
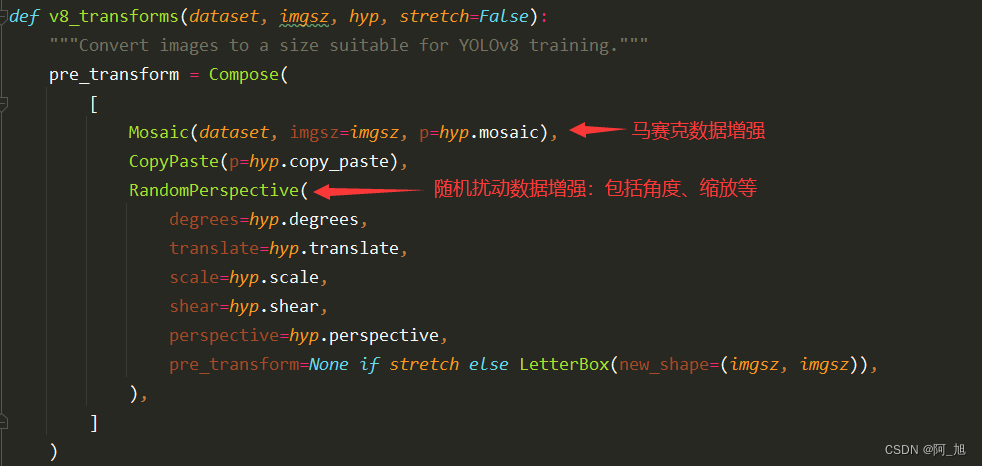
# 1. YOLO数据集增强概述
**1.1 数据集增强的必要性**
在计算机视觉任务中,数据集增强是提高模型泛化能力和鲁棒性的关键技术。它通过对原始数据进行各种变换,生成更多样化的训练样本,从而帮助模型学习更广泛的数据分布。
**1.2 YOLO数据集增强**
YOLO(You Only Look Once)是一种实时目标检测算法,对数据集增强特别敏感。通过应用适当的数据增强技术,可以显著提高YOLO模型的精度和召回率。
# 2. 图像变换增强
图像变换增强是通过改变图像的几何形状来增强数据集的一种方法。它可以增加数据集的多样性,使模型对各种图像变换具有鲁棒性。
### 2.1 旋转、翻转和缩放
#### 2.1.1 旋转增强
旋转增强是将图像围绕其中心旋转一定角度。这可以增加数据集中的图像多样性,使模型能够识别不同方向的对象。
```python
import cv2
import numpy as np
def rotate_image(image, angle):
"""
旋转图像。
参数:
image:输入图像。
angle:旋转角度(以度为单位)。
"""
# 获取图像的中心点
center = (image.shape[1] // 2, image.shape[0] // 2)
# 旋转矩阵
rotation_matrix = cv2.getRotationMatrix2D(center, angle, 1.0)
# 旋转图像
rotated_image = cv2.warpAffine(image, rotation_matrix, (image.shape[1], image.shape[0]))
return rotated_image
```
#### 2.1.2 翻转增强
翻转增强是将图像沿水平或垂直轴翻转。这可以增加数据集中的图像多样性,使模型能够识别镜像对象。
```python
import cv2
def flip_image(image, mode):
"""
翻转图像。
参数:
image:输入图像。
mode:翻转模式(0:水平翻转,1:垂直翻转)。
"""
if mode == 0:
# 水平翻转
flipped_image = cv2.flip(image, 1)
elif mode == 1:
# 垂直翻转
flipped_image = cv2.flip(image, 0)
else:
raise ValueError("Invalid flip mode.")
return flipped_image
```
#### 2.1.3 缩放增强
缩放增强是将图像缩放一定比例。这可以增加数据集中的图像多样性,使模型能够识别不同大小的对象。
```python
import cv2
def scale_image(image, scale):
"""
缩放图像。
参数:
image:输入图像。
scale:缩放比例。
"""
# 缩放图像
scaled_image = cv2.resize(image, (int(image.shape[1] * scale), int(image.shape[0] * scale)))
return scaled_image
```
### 2.2 剪裁和填充
#### 2.2.1 随机剪裁
随机剪裁是随机从图像中剪裁一个矩形区域。这可以增加数据集中的图像多样性,使模型能够识别图像的不同部分。
```python
import cv2
import numpy as np
def random_crop(image, size):
"""
随机剪裁图像。
参数:
image:输入图像。
size:剪裁区域的大小(以像素为单位)。
"""
# 获取图像的中心点
center = (image.shape[1] // 2, image.shape[0] // 2)
# 随机生成剪裁区域的左上角坐标
x = np.random.randint(0, image.shape[1] - size)
y = np.random.randint(0, image.shape[0] - size)
# 剪裁图像
cropped_image = image[y:y+size, x:x+size]
return cropped_image
```
#### 2.2.2 填充增强
填充增强是在图像周围填充一个常数值。这可以增加数据集中的图像多样性,使模型能够识别图像的不同背景。
```python
import cv2
def pad_image(image, size):
"""
填充图像。
参数:
image:输入图像。
size:填充区域的大小(以像素为单位)。
"""
# 获取图像的中心点
center = (image.shape[1] // 2, image.shape[0] // 2)
# 填充图像
padded_image = cv2.copyMakeBorder(image, size, size, size, size, cv2.BORDER_CONSTANT, value=0)
return padded_image
```
# 3. 颜色空间增强
颜色空间增强通过调整图像的颜色分布来丰富数据集,从而增强模型对颜色变化的鲁棒性。它主要包括色彩抖动和对比度增强两种方法。
### 3.1 色彩抖动
色彩抖动通过随机改变图像的色调、饱和度和亮度来增强数据集。
#### 3.1.1 色调抖动
色调抖动通过在一定范围内随机改变图像的色调来增强数据集。色调是指图像中颜色的基本色相,例如红色、绿色和蓝色。色调抖动可以使模型对不同光照条件下的图像更加鲁棒。
```python
import cv2
def hue_jitter(image, hue_range):
"""
色调抖动增强。
参数:
image: 输入图像。
hue_range: 色调抖动范围(-1.0, 1.0)。
返回:
增强后的图像。
"""
# 将图像转换为 HSV 颜色空间。
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 随机改变色调。
hue = hsv[:, :, 0]
hue += np.random.uniform(-hue_range, hue_range)
hue[hue < 0] += 180
hue[hue > 180] -= 180
# 将 HSV 图像转换回 BGR 颜色空间。
image = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return image
```
#### 3.1.2 饱和度抖动
饱和度抖动通过在一定范围内随机改变图像的饱和度来增强数据集。饱和度是指图像中颜色的鲜艳程度。饱和度抖动可以使模型对不同饱和度水平的图像更加鲁棒。
```python
import cv2
def saturation_jitter(image, saturation_range):
"""
饱和度抖动增强。
参数:
image: 输入图像。
saturation_range: 饱和度抖动范围(-1.0, 1.0)。
返回:
增强后的图像。
"""
# 将图像转换为 HSV 颜色空间。
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 随机改变饱和度。
saturation = hsv[:, :, 1]
saturation += np.random.uniform(-saturation_range, saturation_range)
saturation[saturation < 0] = 0
saturation[saturation > 255] = 255
# 将 HSV 图像转换回 BGR 颜色空间。
image = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return image
```
#### 3.1.3 亮度抖动
亮度抖动通过在一定范围内随机改变图像的亮度来增强数据集。亮度是指图像中颜色的明暗程度。亮度抖动可以使模型对不同亮度水平的图像更加鲁棒。
```python
import cv2
def brightness_jitter(image, brightness_range):
"""
亮度抖动增强。
参数:
image: 输入图像。
brightness_range: 亮度抖动范围(-1.0, 1.0)。
返回:
增强后的图像。
"""
# 随机改变亮度。
brightness = np.random.uniform(-brightness_range, brightness_range)
# 将图像转换为 HSV 颜色空间。
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 改变亮度。
hsv[:, :, 2] += brightness
hsv[:, :, 2][hsv[:, :, 2] < 0] = 0
hsv[:, :, 2][hsv[:, :, 2] > 255] = 255
# 将 HSV 图像转换回 BGR 颜色空间。
image = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return image
```
### 3.2 对比度增强
对比度增强通过调整图像中明暗区域之间的差异来增强数据集。它主要包括线性对比度增强和非线性对比度增强两种方法。
#### 3.2.1 线性对比度增强
线性对比度增强通过线性函数调整图像的对比度。它可以使模型对不同对比度水平的图像更加鲁棒。
```python
import cv2
def linear_contrast_enhancement(image, contrast_factor):
"""
线性对比度增强。
参数:
image: 输入图像。
contrast_factor: 对比度因子(> 0)。
返回:
增强后的图像。
"""
# 调整对比度。
image = image * contrast_factor
image[image < 0] = 0
image[image > 255] = 255
return image
```
#### 3.2.2 非线性对比度增强
非线性对比度增强通过非线性函数调整图像的对比度。它可以使模型对不同对比度水平的图像更加鲁棒,并增强图像的局部对比度。
```python
import cv2
def non_linear_contrast_enhancement(image, gamma):
"""
非线性对比度增强。
参数:
image: 输入图像。
gamma: gamma 值(> 0)。
返回:
增强后的图像。
"""
# 调整对比度。
image = cv2.pow(image / 255.0, gamma) * 255.0
return image
```
# 4. 几何变换增强
几何变换增强通过改变图像的几何形状来增加数据集的多样性,从而提高模型对几何变化的鲁棒性。常见的几何变换增强技术包括透视变换和弹性形变。
### 4.1 透视变换
透视变换是一种将图像投影到不同平面上进行扭曲的增强技术。它可以模拟相机角度和位置的变化,从而增加图像的多样性。
#### 4.1.1 平移透视变换
平移透视变换将图像沿水平或垂直方向平移,从而改变图像中物体的相对位置。
```python
import cv2
def translate_perspective(image, tx, ty):
"""
平移透视变换
参数:
image: 输入图像
tx: 水平平移量
ty: 垂直平移量
"""
height, width, channels = image.shape
translation_matrix = np.array([[1, 0, tx], [0, 1, ty], [0, 0, 1]])
transformed_image = cv2.warpPerspective(image, translation_matrix, (width, height))
return transformed_image
```
#### 4.1.2 旋转透视变换
旋转透视变换将图像绕其中心旋转一定角度,从而改变图像中物体的方向。
```python
import cv2
def rotate_perspective(image, angle):
"""
旋转透视变换
参数:
image: 输入图像
angle: 旋转角度(弧度)
"""
height, width, channels = image.shape
rotation_matrix = cv2.getRotationMatrix2D((width/2, height/2), angle, 1)
transformed_image = cv2.warpAffine(image, rotation_matrix, (width, height))
return transformed_image
```
#### 4.1.3 缩放透视变换
缩放透视变换将图像沿水平或垂直方向缩放,从而改变图像中物体的尺寸。
```python
import cv2
def scale_perspective(image, sx, sy):
"""
缩放透视变换
参数:
image: 输入图像
sx: 水平缩放比例
sy: 垂直缩放比例
"""
height, width, channels = image.shape
scale_matrix = np.array([[sx, 0, 0], [0, sy, 0], [0, 0, 1]])
transformed_image = cv2.warpPerspective(image, scale_matrix, (width, height))
return transformed_image
```
### 4.2 弹性形变
弹性形变是一种将图像中的像素随机移动的增强技术。它可以模拟图像中的变形和扭曲,从而增加图像的多样性。
#### 4.2.1 随机弹性形变
随机弹性形变将图像中的像素随机移动,移动量由高斯分布生成。
```python
import cv2
import numpy as np
def random_elastic_deformation(image, alpha, sigma):
"""
随机弹性形变
参数:
image: 输入图像
alpha: 变形强度
sigma: 高斯分布的标准差
"""
height, width, channels = image.shape
dx = np.random.rand(height, width) * 2 * alpha - alpha
dy = np.random.rand(height, width) * 2 * alpha - alpha
dx_smoothed = cv2.GaussianBlur(dx, (sigma, sigma), 0)
dy_smoothed = cv2.GaussianBlur(dy, (sigma, sigma), 0)
transformed_image = cv2.remap(image, dx_smoothed, dy_smoothed, interpolation=cv2.INTER_LINEAR)
return transformed_image
```
#### 4.2.2 局部弹性形变
局部弹性形变将图像中的局部区域随机移动,移动量由高斯分布生成。
```python
import cv2
import numpy as np
def local_elastic_deformation(image, alpha, sigma, grid_size):
"""
局部弹性形变
参数:
image: 输入图像
alpha: 变形强度
sigma: 高斯分布的标准差
grid_size: 网格大小
"""
height, width, channels = image.shape
num_grids_x = width // grid_size
num_grids_y = height // grid_size
dx = np.zeros((height, width))
dy = np.zeros((height, width))
for i in range(num_grids_x):
for j in range(num_grids_y):
dx[i*grid_size:(i+1)*grid_size, j*grid_size:(j+1)*grid_size] = np.random.rand() * 2 * alpha - alpha
dy[i*grid_size:(i+1)*grid_size, j*grid_size:(j+1)*grid_size] = np.random.rand() * 2 * alpha - alpha
dx_smoothed = cv2.GaussianBlur(dx, (sigma, sigma), 0)
dy_smoothed = cv2.GaussianBlur(dy, (sigma, sigma), 0)
transformed_image = cv2.remap(image, dx_smoothed, dy_smoothed, interpolation=cv2.INTER_LINEAR)
return transformed_image
```
# 5. 其他增强技术
### 5.1 马赛克增强
#### 5.1.1 随机马赛克
**定义:**随机马赛克增强是一种数据增强技术,将图像中的随机区域替换为马赛克块,以提高模型对遮挡和局部信息丢失的鲁棒性。
**参数:**
* `num_rectangles`:马赛克块的数量
* `min_size`:马赛克块的最小尺寸
* `max_size`:马赛克块的最大尺寸
**代码示例:**
```python
import cv2
import numpy as np
def random_mosaic(image):
"""随机马赛克增强
Args:
image (np.ndarray): 输入图像
Returns:
np.ndarray: 增强后的图像
"""
h, w, c = image.shape
num_rectangles = np.random.randint(1, 5)
for _ in range(num_rectangles):
x1 = np.random.randint(0, w)
y1 = np.random.randint(0, h)
x2 = np.random.randint(x1 + 1, w)
y2 = np.random.randint(y1 + 1, h)
mosaic_size = np.random.randint(10, 50)
image[y1:y2, x1:x2] = cv2.resize(image[y1:y2, x1:x2], (mosaic_size, mosaic_size))
return image
```
**逻辑分析:**
* `random_mosaic` 函数随机生成马赛克块的数量、尺寸和位置。
* 对于每个马赛克块,它从图像中随机选择一个区域并将其替换为马赛克块。
* 马赛克块的大小由 `mosaic_size` 参数控制。
#### 5.1.2 结构化马赛克
**定义:**结构化马赛克增强是一种数据增强技术,将图像划分为均匀的网格,并对每个网格中的像素进行马赛克处理。
**参数:**
* `grid_size`:网格的大小
* `mosaic_size`:马赛克块的大小
**代码示例:**
```python
import cv2
import numpy as np
def structured_mosaic(image):
"""结构化马赛克增强
Args:
image (np.ndarray): 输入图像
Returns:
np.ndarray: 增强后的图像
"""
h, w, c = image.shape
grid_size = 5
mosaic_size = 10
for i in range(0, h, grid_size):
for j in range(0, w, grid_size):
image[i:i+grid_size, j:j+grid_size] = cv2.resize(image[i:i+grid_size, j:j+grid_size], (mosaic_size, mosaic_size))
return image
```
**逻辑分析:**
* `structured_mosaic` 函数将图像划分为 `grid_size` 大小的网格。
* 对于每个网格,它将网格中的像素替换为马赛克块。
* 马赛克块的大小由 `mosaic_size` 参数控制。
### 5.2 混合增强
#### 5.2.1 混合图像增强
**定义:**混合图像增强是一种数据增强技术,将两幅或多幅图像混合在一起,以创建新的增强图像。
**参数:**
* `images`:要混合的图像列表
* `weights`:每幅图像的混合权重
**代码示例:**
```python
import cv2
import numpy as np
def blend_images(images, weights):
"""混合图像增强
Args:
images (list[np.ndarray]): 要混合的图像列表
weights (list[float]): 每幅图像的混合权重
Returns:
np.ndarray: 增强后的图像
"""
if len(images) != len(weights):
raise ValueError("Number of images and weights must be equal")
blended_image = np.zeros_like(images[0])
for image, weight in zip(images, weights):
blended_image += image * weight
return blended_image
```
**逻辑分析:**
* `blend_images` 函数将给定的图像列表混合在一起,使用提供的权重进行加权平均。
* 混合后的图像具有与输入图像相同的大小和通道数。
#### 5.2.2 混合标签增强
**定义:**混合标签增强是一种数据增强技术,将两个或多个标签混合在一起,以创建新的增强标签。
**参数:**
* `labels`:要混合的标签列表
* `weights`:每个标签的混合权重
**代码示例:**
```python
import numpy as np
def blend_labels(labels, weights):
"""混合标签增强
Args:
labels (list[np.ndarray]): 要混合的标签列表
weights (list[float]): 每幅图像的混合权重
Returns:
np.ndarray: 增强后的标签
"""
if len(labels) != len(weights):
raise ValueError("Number of labels and weights must be equal")
blended_label = np.zeros_like(labels[0])
for label, weight in zip(labels, weights):
blended_label += label * weight
return blended_label
```
**逻辑分析:**
* `blend_labels` 函数将给定的标签列表混合在一起,使用提供的权重进行加权平均。
* 混合后的标签具有与输入标签相同的大小和通道数。
# 6. 数据集增强实践指南
### 6.1 增强策略选择
#### 6.1.1 基于数据集特点选择增强策略
数据集的特点会影响增强策略的选择。例如:
- **图像大小:**小图像需要更强的增强,如缩放和剪裁。
- **目标多样性:**目标多样性较高的数据集需要更全面的增强,如旋转、翻转和颜色空间增强。
- **背景复杂性:**背景复杂的图像需要更强的几何变换增强,如透视变换和弹性形变。
#### 6.1.2 基于模型架构选择增强策略
模型架构也会影响增强策略的选择。例如:
- **卷积神经网络 (CNN):**CNN 对图像变换和颜色空间增强比较敏感。
- **Transformer:**Transformer 对几何变换增强和马赛克增强比较敏感。
### 6.2 增强参数调优
增强参数的调优至关重要,可以最大化增强效果。
#### 6.2.1 增强强度调优
增强强度是指增强操作的程度。例如,旋转增强可以设置旋转角度范围。增强强度应根据数据集和模型进行调优,以找到最佳平衡。
#### 6.2.2 增强顺序调优
增强顺序是指增强操作的执行顺序。不同的顺序可能会产生不同的效果。例如,在旋转之前进行缩放可能会产生不同的结果,而不是在缩放之后进行旋转。
**代码示例:**
```python
import albumentations as A
# 定义增强变换
transform = A.Compose([
A.RandomRotate90(),
A.RandomScale(scale_limit=0.2),
A.RandomCrop(width=320, height=240),
A.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2),
])
# 应用增强
image = transform(image=image)
```
通过调整增强参数和顺序,可以找到最适合特定数据集和模型的增强策略。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了如何改进 YOLO 数据集以提升模型性能。它提供了全面的指南,涵盖了从数据增强和标注到预处理、评估和优化等各个方面。通过遵循这些技巧,读者可以创建高质量的数据集,从而显着提高 YOLO 模型的精度、泛化能力和训练效率。专栏还提供了对数据集工具的深入分析,包括标注、预处理、合成、清理、分割、合并、评估和错误分析工具,帮助读者选择最适合其需求的工具。此外,它还分享了行业最佳实践,为打造高质量 YOLO 数据集提供了宝贵的见解,从而最大限度地提高模型性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Xshell与Vmware交互解析】:打造零故障连接环境的5大实践

# 摘要
本文旨在探讨Xshell与Vmware的交互技术,涵盖远程连接环境的搭建、虚拟环境的自动化管理、安全交互实践以及高级应用等方面。首
火电厂资产管理系统:IT技术提升资产管理效能的实践案例
# 摘要
本文深入探讨了火电厂资产管理系统的背景、挑战、核心理论、实践开发、创新应用以及未来展望。首先分析了火电厂资产管理的现状和面临的挑战,然后介绍了资产管理系统的理论框架,包括系统架构设计、数据库管理、流程优化等方面。接着,本文详细描述了系统的开发实践,涉及前端界面设计、后端服务开发、以及系统集成与测试。随后,文章探讨了火电厂资产管理系统在移动端应用、物联网技术应用以及
Magento多店铺运营秘籍:高效管理多个在线商店的技巧
# 摘要
随着电子商务的蓬勃发展,Magento多店铺运营成为电商企业的核心需求。本文全面概述了Magento多店铺运营的关键方面,包括后台管理、技术优化及运营实践技巧。文中详细介绍了店铺设置、商品和订单管理,以及客户服务的优化方法。此外,本文还探讨了性能调优、安全性增强和第三方集成技术,为实现有效运营提供了技术支撑。在运营实践方面,本文阐述了有效的营销
【实战攻略】MATLAB优化单脉冲测角算法与性能提升技巧

# 摘要
本文全面探讨了MATLAB环境下优化单脉冲测角算法的过程、技术及应用。首先介绍了单脉冲测角算法的基础理论,包括测角原理、信号处理和算法实现步骤。其次,文中详细阐述了在MATLAB平台下进行算法性能优化的策略,包括代码加速、并行计算和G
OPA656行业案例揭秘:应用实践与最佳操作规程

# 摘要
本文深入探讨了OPA656行业应用的各个方面,涵盖了从技术基础到实践案例,再到操作规程的制定与实施。通过解析OPA656的核心组件,分析其关键性能指标和优势,本文揭示了OPA656在工业自动化和智慧城市中的具体应用案例。同时,本文还探讨了OPA656在特定场景下的优化策略,包括性能
【二极管热模拟实验操作教程】:实验室中模拟二极管发热的详细步骤

# 摘要
本文通过对二极管热模拟实验基础的研究,详细介绍了实验所需的设备与材料、理论知识、操作流程以及问题排查与解决方法。首先,文中对温度传感器的选择和校准、电源与负载设备的功能及操作进行了说明,接着阐述了二极管的工作原理、PN结结构特性及电流-电压特性曲线分析,以及热效应的物理基础和焦耳效应。文章进一步详述了实验操作的具体步骤,包括设备搭建、二极管的选取和安装、数据采
重命名域控制器:专家揭秘安全流程和必备准备
# 摘要
本文深入探讨了域控制器重命名的过程及其对系统环境的影响,阐述了域控制器的工作原理、角色和职责,以及重命名的目的和必要性。文章着重介绍了重命名前的准备工作,包括系统环境评估、备份和恢复策略以及变更管理流程,确保重命名操作的安全性和系统的稳定运行。实践操作部分详细说明了实施步骤和技巧,以及重命名后的监控和调优方法。最后,本文讨论了在重命名域控制器过程中的安全最佳实践和合规性检查,以满足信息安全和监管要求。整体而言,
【精通增量式PID】:参数调整与稳定性的艺术

# 摘要
增量式PID控制器是一种常见的控制系统,以其结构简单、易于调整和较高的控制精度广泛应用于工业过程控制、机器人系统和汽车电子等领域。本文深入探讨了增量式PID控制器的基本原理,详细分析了参数调整的艺术、稳定性分析与优化策略,并通过实际应用案例,展现了其在不同系统中的性能。同时,本文介绍了模糊控制、自适应PID策略和预测控制技术与增量式PID结合的
CarSim参数与控制算法协同:深度探讨与案例分析

# 摘要
本文介绍了CarSim软件的基本概念、参数系统及其与控制算法之间的协同优化方法。首先概述了CarSim软件的特点及参数系统,然后深入探讨了参数调整
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )